



 本文通过对CDNow在线音乐零售商1997至1998年的用户交易数据进行深入分析,揭示了用户消费习惯、客户价值及生命周期特点。分析覆盖总体消费趋势、客户获取与留存策略、RFM客户价值分类及客户生命周期评估。
本文通过对CDNow在线音乐零售商1997至1998年的用户交易数据进行深入分析,揭示了用户消费习惯、客户价值及生命周期特点。分析覆盖总体消费趋势、客户获取与留存策略、RFM客户价值分类及客户生命周期评估。
目录
1.简介
1.1 数据集说明
CDNow曾经是一家在线音乐零售平台,后被德国波泰尔斯曼娱乐集团公司出资收购,其资产总价值在最辉煌时曾超过10亿美元。
本次分析数据来源CDNow网站的用户在1997年1月1日至1998年6月30日期间内购买CD交易明细。
数据集字段:用户ID,购买日期,订单数,订单金额。
1.2 分析思路
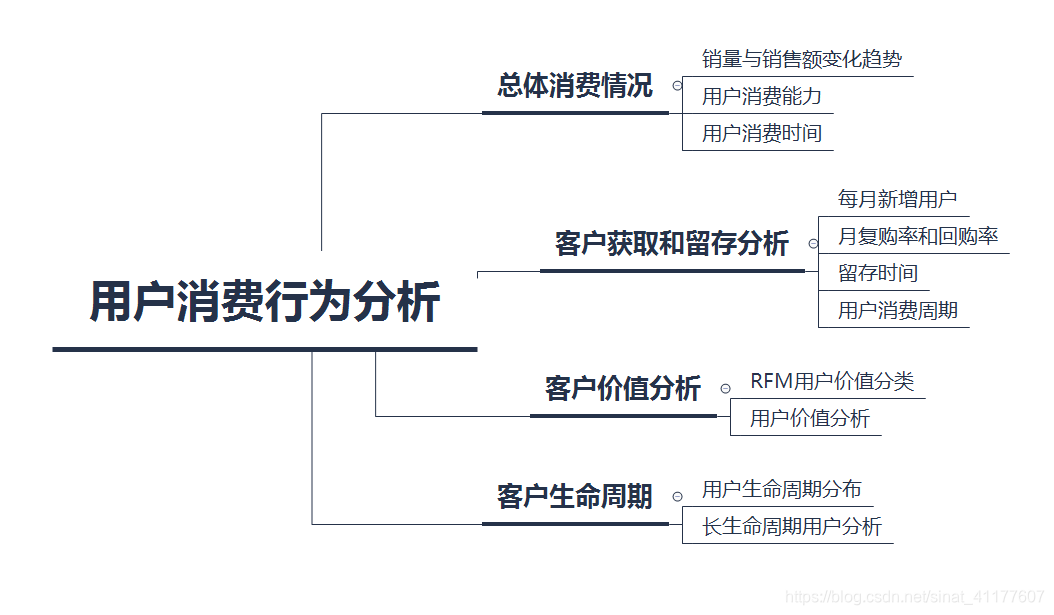
2.分析结果及建议
2.1 总体消费情况
(1)销量与销售额变化趋势
(2)用户消费能力
(3)用户消费时间
2.2 客户获取和留存
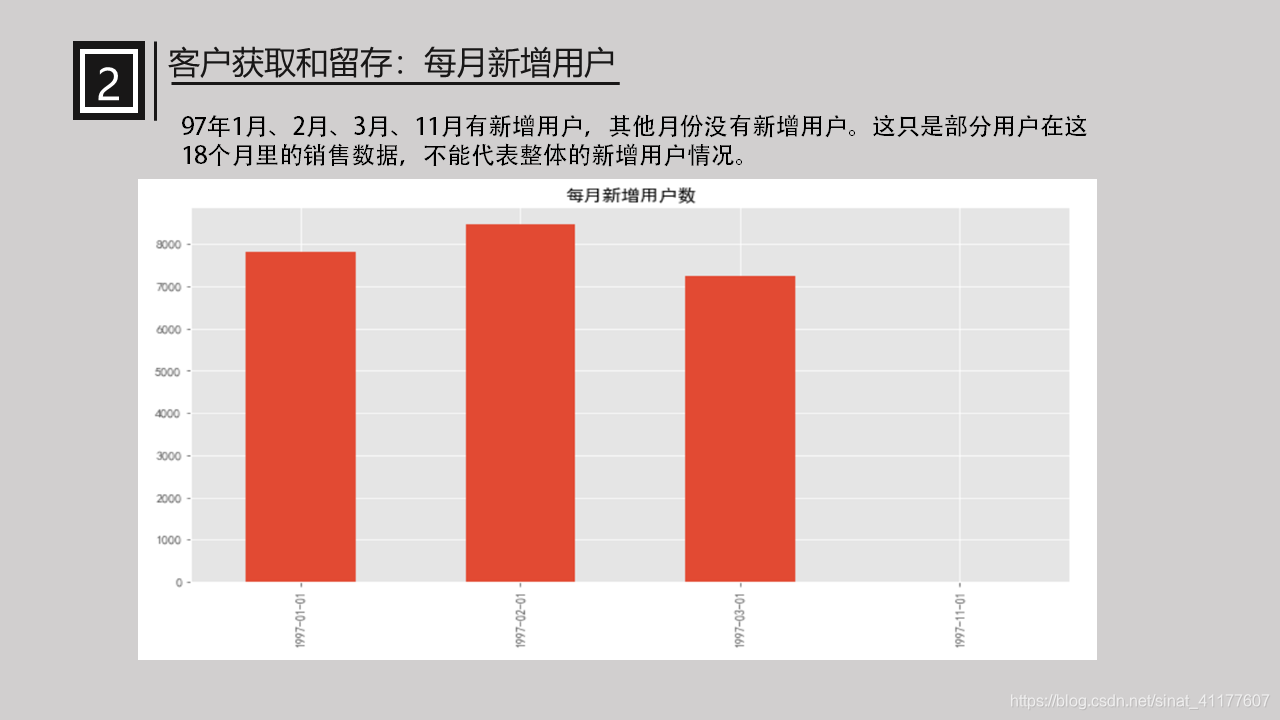
(1)每月新增用户
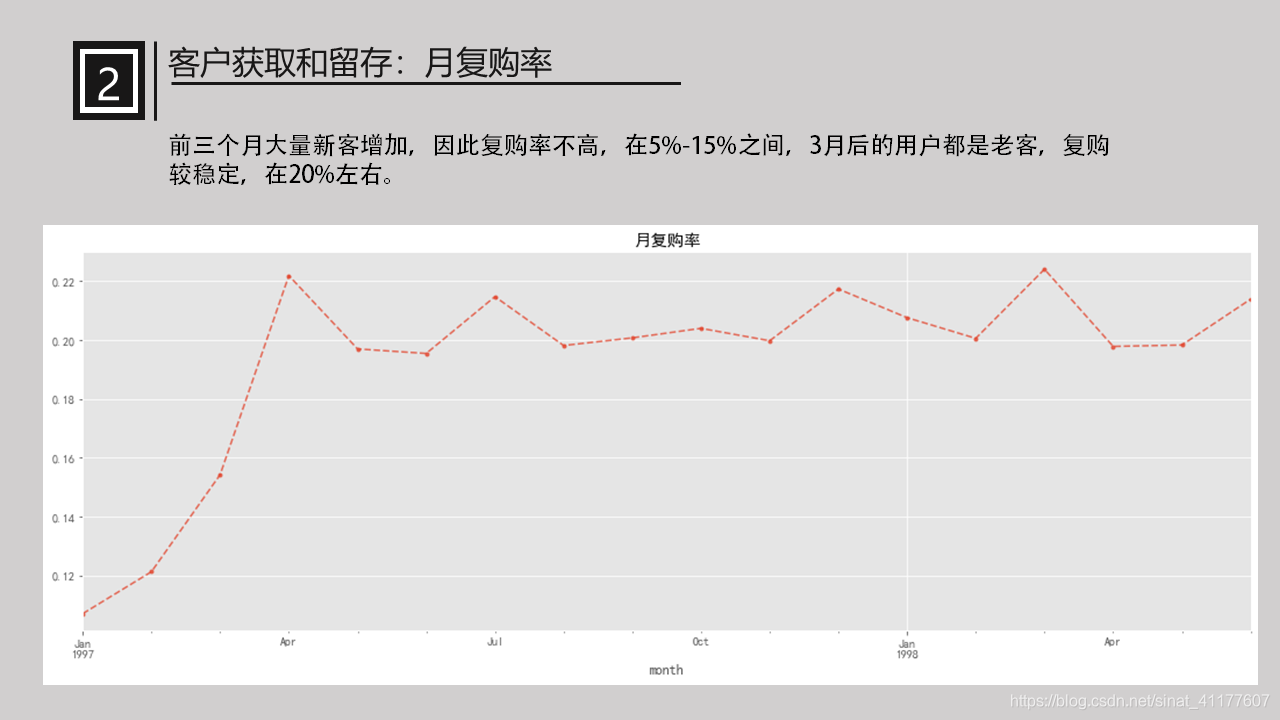
(2)月复购率与回购率
月复购率:在一个月内消费两次及以上的用户在总消费用户中占比。
月回购率:某个月内消费的用户,在下个月仍旧消费的占比。
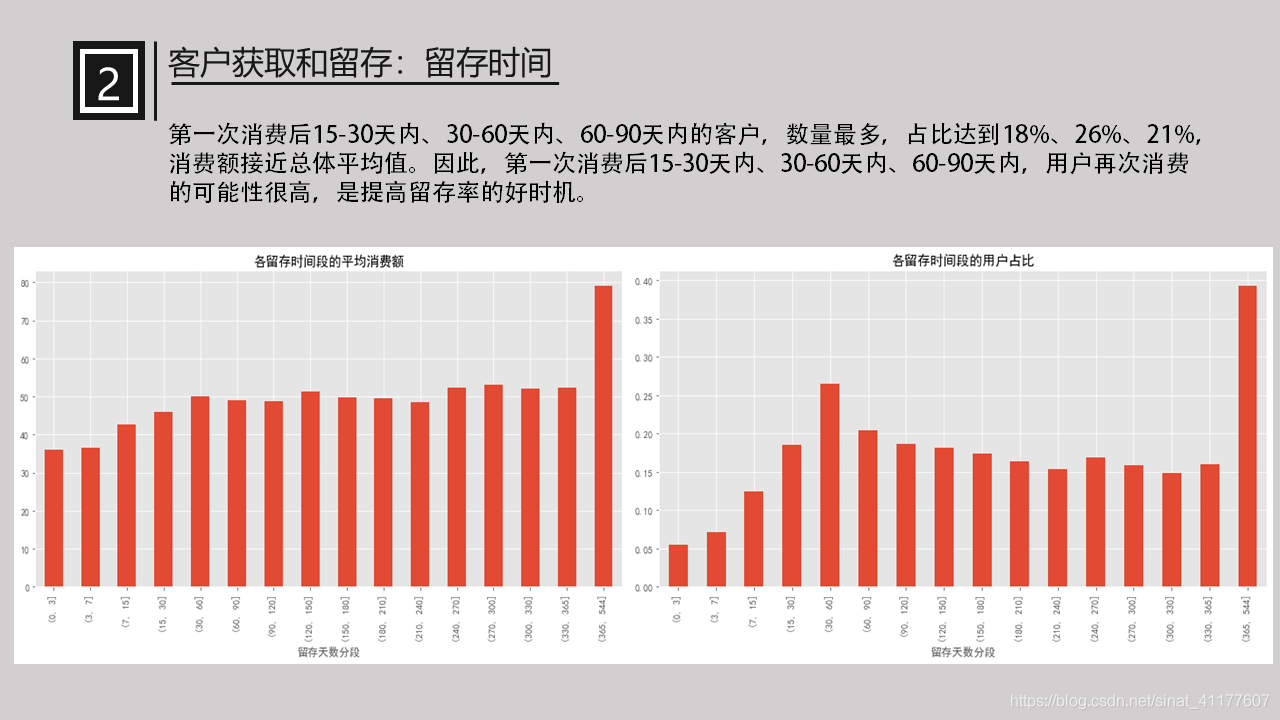
(3)留存时间
将留存时间分段,分析不同留存时间与消费额、用户数的关系。
(4)消费周期
此处定义为距离上次购买的时间间隔。消费周期与商品属性有关,CD的消费周期显然比一般的必需品长。分析消费周期有利于召回客户、理解商品特性。
2.3 客户价值分析
(1)RFM客户价值分类
R(Recency)表示客户最近一次购买时间
F(Frequency)表示客户在时间内购买的次数
M (Monetary)表示客户在时间内购买的金额。
采用k-measn聚类算法对客户数据进行客户分群,分成5类。
(2)用户价值分析
2.4 客户生命周期分析
用户生命周期是指第一次消费至最后一次消费的时间。
(1)生命周期
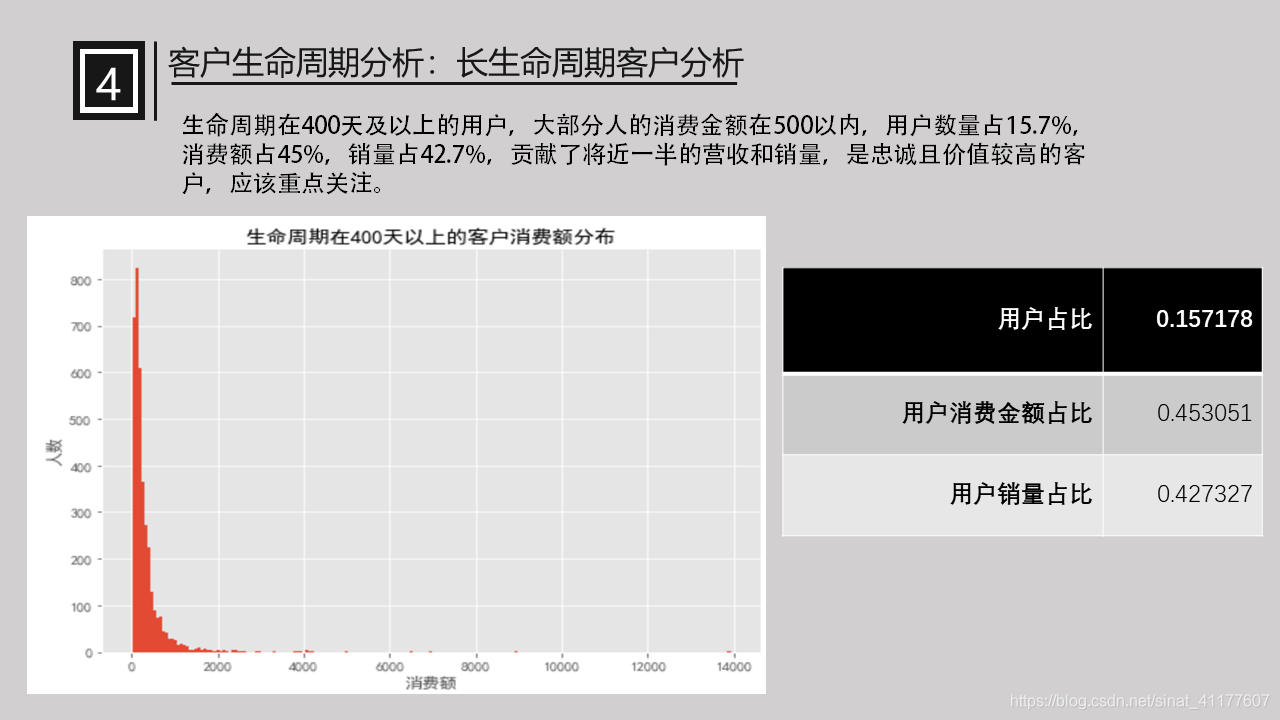
(2)长生命周期客户分析
进一步分析生命周期在400天以上的客户。
3.数据处理过程
导入模块
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from datetime import datetime
%matplotlib inline
plt.style.use('ggplot')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
columns = ['user_id', 'order_dt', 'order_products', 'order_amount']#给表头命名
df = pd.read_table('CDNOW.txt', names = columns,sep = '\s+')#字符串是空格分割,用\s+表示匹配任意空白符
df.head()
| user_id | order_dt | order_products | order_amount | |
|---|---|---|---|---|
| 0 | 1 | 19970101 | 1 | 11.77 |
| 1 | 2 | 19970112 | 1 | 12.00 |
| 2 | 2 | 19970112 | 5 | 77.00 |
| 3 | 3 | 19970102 | 2 | 20.76 |
| 4 | 3 | 19970330 | 2 | 20.76 |
3.1 数据预处理
#查看基本信息
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 69659 entries, 0 to 69658
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 69659 non-null int64
1 order_dt 69659 non-null int64
2 order_products 69659 non-null int64
3 order_amount 69659 non-null float64
dtypes: float64(1), int64(3)
memory usage: 2.1 MB
没有数据缺失
#查看是否有重复数据
sum(df.duplicated())
255
#去除重复数据
df.drop_duplicates(inplace = True)
sum(df.duplicated())
0
#有无异常数据
df.describe()
| user_id | order_dt | order_products | order_amount | |
|---|---|---|---|---|
| count | 69404.000000 | 6.940400e+04 | 69404.000000 | 69404.000000 |
| mean | 11468.913766 | 1.997228e+07 | 2.414558 | 35.963097 |
| std | 6814.368605 | 3.837687e+03 | 2.336528 | 36.318489 |
| min | 1.000000 | 1.997010e+07 | 1.000000 | 0.000000 |
| 25% | 5509.000000 | 1.997022e+07 | 1.000000 | 14.490000 |
| 50% | 11410.000000 | 1.997042e+07 | 2.000000 | 25.980000 |
| 75% | 17261.000000 | 1.997111e+07 | 3.000000 | 43.720000 |
| max | 23570.000000 | 1.998063e+07 | 99.000000 | 1286.010000 |
订单金额有0值,可能是赠品或减免商品,这部分客户没有太大价值,应该删除后再分析。
df.query('order_amount == 0').info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 80 entries, 1548 to 68593
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 80 non-null int64
1 order_dt 80 non-null int64
2 order_products 80 non-null int64
3 order_amount 80 non-null float64
dtypes: float64(1), int64(3)
memory usage: 3.1 KB
订单金额为0值的数有80条
#删除订单金额为0的数据
df = df.drop(df[df.order_amount == 0].index)
df.describe()
