







1.阈值操作:Threshold
将大于阈值的元素置为1,将小于或等于阈值的元素置为0。对应代码为:
int Threshold::forward_inplace(Mat& bottom_top_blob, const Option& opt) const
{
int w = bottom_top_blob.w;
int h = bottom_top_blob.h;
int channels = bottom_top_blob.c;
int size = w * h;
#pragma omp parallel for num_threads(opt.num_threads)
for (int q=0; q<channels; q++)
{
float* ptr = bottom_top_blob.channel(q);
// 对每个元素做阈值操作
for (int i=0; i<size; i++)
{
ptr[i] = ptr[i] > threshold ? 1.f : 0.f;
}
}
return 0;
}2.双曲正切激活:tanh
对每个元素使用tanh激活函数处理:
int TanH::forward_inplace(Mat& bottom_top_blob, const Option& opt) const
{
int w = bottom_top_blob.w;
int h = bottom_top_blob.h;
int channels = bottom_top_blob.c;
int size = w * h;
#pragma omp parallel for num_threads(opt.num_threads)
for (int q=0; q<channels; q++)
{
float* ptr = bottom_top_blob.channel(q);
// 对每个元素做tanh映射
for (int i=0; i<size; i++)
{
ptr[i] = tanh(ptr[i]);
}
}
return 0;
}3.维度压缩:squeeze
将为1的维度压缩掉,例如:a = [[[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]]],使用squeeze压缩后,b=squeeze(a)=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
int Squeeze::forward(const Mat& bottom_blob, Mat& top_blob, const Option& opt) const
{
int w = bottom_blob.w;
int h = bottom_blob.h;
int channels = bottom_blob.c;
int dims = bottom_blob.dims;
top_blob = bottom_blob;
// 对channels维度进行压缩
if (squeeze_c && dims == 3 && channels == 1)
{
// 对height维度进行压缩
if (squeeze_h && h == 1)
top_blob = bottom_blob.reshape(w, opt.blob_allocator);
else
top_blob = bottom_blob.reshape(w, h, opt.blob_allocator);
}
// 对height维度进行压缩
else if (squeeze_h && dims >= 2 && h == 1)
{
// 对width维度进行压缩
if (squeeze_w && w == 1)
top_blob = bottom_blob.reshape(channels, opt.blob_allocator);
else
top_blob = bottom_blob.reshape(w, channels, opt.blob_allocator);
}
// 对width维度进行压缩
else if (squeeze_w && dims >= 1 && w == 1)
{
// 对height维度进行压缩
if (squeeze_h && h == 1)
top_blob = bottom_blob.reshape(channels, opt.blob_allocator);
else
top_blob = bottom_blob.reshape(h, channels, opt.blob_allocator);
}
if (top_blob.empty())
return -100;
return 0;
}4.平铺操作:Tile
沿着某个维度,对输入Mat进行平铺操作,相当于将原始Mat沿着某个维度复制tiles份
int Tile::forward(const Mat& bottom_blob, Mat& top_blob, const Option& opt) const
{
int w = bottom_blob.w;
int h = bottom_blob.h;
int channels = bottom_blob.c;
size_t elemsize = bottom_blob.elemsize;
// 沿着channel方向进行平铺
if (dim == 0)
{
top_blob.create(w, h, channels * tiles, elemsize, opt.blob_allocator);
if (top_blob.empty())
return -100;
const float* ptr = bottom_blob;
int size = bottom_blob.cstep * channels;
#pragma omp parallel for num_threads(opt.num_threads)
for (int p=0; p<tiles; p++)
{
float* outptr = top_blob.channel(p * channels);
for (int i=0; i<size; i++)
{
outptr[i] = ptr[i];
}
}
}
// 沿着height方向进行平铺
else if (dim == 1)
{
top_blob.create(w, h * tiles, channels, elemsize, opt.blob_allocator);
if (top_blob.empty())
return -100;
int size = w * h;
#pragma omp parallel for num_threads(opt.num_threads)
for (int q=0; q<channels; q++)
{
const float* ptr = bottom_blob.channel(q);
float* outptr = top_blob.channel(q);
for (int p=0; p<tiles; p++)
{
for (int i=0; i<size; i++)
{
outptr[i] = ptr[i];
}
outptr += size;
}
}
}
// 沿着width方向进行平铺
else if (dim == 2)
{
top_blob.create(w * tiles, h, channels, elemsize, opt.blob_allocator);
if (top_blob.empty())
return -100;
#pragma omp parallel for num_threads(opt.num_threads)
for (int q=0; q<channels; q++)
{
const float* ptr = bottom_blob.channel(q);
float* outptr = top_blob.channel(q);
for (int i = 0; i < h; i++)
{
for (int p=0; p<tiles; p++)
{
for (int j = 0; j < w; j++)
{
