







 本文探讨了Inception网络模块的构建与组合,展示了如何利用这些模块创建深度学习模型。此外,文章深入介绍了迁移学习的概念,包括如何利用预训练模型进行特定任务的学习,以及数据扩充技术在提升模型性能中的应用。
本文探讨了Inception网络模块的构建与组合,展示了如何利用这些模块创建深度学习模型。此外,文章深入介绍了迁移学习的概念,包括如何利用预训练模型进行特定任务的学习,以及数据扩充技术在提升模型性能中的应用。
卷积神经网络(第二周下半部分)
2.7 Inception网络
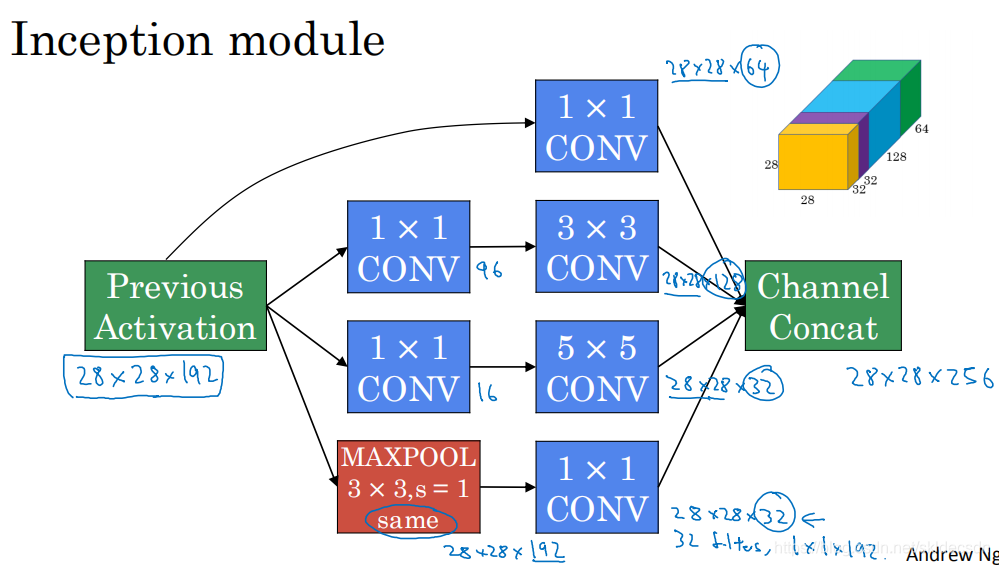
在上节中我们看到了Inception网络模块的基础内容,下面我们将学习如何将这些模块组合起来构建自己的Inception网络。Inception模块会将之前层的激活或者输出作为它的输入作为前提,这是一个28 * 28 * 192的输入和上节中的一样,我们详细分析过的例子是先通过一个1 * 1的层再通过一个5 * 5 的层,1 * 1的层可能有16个通道,而5 * 5的层的输出为28 * 28,32个通道这就是我们上节所说的例子,为了在这个3 * 3的卷积层中节省运算量,你也可以做相同的操作,这样的话3 * 3的层将会输出28 * 28 * 128。或许你还想将其直接通过一个1 * 1的卷积层,这时就不必在后面再跟一个1 * 1的层了,这样的话过程就只有一步了假设这个层的输出是28 * 28 * 64.最后是池化层,为了能在最后将这些输出都连接起来,我们会使用same类型的padding来池化,使得输出的高度和宽度依然是28 * 28,这样才能将它与其他输出连接起来。但是要注意的是,如果进行了最大池化即使用了 same padding,3 * 3的过滤器,stride为1,其输出将会是28 * 28 * 192,其通道数量或者说深度将与输入的28 * 28 * 192相同。所以看起来它会有很多通道,我们实际上要做的就是再加一个1 * 1的卷积层,去进行我们在1 * 1卷积层将通道数量缩小(上节介绍),缩小到28 * 28 * 32,也就是使用32个维度为1 * 1 * 192的过滤器,所以输出的维度其通道数缩小为32。