







目录
基于 Transformer 的模型(BERT、GPT)深度解析
2. BERT:Bidirectional Encoder Representations from Transformers
3. GPT:Generative Pre-trained Transformer
基于Transformer架构的模型已经在自然语言处理(NLP)领域掀起了革命性的变化。模型如BERT(Bidirectional Encoder Representations from Transformers)和GPT(Generative Pre-trained Transformer)不仅在各种NLP任务中表现卓越,还为更复杂的语言理解和生成提供了新的解决方案。今天,我们将深入探讨基于Transformer架构的模型,特别是BERT和GPT,并通过TensorFlow实现它们的简化版本。
1. Transformer架构简介
1.1 Transformer的起源
Transformer架构最早由Vaswani等人在2017年的论文《Attention is All You Need》中提出。与传统的循环神经网络(RNN)和长短期记忆(LSTM)网络不同,Transformer完全摒弃了序列化的计算方式,采用了全局自注意力机制(Self-Attention)来处理序列数据。
Transformer的核心组件包括:
- 自注意力机制(Self-Attention):计算每个词与其它所有词之间的关系。
- 前馈神经网络(Feed-Forward Network):对每个位置的表示进行非线性变换。
- 多头注意力机制(Multi-Head Attention):并行计算多个注意力子空间,增强模型的学习能力。
- 位置编码(Positional Encoding):由于Transformer不具备处理序列顺序的能力,位置编码用于为每个输入位置添加位置信息。
Transformer的优势在于其并行计算能力,这使得它能够更高效地处理长文本。
1.2 Transformer架构的结构图
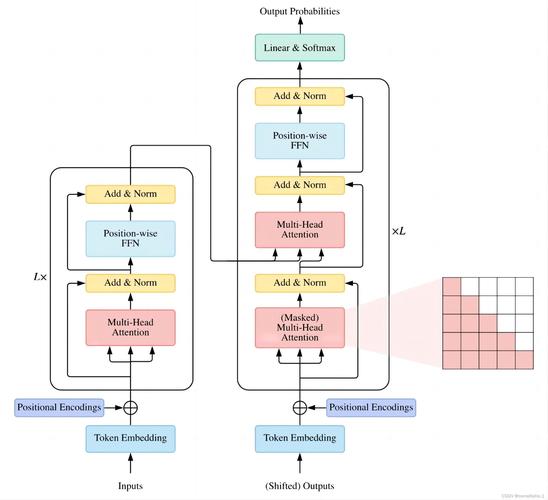
1.3 TensorFlow中的Transformer实现
TensorFlow提供了高效的实现来构建Transformer模型。下面是一个简化版的Transformer编码器的实现:
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense, LayerNormalization, Dropout
from tensorflow.keras.models import Model
# 自注意力机制
def attention(query, key, value):
matmul_qk = tf.matmul(query, key, transpose_b=True)
dk = tf.cast(tf.shape(key)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1)
output = tf.matmul(attention_weights, value)
return output
# Transformer编码器层
def transformer_encoder(inputs, head_size, num_heads, ff_size, dropout=0.1):
# 多头自注意力层
attention_output = attention(inputs, inputs, inputs)
attention_output = Dropout(dropout)(attention_output)
attention_output = LayerNormalization(epsilon=1e-6)(attention_output + inputs)
# 前馈神经网络层
ff_output = Dense(ff_size, activation='relu')(attention_output)
ff_output = Drop 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2573
2573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











