



 本文介绍了有监督学习(包括回归和分类)与无监督学习(聚类、异常值检测和降维)的概念,强调了两者在数据处理中的关键区别:有监督学习依赖于标记数据,无监督学习则需自行发现数据结构。
本文介绍了有监督学习(包括回归和分类)与无监督学习(聚类、异常值检测和降维)的概念,强调了两者在数据处理中的关键区别:有监督学习依赖于标记数据,无监督学习则需自行发现数据结构。
文章目录
1. 什么是有监督学习和无监督学习
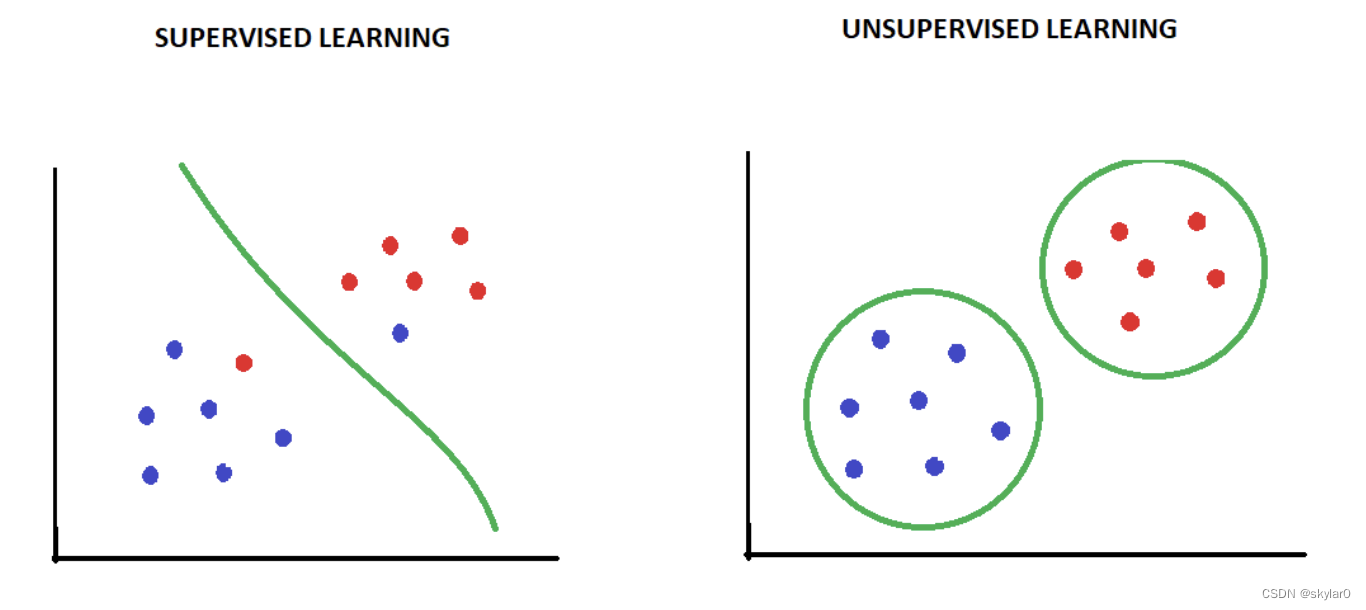
有监督学习和无监督学习一字之差,关键在于是否有监督,也就是数据是否有标签。
2. 有监督学习(有标签)
-
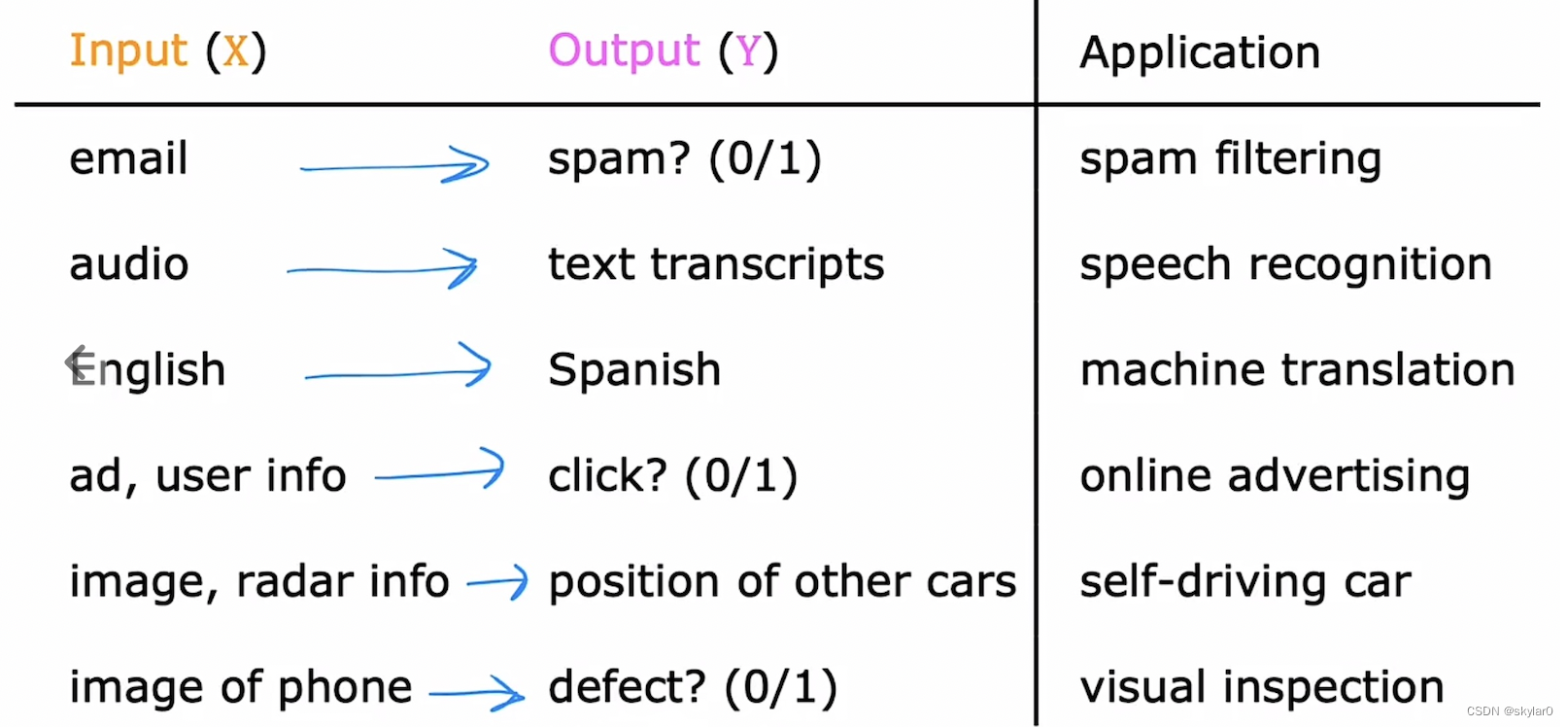
监督学习的主要目标是利用一组带标签的数据,学习从输入到输出的映射,然后将这种映射关系应用到未知数据上,达到分类或者回归的目的。
-
主要分为两类:回归(regression)和分类(classification)
2.1 回归 regression
- 用来预测number的,从无限多种可能性的结果中预测。如:预测房价…
2.2 分类 classification