这样就避免了最后的输出时池化层占据了所有的通道,最后将这些方块全都连接起来,在这个过程中把得到的各个层的通道都加起来,最后得到一个28 * 28 * 256的输出。通道连接实际就是之前看到过的把所有方块连接在一起的操作,这就是一个Inception模块。
Inception网络所做的就是将这些模块都组合到一起,下面是一张取自Szegety et al.论文中关于Inception网络的图片。
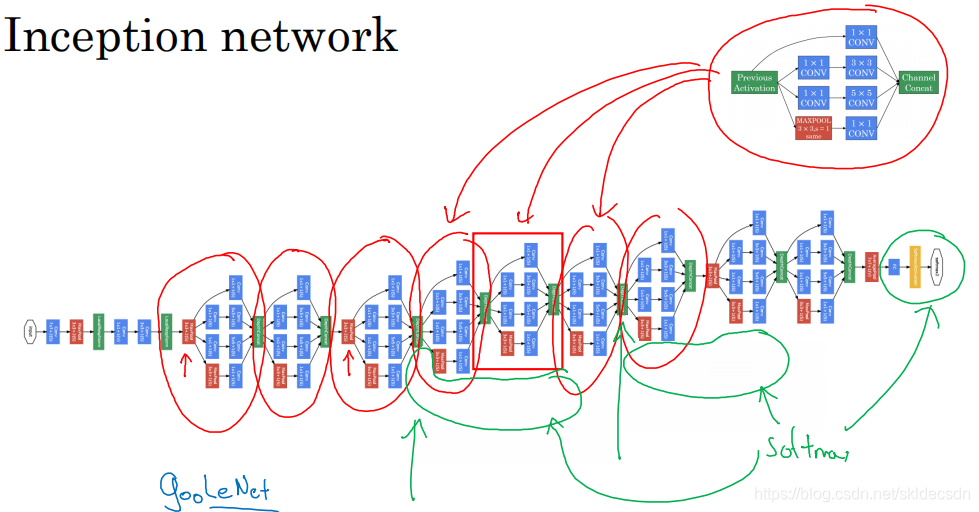
会发现图中有许多重复的模块,可能整张图看起来很复杂,但如果只截取其中一个环节就会发现这是上面我们所说的Inception模块。
所以说,Inception网络是由许多Inception模块组合起来的。
2.9 迁移学习
假如要建立一个猫的检测器,用来检测你自己的宠物猫,比如网络上的假如两只猫的名字叫Tigger和Misty,还有一种情况是两者都不是,所以现在有一个三分类的问题,图片里的是Tigger还是Misty或者都不是。这里忽略两只猫同时出现在一张图片里的情况,所以你的训练集会很小,那么如何让数据集更大呢?可以从网上下载一些神经网络的开源实现不仅把代码下载下来也把权重下载下来,有许多训练好的网络你都可以下载举个例子ImageNet数据集,它有1000个不同的类别,因此这个网络会有一个Softmax单元可以输出1000个可能类别之一。你可以去掉这个Softmax层构建你自己的Softmax层用来输出Tigger和Misty和neither三个类别。
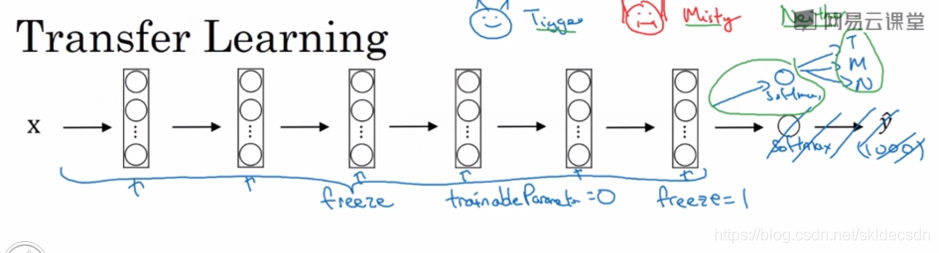
就网络而言,建议把所有的层都看成是冻结的,冻结网络中的所有层的参数,你只需训练和你的softmax层有关的参数,这个softmax层有三个可能的输出值。通过使用其他人预训练的权重,很可能得到很好的性能,即使只有一个小的数据集。幸运的是大多数深度学习框架都支持这种操作。事实上取决于用的框架,它也许会有trainableParameter = 0这样的参数。
