






简明教程!大模型 RL 中的策略梯度算法
作者:skydownacai@知乎
https://zhuanlan.zhihu.com/p/1891822525274637445
前言
随着大模型基建的发展,强化学习在大模型上的作用越来越重要,并且在提升推理能力方面取得了巨大的成功,例如OpenAI o1 / deepseek R1 模型。因此越来越多的人开始学习强化学习。
在目前的主流大模型的强化学习算法中,都是以策略梯度(policy gradient,简称PG) 类方法为主。因此本文尝试将PG的原理从头开始讲清楚,同时避免强化学习中的其他前置知识,让没有强化学习背景的人也能看懂。
由于作者水平有限,如果存在错误,欢迎朋友指出!
基本概念
符号 & 目标函数
大模型采用自回归式的方式生成token, 我们用符号 来表示大模型的token 生成策略。给定一个文本前缀s,下一个token a的生成概率为. 现在让我们一定程度上滥用一下符号,我们定义,对于任意一个长度为的token序列, 其中是中第 t 个token。我们用表示大模型看见文本前缀下出现token序列 的概率。根据自回归方式,容易知道token序列出现同时出现的概率等于所有token出现的概率累乘,即:
其中我们定义 。 为了提升大模型的推理能力,我们通常希望在我们的参考策略 (通常就是待优化模型本身)的置信区域内找到一个最大化奖励函数的新策略。即求解下面的优化问题
,
其中 是模型针对prompt x 的输出token序列,是 y 中的第 t 个token,是prompt的训练分布,是KL约束的系数, 红色高亮了待优化的变量。为了方便符号简单,我们用对和进行缩写。在大模型中,我们的策略是通过神经网络来输出来表征的,我们用参数来代表我们的模型参数。此时我们的token生成策略可以表示成(请注意,神经网络输出logits 配合采样temperature 才是一个完整的生成策略,因为参数 实际上既包括神经网络参数,也包括 ,但在我们的具体实践中,我们通常是不优化 )。我们用来表示我们的目标函数在参数 处的取值。
Policy Gradient
策略梯度实际上通过最简单的梯度上升的方式来求解最优参数 ,给定当前参数
其中 是学习率。下面定理给出了我们的目标函数的梯度表达式。
注意到大模型的输出 是一个token序列, 那么根据公式(1) token序列的概率计算,我们知道
其中我们定义状态 为时刻 t 处token生成的文本前缀。将上式插入到公式(3)中替换掉 ,我们可以直接得到下面的,token级别的策略梯度定理:
Theorem 2 (Token-level Policy Gradient Theorem 1) For parameterized policy ,
在自动微分框架中实现策略梯度算法
下面介绍如何在现代自动微分框架(如PyTorch)中实现策略梯度方法。这些框架支持在对静态数据batch中,通过计算一个含参 的标量损失值时,通过反向传播,进行梯度上升更新参数。这意味着这些框架只能优化静态数据中的明确出现在损失函数中的参数,而出现在输入数据分布的中的参数将不会被优化。 注意到我们的目标函数 中 出现在了 y 的期望上 (见公式(2))。因此为了在这些框架中实现策略梯度,我们需要构造替代目标函数,将参数从期望上中移动到期望内。假设当前的参数值是 , 根据(4),我们可以构造
作为我们的policy loss 函数,它是目标函数 在 处的的替代函数,可以证明对 执行一步梯度下降,实际上等价于执行原始目标函数 的一步策略梯度上升,即:
其背后的思想来自于下面的观察:首先根据(4),
因此我们可以使用 来自于当前参数策略 的数据进行优化,同时把待优化的参数只放在红色高亮处的 的计算上并计算梯度,这样使得梯度值仍然是等价的。注意到:
从而
因此 可以作为 在 处的合格的替代函数 :
-
• 参数只出现在期望内
-
• 处的梯度值和原始目标函数相等。
随机梯度下降 SGD
由于大部分场景下我们只能根据一批数据来进行更新,也就是随机梯度下降。因此根据公式(5), 我们可以在每一个训练step k , 我们可以采样N个 然后对每个采样M个独立同分布的响应输出。我们定义第 i 条prompt的第 j 条响应输出 可以表示为,,其中是的长度, 我们同时定义状态为在生成时看到的文本前缀。我们假设每个样本对的policy loss为,那么总的policy loss 可以表示成
如果每个样本对的policy loss 都是无偏的,即 ,那么整体batch上的policy loss 也是无偏的,即 。接下来,我们将具体的设计每一个样本的policy loss。
REINFORCE
REINFORCE 通过纯Monte-Carlo (MC)采样来构造 policy loss。 根据(5)中的替代函数期望表达式,还有(6)中的符号定义,REINFORCE 的 每个样本对 的policy 为
非常容易看到每个样本对的policy loss 实际上都是无偏的,即 ,因为它实际上是公式(5) 期望内部的纯粹的MC 采样。 然而,单纯的MC采样通常遭遇着巨大的方差,尤其是KL那一项。因此下面将介绍如何通过各种改进来减少REINFORCE的方差
REINFORCE with KL Trick
我们第一个要展示的改进方差的技巧,就是说明,我们不用计算整个轨迹的KL惩罚,即 ,作为(4)中 每个下标t处的token的梯度 的权重,我们只需要用从下标t开始到结束的KL惩罚,即 作为梯度的 的权重。下面定理说明了这件事情
