




 本文探讨了基于G.723.1语音编码器的QIM隐写分析方法,通过PCA降维处理和SVM分类器,实现了对含密载体语音的有效检测。实验采用100个9秒语音片段,通过特征提取、分类模型训练和隐写检测,验证了方法的准确性和有效性。
本文探讨了基于G.723.1语音编码器的QIM隐写分析方法,通过PCA降维处理和SVM分类器,实现了对含密载体语音的有效检测。实验采用100个9秒语音片段,通过特征提取、分类模型训练和隐写检测,验证了方法的准确性和有效性。
一、思想
以G.723.1语音编码器为载体,针对QIM 隐写造成索引分布特征的改变,通过分布特征向量和转移概率矩阵进行了量化。由于分布特征向量和转移概率矩阵维数过高,会降低分类器的估计性能,因此使用 PCA 主成分分析法进行降维处理,在尽可能少丢失信息的基础上,减少了计算量,使得分类器对输入特征的判别更加有效。通过 LIBSVM 实现 SVM 分类器的判别作用,对五类待测样本进行大量实验。
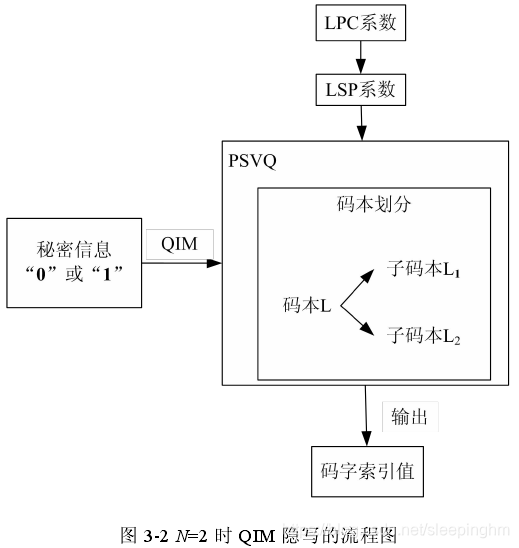
二、实验结构框1和隐写分析流程2: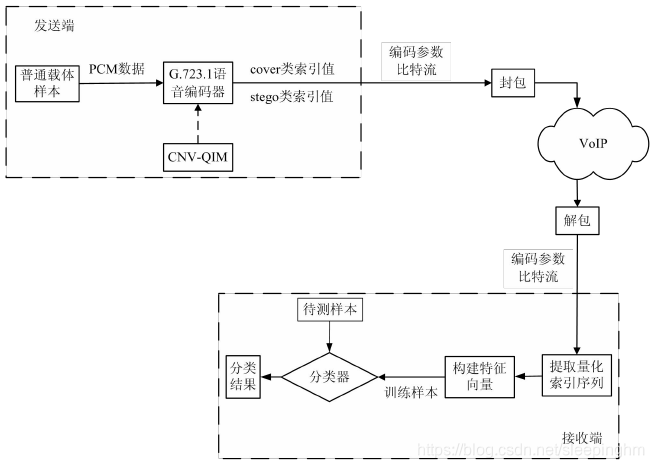
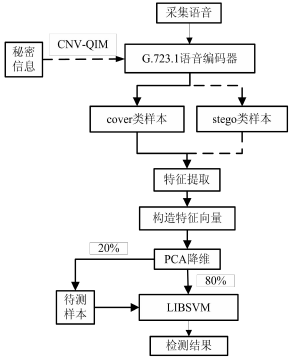
- 采集 100 个时长为 9s 的语音片段,量化后以 PCM 格式存储,输入 G.723.1语音编码器中,即可得到普通载体样本,记为“cover”类。
- 使用 CNV-QIM 隐写方法(二分码本)在采集的语音片段中嵌入秘密信息,获得与步骤 1 中相对应的含密载体语音样本,记为“stego”类。
- 提取所获得的两类样本的特征,构造特征向量,按照样本的类别标记每个向量。
- 使用步骤 3 获得的“cover”类和“stego”类特征向量各 80%作为训练样本,用来训练 SVM 分类器,得到特征向量的分类模型。
- 将“cover”类和“stego”类剩余的 20%特征向量作为待测样本,通过 LIBSVM来实现 SVM 分类器功能,对待测样本进行隐写检测,输出检测结果。
三、分类器介绍
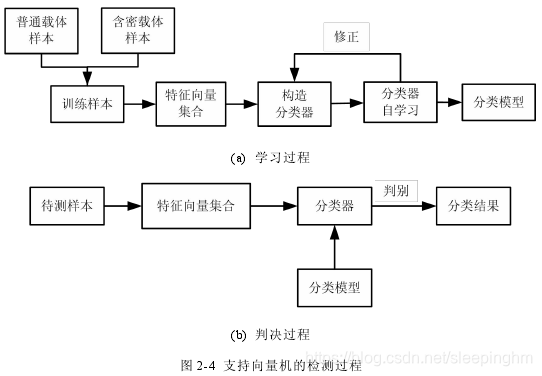
SVM 检测过程:
(1)学习:首先要将大量普通载体样本和含密载体样本组成训练样本,再对训练样本进行特征提取和选择,构成特征向量集,然后对分类器进行训练,最后得到分类模型。
(2)判决:首先提取待测样本的特征向量,然后分类器会依据分类模型判断待测样本是普通的载体样本还是含密载体样本
四、G.723.1编码器
G.723.1两种速率:5.3 Kb/s 和 6.3Kb /s。其中,6.3Kb /s 速率可以获得更好的语立质量,而 5.3 Kb/s 速率在保证语音质量的同时,可以为系统设计者提供更多的灵活性。
G.723.1编码器原理: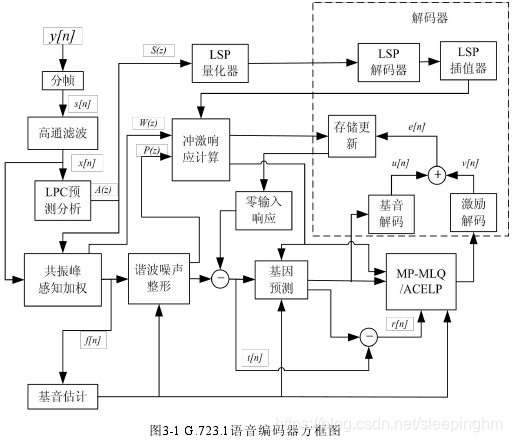
