 Python爬虫与信息提取
Python爬虫与信息提取





 本文为嵩天老师《Python网络爬虫与信息提取》课程的笔记精华,介绍使用BeautifulSoup进行网页解析的方法,包括标签解析、遍历及常用解析器如lxml的使用。
本文为嵩天老师《Python网络爬虫与信息提取》课程的笔记精华,介绍使用BeautifulSoup进行网页解析的方法,包括标签解析、遍历及常用解析器如lxml的使用。
本文主要是 MOOC嵩天老师的《Python网络爬虫与信息提取》课的笔记以及总结。
Bs 的标准代码其实很简单,第一行开启bs
第二行 解析,第一个参数是要解析的html格式的信息,第二个是解析这锅汤要用到的解析器

BeautifulSoup 的基本元素
只要提供的是标签类型的解析内容,就可以进行解析
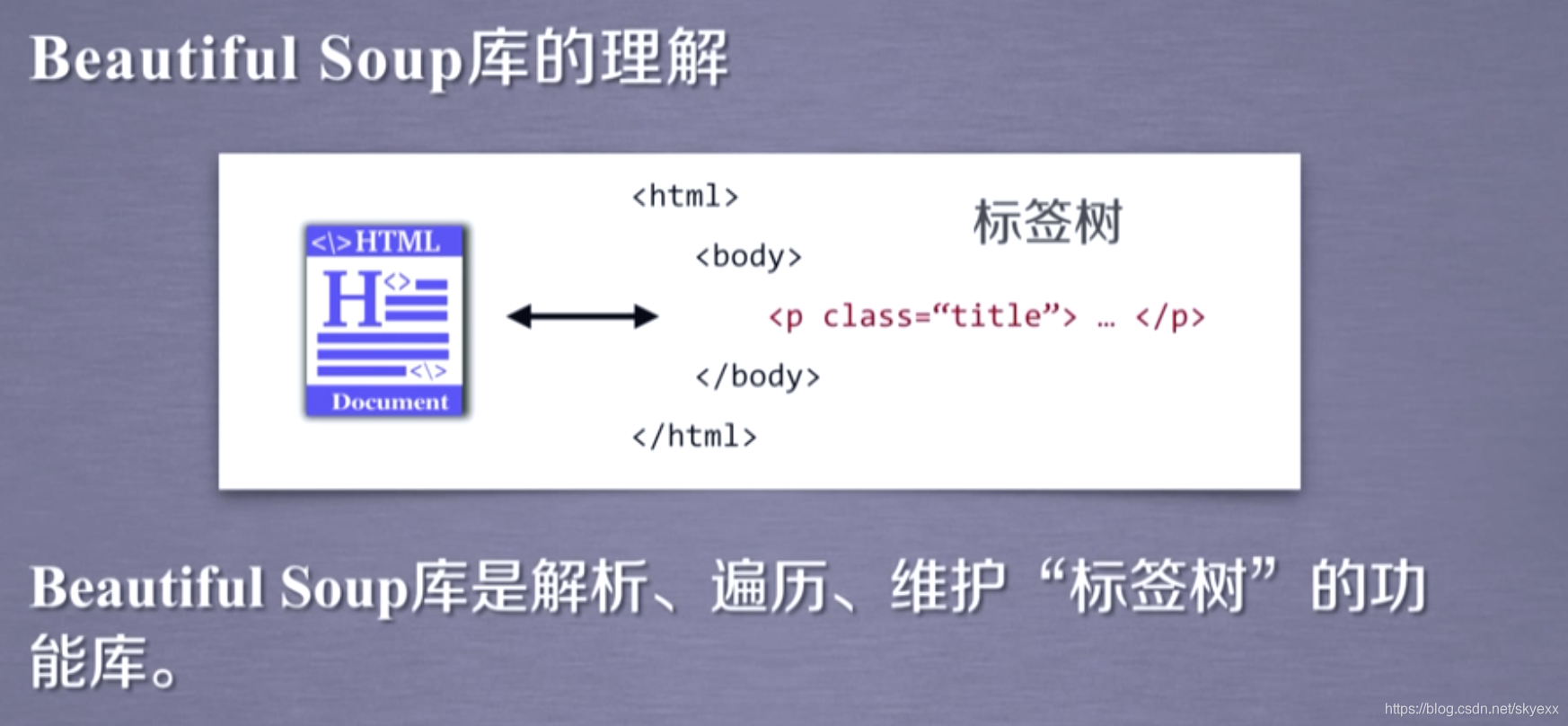
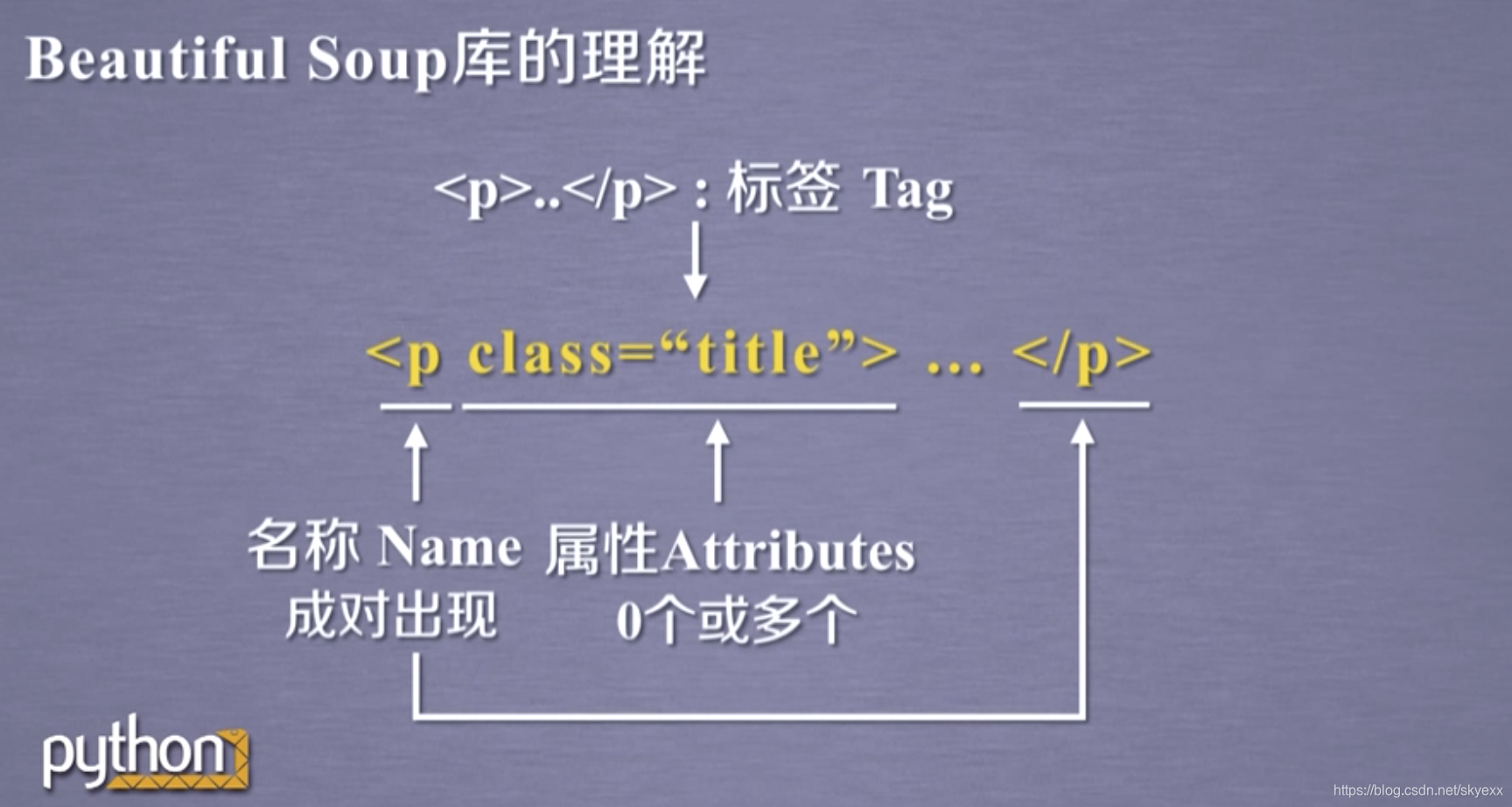
标签的基本结构,标签里面的域是以键值对的形式存在的
可以讲bs的作用理解为把标签树转化为beautiful型的变量

