



强化学习,Reinforcement Learning,简称RL;
机器学习,machine learning,简称ML;
深度学习,Deep learning,简称DL(这个一般指涉及多层神经网络的机器学习)。
一、组成
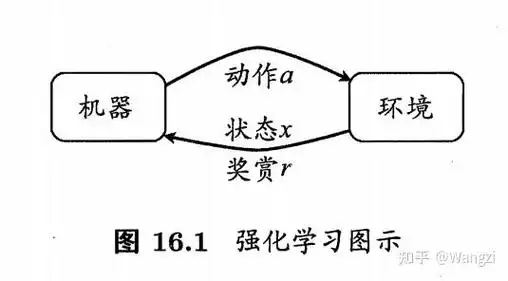
1-1环境Environments
反馈的来源,除智能体自身外的一切周遭。
1-2状态State
- Environment State• 反映环境发生什么改变• 环境自身的状态和环境反馈给agent的状态并不一定相同- Agent State• Agent的现在所处状态的表示• RL所用的状态
状态states 是一个关于这个世界状态的完整描述。这个世界除了状态以外没有别的信息。
观察observations 是对于一个状态的部分描述,可能会漏掉一些信息。
1-3激励/奖赏Reward
- 在每个时间步,环境给Agent发送的标量数字- 定义了强化学习问题中的目标- 定义了对Agent而言什么是好、什么是坏的事件;- 是Agent面临问题的即时和决定性的特征,是环境状态即时、本质的期望- Agent无法改变产生激励信号的函数,也就是说不能改变其面临的问题- 是改变策略的首要基础- 通常而言是环境状态和采取行为的随机函数
1-4行为Action
行为是智能体在某个状态下可以采取的决策或操作(行为空间)。
1-5代理/智能体Agent(图上的“机器”)
- 策略 Policy[它根据当前的观察来决定行为,是从 状态到 行为的映射。 ]- 价值函数 Value function[它 预测了当前状态下未来可能获得的奖励(reward)的期望,用于衡量当前状态的好坏。 ]- 模型 Model[ 预测环境下一步会做出什么样的改变,从而预测智能体的状态或者接收到的奖励(reward)是什么。 ]
1-0小结
常用的符号表示
状态(State)
符号:s 或 st
含义:状态是环境的某个特定配置或描述,表示智能体在环境中的位置或情况。st 表示在时间步 t 的状态。
行为(Action)
符号:a 或 at
含义:行为是智能体在某个状态下可以采取的决策或操作。at 表示在时间步 t 选择的行为。
奖励(Reward)
符号:r 或 rt
含义:奖励是环境对智能体行为的反馈,是一个标量值,表示智能体采取某个行为后的即时收益或损失。rt 表示在时间步 t 获得的奖励。
策略(Policy)
符号:π
含义:策略是智能体的行为准则,定义了在给定状态下选择行为的概率分布。形式化为 π(a∣s),表示在状态 s 下选择行为 a 的概率。

