






本文参考传智播客的Scrapy框架视频教程
视频课程链接:http://study.163.com/course/courseMain.htm?courseId=1004236002
Scrapy 爬虫初探
1、概述
- Scrapy是用纯Python实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架
- 用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片
- Scrapy 使用了 Twisted 异步网络框架来处理网络通电讯,可以加快下载速度;且其中包含了许多中间件接口,可以灵活的完成各种需求(所谓异步网络框架,就是可以并发很多请求,相当于多线程机制)
2、Scrapy 架构
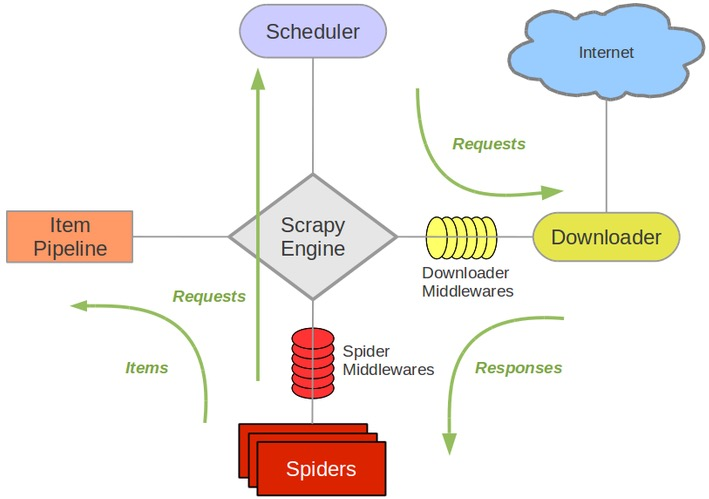
2.1 Scrapy 架构组件
- Scrapy Engine(引擎),只负责Spider、ItemPipeline、Downloader、Scheduler之间的相互通讯,整个架构中的所有信号都要由引擎发布
- Scheduler(调度器),负责调度请求,主要可以实现以下两个功能:
- 调度请求:接收引擎发送的所有Request请求,并按照一定方式进行整理排列,入队,然后依次出队列,请求就交给下载器进行下载,如图所示;(在Request请求出队列时,实际上是调度器先把请求交给引擎,引擎在把接收到的请求交给下载器)
- 去重:调度器能够识别重复的请求,不进行重复处理;
- Downloader(下载器),负责处理引擎发来的请求,并将下载到的Responses响应文件返回给引擎
- Spider(爬虫),就是我们自己需要写的爬虫文件,处理引擎传来的Responses响应文件,从中分析提取数据
- item字段需要的数据:我们自己定制的字段,可以理解为字典,我们定义了其中的键,需要将值存入item字段中,然后将其交给管道文件存储
- 需要跟进的URL数据:例如子网页,将其构建成一个请求,交给引擎,再次调度器
- Item Pipeline(管道),负责处理从Spider中获取的item字段,并进行后期处理
- Downloader Middlewares(下载中间件),引擎和下载器之间的组件,可以自己定制来扩展下载功能,例如在下载之前预先加入代理来处理请求
- Spider Middlewares(Spider中间件),引擎和Spider之间的组件,用于处理引擎和爬虫之间的通信(即从引擎传到Spider的Responses响应文件,从Spider传到引擎的Request请求),由于大部分工作在Spider中完成,因此很少用到Spider中间件
2.2 Scrapy 运作流程
- 引擎首先向Spider询问想要爬取的网站
- Spider中包含了爬虫需要爬取的URL地址,通过引擎将其交给Scheduler调度器