Theorem 3 (Token-level Policy Gradient Theorem 2) For parameterized policy ,
,,
根据定理3, 改良版的REINFORCE 在每个样本对 的policy loss为
与(7)的REINFORCE的policy loss 相比,(9) 由于减少了KL项的随机变量个数,从而减少了方差。 然后(9)仍然具有方差改进的空间,这是由于最终奖励 同样存在方差(因为给定每个中间状态动作对 , 奖励 是随机)。
Policy Gradient with Q Values
一类非常流行的策略梯度算法叫Actor-Critic (AC) 算法, 目的是通过训练critic函数来减少使用累积奖励 (即LLM中的最终奖励)产生的高方差。在AC方法中,我们首先需要定义值函数 Value functions.
给定任意文本前缀s,我们定义状态值函数 是从s出发,策略从s出发进行补全的输出响应 y 获得的期望累积奖励,即
给定任意文本前缀s和token a,我们定义状态-动作值函数,为策略从文本前缀(s,a) 出发进行不全的输出响应 y 获得的期望累积奖励,即
其中
非常容易看到,在我们的定义中, . 下列定理告诉我们,我们的token级别的策略梯度 (公式(5),(8)), 实际上可以用Q value 来作为每个token梯度 处的梯度
Theorem 4 (Token-level Policy Gradient Theorem 3) For parameterized policy ,
,,
这个定理的证明实际上基于下面等式
Actor Critic 类方法 训练一个独立的函数来近似值函数 或者。 更具体的说,在每个训练step k,对每个样本对, 我们通过训练critic函数来对每个状态-动作对的Q值进行估计,即。 然后基于该估计量,构造下列的逐样本对 的policy loss
与REINFORCE的policy loss (公式7,9) 相比, (11) 通过把 替换成了进一步减少了梯度的方差。这是因为给定状态动作对,是随机的,但是是确定性的(因为是通过函数输出得到的)。 然而,由于函数近似误差的存在,不能精准的等于从而产生了偏差 (bias), 即 .
Policy Gradient with Advantages
即使我们精准的获得了Q值的估计,即 ,实际上,在有限样本的情况下,公式(11)处的policy loss 仍然有进一步减少方差的空间。假设,实际上,对 (11)处的policy loss进行一步的梯度下降,通常会增大中所有采样出来的token的概率,因为都是正数。
然而,真实的策略梯度更新,实际上是会对Q值较小的token减少概率。这种训练方差只有在batch size N 和每个prompt的采样输出数 M 充分大的时候才能被避免 (想象一下假设词表中的所有token都被采到,虽然每个token 的梯度权重,也就是Q value, 是正的,但是由于softmax 策略保证了概率之和=1,只有大的Q value 的token才会被增加概率,小的Q value 的token仍然会被降低概率。但是在有限个token被采集到的情况下,由于Q value 为正,往往是增加采集到的token的概率,没有采到的token的概率被降低)。
所以在有限的样本的情况下,我们通常需要一个baseline 项,,来决定每个状态动作对中 的概率增减方向和增减强度。下面定理告诉我们,添加一个baseline 项,在期望上是不影响梯度方向的。
Theorem 5 (Token-level Policy Gradient Theorem 4) For parameterized policy and function b ,
,,
根据定理5,我们可以使用
来作为每个样本对 的policy loss, 其中 . 一个很自然的问题是: 我们应该用哪个baseline ? 在实践中,通常选用 往往能产生较小的方差。基于此,我们定义advantage 。在实践中,我们通常使用各种方式来估计真实的advantage来计算policy loss。 直接分析公式(13)的方差通常不是那么容易也超过了本文的scope。下面式子为为什么使用 作为baseline 提供了一个比较直观的见解。注意到
即状态值函数 实际上是平均意义上距离Q函数有最小均方误差。
当前LLM中常用策略梯度算法及其变种的分析
在接下来的分析中,我们将通过一个统一的视角来分析LLM中常用的基于PG出发的RL算法。首先,我们统一不同算法的policy loss的形式。 我们采用【随机梯度下降 SGD】小节中的符号与定义。在每个训练step k , 我们采样N个 然后对每个 采样M个独立同分布的响应输出 。因此算法的policy loss,都可以采用如下形式:
红色高亮的是待优化的参数 。在当前参数 下,我们可以计算出policy loss的梯度为
其中 ,是的长度,状态为在生成时看到的文本前缀,是状态动作对的advantage 估计。首先从 (14) 我们可以知道,对于每个样本对 ,我们应该对 token loss (即下标t)求和而非求平均。
当前流行的RL算法主要集中在advantage 的不同估计方法上,因此在下面的分析中我们主要聚集 :
-
• 的估计
-
• 偏差 Bias 和 方差Variance 分析。 我们引入一些额外的符号来方便我们论述,我们记
,,
和 。
常用RL算法的advantage估计
下表总结了不同算法 的估计值。

二值奖励下的Bias和Variance分析
接下来,我们将分析这些算法在二值奖励下, 即 ,下的bias和variance。 为了简单起见,我们假设KL系数 .
