







目录
在深度学习的世界中,反向传播(Backpropagation)和梯度下降(Gradient Descent)是最基础也是最重要的技术。它们是神经网络能够从大量数据中学习、进行优化和调整参数的核心机制。在这篇博客中,我们将深入讲解反向传播与梯度下降的原理,详细分析它们在神经网络中的作用,并通过代码示例帮助大家理解这些概念的实现过程。
1. 反向传播(Backpropagation)概述
什么是反向传播?
反向传播是神经网络中用于训练的一个算法,它通过计算每个参数(如权重和偏置)对损失函数的影响,并通过链式法则来更新这些参数。它是神经网络优化的核心,帮助我们通过最小化损失函数来调整网络参数,使得网络的预测更准确。
反向传播的数学原理
反向传播算法基于链式法则,目的是计算损失函数关于网络中每个参数的偏导数。具体来说,反向传播计算的是每一层的梯度,即每一层的参数对最终输出误差的影响。
假设我们有一个神经网络,损失函数为,输出为
,而网络参数为
。我们需要计算的是
以及其他参数的梯度。为了实现这一点,反向传播将通过从输出层开始,逐层计算每一层的梯度,直到输入层。
反向传播的步骤
-
前向传播:首先,计算神经网络的输出。通过输入数据进行前向传播,得到预测值
,并计算损失函数
。
-
计算损失函数的梯度:接着,从输出层开始,计算损失函数对输出的梯度(即误差):
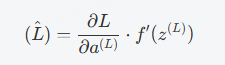
其中,
是激活函数的导数,
是输出层的激活值,
是线性组合的输入。
-
反向传播误差:然后,逐层将误差传递到前一层,计算每层的误差(残差):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 369
369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











