



 本文探讨了过度拟合问题,包括其原因(underfit和variance),以及三种解决策略:增加训练数据、特征选择和正则化。特别介绍了线性回归和逻辑回归中的正则化过程,以及如何选择合适的正则化参数lambda。
本文探讨了过度拟合问题,包括其原因(underfit和variance),以及三种解决策略:增加训练数据、特征选择和正则化。特别介绍了线性回归和逻辑回归中的正则化过程,以及如何选择合适的正则化参数lambda。
文章目录
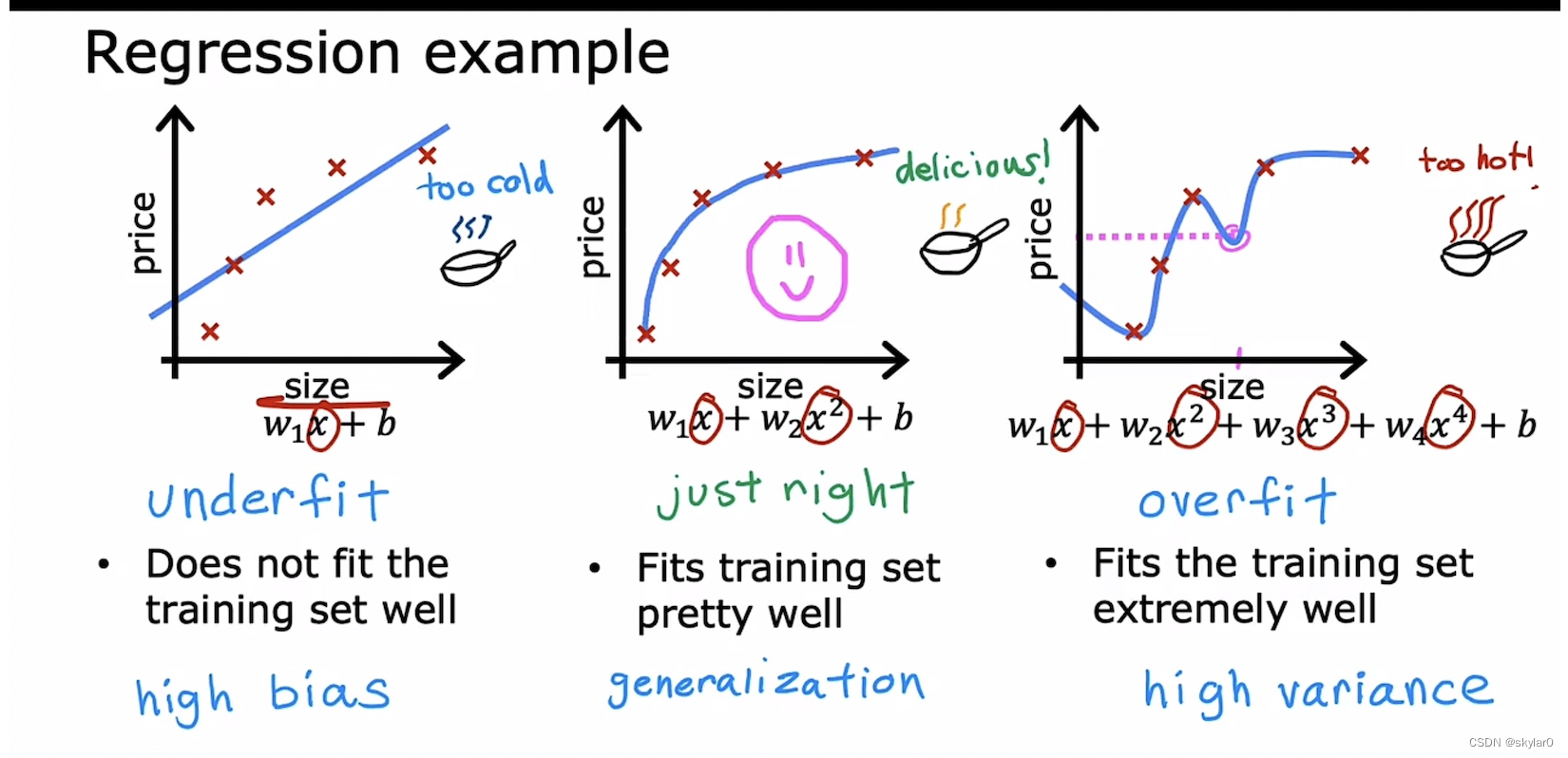
1. 过度拟合
1.1 underfit
- 有很高的bias
- 并不能很好的fit我们的training set
1.2 generalization
- 可以很好的预测不在training set里的数据。
1.3 overfit
- cost 几乎等于0
- 无法推广
- 算法有high variance高方差(overfit的另一种术语)。完全fit training set,如果有一个training set 稍微有点不同就会得到完全不同的预测。
1.4 对于classification也一样