- 输入信号首先要通过高通滤波器,除去其中的直流分量,然后进行分帧处理,一帧语音信号被分为 4 个子帧,每个子帧 60 个样点,对每一个子帧计算 10 阶的线性预测LPC滤波器的系数。对最后一子帧的 LPC 滤波器系数用预测分离矢量量化器PSVQ进行量化,未量化的 LPC 系数用于构造短时感知加权滤波器,使用该滤波器对完整的一帧信号进行滤波,获得感知加权的语音信号。
- 通过加权语音信号,计算每两个子帧之间的开环基音周期 LOL。基音周期估计是针对 120 个样点长度进行的。基音周期的搜索范围是 18 个~142 个样点。之后,语音处理就针对每一个子帧 60 个样点进行的。
- 利用之前计算的基音周期构造谐波噪声整形滤波器。使用 LPC 合成滤波器、共振峰感知加权滤波器和谐波噪声整形滤波器生成一个冲击响应,之后的步骤会用到该冲激响应。
- 使用估计的基音周期 LOL 和上述冲激响应,使用 5 阶的基音预测器计算闭环基音预测器。该基音周期同开环基周期估计值之间有微小的差别。使用初始的目标矢量减去基音周期估计值得到差值。基音周期估计值和差值都传送至解码器。
- 最后,估计激励的非周期部分。具体的方法是:对 6.3Kb /s 的情形,使用多脉冲极大似然量化MP-MLQ激励;对 5.3Kb/s情形,使用代数码激励线性预测ACELP编码。
矢量量化过程:
语音信号输入G.723.1语音编码器后,先经过高通滤波、分帧等处理过程,对前一子帧、当前子帧和下一子帧构成的数据进行加窗,窗是长度为180个样点的Hamming窗,窗的对准当前子帧的中心,然后进行10阶LPC分析。
首先,对从窗口对准的信号中计算出 R[0]~R[10]共11个自相关系数。然后,应用一个白噪声纠正因子(1025/1024)对 R[0]进行修正,计算公式为 R[0]=R[0](1+1/1024),对于 R[1]~R[10]这10个自相关系数,分别乘以二项式窗口系数表中相应的值。最后,对每一个输入语音帧的4个子帧,使用Levinson-Durbin算法进行计算,获得4组10阶LPC系数。
LPC的合成滤波器: ,aij是LPC滤波器系数;i是子帧索引,取值为 0, 1, 2, 3。
,aij是LPC滤波器系数;i是子帧索引,取值为 0, 1, 2, 3。
LPC 系数有较大的波动,可能会导致滤波器不稳定,所以 LPC 系数并不适合直接量化,需要进一步转换。
在经过频带扩展后,通过在单位圆上搜索和过零内插的方法,将 LPC 系数转换成线谱对LSP系数(线谱频率LSF),对最后一个子帧的 LSP 系数进行预测分裂矢量量化PSVQ。
LSP 系数分为两个3维矢量和一个4维矢量,三个分裂矢量分别记为 f1,f2,f3,与之相对应的码本分别为L1,L2,L3,大小均为8比特,每个码本都拥有一个大小为 2^8=256的码字空间![]()
![]() 即
即![]()
根据最小误差准则,每个分裂矢量从相应的码本中选择最优码字,输出相应的码字索引,即为量化结果。
四、QIM隐写