- Scheduler调度器接收到引擎传来的Request请求进行处理,入队,并按顺序通过引擎将请求发送给下载器
- 下载器接收到引擎传来的请求后,按照自定义的下载中间件设置处理:
- 将下载成功的Response响应文件通过引擎传送给Spider;
- 将下载失败的Request通过引擎回传给Scheduler调度器,重新进入请求队列,等待后续处理;
- Spider从引擎传来的Response响应文件中分析提取数据:
- 获取到的Item数据:通过引擎进入管道文件
- 需要跟进的URL:通过引擎进入Scheduler调度器
- Item Pipeline对接收到的Item数据进行后期处理
- 停止条件:当Scheduler调度器中的请求队列为空,爬虫结束(对于下载失败的URL会重新入队,不会被丢弃)
2.3 Scrapy 框架安装
Windows系统:
Mac系统:(有Python环境和pip安装模块)
1.安装homebrew(如果有,跳过)
ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
2.安装 wedget(如果有,跳过)
brew install wget
3.安装 Scrapy
sudo -H pip install Scrapy
Ubuntu操作系统:
2.4 Scrapy 基本命令介绍
Scrapy安装完成后在命令行输入scrapy,如果显示如下,说明Scrapy框架安装成功
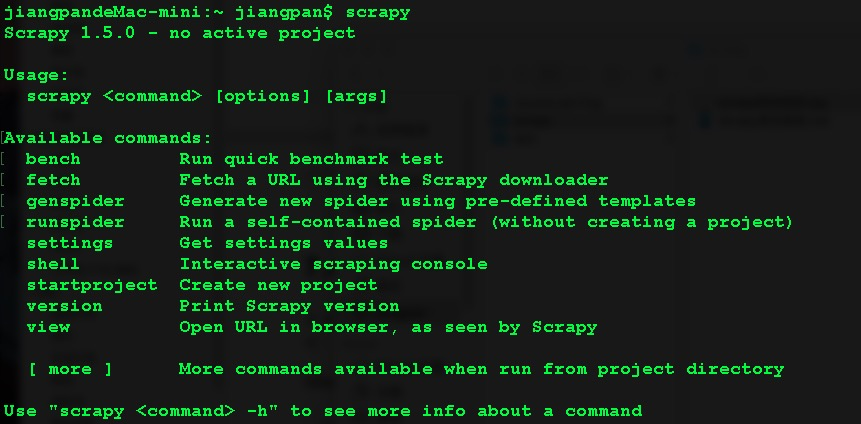
上图中部分命令的解释和命令调用如下:
Scrapy 1.5.0 - no active project //Scrapy版本
Usage:
scrapy <command> [options] [args] //Scrapy命令调用格式
Available commands: //可用的命令
//查看爬虫性能,例:scrapy bench
bench Run quick benchmark test
//给出URL地址,然后去下载,例:scrapy fetch "http://www.baidu.com/"
fetch Fetch a URL using the Scrapy downloader
//创建一个爬虫,例:scrapy genspyder 爬虫名 域名
genspider Generate new spider using pre-defined templates
//启动一个爬虫,可以用该命令启动一个不是用Scrapy写的爬虫
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
//开始一个新的爬虫项目,例:scrapy startproject 爬虫工程名
startproject Create new project
//Scrapy版本,例:scrapy version
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy <command> -h" to see more info about a command