Bias 分析
在bias 分析中,我们主要关注 不同advantage 估计,诱导出来的 policy loss 的梯度 是否是无偏的。我们通过两个量来分析,
-
• 1)advantage的期望值,
-
• 2)policy loss 的期望梯度 。
注意到,我们实际上可以借助第一个量,期望的advantage,来分析我们的期望梯度。这是因为,对于任意的下标 (i,j,t),
同时期望梯度满足
我们将分析结果,总结在下表中 (完整的清晰的表格与表格内容中的推导和符号定义[1]

一些可能的结论
1)由于GRPO (original/R1 version) 和 DAPO的期望梯度中,存在随prompt x 变动的项, (当前策略在prompt x处的平均正确率), (当前策略在prompt x处的平均长度) 和每个响应输出 y 的长度 T ,因此GRPO和DAPO 的期望梯度并不是真实的策略梯度。除此之外,其他算法的梯度都和真实的策略梯度相匹配
2) REINFORCE ++ 和 DR. GRPO 隐式的采用了的学习率。REINFORCE++是由于global batch normalization, DR.GRPO 是由于没有留一(RLOO进了留一baseline,没有出现隐式的学习率)
3) 由于GRPO (original/R1 version) 和DAPO中的梯度渐进存在 这一项,因此更偏好学习简单 和难的题目 ,这些题目的梯度权重更大
4) GRPO (original version) 由于长度正则项1/T的存在,更倾向于输出短且正确的答案。
5)由于存在 这一项,DAPO 更倾向于在输出平均长度更短的prompt的数据上进行学习 ( 更小的prompt,其梯度权重占比更大)
6)假设 ,当 .PPO中的Q值估计,
中critic的输出 将会占据主导,因此如果critic的输出 很烂,将会产生非常大的bias。 ORZ通过采用 ,Q值的估计将不会受critic影响,从而不会产生bias。
Variance Analysis
我们现在研究这些算法的方差。由于明确计算这些算法的方差通常很困难,因此我们主要关注token advantage 的符号,因为是作为token 梯度向量的的权重而出现,因此的符号表明了该token处的概率输出值的增减方向 (请注意,在策略优化后,token处的概率变动,并不一定和的符号完全匹配,因为策略梯度方向还受其他数据影响)。但通常来说,如果,算法都通常会尝试增加 的概率,反之亦然。我们将结果总结在下表。

一些可能的结论:
1) 由于REINFORCE没有使用baseline 项,它会尝试增加所有采集到的token的概率,无论答案是否正确。因此REINFORCE存在较大的方差。