| user_id | order_dt | order_products | order_amount | |
|---|---|---|---|---|
| count | 69324.000000 | 6.932400e+04 | 69324.000000 | 69324.000000 |
| mean | 11470.227569 | 1.997228e+07 | 2.416191 | 36.004598 |
| std | 6813.909552 | 3.838451e+03 | 2.337382 | 36.318874 |
| min | 1.000000 | 1.997010e+07 | 1.000000 | 1.630000 |
| 25% | 5509.750000 | 1.997022e+07 | 1.000000 | 14.490000 |
| 50% | 11414.000000 | 1.997042e+07 | 2.000000 | 25.980000 |
| 75% | 17262.250000 | 1.997111e+07 | 3.000000 | 43.730000 |
| max | 23570.000000 | 1.998063e+07 | 99.000000 | 1286.010000 |
#转换时间格式,提取月份和天数
df['order_dt'] = pd.to_datetime(df['order_dt'],format = '%Y%m%d')
df['date'] = df.order_dt.dt.date
df['month'] = df.order_dt.values.astype('datetime64[M]')
df.head()
| user_id | order_dt | order_products | order_amount | date | month | |
|---|---|---|---|---|---|---|
| 0 | 1 | 1997-01-01 | 1 | 11.77 | 1997-01-01 | 1997-01-01 |
| 1 | 2 | 1997-01-12 | 1 | 12.00 | 1997-01-12 | 1997-01-01 |
| 2 | 2 | 1997-01-12 | 5 | 77.00 | 1997-01-12 | 1997-01-01 |
| 3 | 3 | 1997-01-02 | 2 | 20.76 | 1997-01-02 | 1997-01-01 |
| 4 | 3 | 1997-03-30 | 2 | 20.76 | 1997-03-30 | 1997-03-01 |
df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 69324 entries, 0 to 69658
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 69324 non-null int64
1 order_dt 69324 non-null datetime64[ns]
2 order_products 69324 non-null int64
3 order_amount 69324 non-null float64
4 date 69324 non-null object
5 month 69324 non-null datetime64[ns]
dtypes: datetime64[ns](2), float64(1), int64(2), object(1)
memory usage: 3.7+ MB
#订单的时间范围
min(df.order_dt),max(df.order_dt)
(Timestamp('1997-01-01 00:00:00'), Timestamp('1998-06-30 00:00:00'))
该数据的订单时间是从1997-01-01到1998-06-30。
3.2 数据分析及可视化
1.总体消费情况
每个用户的消费数据
data_by_user = df.groupby('user_id').sum()
data_by_user.head()
| order_products | order_amount | |
|---|---|---|
| user_id | ||
| 1 | 1 | 11.77 |
| 2 | 6 | 89.00 |
| 3 | 16 | 156.46 |
| 4 | 7 | 100.50 |
| 5 | 29 | 385.61 |
data_by_user.describe()
| order_products | order_amount | |
|---|---|---|
| count | 23502.000000 | 23502.000000 |
| mean | 7.127053 | 106.202993 |
| std | 16.950784 | 240.494298 |
| min | 1.000000 | 3.990000 |
| 25% | 1.000000 | 19.990000 |
| 50% | 3.000000 | 43.530000 |
| 75% | 7.000000 | 106.775000 |
| max | 1033.000000 | 13925.980000 |
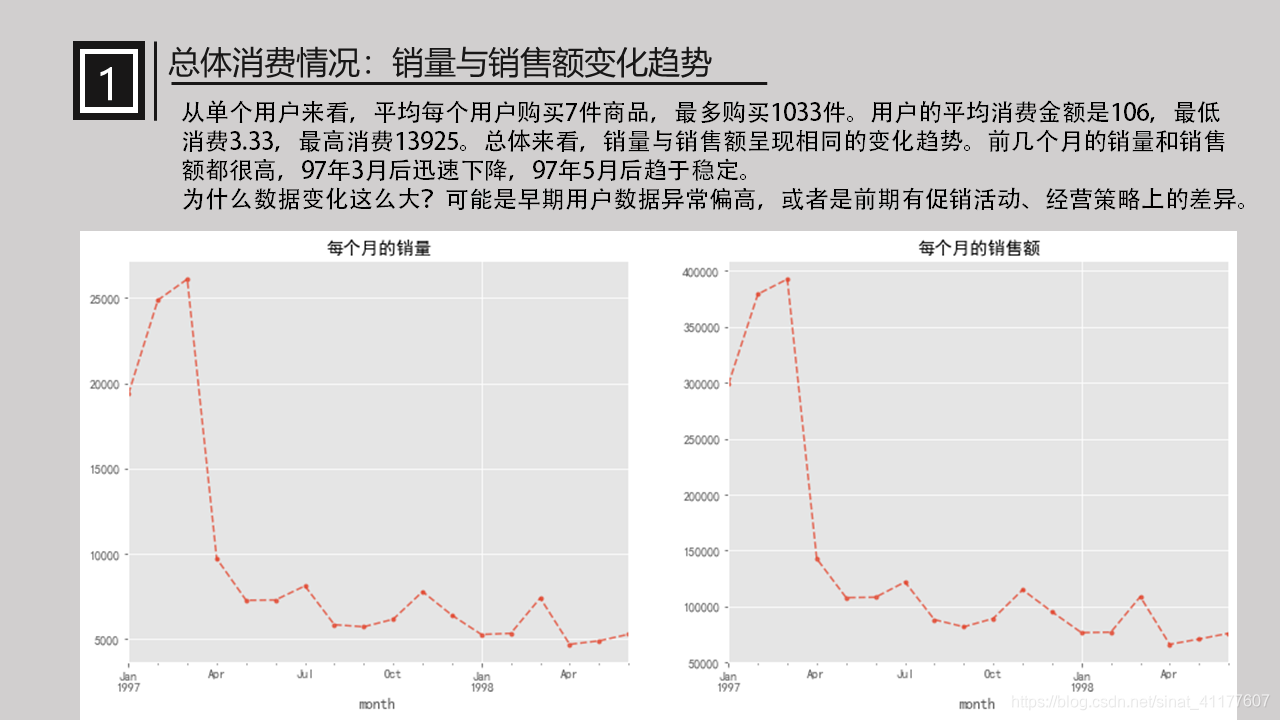
从单个用户来看,平均每个用户购买7件商品,最多购买1033件。用户的平均消费金额是106,最低消费3.33,最高消费13925。
每个月的消费数据
#每个月的销量
plt.figure(figsize = (16,6))
plt.subplot(1,2,1)
df.groupby(['month']).order_products.sum().plot(style = '--.',alpha = 0.8,grid = True)
plt.title('每个月的销量')
#每个月的销售额
plt.subplot(1,2,2)
df.groupby(['month']).order_amount.sum().plot(style = '--.',alpha = 0.8,grid = True)
plt.title('每个月的销售额')
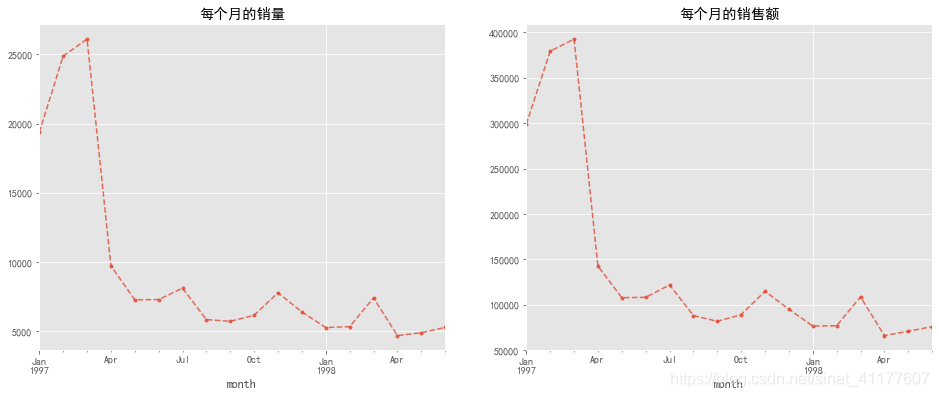
销量与销售额呈现相同的变化趋势。前几个月的销量和销售额都很高,97年3月后迅速下降,97年5月后趋于稳定。
为什么数据变化这么大?可能是早期用户数据异常偏高,或者是前期有促销活动、经营策略上的差异。
进一步分析早期用户数据是否异常:
#绘制97年5月前每笔订单的销量-销售额散点图
fig, axes = plt.subplots(1,2, figsize=(16,6))
df[df.month < pd.Timestamp('1997-05-01 00')].plot.scatter(x = 'order_amount', y = 'order_products',ax = axes[0],title = '97年5月前每笔订单的散点图')
#绘制97年5月前每个用户的销量-销售额散点图