上面的方法对于小的数据集是可以的,如果是一个更大的训练集怎么办呢?根据经验如果有一个更大的数据集也许有大量的Tigger和Misty的照片还有两者都不是的,这种情况你应该冻结更少的层比如只把这些层冻结,然后训练后面的层如果你的输出层的类别不同,那么你需要构建自己的输出单元Tigger和Misty或者两者都不是三个类别。
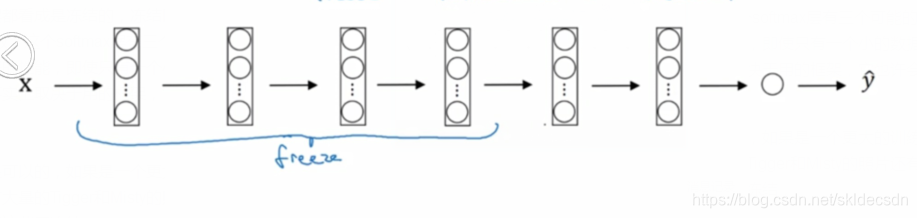
有很多方式可以实现,你可以取后面几层有很多方式可以实现,你可以取这几层的权重用作初始化然后从这里开始梯度下降或者可以直接去掉这几层换成你自己的隐藏单元和自己的softmax输出层这些方法值得一试。但是有一个规律,如果有越多的数据,那么你需要冻结的层数就越少,你能够训练的层数就越多。
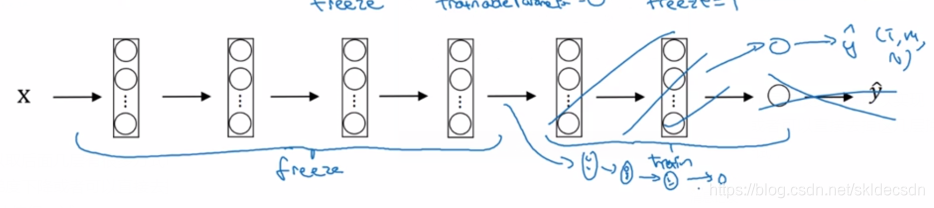
这个理念就是如果你有一个更大的数据集,有足够多的数据,那么不要单单训练一个softmax单元,而是考虑训练中等大小的网络包含你最终要用的网络的后面几层。最后如果有大量的数据应该做的就是用开源的网络和它的权重把整个的当做初始化然后训练整个网络,再次注意,如果这是一个1000个节点的softmax而你只有三个输出,需要你自己的softmax输出层来输出你要的标签,如果你有越多的标定的数据或者越多的Tigger和Misty或者两者都不是的图片,你可以训练越多的层。甚至可以用下载的权重只作为初始化用它们代替随机初始化的权重,接着可以用梯度下降训练更新网络所有层的所有权重,这就是卷积神经网络中的迁移学习。
2.10 数据扩充
大部分计算机视觉任务使用很多的数据,所以数据增强经常是一种技巧。计算机视觉是一个相当复杂的工作,你需要输入图像的像素值然后弄清楚图片中有什么,需要学习一个复杂的方程来做这件事,更多的数据对大多数计算机视觉任务都有帮助,不像其他领域有时候得到充足的数据但是效果并不怎样,但是当下在计算机视觉方面计算机视觉的主要问题是没有办法得到充足的数据,对于机器学习的应用者这不是问题。但是对计算机视觉数据就远远不够,所以就意味着当训练计算机视觉模型的时候数据增强会有所帮助,无论是使用迁移学习使用别人的预训练模型开始或者从源代码开始训练模型。
