









 本文围绕网络编程应用层展开,先介绍自定制协议,以自制网络计算器为例说明序列化与反序列化。重点阐述HTTP协议,包括认识url、其编码与解码,HTTP协议格式、方法、状态码及常见头部信息,还实现了简单HTTP服务器,强调HTTP协议是应用层关键。
本文围绕网络编程应用层展开,先介绍自定制协议,以自制网络计算器为例说明序列化与反序列化。重点阐述HTTP协议,包括认识url、其编码与解码,HTTP协议格式、方法、状态码及常见头部信息,还实现了简单HTTP服务器,强调HTTP协议是应用层关键。
在了解网络整体模型之前学习了套接字编程和一些简单的网络知识。但是网络编程的理论基础是建立在多方面上的,比如数据在每一层是经过了怎么样的封装,每一层使用了哪些协议,每一层的协议又有哪些用途。只有掌握好这些基础知识,才能更好的成为一个服务器开发人员。
应用层
程序员写的一个个解决我们实际问题,满足我们日常需求的网络程序,都是在应用层完成的。
那么应用层使用了哪些协议呢?
自定制协议
socket编程中,收发数据我们通过的是字符串的形式,假如我们想传输“结构化的数据”怎么办?
假定此时我们被分发了一个任务,需要自制一个网络计算器。此时有两种方案。
约定方案一:
客户端发送一个形如"1+1"的字符串;
这个字符串中有两个操作数, 都是整形;
两个数字之间会有一个字符是运算符, 运算符只能是 + ;
数字和运算符之间没有空格;
约定方案二:
定义结构体来表示我们需要交互的信息;
发送数据时将这个结构体按照一个规则转换成字符串, 接收到数据的时候再按照相同的规则把字符串转化回结构体;
这个过程叫做 "序列化" 和 "反序列化"
序列化: 将数据按照持久化存储或网络数据传输的格式进行排布
反序列化: 将数据按照指定的协议进行解析
我们将这个计算的传输数据保存到一个结构体中
struct cal
{
int num1; //cal.num1 = 1 , cal.num2 = 2 , cal.op = '+'
int num2; //send(cal) ---- recv(char buf[9])
char op; // char *a = buf;
}cal;
通过代码实现一下,将之前的TCP.h文件和服务端和客户端进行一个改变即可
之前博客可查看:https://blog.youkuaiyun.com/skrskr66/article/details/91452452
//tcpSocket.hpp
类外添加
typedef struct cal_t
{
int num1;
int num2;
char op;
}cal;
类内添加
int GetSockFd()
{
return _sock;
}
//tcp_cli.cpp
include "tcpsocket.hpp"
int main(int argc,char* argv[])
{
if(argc != 3)
{
cout<<"./tcp_client ip port"<<endl;
return -1;
}
string ip = argv[1];
uint16_t port = atoi(argv[2]);
//字符串转换成整型数的一个函数
TcpSocket sock;