df[df.month < pd.Timestamp('1997-05-01 00')].groupby('user_id').sum().plot.scatter(x = 'order_amount', y = 'order_products',ax = axes[1])
plt.title('97年5月前每个用户的散点图')
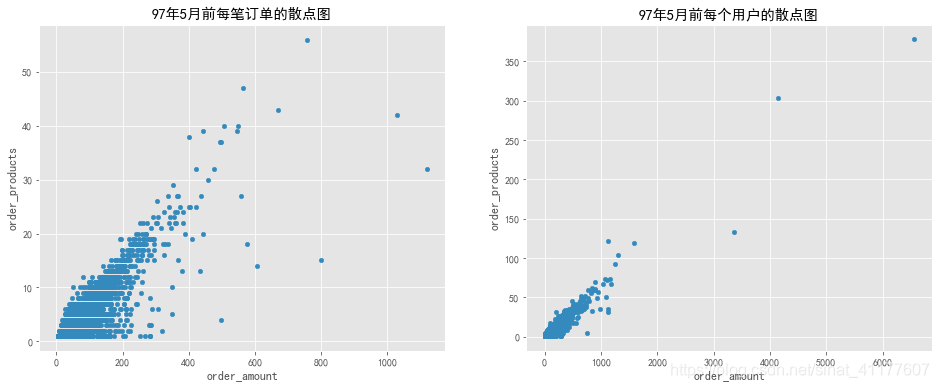
销售额与订单商品数基本呈正相关。有少部分订单销售额和商品数较大,用户数据的极值更少。因此前期数据并无异常。
用户消费能力
#用户购买量
plt.figure(figsize = (16,6))
plt.subplot(1,2,1)
df.groupby('user_id').order_products.sum().hist(bins = range(0,150,5))
plt.title('用户购买量分布直方图')
plt.xlabel('购买量')
plt.ylabel('人数')
#用户消费金额
plt.subplot(1,2,2)
df.groupby('user_id').order_amount.sum().hist(bins = range(0,1500,50))
plt.title('用户消费金额分布直方图')
plt.xlabel('消费金额')
plt.ylabel('人数')
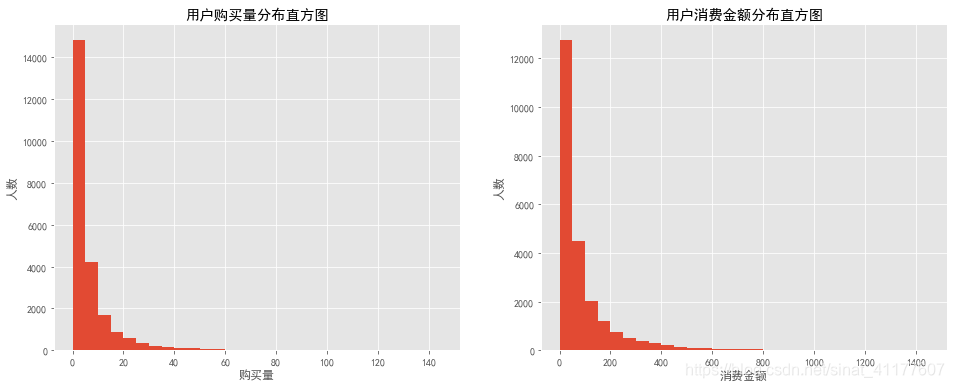
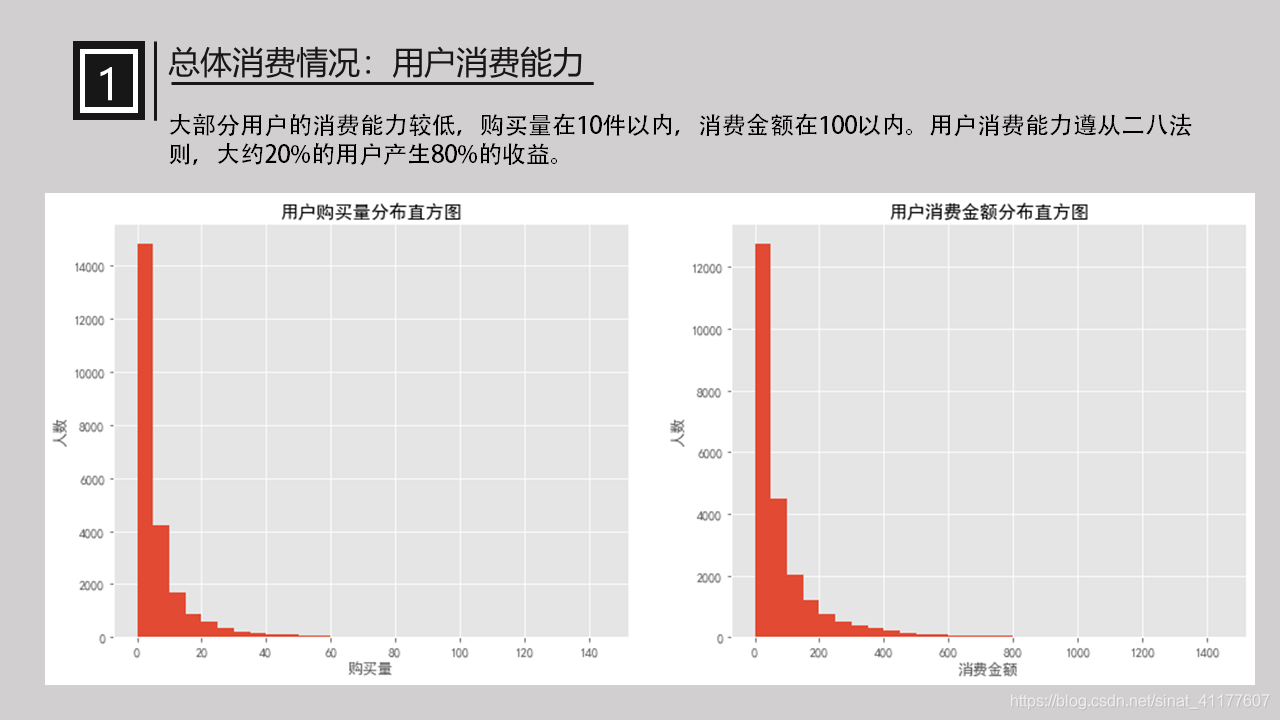
大部分用户的消费能力较低,购买量在10件以内,消费金额在100以内。用户消费能力遵从二八法则,大约20%的用户产生80%的收益。
用户消费时间
#用户第一次消费时间
pay_first = df.groupby('user_id').month.min().value_counts()
pay_first
1997-02-01 8455
1997-01-01 7814
1997-03-01 7231
1997-11-01 2
Name: month, dtype: int64
#用户最后用一次消费时间
pay_last = df.groupby('user_id').month.max().value_counts().sort_index()
pay_last
1997-01-01 4162
1997-02-01 4892
1997-03-01 4460
1997-04-01 677
1997-05-01 480
1997-06-01 499
1997-07-01 493
1997-08-01 384
1997-09-01 397
1997-10-01 455
1997-11-01 609
1997-12-01 620
1998-01-01 514
1998-02-01 551
1998-03-01 992
1998-04-01 769
1998-05-01 1042
1998-06-01 1506
Name: month, dtype: int64
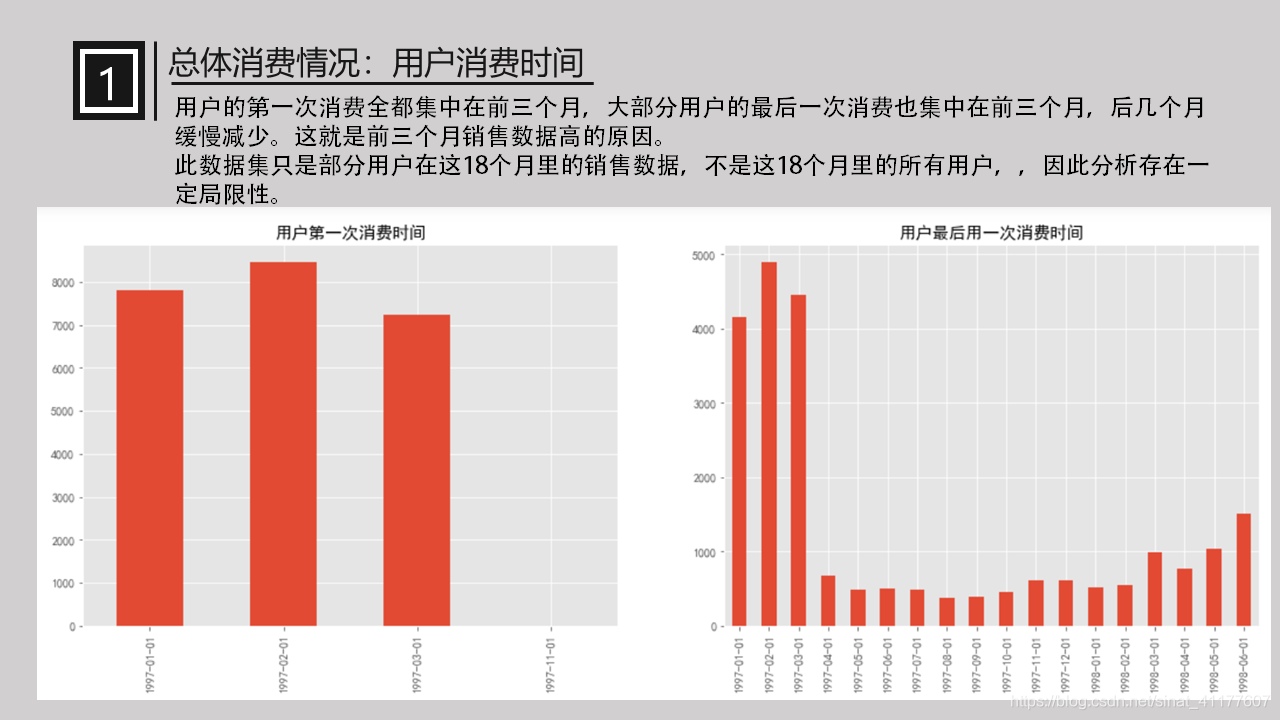
可以看出,用户的第一次消费全都集中在前三个月,大部分用户的最后一次消费也集中在前三个月,后几个月缓慢减少。这就是前三个月销售数据高的原因。
此数据集只是部分用户在这18个月里的销售数据,不是这18个月里的所有用户,因此分析存在一定局限性。
2.客户获取和留存分析
每月新增用户数
pay_first.sort_index().plot(kind = 'bar')
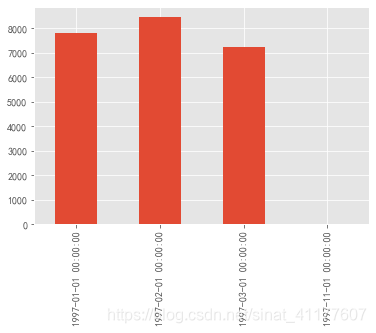
97年1月、2月、3月、11月有新增用户,其他月份没有新增用户。
月复购率与回购率
月复购率:在一个月内消费两次及以上的用户在总消费用户中占比。
月回购率:某个月内消费的用户,在下个月仍旧消费的占比。
#计算每个用户在每月的购买次数
count_by_month = pd.pivot_table(df, values = 'order_dt', index = 'user_id', columns = 'month', aggfunc = 'count').fillna(0)
count_by_month.head()
| month | 1997-01-01 | 1997-02-01 | 1997-03-01 | 1997-04-01 | 1997-05-01 | 1997-06-01 | 1997-07-01 | 1997-08-01 | 1997-09-01 | 1997-10-01 | 1997-11-01 | 1997-12-01 | 1998-01-01 | 1998-02-01 | 1998-03-01 | 1998-04-01 | 1998-05-01 | 1998-06-01 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||||||||||||
| 1 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 2.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 1.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 2.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 4 | 2.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 5 | 2.0 | 1.0 | 0.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 2.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
#将数据转换一下,消费两次及以上记为1,消费一次记为0,没有消费记为NaN
count_by_month1 = count_by_month.applymap(lambda x: 1 if x >1 else np.NaN if x == 0 else 0)
count_by_month1.head()
| month | 1997-01-01 | 1997-02-01 | 1997-03-01 | 1997-04-01 | 1997-05-01 | 1997-06-01 | 1997-07-01 | 1997-08-01 | 1997-09-01 | 1997-10-01 | 1997-11-01 | 1997-12-01 | 1998-01-01 | 1998-02-01 | 1998-03-01 | 1998-04-01 | 1998-05-01 | 1998-06-01 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||||||||||||
| 1 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 0.0 | NaN | 0.0 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | 1.0 | NaN | NaN | NaN | NaN | NaN | 0.0 | NaN |