码本划分算法:在矢量量化过程中从码本中选择最优码字的步骤,即将码本按照某一码本划分算法分为几个部分,而各部分互斥(相交为空集)。记某一码本为 L,分为 N 个子码本 L1,L2…LN,![]()
![]() 。
。 嵌入信息比特01,搜索最优码字的子码本分别为 L1、L2,接收端判断输出结果中的码字属于 L1 还是 L2,就可以知道嵌入的信息比特是“0”还是“1”。
嵌入信息比特01,搜索最优码字的子码本分别为 L1、L2,接收端判断输出结果中的码字属于 L1 还是 L2,就可以知道嵌入的信息比特是“0”还是“1”。
两个码字间的欧氏距离(最小为最近顶点):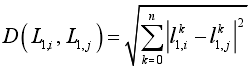 ,其中n表示码字中元素的个数,L1i L1j为两个不同码字。
,其中n表示码字中元素的个数,L1i L1j为两个不同码字。
互补邻居顶点算法CNV,对码本划分:
所有的码字分为不同的连通图,每个连通图中含有偶数个码字,每个码字和与它欧氏距离最小的码字(最近顶点)属于同一个连通图,对码字及其最近顶点进行相反的标记,使得他们位于不同的子码本中。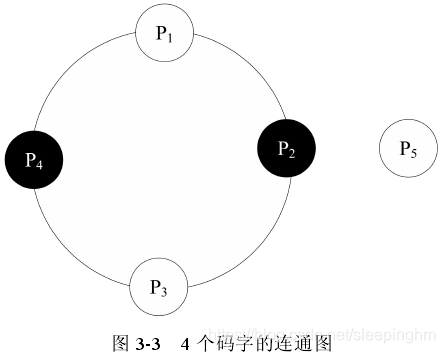 P1、P2、P3、P4 位于同一个连通图中,P1 的最近顶点是 P2,P2 的最近顶点是 P3,P3 的最近顶点是 P4,P4 位的最近顶点是 P1,而 P5 只是 P2 的相邻点,所以不属于这一连通图。因为码字及其最近顶点标记相反,所以若 P1 标记为 0,则 P2 标记为 1,同理得 P3 标记为 0,P4 标记为 1。
P1、P2、P3、P4 位于同一个连通图中,P1 的最近顶点是 P2,P2 的最近顶点是 P3,P3 的最近顶点是 P4,P4 位的最近顶点是 P1,而 P5 只是 P2 的相邻点,所以不属于这一连通图。因为码字及其最近顶点标记相反,所以若 P1 标记为 0,则 P2 标记为 1,同理得 P3 标记为 0,P4 标记为 1。
以二分码本为例,在 CNV-QIM 算法中,划分码本时每个码字需要进行两类判断,一类是判断码字属于哪个连通图,一类是判断码字是标记为“0”还是标记为“1”。连通图的序号 l=1,2,3…,码字(顶点)个数为 256,具体码本划分过程如下:
设连通图的序号 l=1,从码本中任取一个码字记为 X。
-
将码字 X 的连通图的序号设为 l ,码字 X 标记为 1,将 X 放入一个空集 A中。
-
将集合 A 的首个元素记为 Y,根据欧氏距离最小准则找到 Y 的邻接点,放入集合 B 中。
-
取 B 中的一个码字 Z ( Z ≠Y ),如果 Z 的连通图序号未设置,那么设 Z 的连通图序号与 Y 相同,标记 Z 与 Y 相反,将 Z 放在集合 A 的最后。反之,进行下一步。
-
遍历集合 A 中所有元素,进行上一步的操作。
-
从集合 A 中删除元素 Y,若此时 A 不为空,则进入第 2 步,否则退出算法。使所有顶点都标记了。
-
连通图的序号设为 l=l+1,从码本中任取一个未设连通图序号的码字,将它置为 X,如果 X 为空,表示顶点已全部标记,则退出算法;若 X 不为空,则需返回步骤 1。
