




目的:
找到数据集中关于特征的描述。使用数据集中的其他变量来构建最佳模型以预测平均房价。
数据集说明:
数据集总共包含506个案例。
每种情况下,数据集都有14个属性:
| 特征 | 说明 |
|---|---|
| MedianHomePrice | 房价中位数 |
| CRIM | 人均城镇犯罪率 |
| ZN | 25,000平方英尺以上土地的住宅用地比例 |
| INDIUS | 每个城镇非零售业务英亩的比例。 |
| CHAS | 查尔斯河虚拟变量(如果束缚河,则为1;否则为0) |
| NOX- | 氧化氮浓度(百万分之一) |
| RM | 每个住宅的平均房间数 |
| AGE | 1940年之前建造的自有住房的比例 |
| DIS | 到五个波士顿就业中心的加权距离 |
| RAD | 径向公路的可达性指数 |
| TAX | 每10,000美元的全值财产税率 |
| PTRATIO | 各镇师生比例 |
| B | 1000(Bk-0.63)^ 2,其中Bk是按城镇划分的黑人比例 |
| LSTAT | 人口状况降低百分比 |
| MEDV | 自有住房的中位价格(以$ 1000为单位) |
设定库和数据。
import numpy as np
import pandas as pd
import statsmodels.api as sm
from statsmodels.stats.outliers_influence import variance_inflation_factor
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import r2_score
from patsy import dmatrices
import matplotlib.pyplot as plt
%matplotlib inline
np.random.seed(42)
#加载内置数据集,了解即可
boston_data = load_boston()
df = pd.DataFrame()
df['MedianHomePrice'] = boston_data.target
df2 = pd.DataFrame(boston_data.data)
df2.columns = boston_data.feature_names
df = df.join(df2)
df.head()
| MedianHomePrice | CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 24.0 | 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1.0 | 296.0 | 15.3 | 396.90 | 4.98 |
| 1 | 21.6 | 0.02731 | 0.0 | 7.07 | 0.0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2.0 | 242.0 | 17.8 | 396.90 | 9.14 |
| 2 | 34.7 | 0.02729 | 0.0 | 7.07 | 0.0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2.0 | 242.0 | 17.8 | 392.83 | 4.03 |
| 3 | 33.4 | 0.03237 | 0.0 | 2.18 | 0.0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3.0 | 222.0 | 18.7 | 394.63 | 2.94 |
| 4 | 36.2 | 0.06905 | 0.0 | 2.18 | 0.0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3.0 | 222.0 | 18.7 | 396.90 | 5.33 |
1.获取数据集中每个特征的汇总
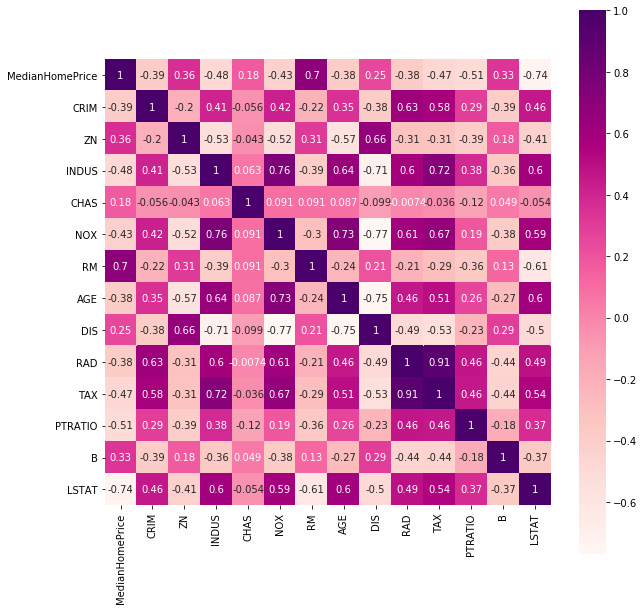
使用 corr 方法计算各变量间的相关性,判断是否存在多重线性。
#绘制热力图
import seaborn as sns
plt.subplots(figsize=(10,10))#调节图像大小
sns.heatmap(df.corr(), annot = True, vmax = 1, square = True, cmap='RdPu')
2.拆分数据集
创建一个 training 数据集与一个 test 数据集,其中20%的数据在 test 数据集中。将结果存储在 X_train, X_test, y_train, y_test 中。
X = df.drop('MedianHomePrice' , axis=1, inplace=False 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4702
4702





 到【灌水乐园】发言
到【灌水乐园】发言