outptr[j] = ptr[j];
}
outptr += w;
}
ptr += w;
}
}
}
return 0;
}5.空间金字塔池化:SPP(Spatial Pyramid Pooling)
作用就是利用池化技术,使得不同尺度输入图像都可以产生相同的输出维度,如图所示:
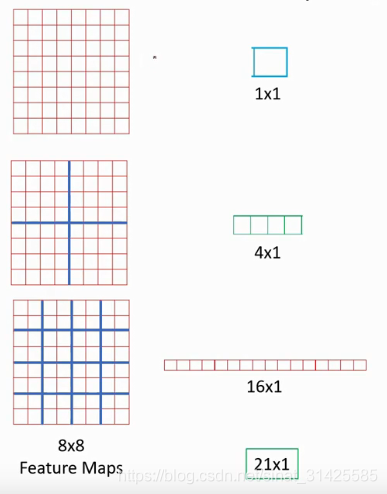
图1 单通道输入SPP示意图(摘自参考资料2)
先考虑输入的channel为1,有第一个部分,可以做一个全局的pooling,就会产生一个1x1的输出,第二个部分,可以将输入划分为2x2个区域,每个区域做一次pooling,就会得到一个4x1的输出,第三个部分,就是将图像划分为8x8个区域,每个区域做一次pooling,就会产生16x1的输出,将这些输出concat起来,就得到一个(1+4+16)x1=21x1的输出,不管输入是多大,按照这个方法都可以产生一个固定的输出维度:21x1
相同的道理,如果输入为256个channel,如图所示,按照相似的处理方法,我们可以得到21x256维的固定输出维度:
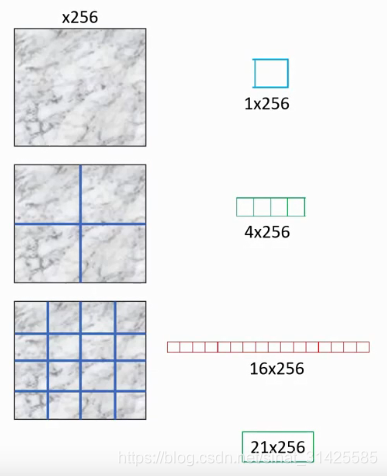
图2 channel为256的输入,对应spp原理(摘自参考资料2)
那么总的bin数目为:
求和方式也很简单,两边乘以4,有:
将两个式子相减,变形有:
有了这个式子,再看一下ncnn实现:
int SPP::forward(const Mat& bottom_blob, Mat& top_blob, const Option& opt) const
{
size_t elemsize = bottom_blob.elemsize;
// 1 + 4 + 16 + 64 + ... + (2*pyramid_height)^2
int pyramid_num_bins = ((1 << (pyramid_height * 2)) - 1) / 3;
top_blob.create(pyramid_num_bins, 1, 2, elemsize, opt.blob_allocator);
if (top_blob.empty())
return -100;
float* pyramid_ptr = top_blob;
// all spatial pyramids
for (int p = 0; p < pyramid_height; p++)
{
int w = bottom_blob.w;
int h = bottom_blob.h;
int channels = bottom_blob.c;
// 每一层总的bins为 1 << 2p
// 针对水平和垂直方向kernel大小和stride时的bins为 1 << p
int num_bins = 1 << p;
// pooing时,height方向的kernel大小和stride大小
int kernel_h = ceil(h / (float)num_bins);
int stride_h = kernel_h;
int remainder_h = stride_h * num_bins - h;
int pad_h = (remainder_h + 1) / 2;
// pooing时,width方向的kernel大小和stride大小
int kernel_w = ceil(w / (float)num_bins);
int stride_w = kernel_w;
int remainder_w = stride_w * num_bins - w;
int pad_w = (remainder_w + 1) / 2;
// max value in NxN window
// avg value in NxN window
// 输出的width和height
int outw = num_bins;
int outh = num_bins;
Mat bottom_blob_bordered = bottom_blob;
if (pad_h > 0 || pad_w > 0)
{
copy_make_border(bottom_blob, bottom_blob_bordered, pad_h, pad_h, pad_w, pad_w, BORDER_CONSTANT, 0.f, opt.workspace_allocator, opt.num_threads);
if (bottom_blob_bordered.empty())
return -100;
w = bottom_blob_bordered.w;
h = bottom_blob_bordered.h;
}
// pooling时,数组长度
const int maxk = kernel_h * kernel_w;
// kernel offsets
// 计算每个kernel对应偏移量
std::vector<int> _space_ofs(maxk);
int* space_ofs = &_space_ofs[0];
{
int p1 = 0;
int p2 = 0;
int gap = w - kernel_w;
for (int i = 0; i < kernel_h; i++)
{
for (int j = 0; j < kernel_w; j++)
{
space_ofs[p1] = p2;
p1++;
p2++;
}
p2 += gap;
}
}
if (pooling_type == PoolMethod_MAX)
{
#pragma omp parallel for num_threads(opt.num_threads)
for (int q=0; q<channels; q++)
{
// 取出第q个channel
const Mat m(w, h, bottom_blob_bordered.channel(q));
// 输出blob的指针
float* outptr = pyramid_ptr + outh * outw * q;
// 输出每个元素对应于SPP的每个划分区域
for (int i = 0; i < outh; i++)
{
for (int j = 0; j < outw; j++)
{
const float* sptr = m.row(i*stride_h) + j*stride_w;
float max = sptr[0];
// maxpooling就是取每个划分区域的最大值
for (int k = 0; k < maxk; k++)
{
float val = sptr[ space_ofs[k] ];
max = std::max(max, val);
}
outptr[j] = max;
}
outptr += outw;
}
}
}
else if (pooling_type == PoolMethod_AVE)
{
#pragma omp parallel for num_threads(opt.num_threads)
for (int q=0; q<channels; q++)
{
const Mat m(w, h, bottom_blob_bordered.channel(q));
float* outptr = pyramid_ptr + outh * outw * q;
for (int i = 0; i < outh; i++)
{
for (int j = 0; j < outw; j++)
{
const float* sptr = m.row(i*stride_h) + j*stride_w;
float sum = 0;
// average pooling就是取每个划分区域的平均值
for (int k = 0; k < maxk; k++)
{
float val = sptr[ space_ofs[k] ];
sum += val;
}
outptr[j] = sum / maxk;
}
outptr += outw;
}
}
}
pyramid_ptr += channels * outh * outw;
}
return 0;
}对着代码看一下,其实很清晰,ncnn代码写的真心棒!