2.5 Scrapy 的入门Demo
以下是跟着传智播客老师写的第一个Scrapy爬虫的过程,这个过程帮助我进一步理解了Scrapy架构。
-
创建一个爬虫项目:
打开命令行,cd进入到自己的项目文件夹,输入如下命令:
scrapy startproject techInfo //开始一个Scrapy爬虫项目 scrapy genspider dwTechInfo "itcast.cn" //创建一个爬虫项目创建成功命令行显示如下:

爬虫创建成功命令行显示如下:

这时,项目就创建好了在当前目录下就会多出一个叫techInfo的文件夹,cd进入到techInfo文件夹,输入如下命令查看工程文件结构:
"find . -print | sed -e 's;[^/]*/;|____;g;s;____|; |;g'"文件结构查看命令是经常要用到的命令,为了简化该命令,可以去设置.bash_profile文件(如果没有用touch命令创建一个),打开文件在最后一行插入以下命令
//将查看文件结构的命令简化为tree(tree也可以换成其他命名) alias tree="find . -print | sed -e 's;[^/]*/;|____;g;s;____|; |;g'"保存后关闭,用source命令激活之后就可以用tree命令来查看当前目录下的文件结构了。当前爬虫工程techInfo目录的文件结构如下图。
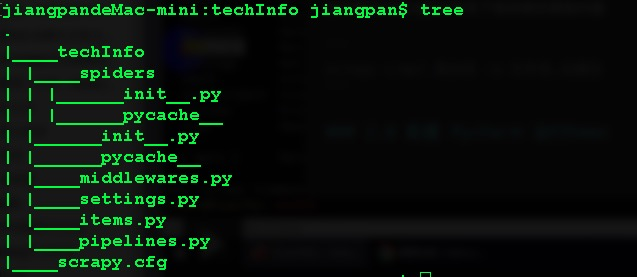
在当前目录下有一个与爬虫工程名字相同的techInfo文件夹和一个scrapy.cfg文件,其中在techInfo文件夹下有一个spiders文件夹和一系列的Python文件,完美契合了Scrapy架构:
-
techInfo文件夹
- spyders文件夹:
- dwTechInfo.py:爬虫文件
- _ init _.py:初始没有任何内容,但不能删(我也不知道为什么)
- middlewares:爬虫中间件
- settings.py:爬虫的设置文件,爬虫启动后按照设置文件的设置运行
- items.py:在该文件中设置item字段,用于存储爬取得到的信息
- pipelines.py:管道文件,处理接收到的item数据
- spyders文件夹:
-
scrapy.cfg:包含了爬虫工程的基本配置信息,如下
[settings] default = techInfo.settings //setting文件的位置 project = techInfo //爬虫工程名称
对于第一个Scrapy爬虫项目,爬虫设置按照默认设置,同时不使用任何中间件,item数据在爬虫文件中直接处理,因此可以暂且先只关注 items.py和dwTechInfo.py 两个文件。
-
-
编写代码
-
明确爬虫目标:
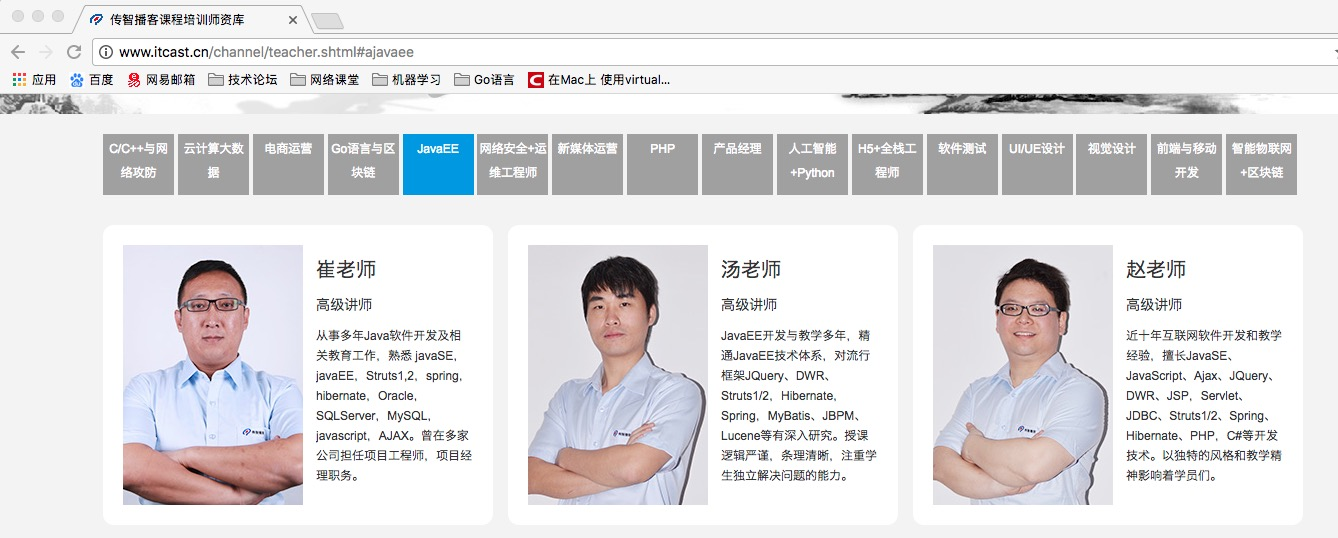
