



一.概述
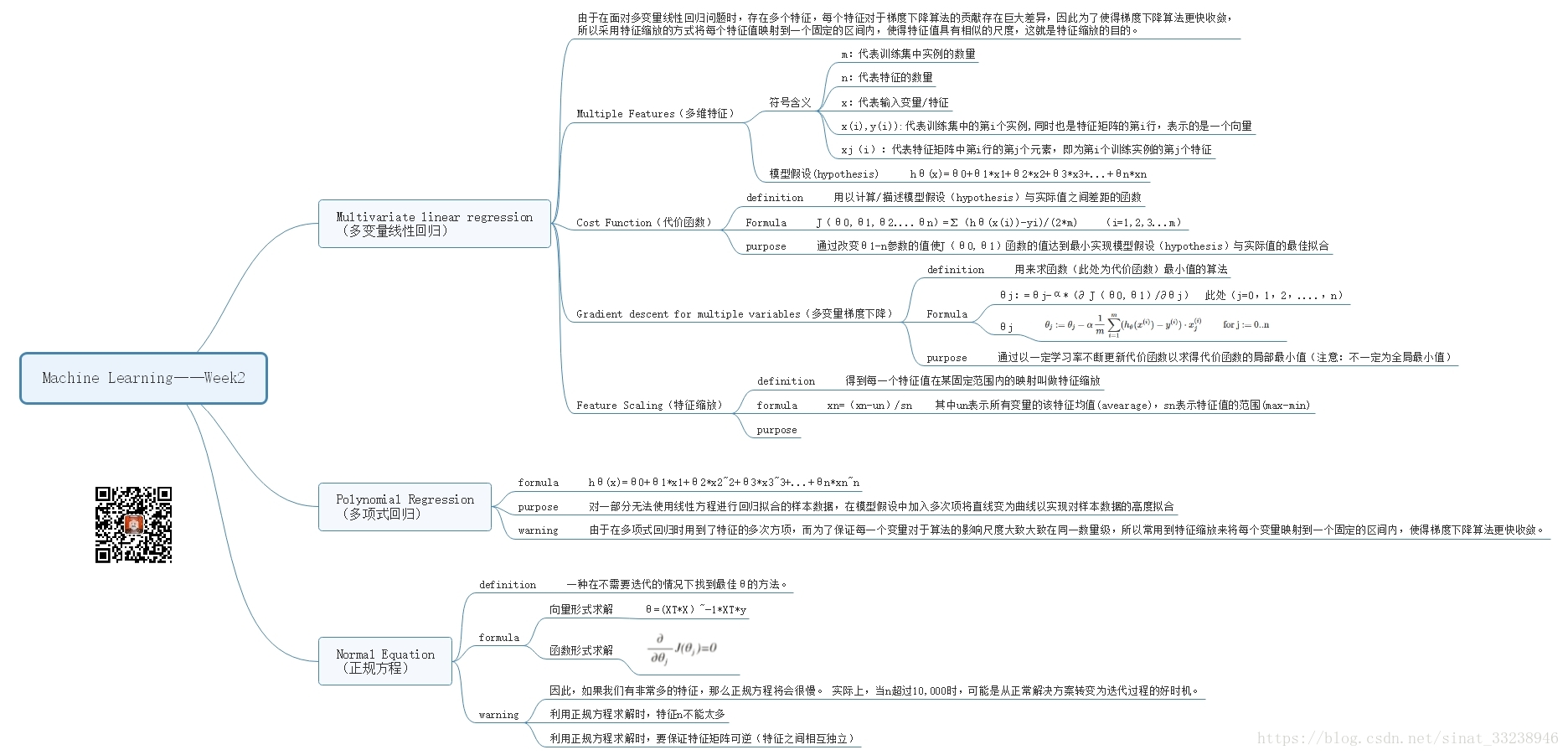
在学习过Cousera上第一周的课程后,自己也对于机器学习有了一个大致的了解,并理解了最简单机器学习问题——单变量线性回归问题的解决方式。然而实际上在日常的应用中,影响结果的特征因素个数绝不仅仅限于一个,且数据特征与结果的函数关系也不限于线性,因此可想而知,为了解决更为实际的问题,必然可以构建新的更具普适性的假设模型。所以在第二周的课程中介绍了多变量线性回归(Multivariate linear regression),多项式回归(Polynomial Regression)和正规方程(Normal Equation)三种解决机器学习问题可能会用到的方法。
(关于Machine learning by Pro.Andrew Ng 的更多资源请关注图中微信公众号——针知与拙见 获取 )
- 在第二周的学习中主要应当掌握以下几个主要概念
- 多变量线性回归(Multivariate linear regression)
- 特征归一化(Feature Normalization )
- 多项式回归(Polynomial Regression)
- 正规方程(Normal Equation)
以及其中概念所对应的函数/向量表达式
1 多变量线性回归的模型表示(Model Representation of Multivariate linear regression)
—— y^=hθ(x)=θ0+θ1x1+θ2x2+θ3x3+θ4x4+...+θnxn y ^ = h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + θ 3 x 3 + θ 4 x 4 + . . . + θ n x n
2 特征归一化(Feature Normalization )
——
xi:=xi−μisi
x
i
:=
x
i
−
μ
i
s
i
3 多项式回归(Polynomial Regression)
——
y^=hθ(x)=θ0+θ1x1+θ2x22+θ3x33+...+θnxnn
y
^
=
h
θ
(
x
)
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
2
+
θ
3
x
3
3
+
.
.
.