6.split层
将输入blob复制n份给输出blob,对应操作为浅拷贝
对应ncnn代码为:
// 将输入blob拷贝n份,分别复制给输出blob
int Split::forward(const std::vector<Mat>& bottom_blobs, std::vector<Mat>& top_blobs, const Option& /*opt*/) const
{
const Mat& bottom_blob = bottom_blobs[0];
for (size_t i=0; i<top_blobs.size(); i++)
{
top_blobs[i] = bottom_blob;
}
return 0;
}7.softmax层
原理就不需要多说了,就是:
但是对于下面函数而言,g(x)随着x成指数增加,当x较大时,就会导致数值溢出,所以一般处理时,会对每个元素做一个减去最大值的处理,这个可以参考资料[3]。
所以,ncnn中softmax层实现时,首先会搜寻当前维度的最大值,然后每个元素减去最大值后,再使用原始的softmax公式计算:
// softmax
int Softmax::forward_inplace(Mat& bottom_top_blob, const Option& opt) const
{
// value = exp( value - global max value )
// sum all value
// value = value / sum
int dims = bottom_top_blob.dims;
size_t elemsize = bottom_top_blob.elemsize;
// 输入是一维
if (dims == 1) // axis == 0
{
int w = bottom_top_blob.w;
float* ptr = bottom_top_blob;
float max = -FLT_MAX;
// 求最大值
for (int i=0; i<w; i++)
{
max = std::max(max, ptr[i]);
}
float sum = 0.f;
// 去最大值,计算e^x并求和
for (int i=0; i<w; i++)
{
ptr[i] = exp(ptr[i] - max);
sum += ptr[i];
}
// 计算softmax
for (int i=0; i<w; i++)
{
ptr[i] /= sum;
}
return 0;
}
// 如果维度为2,并按照第1维求取softmax
// 对每一列求softmax
if (dims == 2 && axis == 0)
{
int w = bottom_top_blob.w;
int h = bottom_top_blob.h;
Mat max;
max.create(w, elemsize, opt.workspace_allocator);
if (max.empty())
return -100;
max.fill(-FLT_MAX);
// 获取每一列最大值
for (int i=0; i<h; i++)
{
// 每次取一行
const float* ptr = bottom_top_blob.row(i);
// 每一列逐个元素求最大值
for (int j=0; j<w; j++)
{
max[j] = std::max(max[j], ptr[j]);
}
}
Mat sum;
sum.create(w, elemsize, opt.workspace_allocator);
if (sum.empty())
return -100;
sum.fill(0.f);
// 每次处理一行
// 每一行逐个元素进行减去最大值,并求和
for (int i = 0; i<h; i++)
{
float* ptr = bottom_top_blob.row(i);
for (int j=0; j<w; j++)
{
ptr[j] = exp(ptr[j] - max[j]);
sum[j] += ptr[j];
}
}
// 对每一行逐个元素求softmax处理
for (int i=0; i<h; i++)
{
float* ptr = bottom_top_blob.row(i);
for (int j=0; j<w; j++)
{
ptr[j] /= sum[j];
}
}
return 0;
}
// 沿着第二维方向处理
if (dims == 2 && axis == 1)
{
int w = bottom_top_blob.w;
int h = bottom_top_blob.h;
for (int i=0; i<h; i++)
{
float* ptr = bottom_top_blob.row(i);
float m = -FLT_MAX;
for (int j=0; j<w; j++)
{
m = std::max(m, ptr[j]);
}
float s = 0.f;
for (int j=0; j<w; j++)
{
ptr[j] = exp(ptr[j] - m);
s += ptr[j];
}
for (int j=0; j<w; j++)
{
ptr[j] /= s;
}
}
return 0;
}
// 与前面的类似
if (dims == 3 && axis == 0)
{
int w = bottom_top_blob.w;
int h = bottom_top_blob.h;
int channels = bottom_top_blob.c;
int size = w * h;
Mat max;
max.create(w, h, elemsize, opt.workspace_allocator);
if (max.empty())
return -100;
max.fill(-FLT_MAX);
for (int q=0; q<channels; q++)
{
const float* ptr = bottom_top_blob.channel(q);
for (int i=0; i<size; i++)
{
max[i] = std::max(max[i], ptr[i]);
}
}
Mat sum;
sum.create(w, h, elemsize, opt.workspace_allocator);
if (sum.empty())
return -100;
sum.fill(0.f);
for (int q=0; q<channels; q++)
{
float* ptr = bottom_top_blob.channel(q);
for (int i=0; i<size; i++)
{
ptr[i] = exp(ptr[i] - max[i]);
sum[i] += ptr[i];
}
}
#pragma omp parallel for num_threads(opt.num_threads)
for (int q=0; q<channels; q++)
{
float* ptr = bottom_top_blob.channel(q);
for (int i=0; i<size; i++)
{
ptr[i] /= sum[i];
}
}
return 0;
}
if (dims == 3 && axis == 1)
{
int w = bottom_top_blob.w;
int h = bottom_top_blob.h;
int channels = bottom_top_blob.c;
Mat max;
max.create(w, channels, elemsize, opt.workspace_allocator);
if (max.empty())
return -100;
max.fill(-FLT_MAX);
#pragma omp parallel for num_threads(opt.num_threads)
for (int q=0; q<channels; q++)
{
const float* ptr = bottom_top_blob.channel(q);
float* maxptr = max.row(q);