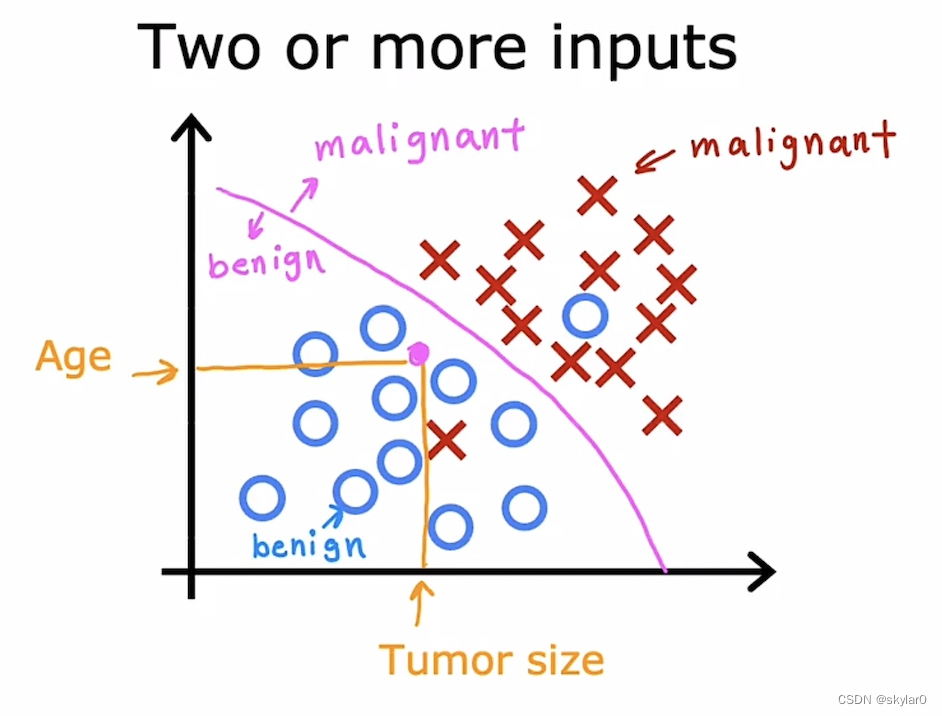
- 用来预测categories,从一小组有限的可能性结果中预测。如:良性/恶性1型/恶性2型,0/1, cat/dog…
3.无监督学习(无标签)
- 不依赖任何标签值,通过对数据内在特征的挖掘,找到样本间的关系,如聚类、降维。
- 数据通常只跟随x input,没有y输出值的label。算法需要自己去找出data的structure。
【没有标签的,需要机器自己去将数据分类】 - 主要分成2种:聚类和降维。
3.1 聚类算法 clustering algorithm
- 聚类问题:将相似的data分到同一组去。
- 如:百度搜索时,会将跟关键词有关的数据都显示出来。
3.2 异常值检测anomaly detection
- 找出unusual data points。
- 在金融系统的欺诈检测很有用。
3.3 降维 dimensionality reduction
- compress data只使用fewer number。

















 1963
1963

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