+
θ
n
x
n
n
4 正规方程(Normal Equation)
——
θ=(XTX)−1XTy
θ
=
(
X
T
X
)
−
1
X
T
y
二.多变量线性回归(Multivariate linear regression)
在多变量线性回归问题中,我们可以有任意多个输入变量(特征),并通过调整多个变量对于模型假设的贡献(参数 θn θ n 的大小),实现对样本数据最大程度的拟合。
为了实现上述目的,需要了解几个输入变量的定义、多变量线性回归问题所对应的模型假设、代价函数、梯度下降算法以及特征缩放。
首先对多变量线性回归问题中所需要用到的几个输入变量和模型假设进行介绍。
1.模型假设(hypothesis)
m:代表训练集中实例的数量
n=| x(i) x ( i ) | : 代表输入变量特征的数目
x(i) x ( i ) :代表训练集中的第i个实例
x(i)j x j ( i ) :代表特征矩阵中第i行的第j个元素,即为第i个训练实例的第j个特征
hypothesis function—— hθ(x)=θ0+θ1x1+θ2x2+θ3x3+θ4x4+...+θnxn h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + θ 3 x 3 + θ 4 x 4 + . . . + θ n x n
其向量表示形式为—— hθ(x)=[θ0θ1θ2...θn] h θ ( x ) = [ θ 0 θ 1 θ 2 . . . θ n ] ⎡⎣⎢⎢⎢⎢⎢⎢⎢x0x1x2⋮xn⎤⎦⎥⎥⎥⎥⎥⎥⎥ [ x 0 x 1 x 2 ⋮ x n ] =θTx = θ T x
2.代价函数(Cost Function)
definition——用以计算/描述模型假设(hypothesis)与实际值之间差距的函数
purpose——通过改变θ1-n参数的值使J(θ0,θ1)函数的值达到最小实现模型假设(hypothesis)与实际值的最佳拟合
函数形式—— J(θ)=12m∑mi=1(hθ(x(i))−y(i))2 J ( θ ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2
向量形式——
J(θ)=12m(Xθ−y⃗ )T(Xθ−y⃗ )
J
(
θ
)
=
1
2
m
(
X
θ
−
y
→
)
T
(
X
θ
−
y
→
)
y⃗
y
→
表示的是所有y值的向量
3.梯度下降(Gradient Descent for Multiple Variables)
θj:=θj−α1m∑mi=1(hθ(x(i))−y(i))x(i)jforj:=0...n θ j := θ j − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) f o r j := 0... n
三.特征归一化/规范化(Feature Normalization)——特征缩放和均值归一化
(1)特征缩放(feature scaling)
definition:用来标准化数据特征的范围
purpose:由于在面对多变量线性回归问题时,存在多个特征,每个特征对于梯度下降算法的贡献存在巨大差异,因此为了使得梯度下降算法更快收敛,所以采用特征缩放的方式将每个特征值映射到一个固定的区间内,使得特征值具有相似的尺度,这就是特征缩放的目的。
注意:特征缩放并不是必要的,我们应用它只是为了让梯度下降的速度提高。
method:特征缩放涉及将输入值x除以输入变量的范围(即最大值减去最小值),从而产生仅1的新取值范围。
举例说明:在多变量线性回归处理房价问题时, x1 x 1 表示房屋面积, x2 x 2 表示房屋所拥有房间数目。
x1=size
x
1
=
s
i
z
e
(0-2000 feet^2)
x2=
x
2
=
number of bedrooms(1-5)
在这一实例中, x1 x 1 的变化范围远大于 x2 x 2 ,在遇到这种情况时,就需要应用特征缩放。直接应用特征缩放的方法为:
x1=size(feet2)2000 x 1 = s i z e ( f e e t 2 ) 2000
x2=numberofbedrooms5 x 2 = n u m b e r o f b e d r o o m s 5
(2)均值归一化 (mean normalization)
均值归一化是在特征缩放的基础上一个改进,均值归一化是从输入值中减去输入变量的平均值,然后除以输入变量的范围。 其公式表示为:
xi:=xi−uisi x i := x i − u i s i
在上式中, ui u i 是所有输入变量的平均值, si s i 是输入变量的范围,即最大值减去最小值。
四.多项式回归(Polynomial Regression)
purpose:对一部分无法使用线性方程进行回归拟合的样本数据,在模型假设中加入多次项将直线变为曲线以实现对样本数据的高度拟合
模型假设(hypothesis function)
——
hθ(x)=θ0+θ1x1+θ2x22+θ3x33+...+θnxnn
h
θ
(
x
)
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
2
+
θ
3
x
3
3
+
.
.
.
+
θ
n
x
n
n
注意事项:由于在多项式回归时用到了特征的多次方项,而为了保证每一个变量对于算法的影响尺度大致大致在同一数量级,所以常用到特征缩放来将每个变量映射到一个固定的区间内,使得梯度下降算法更快收敛。
五.正规方程(Normal Equation)
definition:一种在不需要迭代的情况下找到最佳参数(θ)的方法。
向量形式求解
——
θ=(XTX)−1XTy
θ
=
(
X
T
X
)
−
1
X
T
y
函数形式求解
——令
∂∂θjJ(θj)=0
∂
∂
θ
j
J
(
θ
j
)
=
0
求出满足条件的参数
θ
θ
需要注意的是:
1 如果我们有非常多的特征,那么正规方程将会计算的很慢。 实际上,当n超过10,000时,可能是从正常解决方案转变为迭代过程的好时机。
2 利用正规方程求解时,特征n不能太多
3 利用正规方程求解时,要保证特征矩阵可逆(特征之间相互独立)
文中部分英文原文取自Pro.Andrew Ng 于cousera上发布的Machine learning 公开课的Week 2 Lecture Notes。其他内容均由个人整理撰写,如需要更多机器学习的学习资源欢迎关注微信公众号:针知与拙见并在后台留言。
[1] https://www.coursera.org/learn/machine-learning/
[2] 微信公众号——针知与拙见

















 1373
1373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









