




上一篇文章简单配置了一下 Spyder 工具窗口,现在开始进入开发阶段。我也是刚开始学习,难免出现笔误和理解不当的地方,欢迎指正:)。我目前主要的学习资源是 Scrapy 官方文档 以及 百度,个人比较喜欢去官网,虽然全英文,学习起来比起看别人的中文博客要慢很多,但是毕竟官网上给出的解决方案都是保持更新的,现在的很多博客都是一两年前的文章,随着版本跟新很多方案可能不再适用,所以我一边学习,一边更新博客,尽量语言简洁,不扯duzi,但又尽量 step by step,提高内容的实用性。
为了使用 Scrapy 框架开发,同时尽量减少学习阻碍,下面给出一份大致的 Scrapy 框架流程。
首先,查看 Spyder 上已经创建好的项目的结构。
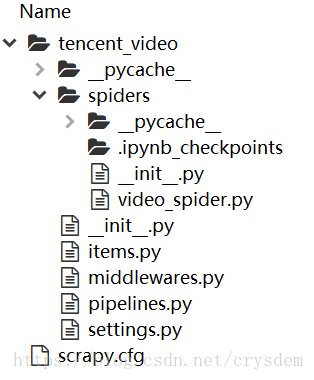
经常编辑的文件就是其中的:
scrapy.cfg
items.py
piplines.py
settings.py
video_spider.py # 这是你用模板创建出来的爬虫文件Scrapy 大致流程是:
- items.py 想要爬取的页面中的内容,比如对于腾讯视频,我想要爬取网页上列出的电视剧的名字和豆瓣评分
- video_spider.py 爬虫本体,执行爬取过程,在哪个网页上爬取什么内容,返回到哪里,都要自己编写
- piplines.py 处理返回结果,爬虫爬完后返回的结果如果想用 txt、excel、mysql 等格式存储,就在这里写
以上就是 Scrapy 框架的一个最简单版本的理解,其中的主要环节就是爬虫本体,它封装好了诸如 urllib 等依赖库,无需关心细节。使用 Scrapy 的感觉就像是一说到吃饭只要能够想到要用筷子(或者刀叉或者手等)把面前的米饭(面包、面条等)送进嘴里咀嚼后吞下去一样,问题就能够解决。而筷子(工具)从哪来、怎么做、好不好用等等细节无需关心,只要能够想到最外层(框架)的思路,问题就能够解决。这也就是框架的强大之处。
- 找到要爬取的内容
首先,去腾讯视频网站上查看网页结构,具体的方法非常简单,就是打开百度,搜素腾讯视频,进入官网,鼠标移动到电视剧上然后在显示出的小面板上点击全部电视剧即可。可能是因为网页进行了改版,现在想要查看所有的电视剧列表不太方便了,入口如下,在左边蓝色箭头位置。

点击最受好评后可以看到这样的页面。
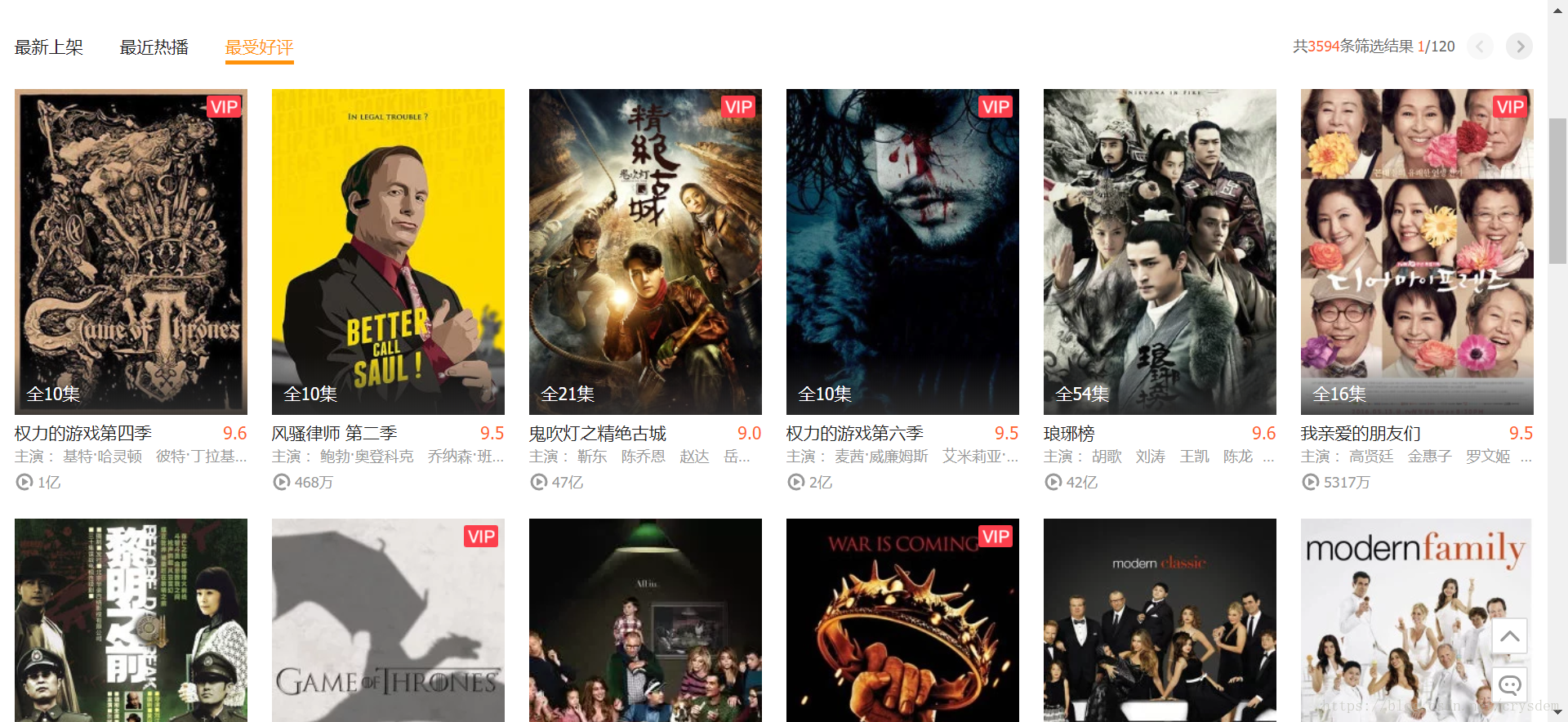
这样的页面结构比较清晰,每一页包含30个电视剧,每一个电视剧包含名称,豆瓣分数,主演,图片等等内容,而且可以想象,页面背后的源码应该也是比较规整的,不同的电视剧之间的源码结构应该都一样,注意这里我已经得到了第一个关键数据,就是这个页面的 url,https://v.qq.com/x/list/tv?offset=0&sort=16。使用右键查看源码,可以看到 html 源码非常多而且看起来比较杂乱,不过没关系, ctrl
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 491
491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









