







 本文介绍了多变量线性回归模型,包括多维特征、梯度下降法及其实践,如特征缩放和学习率调整。还讨论了特征和多项式回归以及正规方程,提供了解决线性回归问题的两种方法,并比较了它们的适用场景。
本文介绍了多变量线性回归模型,包括多维特征、梯度下降法及其实践,如特征缩放和学习率调整。还讨论了特征和多项式回归以及正规方程,提供了解决线性回归问题的两种方法,并比较了它们的适用场景。
多维特征
目前为止,我们探讨了单变量/特征的回归模型,现在我们对房价模型增加更多的特征,例如房间数楼层等,构成一个含有多个变量的模型,模型中的特征为(𝑥1, 𝑥1, . . . , 𝑥𝑛)。
增添更多特征后,我们引入一系列新的注释:
𝑛 代表特征的数量
𝑥(𝑖)代表第 𝑖 个训练实例,是特征矩阵中的第𝑖行,是一个向量(vector)。
𝑥j(𝑖)代表特征矩阵中第 𝑖 行的第 𝑗 个特征,也就是第 𝑖 个训练实例的第 𝑗 个特征。
支持多变量的假设 h 表示为:![]()
x为特征值,𝜃0为特征值的参数
𝜃是参数
假设函数:h𝜃(𝑥)
损失函数:计算单个训练集的误差
代价函数: 计算整个训练集所有损失之和的平均值
目标函数:一个更加宽泛的概念。目标函数是优化问题中的一个概念。
概括起来,各类算法要解决的核心问题是:
分类算法 是什么
回归算法 是多少
聚类算法 怎么分
数据降维 怎么压
强化学习 怎么做对于有监督学习中的分类问题与回归问题,机器学习算法寻找一个映射函数:h(x)
多变量梯度下降
在多变量线性回归中,我们也构建一个代价函数![]()
![]()
使代价函数最小,多变量线性回归的批量梯度下降算法为:
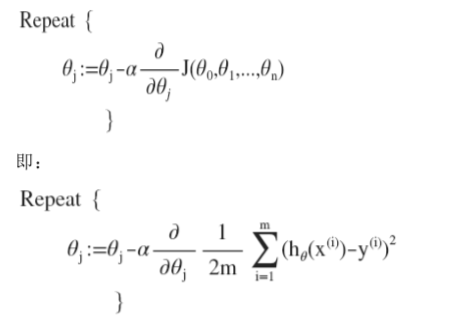
求导后:

我们开始随机选择一系列的参数值,计算所有的预测结果后,再给所有的参数一个新的值,如此循环直到收敛。
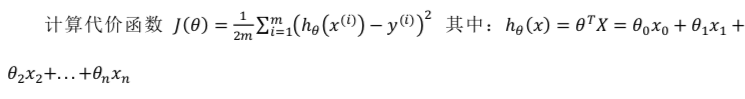
function J = computeCostMulti(X, y, theta)
m = length(y); % number of training examples
J = 0;
h = X*theta;
J = 1/(2*m)*sum((h-y).^2);
end
function [theta, J_history] = gradientDescentMulti(X, y, theta, alpha, num_iters)
m = length(y); % number of training examples
J_history = zeros(num_iters, 1);
for iter = 1:num_iters
theta = theta - alpha/m* X'*(X*theta- y);
J_history(iter) = computeCostMulti(X, y, theta);
end
end
梯度下降法实践 1-特征缩放
不同的特征很有可能在取值方面相差很大,这样就会导致梯度下降时间更长。
在我们面对多维特征问题的时候,我们要保证这些特征都具有相近的尺度,这将帮助梯度下降算法更快地收敛。
解决的方法是尝试将所有特征的尺度都尽量缩放到-1 到 1 之间 。
那么 x = (x-均值)/(x的最大值-x的最小值)。有了这个算式,我们可以轻易地编写代码。
在octave中
function [X_norm, mu, sigma] = featureNormalize(X)
X_norm = X;
mu = zeros(1, size(X, 2));
sigma = zeros(1, size(X, 2));
mu = mean(X);
sigma = std(X);
X_norm = (X_norm - mu) ./sigma;
end
梯度下降法实践 2-学习率
梯度下降算法收敛所需要的迭代次数根据模型的不同而不同,我们不能提前预知,我们 可以绘制迭代次数和代价函数的图表来观测算法在何时趋于收敛
梯度下降算法的每次迭代受到学习率的影响,如果学习率𝑎过小,则达到收敛所需的迭 代次数会非常高;如果学习率𝑎过大,每次迭代可能不会减小代价函数,可能会越过局部最 小值导致无法收敛。
通常可以考虑尝试些学习率:
𝛼 = 0.01,0.03,0.1,0.3,1,3,10
特征和多项式回归
线性回归并不适用于所有数据,有时我们需要曲线来适应我们的数据,比如一个二次方模型:![]() ,三次方模型:
,三次方模型:![]() ,
,
通常我们需要先观察数据然后再决定准备尝试怎样的模型。 另外,我们可以令:![]() ,从而将模型转化为线性回归模型。
,从而将模型转化为线性回归模型。
正规方程
到目前为止,我们都在使用梯度下降算法,但是对于某些线性回归问题,正规方程方法 是更好的解决方案。
正规方程是通过求解下面的方程来找出使得代价函数最小的参数的: 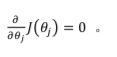
假设我们的训练集特征矩阵为 𝑋(包含了 𝑥0 = 1)并且我们的训练集结果为向量 𝑦,则利用正规方程解出向量![]()
在 Octave 中,正规方程写作:
theta = pinv(X'*X)*X'*y;
注:对于那些不可逆的矩阵(通常是因为特征之间不独立,如同时包含英尺为单位的尺寸和米为单位的尺寸两个特征,也有可能是特征数量大于训练集的数量),正规方程方法是不能用的。
梯度下降与正规方程的比较:
| 梯度下降 | 正规方程 |
| 需要选择学习率𝛼 | 不需要 |
| 需要多次迭代 | 一次运算得出 |
| 当特征数量𝑛大时也能较好适用 | 需要计算(𝑋𝑇𝑋)−1 如果特征数量𝑛较大则 运算代价大,因为矩阵逆的计算时间复杂度 为𝑂(𝑛3),通常来说当𝑛小于 10000 时还是 可以接受的 |
| 适用于各种类型的模型 | 只适用于线性模型,不适合逻辑回归模型等其他模型 |
总结:只要特征变量的数目并不大,标准方程是一个很好的计算参数𝜃的替代方法。 具体地说,只要特征变量数量小于一万,我通常使用标准方程法,而不使用梯度下降法。但是,标准方程法在有些算法上不适合使用。
对于这个特定的线性回归模型,标准方程法是一个比梯度下降法更快的替代算法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