CHECK_RET(sock.Socket());
CHECK_RET(sock.Connect(ip,port));
while(1)
{
cal info;
cin>>info.num1>>info.op>>info.num2;
int fd = sock.GetSockFd();
send(fd,&info,sizeof(cal),0);
}
sock.Close();
return 0;
}
//tcp_ser.cpp
#include "tcpsocket.hpp"
int main(int argc,char* argv[])
{
if(argc != 3)
{
cout<<"./tcp_server ip port"<<endl;
return -1;
}
string ip = argv[1];
uint16_t port = atoi(argv[2]);
TcpSocket sock;
CHECK_RET(sock.Socket());
CHECK_RET(sock.Bind(ip,port));
CHECK_RET(sock.Listen());
while(1)
{
TcpSocket clisock;
struct sockaddr_in cliaddr;
if(sock.Accept(clisock,&cliaddr) == false)
{
continue;
}
cout<<"new connect client:"<<inet_ntoa(cliaddr.sin_addr)<<":"<<ntohs(cliaddr.sin_port)<<endl;
int fd = clisock.GetSockFd();
cal info;
recv(fd,&info,sizeof(cal),0);
switch(info.op)
{
case '+':
cout<<"num1: ["<<info.num1<<"]"<<info.op<<"num2: ["<<info.num2<<"]"<<"= ["<<info.num1 + info.num2<<"]"<<endl;
break;
case '-':
cout<<"num1: ["<<info.num1<<"]"<<info.op<<"num2: ["<<info.num2<<"]"<<"= ["<<info.num1 - info.num2<<"]"<<endl;
break;
case '*':
cout<<"num1: ["<<info.num1<<"]"<<info.op<<"num2: ["<<info.num2<<"]= ["<<info.num1 * info.num2<<"]"<<endl;
break;
case '/':
cout<<"num1:["<<info.num1<<"]"<<info.op<<"num2: ["<<info.num2<<"]= ["<<info.num1 / info.num2<<"]"<<endl;
break;
}
}
sock.Close();
}
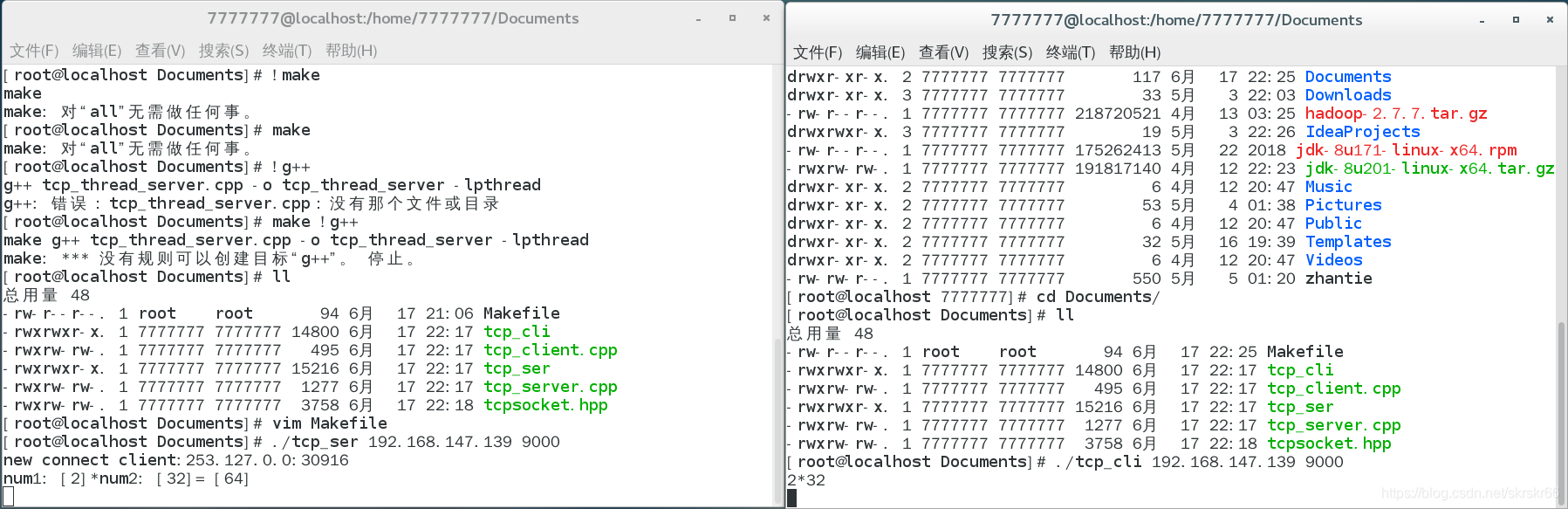
客户端输入计算值,服务端即可返回计算结果。传输了结构化数据
HTTP协议