经过码本划分后,整个码本被分为标记为0和标记为1的两个子码本,而且码字及其最近顶点一定分别位于两个子码本中,从而减小了因为隐写而产生的失真。
CNV-QIM可以保证原码书划分后每个码字和它最邻近码字属于不同的分组,从而使得嵌入机密消息后局部附加量化失真的极大值相对其它划分方式取得极小,减小了 隐写带来的语音失真,提高了隐蔽性。
QIM 引起码字分布特征的变化
经过 CNV-QIM 隐写,码字搜索范围发生了变化,未进行隐写时,分裂矢量在一个码本(256 个码字)中搜索最优码字;进行隐写后,码本被分为两个子码本,嵌入秘密信息比特“0”和“1”时,分裂矢量分别在其对应的子码本(128 个码字)中搜索最优码字。
假设输入N 个G.723.1语音帧,则这段语音输出的量化索引序列 QIS为![]()
![]()

表中一列数据表示一帧语音输出的 3 个量化索引序列,而表中一行数据表示 N 帧语音的第 i 个量化索引序列 QISi 的 N 个值。
与载体语音的量化索引序列相比,载密语音输出的量化索引序列会发生变化。如果同一帧“cover”类和“stego”类的索引值相同,则表示载密语音和载体语音在进行矢量量化的过程中选择的最优码字相同;如果同一帧“cover”类和“stego”类的索引值不同,则表示载密语音和载体语音进行矢量量化时选择的最优码字不同。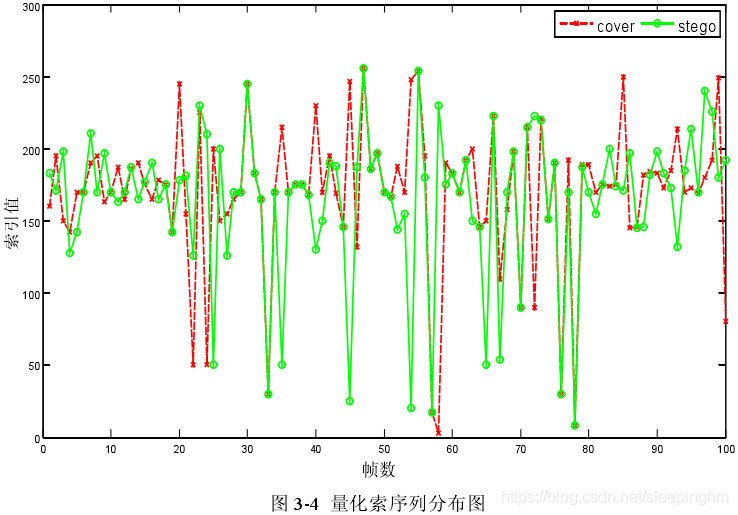
从量化索引序列的变化中主要可以提炼出两个关键点:一是从纵轴的角度看,每个索引值出现的概率发生了变化;二是从横轴的角度看,因为语音信号具有短时不变性,而相邻帧之间具有一定的相关性,所以每个索引的出现会与其相邻索引之间相互影响。通过统计学的相关知识可以对索引值分布特性的变化进行量化,就可以对 QIM 进行隐写分析。
索引的分布特性的量化
索引的分布概率:假设N帧G.723.1语音输出的某一个量化索引序列![]()
索引序列中任意一位索引值Sj可以取得 0~255 之间任意一个整数值,可表示为![]()
2.索引的概率![]() ,
,![]() 表示在 N 个语音帧中索引Sj=k出现的次数。
表示在 N 个语音帧中索引Sj=k出现的次数。
3.索引的概率分布矩阵 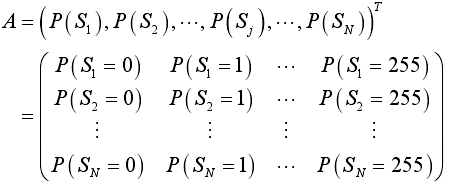 ,维度256*256,代表 N 帧语音信号的索引在其每种可能的取值(共256 种)上的概率,表征索引分布的长时特征。
,维度256*256,代表 N 帧语音信号的索引在其每种可能的取值(共256 种)上的概率,表征索引分布的长时特征。
4.索引的转移概率矩阵:将选择最优码字的过程视为离散时间随机过程,每个码字的出现仅与它前一码字有关:![]()
5.马尔可夫转移概率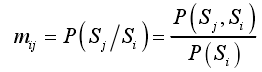 ,其中
,其中![]() 。
。
6.马尔可夫转移概率矩阵 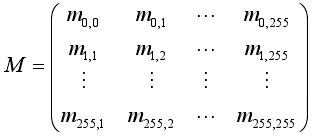