for (int i=0; i<h; i++)
{
for (int j=0; j<w; j++)
{
maxptr[j] = std::max(maxptr[j], ptr[j]);
}
ptr += w;
}
}
Mat sum;
sum.create(w, channels, elemsize, opt.workspace_allocator);
if (sum.empty())
return -100;
sum.fill(0.f);
#pragma omp parallel for num_threads(opt.num_threads)
for (int q=0; q<channels; q++)
{
float* ptr = bottom_top_blob.channel(q);
float* maxptr = max.row(q);
float* sumptr = sum.row(q);
for (int i=0; i<h; i++)
{
for (int j=0; j<w; j++)
{
ptr[j] = exp(ptr[j] - maxptr[j]);
sumptr[j] += ptr[j];
}
ptr += w;
}
}
#pragma omp parallel for num_threads(opt.num_threads)
for (int q=0; q<channels; q++)
{
float* ptr = bottom_top_blob.channel(q);
float* sumptr = sum.row(q);
for (int i=0; i<h; i++)
{
for (int j=0; j<w; j++)
{
ptr[j] /= sumptr[j];
}
ptr += w;
}
}
return 0;
}
if (dims == 3 && axis == 2)
{
int w = bottom_top_blob.w;
int h = bottom_top_blob.h;
int channels = bottom_top_blob.c;
#pragma omp parallel for num_threads(opt.num_threads)
for (int q=0; q<channels; q++)
{
float* ptr = bottom_top_blob.channel(q);
for (int i=0; i<h; i++)
{
float max = -FLT_MAX;
for (int j=0; j<w; j++)
{
max = std::max(max, ptr[j]);
}
float sum = 0.f;
for (int j=0; j<w; j++)
{
ptr[j] = exp(ptr[j] - max);
sum += ptr[j];
}
for (int j=0; j<w; j++)
{
ptr[j] /= sum;
}
ptr += w;
}
}
return 0;
}
return 0;
}8.Slice层
将输入blob按照某个axis切分为N个部分,如输入为6*H*W,按照axis=0,将输入切分为三段,每一段对应长度分别为1,2,3,那么输出为:1*H*W,2*H*W,3*H*W,对应代码为:
int Slice::forward(const std::vector<Mat>& bottom_blobs, std::vector<Mat>& top_blobs, const Option& opt) const
{
const Mat& bottom_blob = bottom_blobs[0];
int dims = bottom_blob.dims;
size_t elemsize = bottom_blob.elemsize;
const int* slices_ptr = slices;
// 输入维度为1
if (dims == 1) // axis == 0
{
int w = bottom_blob.w;
int q = 0;
for (size_t i=0; i<top_blobs.size(); i++)
{
int slice = slices_ptr[i];
// 如果是-233就将剩余channel均匀分配
if (slice == -233)
{
slice = (w - q) / (top_blobs.size() - i);
}
// 对第i个输出分配内存
Mat& top_blob = top_blobs[i];
top_blob.create(slice, elemsize, opt.blob_allocator);
if (top_blob.empty())
return -100;
const float* ptr = (const float*)bottom_blob + q;
float* outptr = top_blob;
// 对第i个输出赋值
memcpy(outptr, ptr, slice * elemsize);
// 更新切分点
q += slice;
}
return 0;
}
// 输入为二维,在第一个维度对输入进行切分
if (dims == 2 && axis == 0)
{
int w = bottom_blob.w;
int h = bottom_blob.h;
int q = 0;
for (size_t i=0; i<top_blobs.size(); i++)
{
int slice = slices_ptr[i];
// 如果输入为-233,对后面的输出进行均匀分配
if (slice == -233)
{
slice = (h - q) / (top_blobs.size() - i);
}
// 为第i个输出分配内存
Mat& top_blob = top_blobs[i];
top_blob.create(w, slice, elemsize, opt.blob_allocator);
if (top_blob.empty())
return -100;
int size = w * slice;
const float* ptr = bottom_blob.row(q);
float* outptr = top_blob;
// 对第i个输出赋值
memcpy(outptr, ptr, size * elemsize);
// 更新切分点
q += slice;
}
return 0;
}
// 后面的与上面类似
if (dims == 2 && axis == 1)
{
int w = bottom_blob.w;
int h = bottom_blob.h;
int q = 0;
for (size_t i=0; i<top_blobs.size(); i++)
{
int slice = slices_ptr[i];
if (slice == -233)
{
slice = (w - q) / (top_blobs.size() - i);
}
Mat& top_blob = top_blobs[i];
top_blob.create(slice, h, elemsize, opt.blob_allocator);
if (top_blob.empty())
return -100;
#pragma omp parallel for num_threads(opt.num_threads)
for (int j=0; j<h; j++)
{
float* outptr = top_blob.row(j);
const float* ptr = bottom_blob.row(j) + q;
memcpy(outptr, ptr, slice * elemsize);
}
q += slice;
}
return 0;
}
if (dims == 3 && axis == 0)
{
int w = bottom_blob.w;
int h = bottom_blob.h;
int channels = bottom_blob.c;
int q = 0;
for (size_t i=0; i<top_blobs.size(); i++)
{