虽然HTTP协议早已耳熟能详。但是它也是由大佬定义的协议,我个人认为也算在自定制协议中。
HTTP协议又称为超文本传输协议。是一个基于请求与响应模式的、无状态的、应用层的协议,常基于TCP的连接方式 。
认识url
url简单的理解就是我们常说的网址。它的专业名称是:统一资源定位符
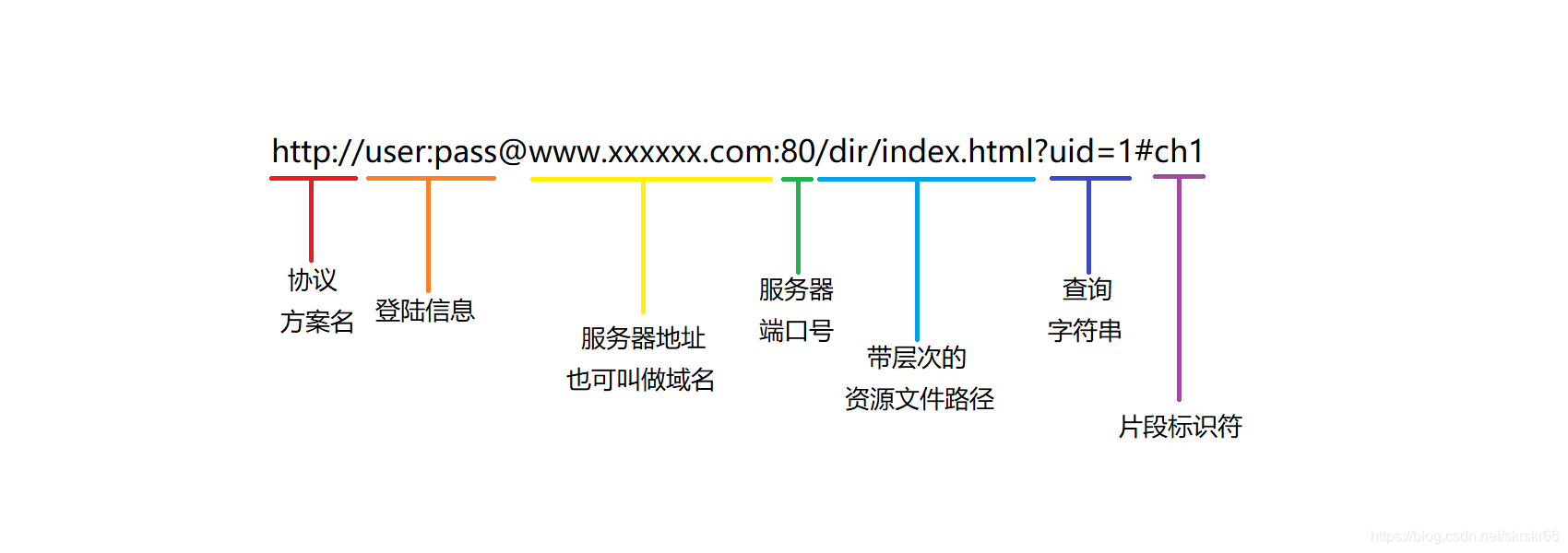
上面就是一个url各个部分的意义
url的编码urlencode与解码urldecode
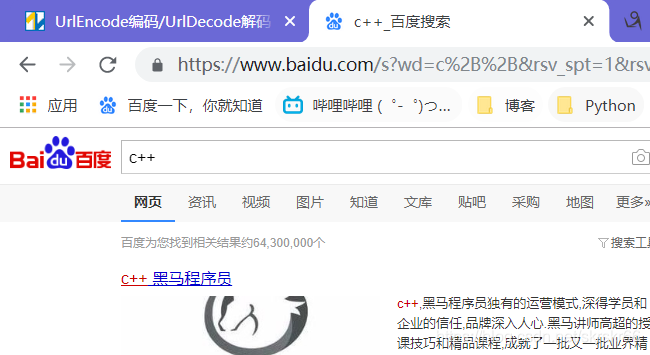
当我们进行一些查找的操作时,比如百度搜索C++,但是上面的url却变成了c%2B%2B,这是怎么回事?
像这样的字符,已经被url当作特殊意义理解了。因此这些字符不能随意出现。
比如,某个参数中需要带又这些特殊字符,就必须先对这些字符进行编码操作。
urlencode:将特殊字符转换为16进制字符串,并且在前方使用%表明两个字符是经过了编码的
urldecode:当查询字符串出现%则认为,后续两个字符是需要进行url解码的
HTTP协议格式
通过使用fiddler进行抓包,查看HTTP的协议格式
域名中的xx是我个人隐藏。。。
GET http://123.207.58.xx/ HTTP/1.1
Host: 123.207.58.xx
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Referer: http://123.207.58.25/homework/userHomework
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: PHPSESSID=1vgu9tcfei5t4erlc9sq9gj8o3; loginStatus=yes
HTTP/1.1 200 OK
Server: nginx/1.12.2
Date: Tue, 18 Jun 2019 06:46:49 GMT
Content-Type: text/html; charset=UTF-8
Transfer-Encoding: chunked
Connection: keep-alive
X-Powered-By: PHP/5.4.16
Expires: Thu, 19 Nov 1981 08:52:00 GMT
Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0
Pragma: no-cache
上面分别为http协议请求和http协议响应
请求首行:[请求方法] + [url] + [版本]
Header(请求头部):请求的属性,由一个个键值对组成,每个键值对都有对其含义和功能 key:val\r\nkay:val\r\n,每组属性之间使用\n分隔;遇到空行表示Header部分结束
响应首行:[版本号] + [状态码] + [状态码解释]
Body:空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个键值对Content-Length属性来标识Body的长度; 如果服务器返回了一个html页面, 那么html页面内容就是在body中.