| 4 | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 5 | 1.0 | 0.0 | NaN | 0.0 | 0.0 | 0.0 | 0.0 | NaN | 0.0 | NaN | NaN | 1.0 | 0.0 | NaN | NaN | NaN | NaN | NaN |
#计算复购率
repay_rate_by_month = count_by_month1.sum()/count_by_month1.count()
repay_rate_by_month.plot(style = '--.',alpha = 0.8,grid = True,figsize = (18,6))
plt.title('月复购率')
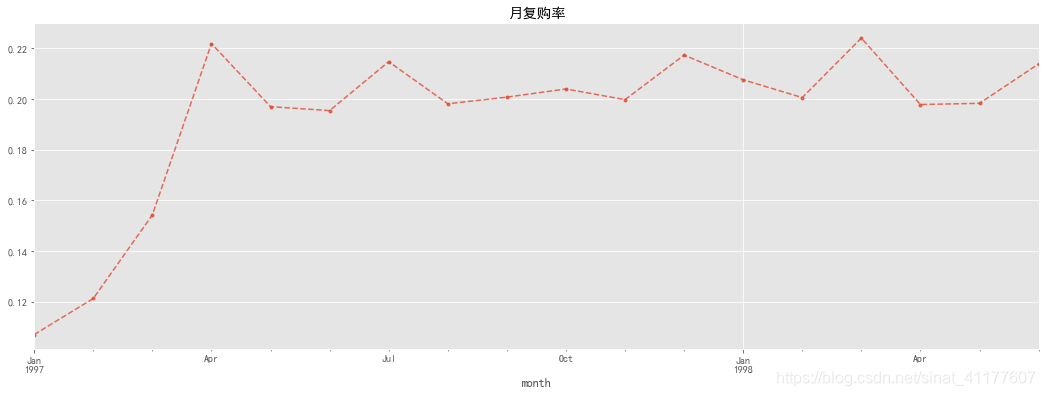
前三个月大量新客增加,因此复购率不高,在5%-15%之间,3月后的用户都是老客,复购较稳定,在20%左右。
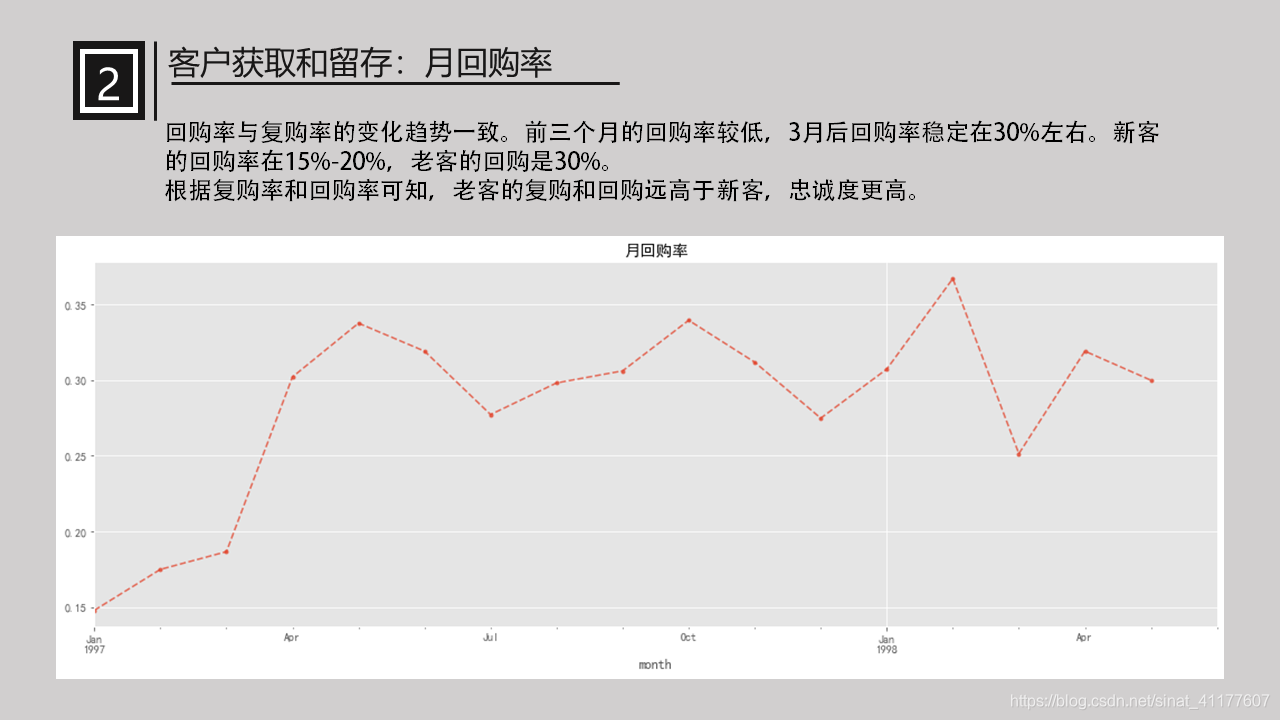
月回购率
#购买过的用户记为1,没购买过的记为0
pay_user = count_by_month.applymap(lambda x: 1 if x > 0 else 0)
pay_user.head()
| month | 1997-01-01 | 1997-02-01 | 1997-03-01 | 1997-04-01 | 1997-05-01 | 1997-06-01 | 1997-07-01 | 1997-08-01 | 1997-09-01 | 1997-10-01 | 1997-11-01 | 1997-12-01 | 1998-01-01 | 1998-02-01 | 1998-03-01 | 1998-04-01 | 1998-05-01 | 1998-06-01 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||||||||||||
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
#回购用户函数:
def pay_return(data):
pay_by_month = []
for i in range(17):#循环前17列
if data[i] == 1:
if data[i+1] == 1:
pay_by_month.append(1)#如果本月购买过,且在下月也购买过,记为1
if data[i+1] == 0:
pay_by_month.append(0)#如果本月购买过,且在下月没买,记为0
else:
pay_by_month.append(np.NaN)#其他情况记为NaN
pay_by_month.append(np.NaN)#最后一列填充NaN值
return pd.Series(pay_by_month,index = pay_user.columns)#将列表pay_by_month转换为series
pay_return_by_month = pay_user.apply(pay_return, axis = 1)#对数据集的每一行使用函数
pay_return_by_month.head()
| month | 1997-01-01 | 1997-02-01 | 1997-03-01 | 1997-04-01 | 1997-05-01 | 1997-06-01 | 1997-07-01 | 1997-08-01 | 1997-09-01 | 1997-10-01 | 1997-11-01 | 1997-12-01 | 1998-01-01 | 1998-02-01 | 1998-03-01 | 1998-04-01 | 1998-05-01 | 1998-06-01 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||||||||||||
| 1 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 0.0 | NaN | 1.0 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN | NaN | NaN | 0.0 | NaN |
| 4 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 5 | 1.0 | 0.0 | NaN | 1.0 | 1.0 | 1.0 | 0.0 | NaN | 0.0 | NaN | NaN | 1.0 | 0.0 | NaN | NaN | NaN | NaN | NaN |
#计算回购率
pay_return_rate = pay_return_by_month.sum()/pay_return_by_month.count()
pay_return_rate.plot(style = '--.',alpha = 0.8,grid = True,figsize = (18,6))
plt.title('月回购率')
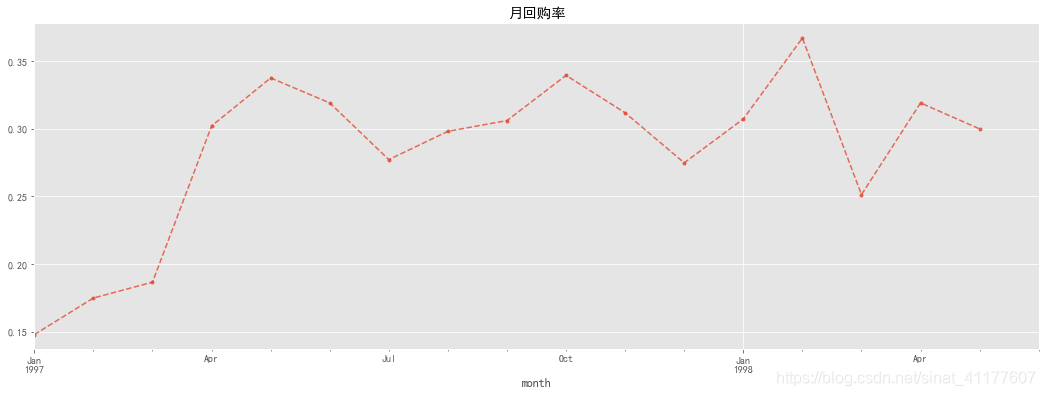
回购率与复购率的变化趋势一致。前三个月的回购率较低,3月后回购率稳定在30%左右。新客的回购率在15%-20%,老客的回购是30%。
根据复购率和回购率可知,老客的复购和回购远高于新客,忠诚度更高,
留存时间分析
将留存时间分段,分析不同留存时间与消费额、用户数的关系。
df.groupby('user_id').order_dt.min().reset_index()
| user_id | order_dt | |
|---|---|---|
| 0 | 1 | 1997-01-01 |
| 1 | 2 | 1997-01-12 |
| 2 | 3 | 1997-01-02 |
| 3 | 4 | 1997-01-01 |
| 4 | 5 | 1997-01-01 |
| ... | ... | ... |
| 23497 | 23566 | 1997-03-25 |
| 23498 | 23567 | 1997-03-25 |
| 23499 | 23568 | 1997-03-25 |
| 23500 | 23569 | 1997-03-25 |
| 23501 | 23570 | 1997-03-25 |
23502 rows × 2 columns
#计算个用户的最早消费时间
user_retention = pd.merge(df,df.groupby('user_id').order_dt.min().reset_index(),on = 'user_id',suffixes = ('','_min'))
#计算每笔订单的留存天数
user_retention['留存天数'] = (user_retention.order_dt - user_retention.order_dt_min).astype('timedelta64[D]')
user_retention.head()
