



 探讨微服务环境下数据查询的不同实现方式,分析各自优劣,并提出全局最优解。强调单一职责原则,推荐事件溯源模式同步数据。
探讨微服务环境下数据查询的不同实现方式,分析各自优劣,并提出全局最优解。强调单一职责原则,推荐事件溯源模式同步数据。

站在不同的角度看待同一个问题,会得出不同的结论。对于程序的实现也一样。
一、查询功能实现的罗生门
不久前公司遇到一个场景,也是微服务状态下肯定会遇到的一个场景(以下对比真实情况有所抽象和改编):
某一个服务A,需要实现一个较为边缘的功能;
这个边缘功能需要用到另外一个服务B管控的大量数据用于展示;
同时对于展示的数据需要打一个标志(更新),该标志后续需要用于过滤显示的数据。
对于这个功能需求,实现无非包含三个大方向:
实现一、服务A直接利用服务B的数据库进行查询及更新;
实现二、服务A的数据库导入服务B里所有需要的数据,然后服务A在其自身的数据库中对数据进行更新;
实现三、服务A自行存储打标志信息(更新),需要B的数据时直接向服务B实时查询,服务A在应用代码中合并多方数据得出结果后,向用户反馈。

对于不同的实现,各方有不同的态度(自行瞎编)。
对于实现一:
服务A开发人员:这个实现极好,最简单、最省事;
服务B开发人员:为啥我们的数据库要存跟我们服务职责无关的数据?这会导致我们的代码腐化。
对于实现二:
服务A开发人员:实现这么个简单功能,还要导入维护这么大量的数据,太麻烦;
服务B开发人员:嗯,数据给你,你爱怎么折腾就怎么折腾。
对于实现三:
服务A开发人员:数据分布在不同的库,在应用中合并处理得到对应结果的过程的开发复杂度高且代码不够优雅;
服务B开发人员:要给你提供查询接口,不是不可以,但是如果每个服务有相关查询需求我们都要协助改这也很烦。
二、如何破局?
服务A、服务B开发人员站在他们自己的角度分析这些实现得出的这些想法都是正确的。但如果只站在自己的立场,互不让步的话,事情是无法推进的。
个人认为这个问题应该
跳出自身立场,站在更高角度,选出全局收益最高的实现
全局收益 = Σ局部收益 - Σ局部代价对于上述具体场景,站在全局得失角度的考虑,个人觉得应该是这样的:
这是一个边缘功能,使用的人数和频率不高,我们实现该功能的代价一定不能高于其产生的收益;
方案一在服务B的数据库中存储与其无关的数据,违反单一职责原则,虽然该实现整体很简单,但其会导致服务B代码/数据腐化,不利于服务B的后续演化;
有人或许会说,只是一个简单的标志,不至于;
但如果每个其他服务都要求服务B为其进行改造,存储服务B不应该存储的数据,那服务B还怎么重构演化?这不就变回单体应用了么?
方案二将所需数据从服务B全部导入服务A的话,除却存储服务B数据所需的物理资源消耗外,无论是全量批量导入、增量批量导入还是流式导入我们都需要关心其导入到服务A中数据的正确性。尤其是跑批,我相信是无数开发和运维的噩梦。因此个人觉得方案二的投入可能已大于其能获得的收入;
对于方案三。
要求服务B提供对其自身数据的查询接口,只要其查询接口是一个较为通用的,而并非对服务A专门定制的话,其本应属于服务B的职责,不存在代码腐化;
要求服务A在内存中合并数据进行展示,由于服务B提供通用接口的能力的限制、拼装筛选数据逻辑复杂,复杂的查询确实需要很大开发量;
但因为该功能确实较为边缘,产出价值并不是特别巨大,因此我们可以要求业务对相关查询进行简化,不要想着面面俱到,以减少开发成本,将人力投入到更有需要的地方。
综上,个人觉得针对该场景应该选择方案三。
三、何时选用方案二
方案一是单体应用的老路,不再讨论及考虑。以下分析下方案二的使用场景。
我们上面提到方案二需要存储数据、同步数据、维护数据准确性需要给到不少的代价,那何时选用方案二?
当然是获得的收益远大于付出的代价的时候,例如服务A需要为客户提供一个高频复杂的查询计算、并因此能获得一个很高的收益,此时我们就可以将B的数据导入到服务A,这样我们可以更方便的处理数据,提供更简洁高效的服务。
这里扩展一下,我们要如何同步服务B的数据呢?因批处理不实时、binlog等手段直接暴露底层数据结构增加服务间耦合,个人觉得利用队列实现的事件溯源模式是一个不错的选择,后续会写文章介绍相关实现。
四、总结
对于微服务场景下的数据查询,对于原始数据提供方:
不应该接受非本服务的任何逻辑及数据;
提供通用(非定制)的查询接口,以满足其他服务基础查询需求;
提供获取全量业务层级数据的方式,如事务溯源模式,发布业务层级的每一次状态变化(状态变化的形态要像API一样保持兼容性)。
对于使用数据方:
尽可能地使用对方通用的查询接口;
综合考虑收益及代价后,可在本地数据库导入其他服务的数据,以实现更高效灵活的业务逻辑。
(对于不使用上述总结规则的微服务容易陷入一个怪圈,如下,大家看看就好)
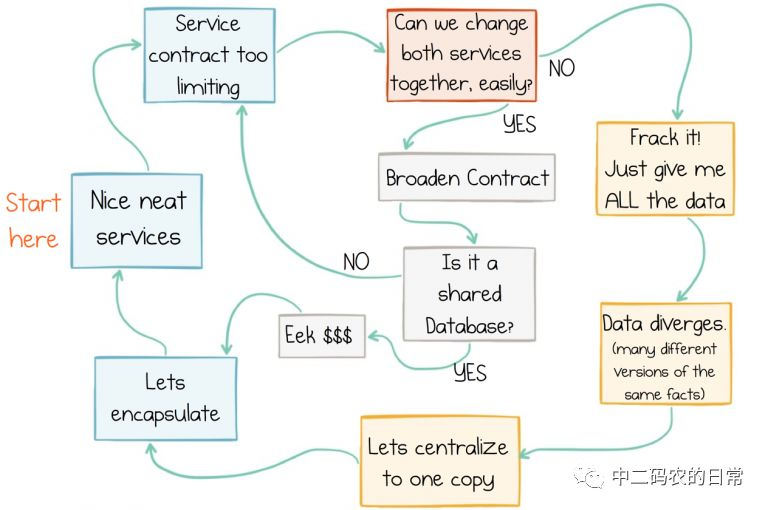
五、最后
本文为个人的一些思考,仅为抛砖引玉,欢迎各位提出自己的一件。
如本文对你有所启发及帮助,请转发以帮助更多的人,谢谢!
六、引用
百度百科——罗生门
https://baike.baidu.com/item/罗生门/52523?fr=aladdin
data-dichotomy-rethinking-the-way-we-treat-data-and-services
https://www.confluent.io/blog/data-dichotomy-rethinking-the-way-we-treat-data-and-services/

















 307
307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