下面来看下数据增强的过程
最简单的数据增强是垂直镜像对称,假如输入图像为左边的,然后将其翻转得到右边的图像。左边图像是猫,然后镜像对称仍然是猫,这样的操作保留了图像中的实体,是一种较好的数据增强技巧。另一个经常使用的技巧是随机剪裁,给定一张原始的图像,然后开始随机剪裁可以得到不同的图片,放在数据集中,你的训练集中有不同的剪裁后的图像。随机剪裁并不是一个完美的数据增强的方法,会出现如果你随机剪裁的那一部分可能是实体的一个角落的图片(图中红色框)。
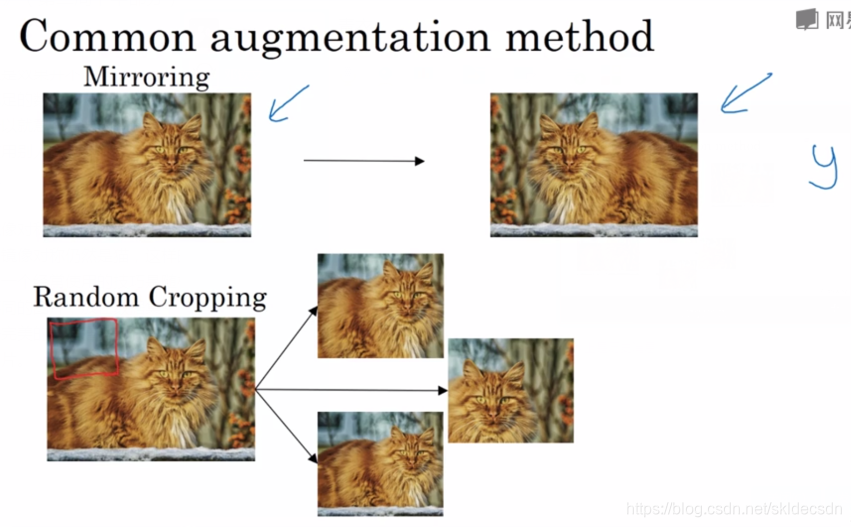
镜像和随机修剪是经常使用的,当然理论上你也可以使用旋转、剪切图像,可以对图像进行这样的扭曲变换,介绍了很多形式的局部弯曲。在实践中,因为太复杂所以使用的很少。
另一种数据增强的方法是色彩转换,有这样一张图片然后给R、G、B三通道加上不同的失真值,在这个例子中要给红色和蓝色通道加值给绿色通道减值,红色和蓝色会产生紫色使整张图片看起来偏紫色,这样做的目的就是改变R、G、B的值,使用这些值来改变颜色,在第二个例子中我们少用了一点红色更多的绿色和蓝色值,使整张图片偏黄一点,再下面是使用了更多的蓝色仅仅多了一点红色。在实践中R、G、B的值是根据某种概率分布决定的。
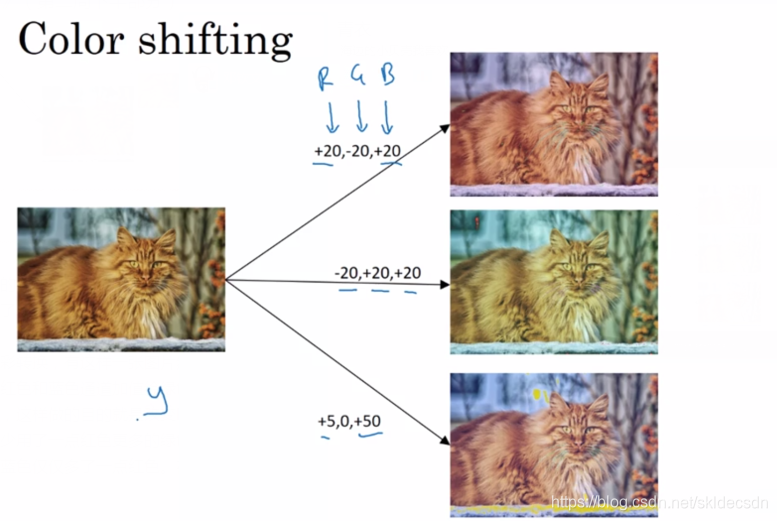
这些改变图片颜色的,但是并未改变图像要识别实体的内容,这些颜色扭曲或者颜色变换的方法,这样会使得你的学习算法对照片的颜色更改更具有鲁棒性。关于颜色改变R、G、B的值时可以网上搜索阅读AlexNet论文中的细节也有PCA颜色增强的开源实现方法。

















 1016
1016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