| user_id | order_dt | order_products | order_amount | date | month | order_dt_min | 留存天数 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1997-01-01 | 1 | 11.77 | 1997-01-01 | 1997-01-01 | 1997-01-01 | 0.0 |
| 1 | 2 | 1997-01-12 | 1 | 12.00 | 1997-01-12 | 1997-01-01 | 1997-01-12 | 0.0 |
| 2 | 2 | 1997-01-12 | 5 | 77.00 | 1997-01-12 | 1997-01-01 | 1997-01-12 | 0.0 |
| 3 | 3 | 1997-01-02 | 2 | 20.76 | 1997-01-02 | 1997-01-01 | 1997-01-02 | 0.0 |
| 4 | 3 | 1997-03-30 | 2 | 20.76 | 1997-03-30 | 1997-03-01 | 1997-01-02 | 87.0 |
user_retention['留存天数'].max()
544.0
#给留存天数分段:
bin = [0,3,7,15,30,60,90,120,150,180,210,240,270,300,330,365,544]
user_retention['留存天数分段'] = pd.cut(user_retention['留存天数'],bins = bin)
#用户在第一次消费之后,在后续各时间段内的消费总额
pivoted_retention = user_retention.pivot_table(index = 'user_id',columns ='留存天数分段',values = 'order_amount',aggfunc = sum)
pivoted_retention.head()
| 留存天数分段 | (0, 3] | (3, 7] | (7, 15] | (15, 30] | (30, 60] | (60, 90] | (90, 120] | (120, 150] | (150, 180] | (180, 210] | (210, 240] | (240, 270] | (270, 300] | (300, 330] | (330, 365] | (365, 544] |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||||||||||
| 3 | NaN | NaN | NaN | NaN | NaN | 40.3 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 78.41 | NaN | 16.99 |
| 4 | NaN | NaN | NaN | 29.73 | NaN | NaN | NaN | NaN | NaN | NaN | 14.96 | NaN | NaN | NaN | 26.48 | NaN |
| 5 | NaN | NaN | 13.97 | NaN | 38.90 | NaN | 45.55 | 38.71 | 26.14 | 28.14 | NaN | 40.47 | NaN | NaN | 86.93 | 37.47 |
| 7 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 97.43 | NaN | NaN | 138.50 |
| 8 | NaN | NaN | NaN | NaN | 13.97 | NaN | NaN | NaN | 45.29 | 36.76 | NaN | NaN | NaN | 53.42 | 13.99 | 24.46 |
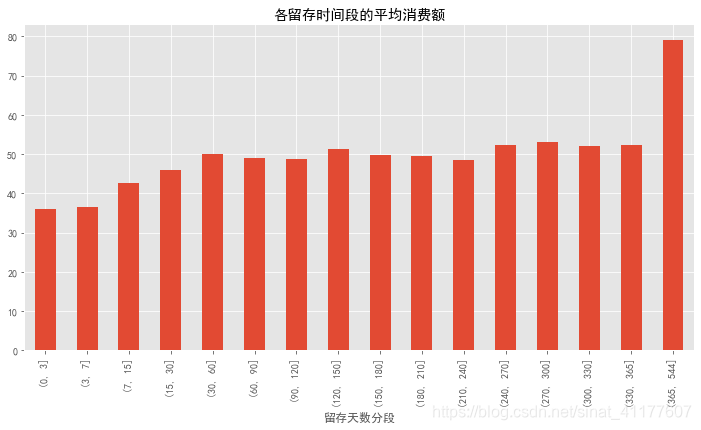
#各留存时间段的平均消费额
plt.figure(figsize = (12,6))
pivoted_retention.mean().plot.bar()
plt.title('各留存时间段的平均消费额')
#各留存时间段的用户数
pivoted_retention_counts = pivoted_retention.fillna(0).applymap(lambda x:1 if x > 0 else 0)
pivoted_retention_counts.head()
| 留存天数分段 | (0, 3] | (3, 7] | (7, 15] | (15, 30] | (30, 60] | (60, 90] | (90, 120] | (120, 150] | (150, 180] | (180, 210] | (210, 240] | (240, 270] | (270, 300] | (300, 330] | (330, 365] | (365, 544] |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||||||||||
| 3 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| 4 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| 5 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 |
| 7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 |
| 8 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 |
plt.figure(figsize = (12,6))
(pivoted_retention_counts.sum()/pivoted_retention_counts.count()).plot.bar()
plt.title('各留存时间段的用户占比')
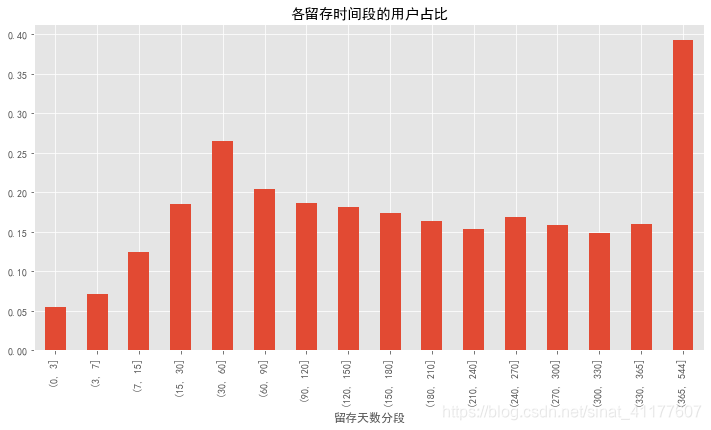
第一次消费后0-3天内、3-7天内,用户可能消费更多,但这两类用户占比只有5%和7%,显然不高。
其他留存时段的消费金额差距不大,都在50左右,所以重点比较各个时段的用户数。
第一次消费后15-30天内、30-60天内、60-90天内的客户,数量最多,占比达到18%、26%、21%,消费额接近总体平均值。因此,第一次消费后15-30天内、30-60天内、60-90天内,用户再次消费的可能性很高,是提高留存率的好时机。
用户消费周期
此处定义为距离上次购买的时间间隔。消费周期与商品属性有关,CD的消费周期显然比一般的必需品长。分析消费周期有利于召回客户、理解商品特性。
#计算每个用户每次消费距上次消费的时间间隔
def diff(data):
diffs = (data.order_dt - data.order_dt.shift(-1)).astype('timedelta64[D]')
return diffs
last_diffs = user_retention.groupby('user_id').apply(diff)
last_diffs
user_id
1 0 NaN
2 1 0.0
2 NaN
3 3 -87.0
4 -3.0
...