int slice = slices_ptr[i];
if (slice == -233)
{
slice = (channels - q) / (top_blobs.size() - i);
}
Mat& top_blob = top_blobs[i];
top_blob.create(w, h, slice, elemsize, opt.blob_allocator);
if (top_blob.empty())
return -100;
int size = bottom_blob.cstep * slice;
const float* ptr = bottom_blob.channel(q);
float* outptr = top_blob;
memcpy(outptr, ptr, size * elemsize);
q += slice;
}
return 0;
}
if (dims == 3 && axis == 1)
{
int w = bottom_blob.w;
int h = bottom_blob.h;
int channels = bottom_blob.c;
int q = 0;
for (size_t i=0; i<top_blobs.size(); i++)
{
int slice = slices_ptr[i];
if (slice == -233)
{
slice = (h - q) / (top_blobs.size() - i);
}
Mat& top_blob = top_blobs[i];
top_blob.create(w, slice, channels, elemsize, opt.blob_allocator);
if (top_blob.empty())
return -100;
#pragma omp parallel for num_threads(opt.num_threads)
for (int p=0; p<channels; p++)
{
int size = w * slice;
float* outptr = top_blob.channel(p);
const float* ptr = bottom_blob.channel(p).row(q);
memcpy(outptr, ptr, size * elemsize);
}
q += slice;
}
return 0;
}
if (dims == 3 && axis == 2)
{
int w = bottom_blob.w;
int h = bottom_blob.h;
int channels = bottom_blob.c;
int q = 0;
for (size_t i=0; i<top_blobs.size(); i++)
{
int slice = slices_ptr[i];
if (slice == -233)
{
slice = (w - q) / (top_blobs.size() - i);
}
Mat& top_blob = top_blobs[i];
top_blob.create(slice, h, channels, elemsize, opt.blob_allocator);
if (top_blob.empty())
return -100;
#pragma omp parallel for num_threads(opt.num_threads)
for (int p=0; p<channels; p++)
{
float* outptr = top_blob.channel(p);
const Mat m = bottom_blob.channel(p);
for (int j=0; j<h; j++)
{
const float* ptr = m.row(j) + q;
memcpy(outptr, ptr, slice * elemsize);
outptr += slice;
}
}
q += slice;
}
return 0;
}
return 0;
}9.Sigmoid函数
对每个输入进行sigmoid激活处理:
对应代码为:
// sigmoid函数
int Sigmoid::forward_inplace(Mat& bottom_top_blob, const Option& opt) const
{
int w = bottom_top_blob.w;
int h = bottom_top_blob.h;
int channels = bottom_top_blob.c;
int size = w * h;
#pragma omp parallel for num_threads(opt.num_threads)
for (int q=0; q<channels; q++)
{
float* ptr = bottom_top_blob.channel(q);
// 对每个输入进行sigmoid处理
for (int i=0; i<size; i++)
{
ptr[i] = 1.f / (1.f + exp(-ptr[i]));
}
}
return 0;
}10.ShuffleChannel
精简的CNN网络都会采用Group Convolution技术,进而降低运算量,但是Group之间的特征图不会发生共享,导致每一个filter只能对部分特征可见,降低了模型的表征能力。为了降低group convolution对于模型表征能力的影响,会在Group convolution的特征图后面加入shuffle处理,使得接下来的group convolution filters可以在每个group输出的部分channel上进行计算,参考资料[4]。
ncnn对应的ShuffleChannel代码其实就是:
首先,将输入的channel分为group个组,每个组对应channel数目为:
然后,打乱顺序:
如图所示:
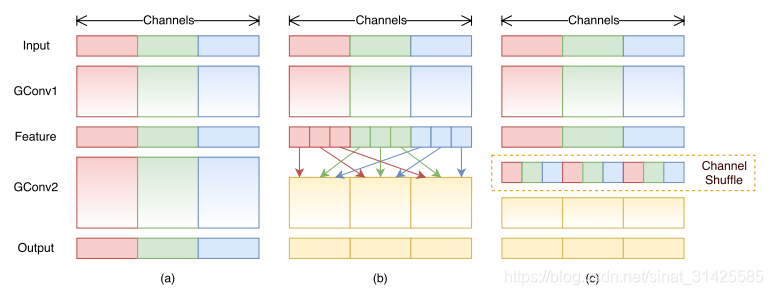
图3 Channel Shuffle示意图(摘自参考资料[5])
对应ncnn代码为:
// 将channel进行分组
int ShuffleChannel::forward(const Mat& bottom_blob, Mat& top_blob, const Option& opt) const
{
int w = bottom_blob.w;
int h = bottom_blob.h;
int c = bottom_blob.c;
size_t elemsize = bottom_blob.elemsize;
// 每个group对应channel数目
int chs_per_group = c / group;
if (c != chs_per_group * group)
{
// reject invalid group
return -100;
}
top_blob.create(w, h, c, elemsize, opt.blob_allocator);
if (top_blob.empty())
return -100;
const size_t feature_sz = w * h * elemsize;
// 遍历group
for (int i = 0; i != group; i++)
{
// 遍历每个group对应channel
for (int j = 0; j != chs_per_group; j++)
{
// src上第i个group的第j个channel
int src_q = chs_per_group * i + j;
// dst上第j个group第i个channel
int dst_q = group * j + i;
memcpy(top_blob.channel(dst_q), bottom_blob.channel(src_q), feature_sz);
}
}
return 0;
}11.SELU激活函数
计算公式为:
// SELU激活函数
int SELU::forward_inplace(Mat& bottom_top_blob, const Option& opt) const
{
int w = bottom_top_blob.w;