其他的一些解析器,lxml,xml解析器只要安装 一下lxml

bs中的基本元素

遍历标签的方式
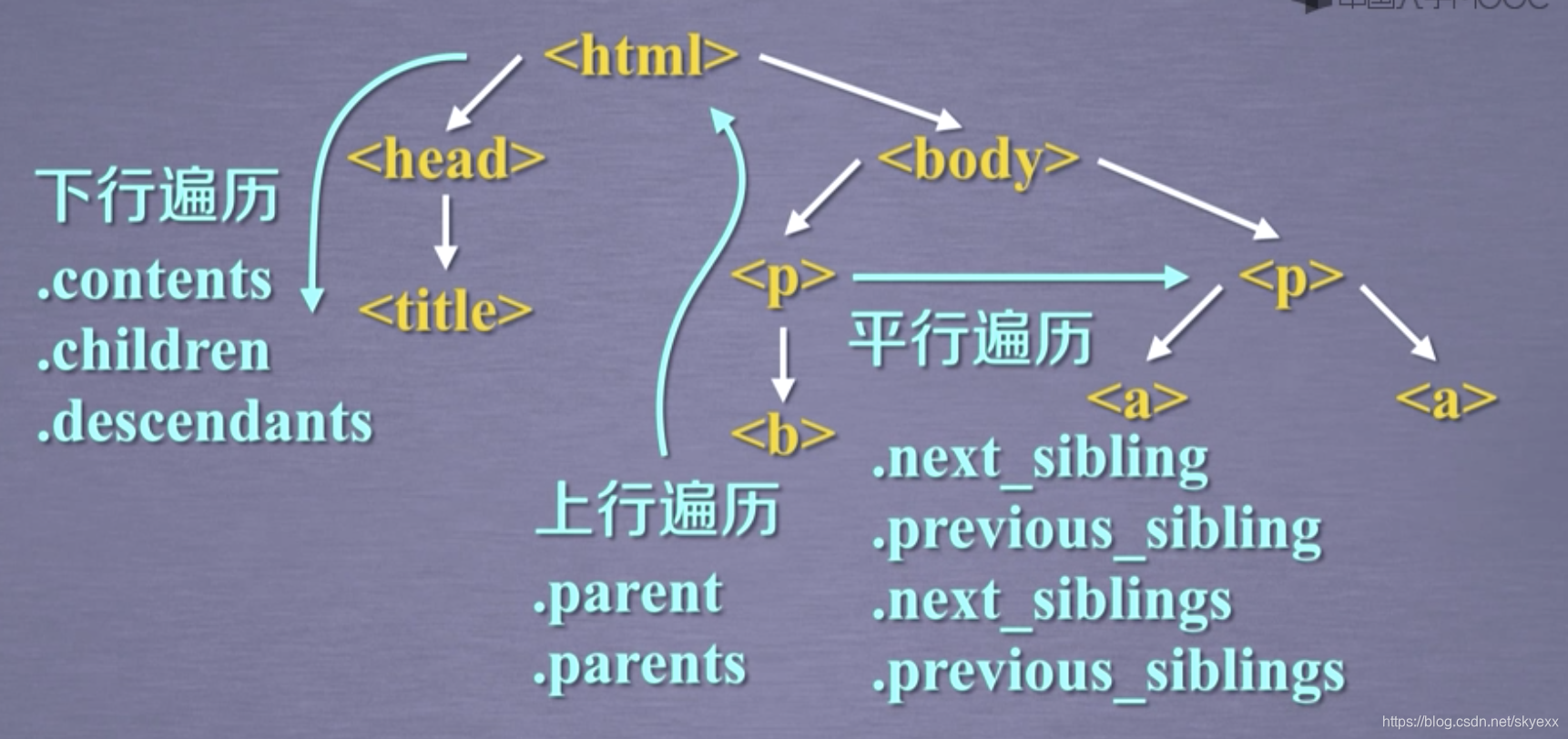 单元小结
单元小结


















 1729
1729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