HTTP的方法
请求方法有很多,依次罗列,不过所有方法名均为大写
| GET | 请求获取request-url所标识的资源 | 1.0/1.1 |
|---|---|---|
| POST | 在request-url所标识的资源后附加新的数据 | 1.0/1.1 |
| HEAD | 请求获取由request-url所标识的资源的响应消息报头 | 1.0/1.1 |
| PUT | 请求服务器存储一个资源,并用request-url作为其标识 | 1.0/1.1 |
| DELETE | 请求删除request-url所标识的资源 | 1.0/1.1 |
| TRACE | 请求服务器回送收到的请求信息,主要用于测试或诊断 | 1.1 |
| CONNECT | 保留将来使用 | 1.1 |
| OPTIONS | 请求查询服务器的性能,或者查询与资源相关的选项和需求 | 1.1 |
| LINK | 建立和资源之间的联系 | 1.0 |
| UNLINE | 断开连接关系 | 1.0 |
其中最常用的就是GET和POST
GET方法:在浏览器的地址栏中输入网址的方式访问网页时,浏览器采用GET方法向服务器获取资源
POST方法要求被请求服务器接受附在请求后面的数据,常用于提交表单。
HTTP的状态码
| 类别 | 原因 | |
|---|---|---|
| 1xx | Informational(信息性状态码) | 表示请求已被接收,正在被处理 |
| 2xx | Success(成功状态码) | 请求正常处理完毕 |
| 3xx | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
| 4xx | Client Error(客户端错误状态码) | 服务器不能处理该请求 |
| 5xx | Server Error(服务端错误状态码) | 服务器处理请求出错 |
常见状态码:
200 OK //客户端请求成功
302 Redirect //重定向
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
HTTP常见的头部信息
Content-Type: 数据类型(text/html等);
Content-Length: Body的长度;
Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
User-Agent: 声明用户的操作系统和浏览器版本信息;
referer: 当前页面是从哪个页面跳转过来的;
location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问;
Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;
实现一个简单HTTP服务器
#include <iostream>
#include <sstream>
#include "tcpsocket.hpp"
int main(int argc,char* argv[])
{
if(argc != 3)
{
cout<<"./httpserver ip port\n"<<endl;