int h = bottom_top_blob.h;
int channels = bottom_top_blob.c;
int size = w * h;
float alphaxlambda = alpha * lambda;
#pragma omp parallel for num_threads(opt.num_threads)
for (int q=0; q<channels; q++)
{
float* ptr = bottom_top_blob.channel(q);
// 计算SELU
for (int i=0; i<size; i++)
{
if (ptr[i] < 0.f)
ptr[i] = (exp(ptr[i]) - 1.f) * alphaxlambda;
else
ptr[i] *= lambda;
}
}
return 0;
}12.Scale操作
很简单,计算公式为:
对应ncnn代码为:
int Scale::forward_inplace(std::vector<Mat>& bottom_top_blobs, const Option& opt) const
{
Mat& bottom_top_blob = bottom_top_blobs[0];
const Mat& scale_blob = bottom_top_blobs[1];
int dims = bottom_top_blob.dims;
if (dims == 1)
{
int w = bottom_top_blob.w;
float* ptr = bottom_top_blob;
// 如果有bias
if (bias_term)
{
#pragma omp parallel for num_threads(opt.num_threads)
for (int i=0; i<w; i++)
{
ptr[i] = ptr[i] * scale_blob[i] + bias_data[i];
}
}
else
{
// 如果没有bias
#pragma omp parallel for num_threads(opt.num_threads)
for (int i=0; i<w; i++)
{
ptr[i] *= scale_blob[i];
}
}
}
// 二维矩阵
if (dims == 2)
{
int w = bottom_top_blob.w;
int h = bottom_top_blob.h;
if (bias_term)
{
#pragma omp parallel for num_threads(opt.num_threads)
for (int i=0; i<h; i++)
{
float* ptr = bottom_top_blob.row(i);
float s = scale_blob[i];
float bias = bias_data[i];
// 与上面的类似
for (int j=0; j<w; j++)
{
ptr[j] = ptr[j] * s + bias;
}
}
}
else
{
#pragma omp parallel for num_threads(opt.num_threads)
for (int i=0; i<h; i++)
{
float* ptr = bottom_top_blob.row(i);
float s = scale_blob[i];
// 不存在bias
for (int j=0; j<w; j++)
{
ptr[j] *= s;
}
}
}
}
// 三维矩阵
if (dims == 3)
{
int w = bottom_top_blob.w;
int h = bottom_top_blob.h;
int channels = bottom_top_blob.c;
int size = w * h;
if (bias_term)
{
#pragma omp parallel for num_threads(opt.num_threads)
for (int q=0; q<channels; q++)
{
float* ptr = bottom_top_blob.channel(q);
float s = scale_blob[q];
float bias = bias_data[q];
for (int i=0; i<size; i++)
{
ptr[i] = ptr[i] * s + bias;
}
}
}
else
{
#pragma omp parallel for num_threads(opt.num_threads)
for (int q=0; q<channels; q++)
{
float* ptr = bottom_top_blob.channel(q);
float s = scale_blob[q];
for (int i=0; i<size; i++)
{
ptr[i] *= s;
}
}
}
}
return 0;
}13.roipooling操作
roipooling源自于faster rcnn网络,rcnn网络检测目标物体的思路为:先使用推断出有限的最可能存在物体的位置,再进行分类和回归,得到最终精确的目标位置,采用这个流程的目标检测方法也称为二阶段检测方法,这里不是解读faster rcnn算法,就不做深究了,但是理解roipooling,还是需要理解一下faster rcnn的思路,最原始的rcnn采用的方法是:直接在原始图像上使用region proposal技术生成2K个可能的目标位置,然后将对应图像块抠出来resize到一个固定大小放到神经网络中进行训练,生成的2K个区域每一个都需要放到神经网络中进行一次前向传播,训练耗时不说,还十分耗费资源;于是,作者就对其进行了改进,由于cnn网络每个神经元与输入其实存在着空间位置的对应关系,我们只需要将原始图像放到cnn网络中进行一次前向传播,就可以基于roi与特征图之间对应关系找到每个roi在feature map上的对应位置关系,然后采用roi pooling技术将不等尺寸的输入执行最大池化操作,以获得固定尺寸的特征映射,但是任然存在一个问题,前面候选区域生成还是采用的图像处理方法,无法直接放到gpu上进行训练,于是就有了faster rcnn,faster rcnn内嵌了一个rpn网络,取代了前面的region proposal功能,实现了一个端到端的训练过程,大大提升了模型训练效率(有点扯远了),具体可以参考资料[6]:
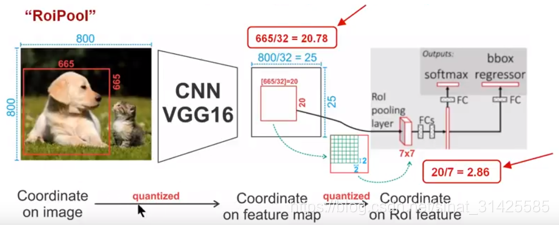
roipool需要进行三个步骤:
(1)找roi从输入到feature map的对应关系:
如图所示,输入尺寸为800x800,feature map尺寸为25x25
那么对应feat_stride = 800 / 25 = 32,也就是说,将输入上roi除以32,就可以得到对应于feature map上roi位置,如:
roi大小为665x665,对应于feature map上roi大小为:665/32 x 665/32 = 20.78 x 20.78,做一个向下取整操作有:20 x 20,从20.78到20的过程称为第一次量化。
(2)feature map 到roi pooling 输出的区域划分:
由于我们需要得到pool_w x pool_h的输出,所以需要将feature map上的roi划分为pool_w x pool_h个区域,那么每个区域对应的width和height为:
如,roipooling的最终尺寸为7x7,那么每个区域的width和height为:
实际计算会对2.86取整,这就是第二次量化,得到每个区域大小为2x2
(3)对每个区域做maxpooling操作。
具体代码如下:
int ROIPooling::forward(const std::vector<Mat>& bottom_blobs, std::vector<Mat>& top_blobs, const Option& opt) const
{
const Mat& bottom_blob = bottom_blobs[0];
int w = bottom_blob.w;
int h = bottom_blob.h;