2) 除PPO外,所有算法都使用 作为MC Q估计值。因此,无论使用何种baseline,这些算法在答案正确时通常会尝试增加token概率,在答案错误时降低token概率。因此,无论采用哪种baseline,这些算法在方差减少方面并无本质差异。使用 作为MC Q估计值确实会引入训练方差,因为轨迹的最终奖励 可能与token真实的advantage 的符号不匹配。下图是一个step-level的示例
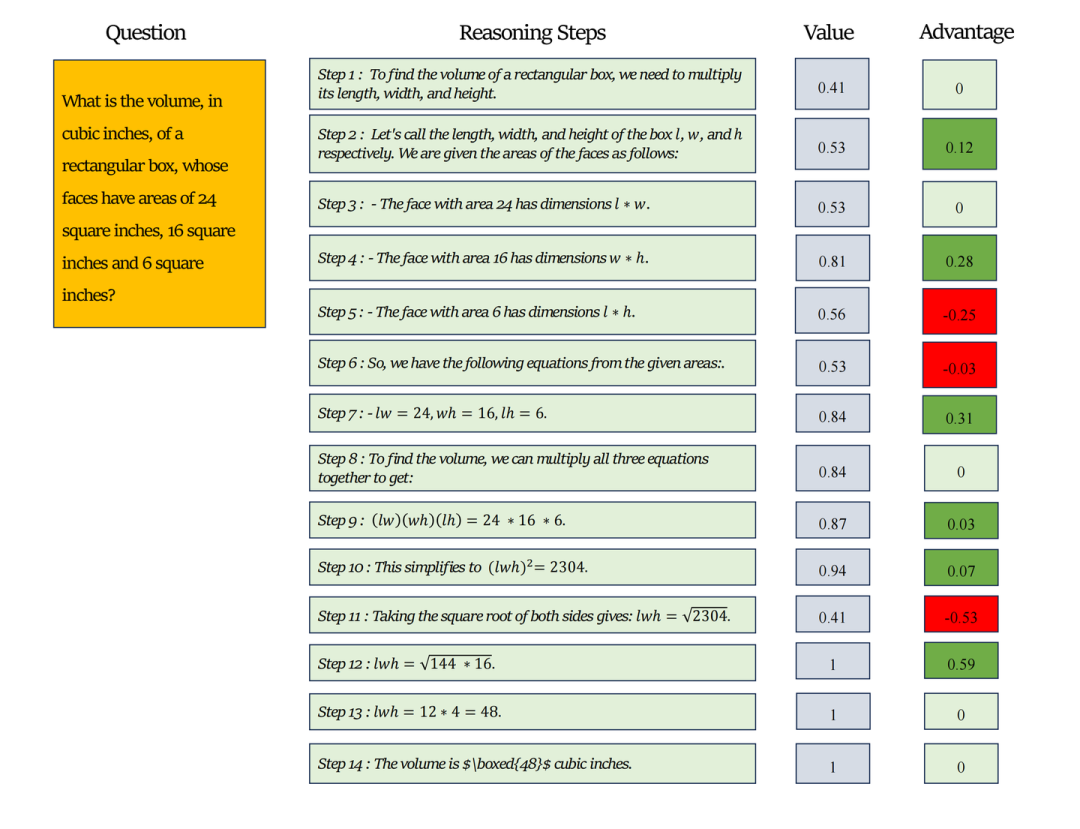
该图展示的轨迹包含14个推理步骤,是从Llama-3.1-8B-instruct模型采样得到的一条正确轨迹。图中右侧标注了每个推理步骤的value(即准确率) 和advantage。可以观察到第11步的value出现明显下降,从0.94骤降至0.41,导致advantage为-0.53。这表明模型从第11步开始更容易产生错误。因此即使最终答案正确,好的的策略更新应当降低第11步的发生概率而非提升。这说明存在这样一类轨迹:虽然轨迹最终正确答案正确,但轨迹中仍然可能包含模型易犯错的推理步骤或者token;反之也存在最终答案错误但包含好的推理步骤或token的轨迹。
3)除了PPO和ORZ外,其他所有算法,每个状态动作对 的baseline项都至多是prompt级别的,例如DR.GRPO中的 作为baseline项,并不会随着不同token 而变化。实际上,从方差的角度考虑,每个token都应该用自己的value,即 作为baseline项。但在二元奖励下,由于ORZ放弃了使用critic对Q value进行估计,使得虽然使用 作为baseline 项,但是本质上只调整了不同token处的advantage的scale(也就是绝对值大小),所有token的advantage符号都和最终轨迹奖励相匹配。因此从某种程度上来说,只有PPO能够实现token-level级别的精细策略优化。
4)PPO 的critic 如果估计良好,那么应当减少Q value的估计方差 并且产生更好的策略优化性能。话虽如此,在实际场景中,PPO 要么训不出来,要么并没有表现出相比其他算法绝对更好的性能。从题主自己的实践经验来看,其中一个关键原因是PPO的critic没训好。同时在笔者写本文的时候仍然想到了一个问题: 使用critic降低MC Q value的估计方差在二元累积奖励下到底是否关键? 我想这个问题应该是PPO和其他outcome-based算法的性能差异理论上限的主要区别。
引用链接
[1] 完整的清晰的表格与表格内容中的推导和符号定义: https://www.notion.so/Brief-Introduction-of-Policy-Gradient-In-LLM-Reasoning-1c04795a3e8b805abbd6ccc9f1a34
往期推荐






















 1138
1138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