23568 69319 -17.0
69320 NaN
23569 69321 NaN
23570 69322 -1.0
69323 NaN
Name: order_dt, Length: 69324, dtype: float64
plt.figure(figsize = (12,6))
last_diffs.hist(bins = 50)
plt.title('用户消费周期分布图')
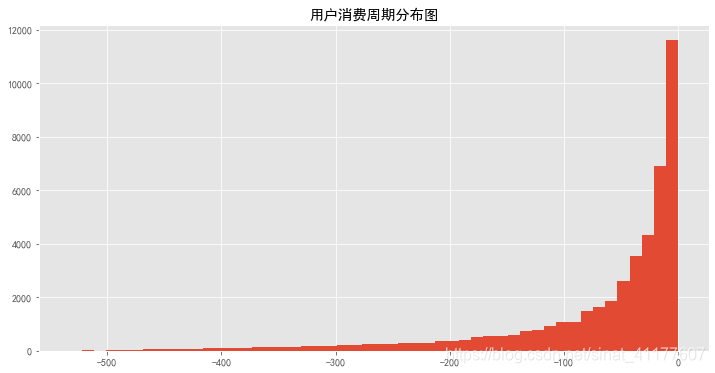
#平均消费周期
last_diffs.mean()
-69.36085286543582
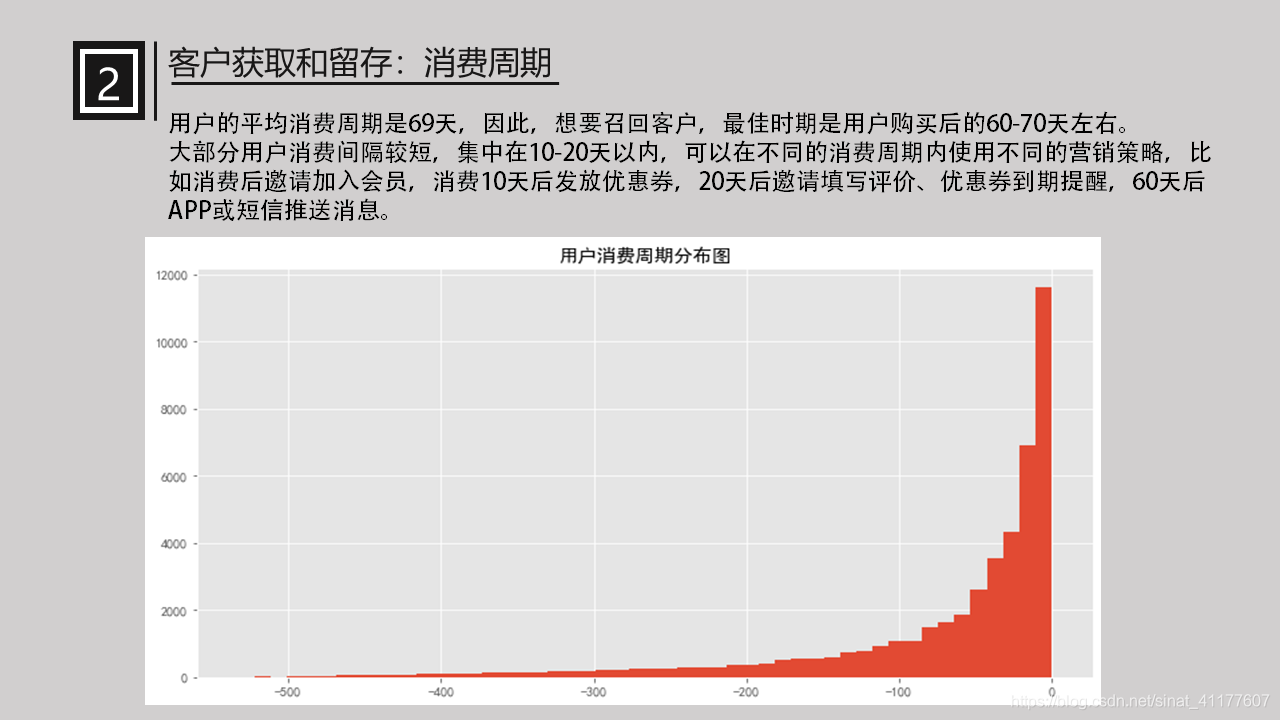
用户的平均消费周期是69天,因此,想要召回客户,最佳时期是用户购买后的60-70天左右。
大部分用户消费间隔较短,集中在10-20天以内,可以在不同的消费周期内使用不同的营销策略,比如消费后邀请加入会员,消费10天后发放优惠券,20天后邀请填写评价、优惠券到期提醒,60天后APP或短信推送消息。
3.客户价值分析
RFM用户价值分类:
R(Recency)表示客户最近一次购买时间
F(Frequency)表示客户在时间内购买的次数
M (Monetary)表示客户在时间内购买的金额。
#计算每笔订单的r
df['order_interval']= pd.to_datetime('1998-06-30')- df['order_dt']#距今购买时间
df['order_interval'] = df.order_interval.astype('timedelta64[D]')#提取天数
df.head()
| user_id | order_dt | order_products | order_amount | date | month | order_interval | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 1997-01-01 | 1 | 11.77 | 1997-01-01 | 1997-01-01 | 545.0 |
| 1 | 2 | 1997-01-12 | 1 | 12.00 | 1997-01-12 | 1997-01-01 | 534.0 |
| 2 | 2 | 1997-01-12 | 5 | 77.00 | 1997-01-12 | 1997-01-01 | 534.0 |
| 3 | 3 | 1997-01-02 | 2 | 20.76 | 1997-01-02 | 1997-01-01 | 544.0 |
| 4 | 3 | 1997-03-30 | 2 | 20.76 | 1997-03-30 | 1997-03-01 | 457.0 |
#计算RFM
rfm = df.groupby('user_id',as_index = False).agg({'order_interval': 'min', 'order_products': 'count', 'order_amount':'sum'})
rfm.columns = ['user_id','r', 'f', 'm']
rfm.head()
| user_id | r | f | m | |
|---|---|---|---|---|
| 0 | 1 | 545.0 | 1 | 11.77 |
| 1 | 2 | 534.0 | 2 | 89.00 |
| 2 | 3 | 33.0 | 6 | 156.46 |
| 3 | 4 | 200.0 | 4 | 100.50 |
| 4 | 5 | 178.0 | 11 | 385.61 |
rfm.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 23502 entries, 0 to 23501
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 23502 non-null int64
1 r 23502 non-null float64
2 f 23502 non-null int64
3 m 23502 non-null float64
dtypes: float64(2), int64(2)
memory usage: 918.0 KB
标准化处理数据
#标准化
from sklearn.preprocessing import StandardScaler#通过(X-X_mean)/std计算,使所有数据聚集在0附近
#使用 StandardScaler 来缩放数据集中的所有变量,将结果存储在 rfm_scaled 中。
rfm_scaled = StandardScaler()
#创建一个 pandas 数据帧并存储缩放的 x 变量以及 y_train。命名为 training_data 。
rfm_standar = rfm_scaled.fit_transform(rfm.iloc[:,1:])
rfm_standar = pd.DataFrame(rfm_standar,columns = ['r','f','m'])
rfm_standar['user_id'] = rfm['user_id']
rfm_standar.head()
| r | f | m | user_id | |
|---|---|---|---|---|
| 0 | 0.982776 | -0.416202 | -0.392670 | 1 |
| 1 | 0.922105 | -0.202733 | -0.071533 | 2 |
| 2 | -1.841192 | 0.651144 | 0.208978 | 3 |
| 3 | -0.920093 | 0.224205 | -0.023714 | 4 |
| 4 | -1.041436 | 1.718489 | 1.161828 | 5 |
rfm_standar.describe()
| r | f | m | user_id | |
|---|---|---|---|---|
| count | 2.350200e+04 | 2.350200e+04 | 2.350200e+04 | 23502.000000 |
| mean | 9.646781e-17 | 2.234993e-15 | 5.175729e-16 | 11789.461535 |
| std | 1.000021e+00 | 1.000021e+00 | 1.000021e+00 | 6802.223681 |
| min | -2.023206e+00 | -4.162021e-01 | -4.250212e-01 | 1.000000 |
| 25% | -8.856209e-01 | -4.162021e-01 | -3.584901e-01 | 5901.250000 |
| 50% | 5.746244e-01 | -4.162021e-01 | -2.606063e-01 | 11790.500000 |
| 75% | 7.621536e-01 | 1.073613e-02 | 2.378513e-03 | 17678.750000 |
| max | 9.827761e-01 | 4.569313e+01 | 5.746528e+01 | 23570.000000 |
采用k-measn聚类算法对客户数据进行客户分群,分成5类
from sklearn.cluster import KMeans #导入K均值聚类算法
#调用k-means算法,进行聚类分析
kmodel = KMeans(n_clusters = 5, n_jobs = 4) #n_jobs是并行数,一般等于CPU数较好
kmodel.fit(rfm_standar.iloc[:,[0,1,2]]) #训练模型
r1 = pd.DataFrame(kmodel.cluster_centers_) #各个类别的聚类中心
r2 = pd.Series(kmodel.labels_).value_counts() #统计各个类别的数目
rfm_model = pd.concat([r1,r2], axis = 1)#合并
rfm_model.columns = ['r','f','m','标签数']
rfm_model.head()
| r | f | m | 标签数 | |
|---|---|---|---|---|
| 0 | -1.267706 | 0.297815 | 0.145617 | 6469 |
| 1 | 0.650241 | -0.337605 | -0.263892 | 15789 |