size_t elemsize = bottom_blob.elemsize;
int channels = bottom_blob.c;
// 读取roi参数
const Mat& roi_blob = bottom_blobs[1];
// 为输出blob分配空间
Mat& top_blob = top_blobs[0];
top_blob.create(pooled_width, pooled_height, channels, elemsize, opt.blob_allocator);
if (top_blob.empty())
return -100;
// For each ROI R = [x y w h]: max pool over R
// 读取roi:[x, y, width, height]
const float* roi_ptr = roi_blob;
// 计算在feature map上的roi
int roi_x1 = round(roi_ptr[0] * spatial_scale);
int roi_y1 = round(roi_ptr[1] * spatial_scale);
int roi_x2 = round(roi_ptr[2] * spatial_scale);
int roi_y2 = round(roi_ptr[3] * spatial_scale);
// 计算feature map上roi的宽度和高度
int roi_w = std::max(roi_x2 - roi_x1 + 1, 1);
int roi_h = std::max(roi_y2 - roi_y1 + 1, 1);
// 需要将feature map上的roi分解成pooled_width x pooled_height个region
// 计算每个region对应长度
float bin_size_w = (float)roi_w / (float)pooled_width;
float bin_size_h = (float)roi_h / (float)pooled_height;
#pragma omp parallel for num_threads(opt.num_threads)
for (int q=0; q<channels; q++)
{
const float* ptr = bottom_blob.channel(q);
float* outptr = top_blob.channel(q);
for (int ph = 0; ph < pooled_height; ph++)
{
for (int pw = 0; pw < pooled_width; pw++)
{
// Compute pooling region for this output unit:
// start (included) = floor(ph * roi_height / pooled_height)
// end (excluded) = ceil((ph + 1) * roi_height / pooled_height)
// 计算每个region的坐标位置
int hstart = roi_y1 + floor((float)(ph) * bin_size_h);
int wstart = roi_x1 + floor((float)(pw) * bin_size_w);
int hend = roi_y1 + ceil((float)(ph + 1) * bin_size_h);
int wend = roi_x1 + ceil((float)(pw + 1) * bin_size_w);
// 越界检查
hstart = std::min(std::max(hstart, 0), h);
wstart = std::min(std::max(wstart, 0), w);
hend = std::min(std::max(hend, 0), h);
wend = std::min(std::max(wend, 0), w);
// 判断region是否为空
bool is_empty = (hend <= hstart) || (wend <= wstart);
// 赋初值
float max = is_empty ? 0.f : ptr[hstart * w + wstart];
// maxpooling
for (int y = hstart; y < hend; y++)
{
for (int x = wstart; x < wend; x++)
{
int index = y * w + x;
max = std::max(max, ptr[index]);
}
}
outptr[pw] = max;
}
// 更新输出指针
outptr += pooled_width;
}
}
return 0;
}14.roialign操作
前面的roipooling存在一个很严重的问题,那就是两次量化之后存在较大偏差,这对于后面回归任务而言毕然造成影响,因此,就有了roialign,和前面roipooling不同的是:直接采用浮点数计算,不进行向下取整的过程,最后计算pooling的区域大小后,对区域中每个元素采用双线性插值的形式计算后求均值或maxpooling得到,具体过程如下:
(1)找roi从输入到feature map的对应关系:
如图上面图所示,输入尺寸为800x800,feature map尺寸为25x25
那么对应feat_stride = 800 / 25 = 32,也就是说,将输入上roi除以32,就可以得到对应于feature map上roi位置,如:
roi大小为665x665,对应于feature map上roi大小为:665/32 x 665/32 = 20.78 x 20.78。
(2)feature map 到roi pooling 输出的区域划分:
由于我们需要得到pool_w x pool_h的输出,所以需要将feature map上的roi划分为pool_w x pool_h个区域,那么每个区域对应的width和height为:
如,roipooling的最终尺寸为7x7,那么每个区域的width和height为:
(3)对每个区域的每个元素进行双线性插值求均值(ncnn代码里面是这样实现的,但是在一些其他的地方是双线性插值之后,再maxpooling)。
具体代码为:
int ROIAlign::forward(const std::vector<Mat>& bottom_blobs, std::vector<Mat>& top_blobs, const Option& opt) const
{
const Mat& bottom_blob = bottom_blobs[0];
int w = bottom_blob.w;
int h = bottom_blob.h;
size_t elemsize = bottom_blob.elemsize;
int channels = bottom_blob.c;
const Mat& roi_blob = bottom_blobs[1];
Mat& top_blob = top_blobs[0];
top_blob.create(pooled_width, pooled_height, channels, elemsize, opt.blob_allocator);
if (top_blob.empty())
return -100;
// For each ROI R = [x y w h]: avg pool over R
const float* roi_ptr = roi_blob;
// 计算roi在feature map上的位置
float roi_x1 = roi_ptr[0] * spatial_scale;
float roi_y1 = roi_ptr[1] * spatial_scale;
float roi_x2 = roi_ptr[2] * spatial_scale;
float roi_y2 = roi_ptr[3] * spatial_scale;
// 计算roi的size