2. 如何解决过度拟合(3种)
- 收集更多的training set
- 选择更合适的feature(x)(减少/增加)
- regularization: 减小parameter的size。
(1)保留所有的feature但要防止feature产生过大的影响。
(2)b不需要regularization,b的变化几乎不影响。
3. regularization
- lambda:regularization parameter,lambda > 0。
- 使用第一个term来fit data。
- 使用第二个term来minimize w。

- 如何选择lambda:
- =0 : f(x) = b
- 太大:f(x) overfit
3.1 用于linear regression的regularization
-
偏导后面有过程。

-
重新排序wj。前一项非常接近 wj。

- 正规项求偏导:最后等于lambda * wj / m,求和项展开,只有wj项会保留。

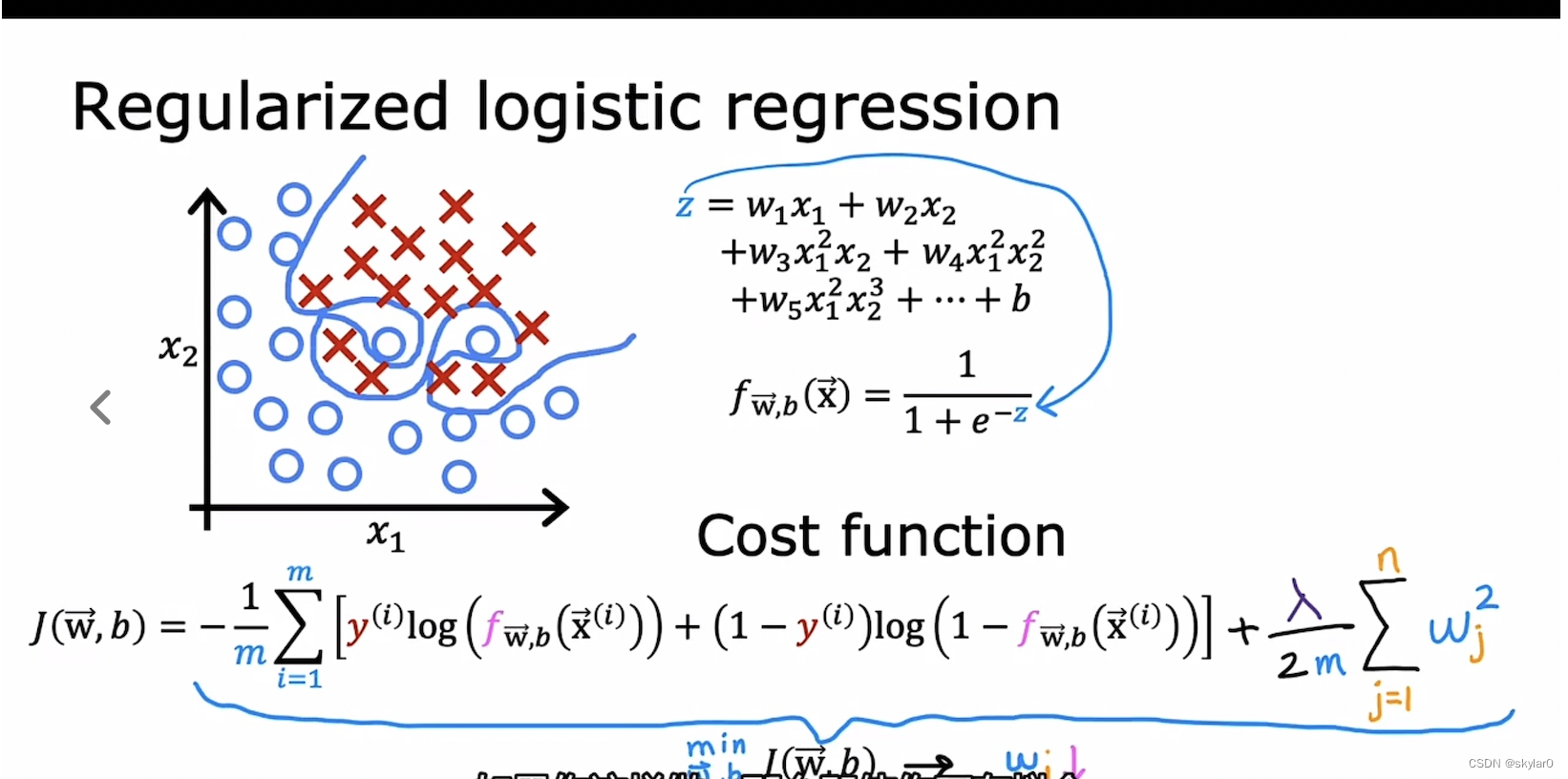
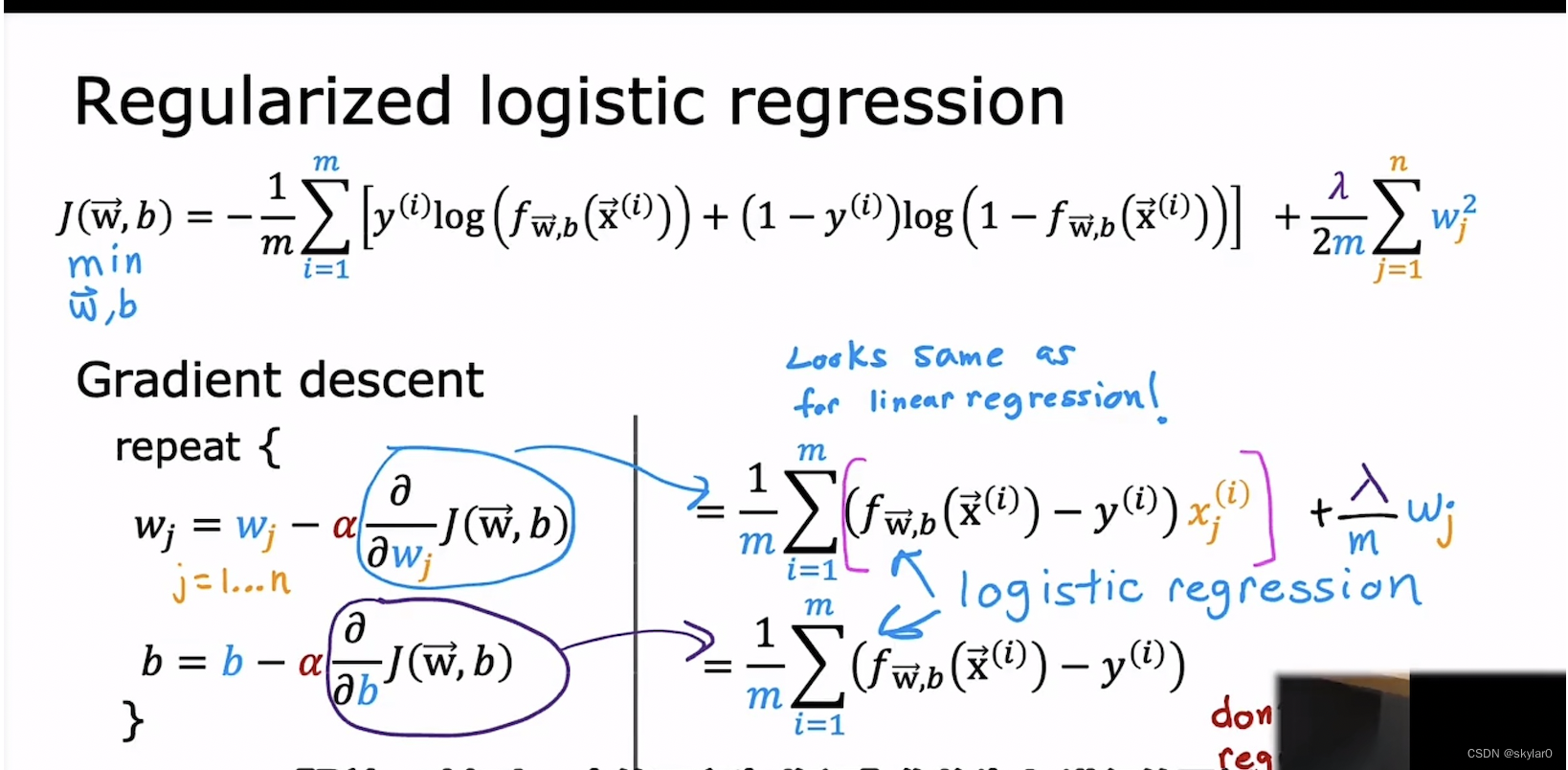
3.2 用于logistic regression的regularization
-
加上regularization term会使得预测的曲线更加的平滑,避免overfit
-
注意:b 不做regularization。

















 4205
4205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