| 2 | -1.651859 | 2.297280 | 2.047365 | 1168 |
| 3 | -1.745010 | 8.154730 | 9.648007 | 73 |
| 4 | -2.012175 | 39.573682 | 40.949564 | 3 |
rfm_model['各标签占比'] = rfm_model['标签数']/rfm_model['标签数'].sum()
rfm_model.head()
| r | f | m | 标签数 | 各标签占比 | |
|---|---|---|---|---|---|
| 0 | -1.267706 | 0.297815 | 0.145617 | 6469 | 0.275253 |
| 1 | 0.650241 | -0.337605 | -0.263892 | 15789 | 0.671815 |
| 2 | -1.651859 | 2.297280 | 2.047365 | 1168 | 0.049698 |
| 3 | -1.745010 | 8.154730 | 9.648007 | 73 | 0.003106 |
| 4 | -2.012175 | 39.573682 | 40.949564 | 3 | 0.000128 |
#将标签加入原数据中
rfm_standar['label'] = pd.Series(kmodel.labels_)
df = pd.merge(df, rfm_standar.iloc[:,[3,4]],on = 'user_id')
df.head()
| user_id | order_dt | order_products | order_amount | date | month | order_interval | label | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1997-01-01 | 1 | 11.77 | 1997-01-01 | 1997-01-01 | 545.0 | 1 |
| 1 | 2 | 1997-01-12 | 1 | 12.00 | 1997-01-12 | 1997-01-01 | 534.0 | 1 |
| 2 | 2 | 1997-01-12 | 5 | 77.00 | 1997-01-12 | 1997-01-01 | 534.0 | 1 |
| 3 | 3 | 1997-01-02 | 2 | 20.76 | 1997-01-02 | 1997-01-01 | 544.0 | 0 |
| 4 | 3 | 1997-03-30 | 2 | 20.76 | 1997-03-30 | 1997-03-01 | 457.0 | 0 |
df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 69324 entries, 0 to 69323
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 69324 non-null int64
1 order_dt 69324 non-null datetime64[ns]
2 order_products 69324 non-null int64
3 order_amount 69324 non-null float64
4 date 69324 non-null object
5 month 69324 non-null datetime64[ns]
6 order_interval 69324 non-null float64
7 label 69324 non-null int32
dtypes: datetime64[ns](2), float64(2), int32(1), int64(2), object(1)
memory usage: 4.5+ MB
画出密度函数
def density_plot(data): #自定义作图函数
p = data.iloc[:,[0,1,2]].plot(kind='kde', title = '标签为{}的rfm概率密度'.format(i),figsize = (12,5),linewidth = 2, subplots = True, sharex = False)
rfm_mean = [9.6, 2.2, 5.2]
[p[i].set_ylabel('density') for i in range(3)]
[p[i].axvline(x = rfm_mean[i]) for i in range(3)]
plt.legend()
return plt
for i in range(5):
density_plot(rfm_standar[rfm_standar['label']==i])
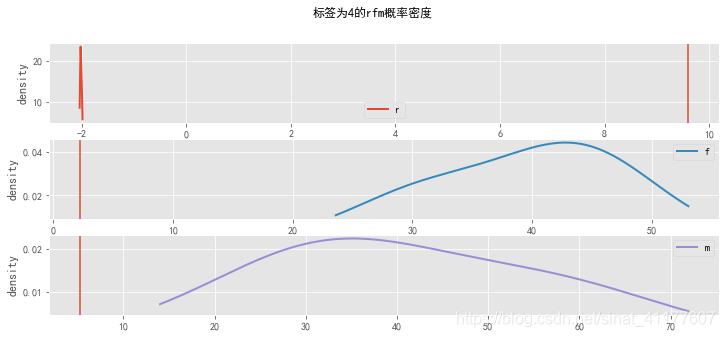
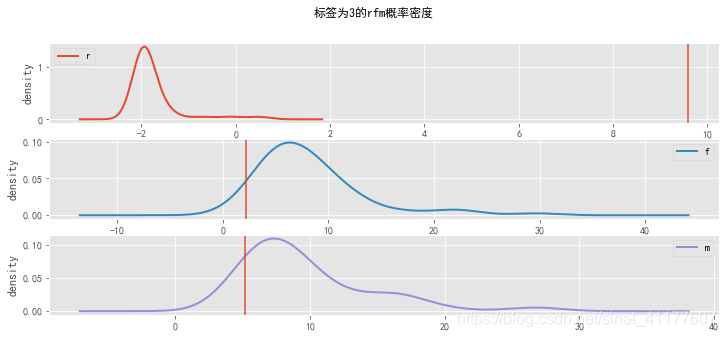
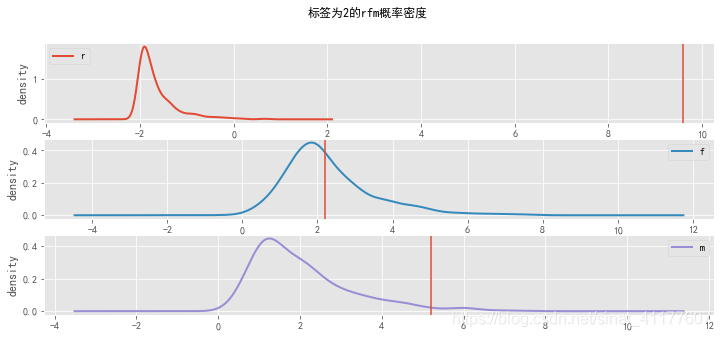
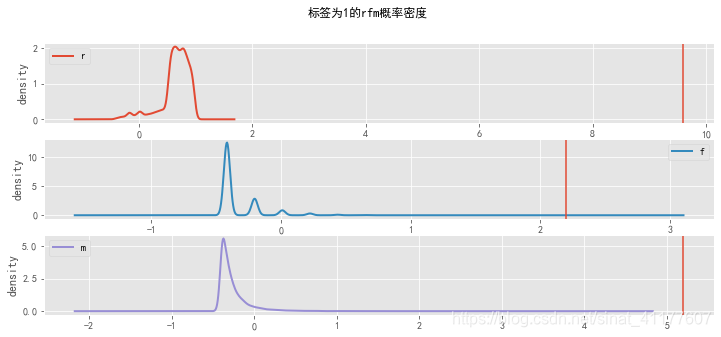
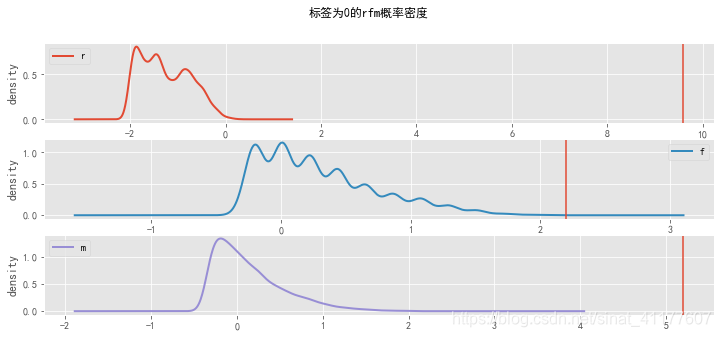
根据rfm概率密度可知,不同标签的用户有不同的特征:
标签为0的客户,R、F、M最小;标签为1的客户,在R属性上最大,在F、M属性上最小;标签为2的客户在R很小、F、M较小;标签为3的客户,R很小,F、M较大;标签为4的客户,R很小,F、M最大。
#用户分类
rfm_model['用户分类'] = ['有潜力的一般客户','一般与低价值客户','重要发展客户','重要保持客户','高价值客户']
rfm_model.head()
| r | f | m | 标签数 | 各标签占比 | 用户分类 | |
|---|---|---|---|---|---|---|
| 0 | -1.267706 | 0.297815 | 0.145617 | 6469 | 0.275253 | 有潜力的一般客户 |
| 1 | 0.650241 | -0.337605 | -0.263892 | 15789 | 0.671815 | 一般与低价值客户 |
| 2 | -1.651859 | 2.297280 | 2.047365 | 1168 | 0.049698 | 重要发展客户 |
| 3 | -1.745010 | 8.154730 | 9.648007 | 73 | 0.003106 | 重要保持客户 |
| 4 | -2.012175 | 39.573682 | 40.949564 | 3 | 0.000128 | 高价值客户 |
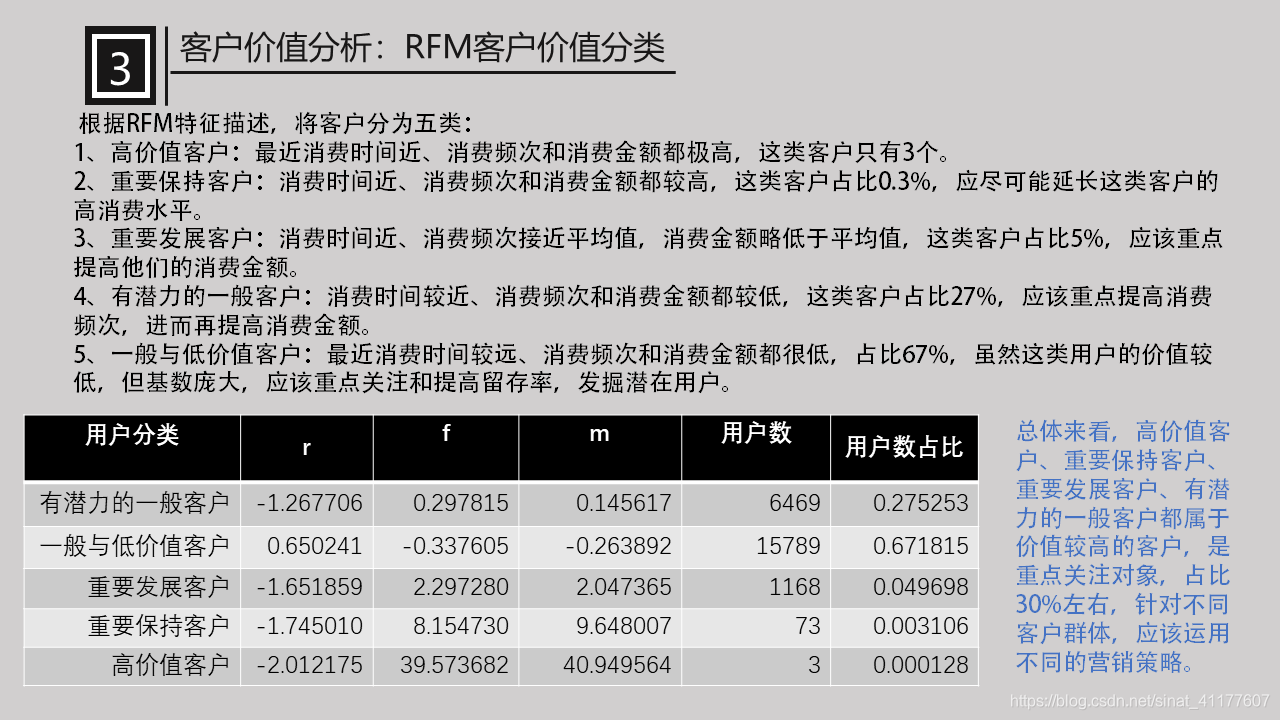
根据RFM特征描述,将客户分为五类:
1、高价值客户:最近消费时间近、消费频次和消费金额都极高,这类客户只有3个。
2、重要保持客户:消费时间近、消费频次和消费金额都较高,这类客户占比0.3%,应尽可能延长这类客户的高消费水平。
3、重要发展客户:消费时间近、消费频次接近平均值,消费金额略低于平均值,这类客户占比5%,应该重点提高他们的消费金额。
4、有潜力的一般客户:消费时间较近、消费频次和消费金额都较低,这类客户占比27%,应该重点提高消费频次,进而再提高消费金额。
5、一般与低价值客户:最近消费时间较远、消费频次和消费金额都很低,占比67%,虽然这类用户的价值较低,但基数庞大,应该重点关注和提高留存率,发掘潜在用户。
总体来看,高价值客户、重要保持客户、重要发展客户、有潜力的一般客户都属于价值较高的客户,是重点关注对象,占比30%左右,针对不同客户群体,应该运用不同的营销策略。
用户价值分析:
#每个用户的累计消费金额并排序
user_amount = df.groupby('user_id').order_amount.sum().sort_values().reset_index()
#计算用户消费金额累加值、比例
user_amount['用户累计消费金额'] = user_amount.order_amount.cumsum()
user_amount['用户累计消费比例'] = user_amount['用户累计消费金额']/user_amount['用户累计消费金额'].max()
user_amount.tail()
| user_id | order_amount | 用户累计消费金额 | 用户累计消费比例 | |
|---|---|---|---|---|
| 23497 | 7931 | 6497.18 | 2459567.66 | 0.985411 |