float roi_w = std::max(roi_x2 - roi_x1, 1.f);
float roi_h = std::max(roi_y2 - roi_y1, 1.f);
// 计算每个小区域的size
float bin_size_w = roi_w / (float)pooled_width;
float bin_size_h = roi_h / (float)pooled_height;
#pragma omp parallel for num_threads(opt.num_threads)
for (int q=0; q<channels; q++)
{
const float* ptr = bottom_blob.channel(q);
float* outptr = top_blob.channel(q);
for (int ph = 0; ph < pooled_height; ph++)
{
for (int pw = 0; pw < pooled_width; pw++)
{
// Compute pooling region for this output unit:
// start (included) = ph * roi_height / pooled_height
// end (excluded) = (ph + 1) * roi_height / pooled_height
// 计算每个小区域的的位置
float hstart = roi_y1 + ph * bin_size_h;
float wstart = roi_x1 + pw * bin_size_w;
float hend = roi_y1 + (ph + 1) * bin_size_h;
float wend = roi_x1 + (pw + 1) * bin_size_w;
// 越界检测
hstart = std::min(std::max(hstart, 0.f), (float)h);
wstart = std::min(std::max(wstart, 0.f), (float)w);
hend = std::min(std::max(hend, 0.f), (float)h);
wend = std::min(std::max(wend, 0.f), (float)w);
// 计算每个小区域的size
int bin_grid_h = ceil(hend - hstart);
int bin_grid_w = ceil(wend - wstart);
// 判断是否为空
bool is_empty = (hend <= hstart) || (wend <= wstart);
// 计算面积
int area = bin_grid_h * bin_grid_w;
float sum = 0.f;
for (int by = 0; by < bin_grid_h; by++)
{
float y = hstart + (by + 0.5f) * bin_size_h / (float)bin_grid_h;
for (int bx = 0; bx < bin_grid_w; bx++)
{
float x = wstart + (bx + 0.5f) * bin_size_w / (float)bin_grid_w;
// bilinear interpolate at (x,y)
// 对(x,y)位置进行双线性插值
float v = bilinear_interpolate(ptr, w, h, x, y);
sum += v;
}
}
// 求平均
outptr[pw] = is_empty ? 0.f : (sum / (float)area);
}
outptr += pooled_width;
}
}
return 0;
}15.Reshape操作
改变形状,这个没啥好说的,直接看代码:
int Reshape::forward(const Mat& bottom_blob, Mat& top_blob, const Option& opt) const
{
size_t elemsize = bottom_blob.elemsize;
int total = bottom_blob.w * bottom_blob.h * bottom_blob.c;
// 输入为一维
if (ndim == 1)
{
int _w = w;
if (_w == 0)
_w = bottom_blob.w;
// 计算reshape后mat的形状
if (_w == -1)
_w = total;
// 转置
if (permute == 1)
{
top_blob.create(_w, elemsize, opt.blob_allocator);
if (top_blob.empty())
return -100;
// c-h-w to h-w-c
float* ptr = top_blob;
for (int i=0; i<bottom_blob.h; i++)
{
for (int j=0; j<bottom_blob.w; j++)
{
for (int p=0; p<bottom_blob.c; p++)
{
const float* bptr = bottom_blob.channel(p);
*ptr++ = bptr[i*bottom_blob.w + j];
}
}
}
}
else
{
top_blob = bottom_blob.reshape(_w, opt.blob_allocator);
}
}
else if (ndim == 2)
{
int _w = w;
int _h = h;
if (_w == 0)
_w = bottom_blob.w;
if (_h == 0)
_h = bottom_blob.h;
// 计算reshape后mat的形状
if (_w == -1)
_w = total / _h;
if (_h == -1)
_h = total / _w;
top_blob = bottom_blob.reshape(_w, _h, opt.blob_allocator);
}
else if (ndim == 3)
{
int _w = w;
int _h = h;
int _c = c;
if (_w == 0)
_w = bottom_blob.w;
if (_h == 0)
_h = bottom_blob.h;
if (_c == 0)
_c = bottom_blob.c;
// 计算reshape后mat的形状
if (_w == -1)
_w = total / _c / _h;
if (_h == -1)
_h = total / _c / _w;
if (_c == -1)
_c = total / _h / _w;
top_blob = bottom_blob.reshape(_w, _h, _c, opt.blob_allocator);
}
if (top_blob.empty())
return -100;
return 0;
}
参考资料:
[1] https://github.com/Tencent/ncnn
[2] https://www.bilibili.com/video/av64313133?from=search&seid=6032750934674516839
[3] https://www.jianshu.com/p/afa0ac6b7201
[4] https://www.jianshu.com/p/44db6d72d6eb
[5] Zhang X, Zhou X, Lin M, et al. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices[J]. arXiv: Computer Vision and Pattern Recognition, 2017.
[6] https://www.cnblogs.com/wangyong/p/8523814.html

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