return -1;
}
string ip = argv[1];
uint16_t port = atoi(argv[2]);
TcpSocket sock;
CHECK_RET(sock.Socket());
CHECK_RET(sock.Bind(ip,port));
CHECK_RET(sock.Listen());
while(1)
{
TcpSocket clisock;
if(sock.Accept(clisock) == false)
{
continue;
}
string buf;
clisock.Recv(buf);
cout<<"req:["<<buf<<"]"<<endl;
string body;
body = "<html><body><h1>Hello Donkey</h1></body></html>";
stringstream ss;
ss << "HTTP/1.1 502 Bad GateWay\r\n";
ss << "Content-Length: " << body.size() <<"\r\n";
ss << "Content-Type: text/html\r\n";
ss << "Location: http://www.baidu.com\r\n";
ss << "\r\n";
string header = ss.str();
clisock.Send(header);
clisock.Send(body);
clisock.Close();
}
sock.Close();
return 0;
}
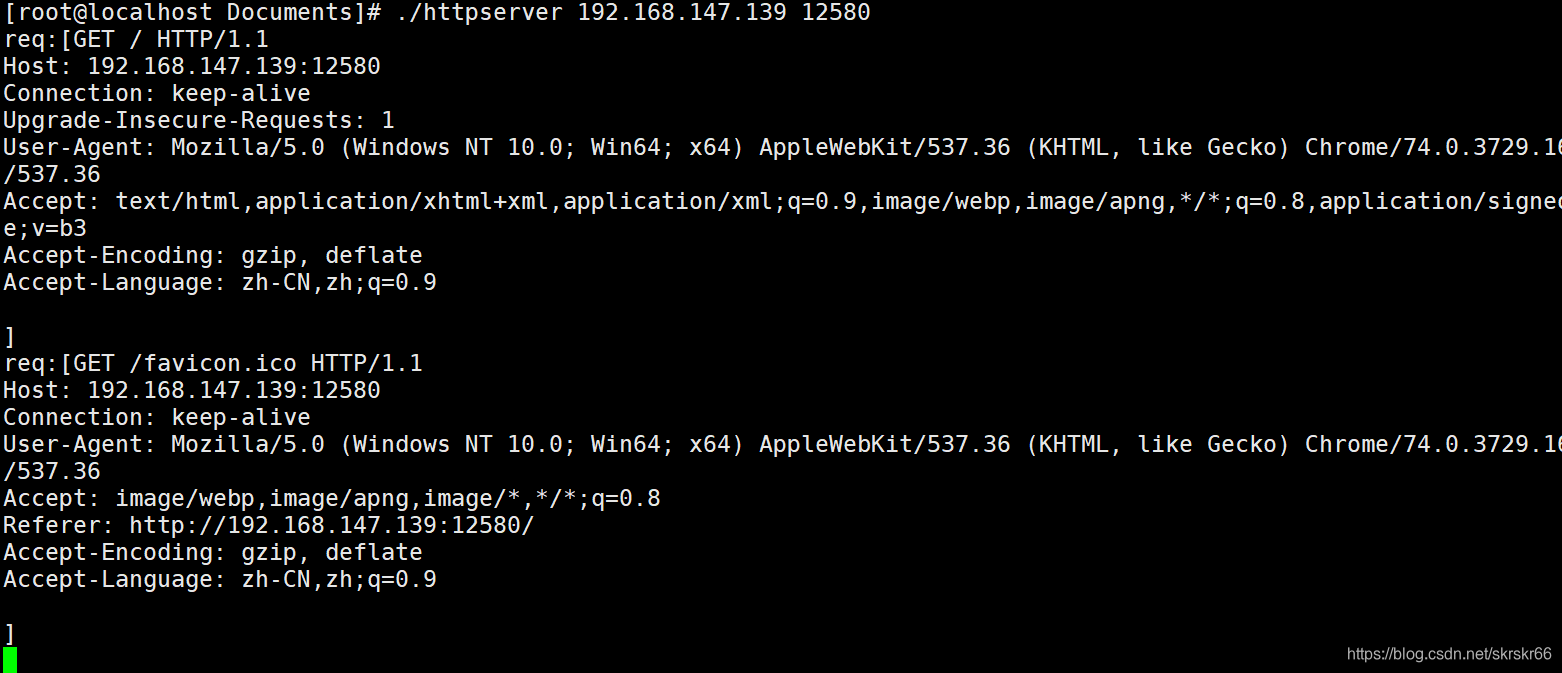
运行如图,感觉还不错。
个人小结
应用层中最关键的是HTTP协议。而在HTTP协议中,首先是了解url,url又叫做统一资源定位符。
url在查找过程中当遇到特殊的字符存在时还有编码与解码的操作。将特殊字符转换为16进制。
HTTP的协议格式分为请求和响应。它们又分别具有请求首行,请求报头;响应首行,响应报头
HTTP的方法有多种,我们常用的为GET和POST这两种
HTTP的状态码有五种分别为1xx,2xx,3xx,4xx,5xx。它们分别对应了信息性状态码,成功状态码,重定向状态码,客户端错误状态码,服务端错误状态码
HTTP的常见头部信息有:
Content-Type: 数据类型(text/html等)
Content-Length: Body的长度
Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
User-Agent: 声明用户的操作系统和浏览器版本信息;
referer: 当前页面是从哪个页面跳转过来的;
location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问;
Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;
HTTP协议的知识点比较多,还是多看才能记住

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