| 23498 | 19339 | 6552.70 | 2466120.36 | 0.988036 |
| 23499 | 7983 | 6960.08 | 2473080.44 | 0.990824 |
| 23500 | 14048 | 8976.33 | 2482056.77 | 0.994421 |
| 23501 | 7592 | 13925.98 | 2495982.75 | 1.000000 |
plt.figure(figsize = (12,6))
user_amount['用户累计消费比例'].plot()
plt.title('用户消费额累计贡献')
plt.xlabel('人数')
plt.ylabel('用户消费额累计贡献')
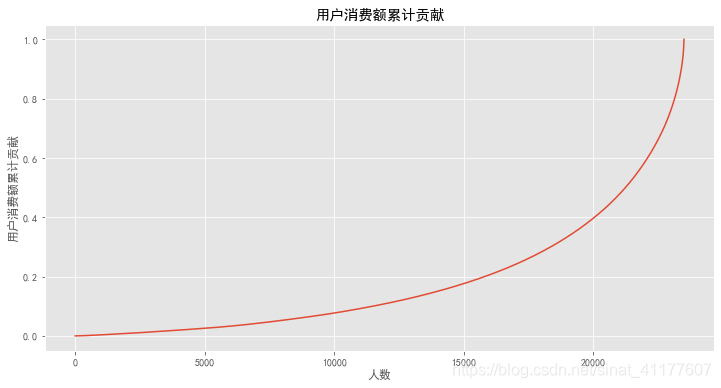
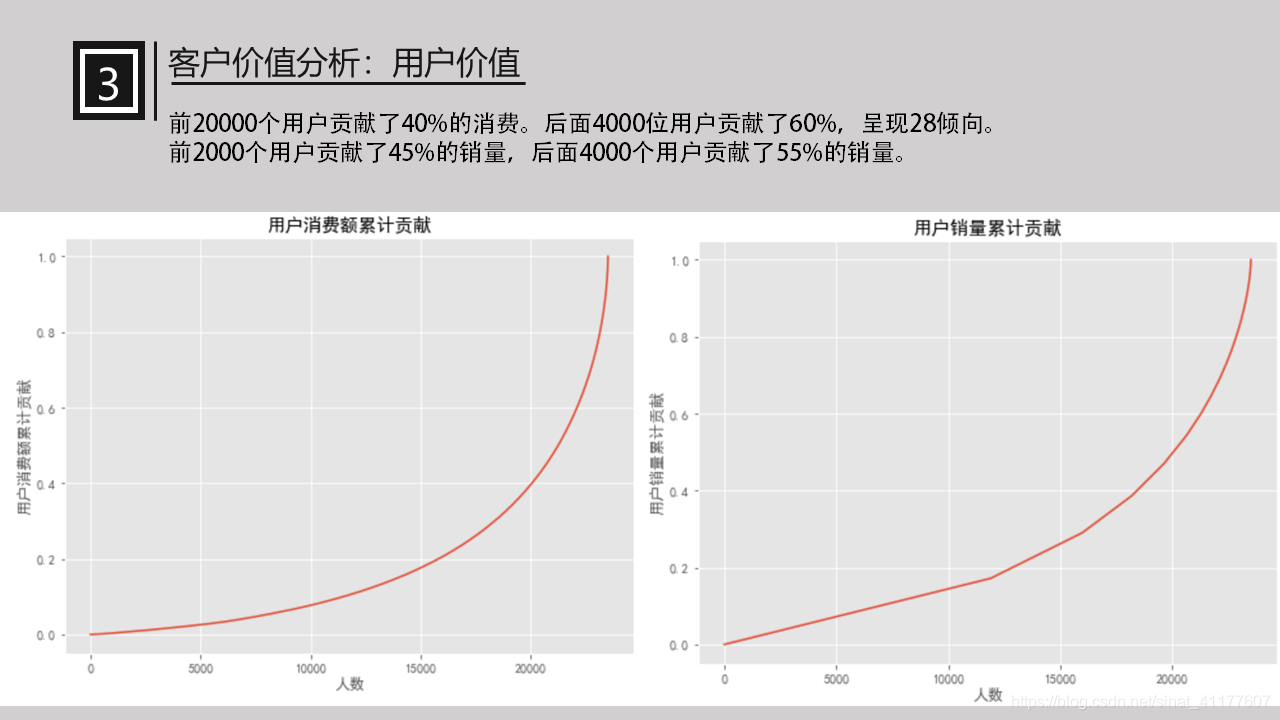
前20000个用户贡献了40%的消费。后面4000位用户贡献了60%,呈现28倾向。
#每个用户的累计销量并排序
user_counts = df.groupby('user_id').order_dt.count().sort_values().reset_index()
#计算用户销量累加值、比例
user_counts['用户累计销量'] = user_counts.order_dt.cumsum()
user_counts['用户累计销量比例'] = user_counts['用户累计销量']/user_counts['用户累计销量'].max()
user_counts.tail()
| user_id | order_dt | 用户累计销量 | 用户累计销量比例 | |
|---|---|---|---|---|
| 23497 | 3049 | 110 | 68617 | 0.989802 |
| 23498 | 22061 | 142 | 68759 | 0.991850 |
| 23499 | 7983 | 148 | 68907 | 0.993985 |
| 23500 | 7592 | 200 | 69107 | 0.996870 |
| 23501 | 14048 | 217 | 69324 | 1.000000 |
plt.figure(figsize = (12,6))
user_counts['用户累计销量比例'].plot()
plt.title('用户销量累计贡献')
plt.xlabel('人数')
plt.ylabel('用户销量累计贡献')
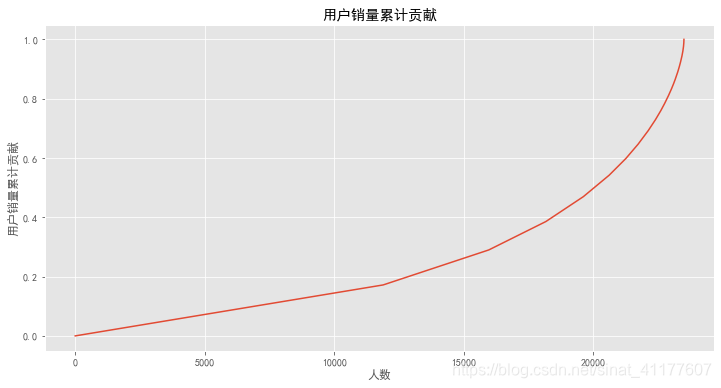
前2000个用户贡献了45%的销量,后面4000个用户贡献了55%的销量。
4.客户生命周期分析
用户生命周期是指第一次消费至最后一次消费的时间。
#用户第一次消费的时间
oder_date_min = df.groupby('user_id').order_dt.min()
#用户最后一次消费的时间
oder_date_max = df.groupby('user_id').order_dt.max()
clc = (oder_date_max - oder_date_min).astype('timedelta64[D]')
#用户平均生命周期、最长生命周期
clc.mean(), clc.max()
(135.23329929367713, 544.0)
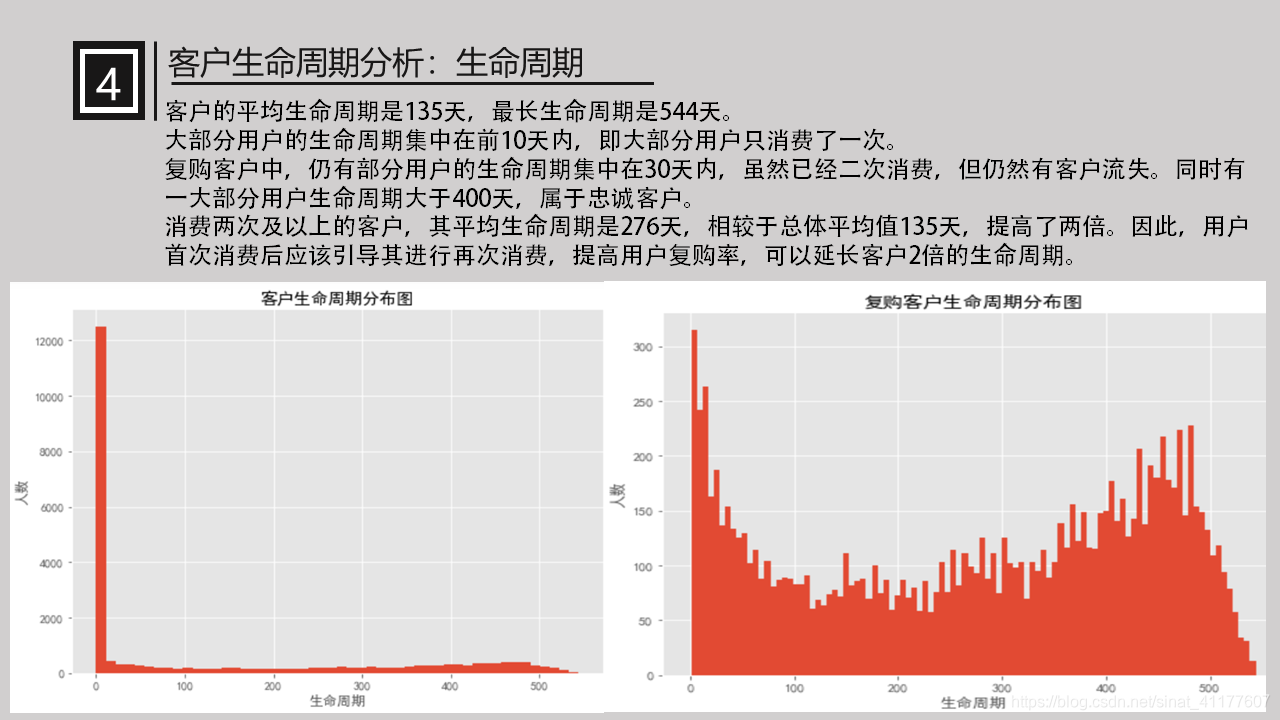
客户的平均生命周期是135天,最长生命周期是544天。
plt.figure(figsize = (12,6))
clc.hist(bins = 50)
plt.title('客户生命周期分布图')
plt.xlabel('生命周期')
plt.ylabel('人数')
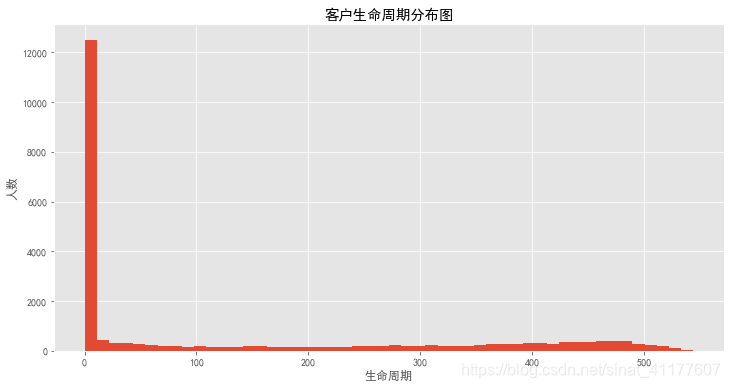
大部分用户的生命周期集中在前10天内,即大部分用户只消费了一次。
去除只消费一次的客户:
plt.figure(figsize = (12,6))
clc[clc != 0].hist(bins = 100)
plt.title('客户生命周期分布图')
plt.xlabel('生命周期')
plt.ylabel('人数')
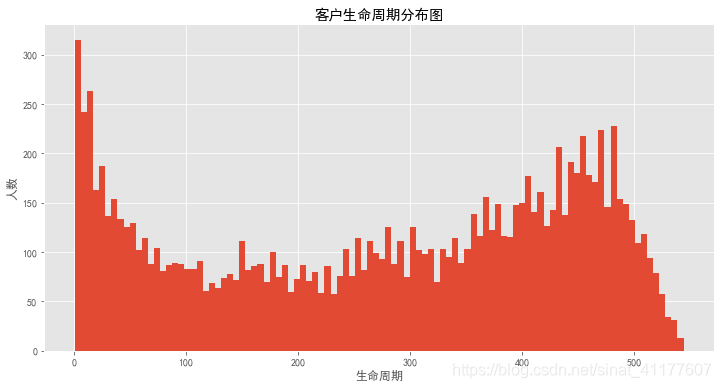
仍有部分用户的生命周期集中在30天内,虽然已经二次消费,但仍然有客户流失。同时有一大部分用户生命周期大于400天,属于忠诚客户。
#消费两次以上的用户生命平均周期
clc[clc != 0].mean()
276.05776079214803
消费两次及以上的客户,其平均生命周期是276天,相较于总体平均值135天,提高了两倍。因此,用户首次消费后应该引导其进行再次消费,提高用户复购率,可以延长客户2倍的生命周期。
分析忠诚客户:
进一步分析生命周期在400天以上的客户
clc_400 = pd.DataFrame([clc[clc >= 400]]).T.reset_index()
clc_400 = clc_400.rename(columns = {'order_dt':'clc'})
clc_400.head()
| user_id | clc | |
|---|---|---|
| 0 | 3 | 511.0 |
| 1 | 7 | 445.0 |
| 2 | 8 | 452.0 |
| 3 | 9 | 523.0 |
| 4 | 11 | 415.0 |
user_clc_400_ = pd.merge(df,clc_400.reset_index(),on = 'user_id')
user_clc_400_.head()
| user_id | order_dt | order_products | order_amount | date | month | order_interval | label | index | clc | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | 1997-01-02 | 2 | 20.76 | 1997-01-02 | 1997-01-01 | 544.0 | 0 | 0 | 511.0 |
| 1 | 3 | 1997-03-30 | 2 | 20.76 | 1997-03-30 | 1997-03-01 | 457.0 | 0 | 0 | 511.0 |
| 2 | 3 | 1997-04-02 | 2 | 19.54 | 1997-04-02 | 1997-04-01 | 454.0 | 0 | 0 | 511.0 |
| 3 | 3 | 1997-11-15 | 5 | 57.45 | 1997-11-15 | 1997-11-01 | 227.0 | 0 | 0 | 511.0 |
| 4 | 3 | 1997-11-25 | 4 | 20.96 | 1997-11-25 | 1997-11-01 | 217.0 | 0 | 0 | 511.0 |
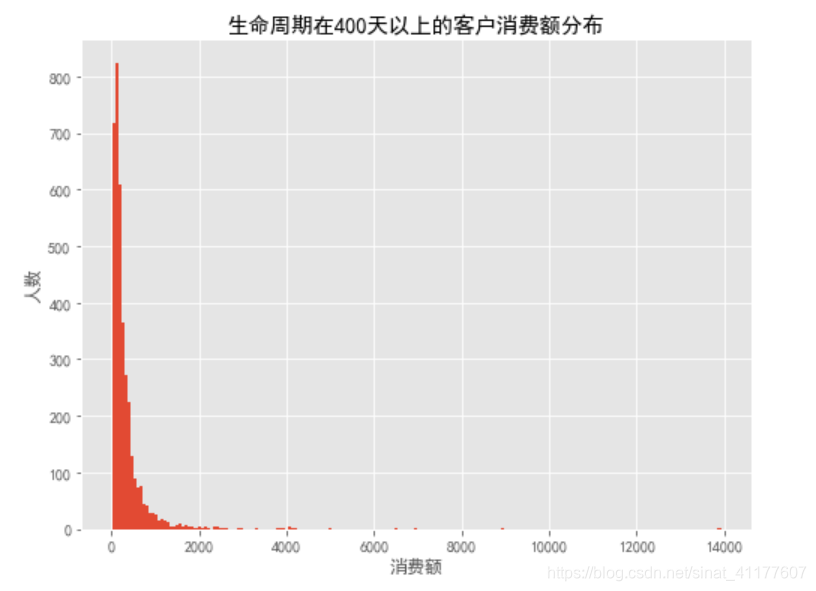
plt.figure(figsize = (8,6))
user_clc_400_.groupby('user_id').order_amount.sum().hist(bins = 200)
plt.title('生命周期在400天以上的客户消费额分布')
plt.xlabel('消费额')
plt.ylabel('人数')
#用户占比、用户消费金额占比、用户销量占比
pd.DataFrame([clc_400.user_id.count()/df.user_id.nunique(),user_clc_400_.order_amount.sum()/df.order_amount.sum(),user_clc_400_.order_dt.count()/df.order_dt.count()],index = ['用户占比','用户消费金额占比','用户销量占比'])
| 0 | |
|---|---|
| 用户占比 | 0.157178 |
| 用户消费金额占比 | 0.453051 |
| 用户销量占比 | 0.427327 |
生命周期在400天及以上的用户,大部分人的消费金额在500以内,用户数量占15.7%,消费额占45%,销量占42.7%,贡献了将近一半的营收和销量,是忠诚且价值较高的客户,应该重点关注。

















 468
468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