7.降维处理:原始矩阵的维数过高,将会使得训练误差过小,不利于分类器对样本统计特性进行估计,所以通过主成分分析PCA法对概率分布矩阵A和马尔可夫转移概率矩阵M进行降维处理。(PCA设法将具有相关性的大量变量,转化成一组较少的互不相关的变量,然后按照一定标准从中选取最能代表原始数据的变量,反映原始数据绝大部分特点的变量被称为主成分,每个主成分所含信息互不重叠)
主成分分析的计算步骤:
- 计算协方差矩阵C:
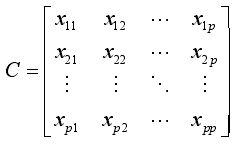 其中,
其中,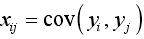 ,
,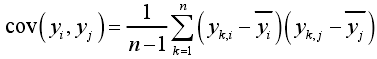
yi 和yj 分别表示矩阵 Y 中第i列和第j列的列向量。 - 计算协方差矩阵 C 的特征值和相应的特征向量:用QR法或雅克比法求出协方差矩阵 C 的特征值,从大到小的顺序排列
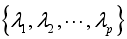 ,与之相应的特征向量记为
,与之相应的特征向量记为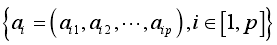 ,a1,a2...分别被称为第一主成分,第二主成分...
,a1,a2...分别被称为第一主成分,第二主成分... - 选择重要的主成分:贡献率是指某个特征值占全部特征值的比例
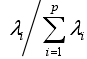 ,选取几个主成分,主要根据主成分的累积贡献率来决定,为了保证选取的主成分能够反映原始数据绝大部分特点,选前 120 个特征向量能够充分反映原始数据的特点。
,选取几个主成分,主要根据主成分的累积贡献率来决定,为了保证选取的主成分能够反映原始数据绝大部分特点,选前 120 个特征向量能够充分反映原始数据的特点。 - 降维处理:选择完主要成分后,可以得到 p×120 维特征矩阵,把原始矩阵 Y 与特征矩阵相乘,就得到降维之后的 n×120 维矩阵,算法结束。降维之后概率分布矩阵 A 变成 N×120 维矩阵 A′,马尔可夫转移概率矩阵 M 变成256×120 维矩阵 M′,矩阵 A′和矩阵 M′分别表征索引的长时特征和索引之间的相关性。
五、评价标准
TPR=密载体正确判别为含密载体/所有含密载体样本
FPR=普通载体错误判断为含密载体/所有普通载体样本的数量
FNR=含密载体错误判断为普通载体样本/所有含密载体样本
可靠性用ROC曲线判断,以虚警率(FPR)和检测率(TPR)为横、纵坐标轴。
检测率 TPR 越高,虚警率 FPR 和漏检率 FNR 越低,全局检测率 Pr 越高,ROC靠近左上,隐写分析方法的准确性越好。
四、参考文献





















 5086
5086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