如图所示,爬取目标是读取网页中的老师的名字、职称和个人信息,将其保存在json或者xml文件中。明确了目标后,找到 item.py 文件,编写代码如下:# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy # 定义一个item数据类,用于保存爬虫提取到的item数据 class TechinfoItem(scrapy.Item): # define the fields for your item here like: # item数据中的name字段:用于保存老师的名字 # 其中scrapy.Field()是Scrapy框架中用于创建一个字段的方法 name = scrapy.Field() # 保存老师的职称 title = scrapy.Field() # 保存老师的个人信息 info = scrapy.Field() -
编写爬虫文件 dwTechInfo.py :
爬虫创建成功后自动生成的爬虫文件内容如下:# -*- coding: utf-8 -*- import scrapy class DwtechinfoSpider(scrapy.Spider): # 爬虫名 name = 'dwTechInfo' # 允许域名 allowed_domains = ['itcast.cn'] # 爬虫开始的URL地址 start_urls = ['http://www.itcast.cn/channel/teacher.shtml'] # 函数功能:从下载成功的response响应文件中分析提取数据 # 函数参数response: 下载器下载成功的响应文件 def parse(self, response): pass接下来只需要在parse函数中分析提取response响应文件的数据,添加提取响应文件数据的代码后,爬虫文件如下:
import scrapy # 导入Item数据类 from techInfo.items import TechinfoItem class DwtechinfoSpider(scrapy.Spider): # 爬虫名 name = 'dwTechInfo' # 允许域名 allowed_domains = ['itcast.cn'] # 爬虫开始的URL地址 start_urls = ['http://www.itcast.cn/channel/teacher.shtml'] # 函数功能:从下载成功的response响应文件中分析提取数据 # 函数参数response: 下载器下载成功的响应文件 def parse(self, response): root = response.xpath("//div[@class='li_txt']") items = [] for node in root: # 创建爬虫对象 item = TechinfoItem() item['name'] = node.xpath("./h3/text()").extract()[0] item['title'] = node.xpath("./h4/text()").extract()[0] item['info'] = node.xpath("./p/text()").extract()[0] items.append(item) return items # print( response.body ) # pass
-
-
运行爬虫
-
命令行运行爬虫:执行如下命令运行爬虫并将爬虫获取的内容保存
# scrapy crawl 爬虫名 -o 文件名 scrapy crawl dwTechInfo -o teacher.json -
配置 Pycharm 运行爬虫:
-
在Pycharm中打开爬虫项目,在当前爬虫项目的解释器中安装scrapy框架,点击左下方的加号,在弹出的搜索框内输入scrapy,点击Install Packages,完成scrapy框架安装,安装成功如下图所示
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c3GhMZss-1569639517522)(https://img-blog.youkuaiyun.com/20180421134403710?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvc21hcnRXZXN0YnJvb2s=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)] -
在当前爬虫项目下添加 begin.py 文件(注意begin文件所在位置)
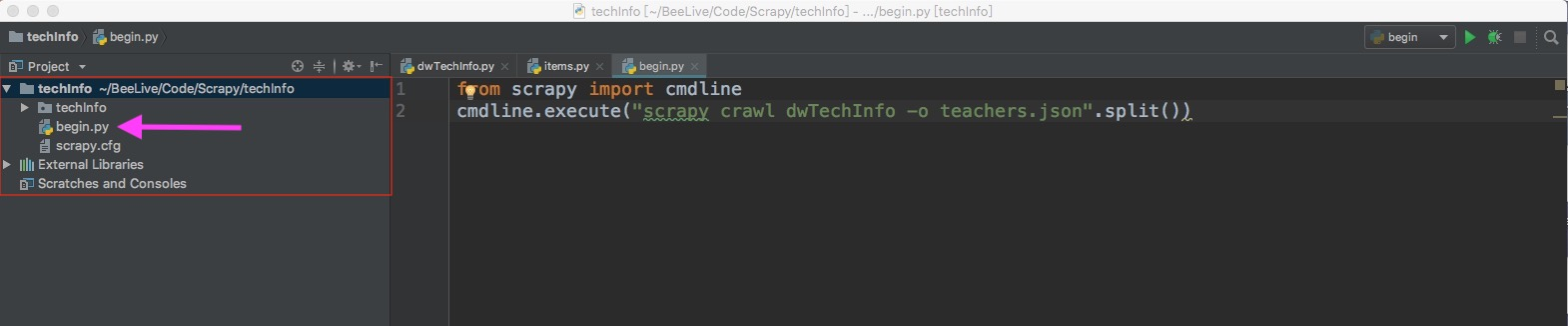
-
在begin.py文件中输入以下命令:
# 导入命令行 from scrapy import cmdline # 命令行执行(之前一模一样的运行爬虫命令) scrapy crawl dwTechInfo -o teachers.json cmdline.execute("scrapy crawl dwTechInfo -o teachers.json".split()) -
配置PyCharm
点击菜单栏中的Run->Edit Configurations,点击左上角的加号添加一个Python模块并在name框中为新建的Python模块起一个名字(笔者直接命名为begin),在script path中选择之前建立的begin.py,Working dirctory选择爬虫项目的路径(最外层的techInfo),如下图所示。最后点击左上角的运行按钮,运行爬虫
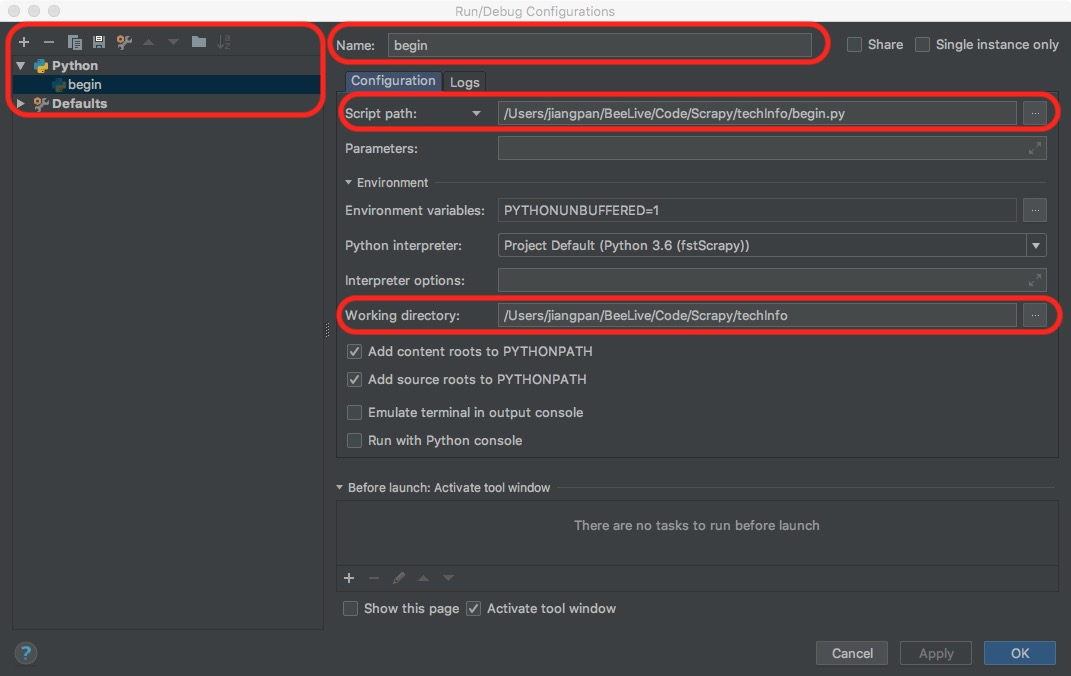
-
-

















 8576
8576

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