二、分类
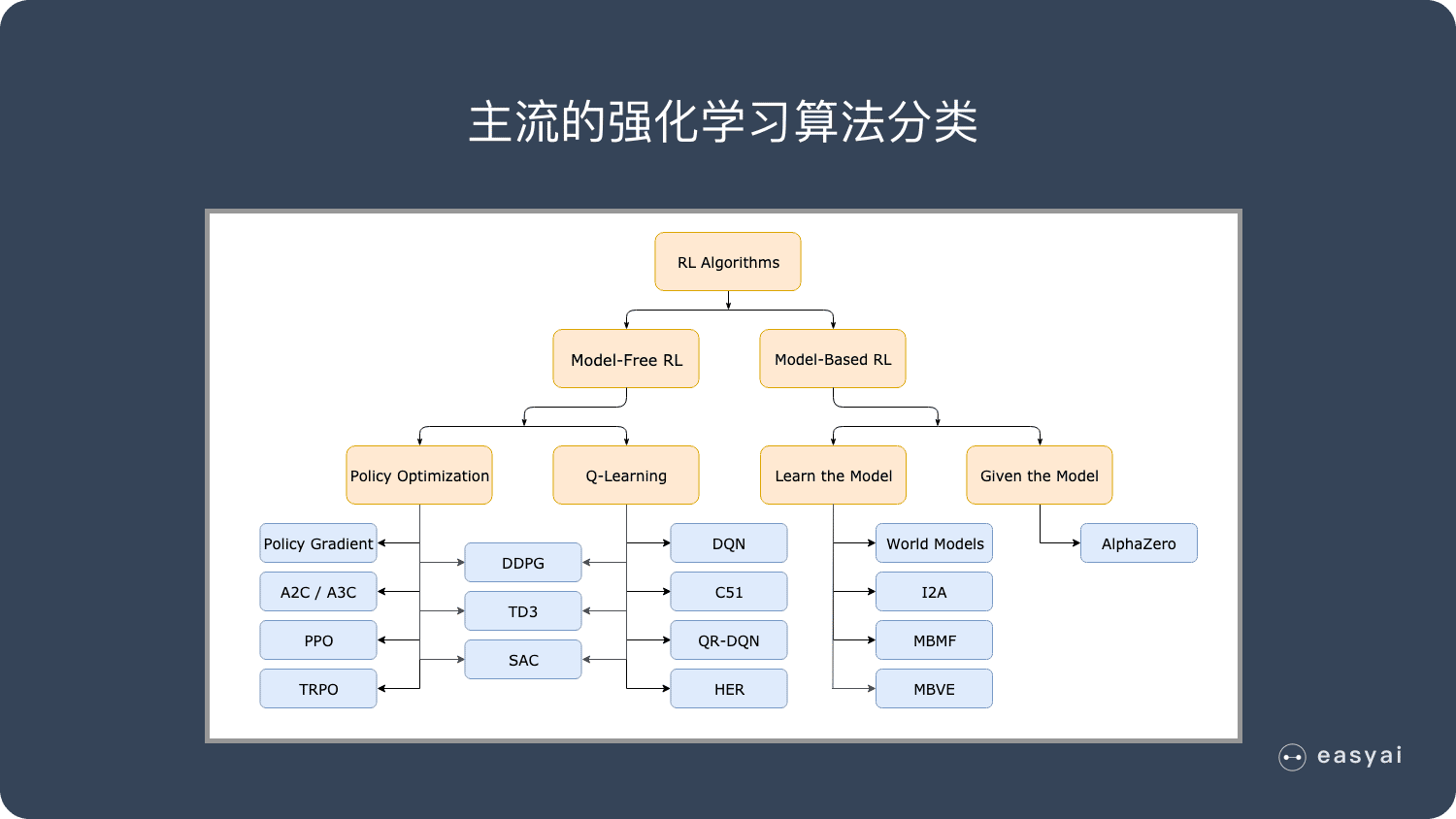
- Learning• 环境初始时是未知的• Agent不知道环境如何工作• Agent通过与环境进行交互,逐渐改善Policy- Planning• 环境如何工作对于Agent是已知或近似已知的• Agent并不与环境发生实际的交互• Agent利用其构建的Model进行计算,在此基础上改善Policy
三、分类介绍
3-1基础
一些概念的简单介绍:
1)Markov Decision Processes(马尔可夫决策过程)
- 一种数学框架,用于建模决策制定代理(agent)在部分可观察环境中的行为。在马尔可夫决策过程中,未来的结果仅依赖于当前状态和采取的动作,而与过去的状态和动作无关。
2) Bellman Equation(贝尔曼方程)
- 一组递归方程,用于计算马尔可夫决策过程中的最优价值函数和最优策略。贝尔曼方程表达了价值函数的最优子结构性质,即最优策略具有这样的性质:无论初始状态和历史如何,剩余决策都构成一个最优策略。
3) Optimal Policies and Optimal Value Functions(最优策略与最优价值函数)
- 最优策略是指在所有可能的策略中,能够最大化长期累积奖励的策略。最优价值函数是指在最优策略下,从任意状态出发所能获得的最大期望回报。
4) Monte Carlo Methods(蒙特卡罗方法)
- 一种基于随机抽样的计算方法,用于估计复杂系统的概率分布和期望值。在强化学习中,蒙特卡罗方法通过模拟多个完整的决策过程(episodes),并利用这些模拟的结果来估计价值函数和策略。
3-2动态规划 与 时序差分
Dynamic Programming(DP,动态规划)
Temporal-Difference Learning(TD,时序差分学习)
两者关系图

1)Q-learning: Off-policy TD Control (Q-学习:无策略的时序差分控制)
Double Q-Learning(双重Q学习) 双重Q学习是一种强化学习算法,旨在减少Q学习算法中过高估计(overestimation)的问题。它通过使用两个独立的Q值函数来交替更新,从而降低估计偏差。
2)Sarsa: On-policy TD Control (Sarsa:一种基于策略的时序差分控制)
Expected Sarsa(期望Sarsa)
一种在线策略算法,它使用当前策略选择动作,并基于这些动作的预期价值更新价值函数。
n-step Sarsa(n步Sarsa)一种在线策略算法,它根据n步内的回报来更新价值函数,而不是仅仅基于下一步的结果。
Off-policy n-step Sarsa(离线n步Sarsa)
一种离线策略算法,它使用行为策略选择动作,但更新目标策略的价值函数。
Off-policy n-step Expected Sarsa(离线期望n步Sarsa)
一种离线策略算法,它在更新时考虑了目标策略的预期价值,而不是仅仅依赖于实际采取的动作。
3)Maximization Bias(最大化偏差)

3-3Integrating Learning and Planning(规划与学习)
Model-Based Methods(基于模型的方法)
Model-Based RL:基于模型的强化学习
Dyna / Dyna-Q with an Inaccurate Model:Dyna架构、使用不准确模型的Dyna-Q
Inaccurate Model:不准确模型
Planning Methods(规划方法)
Sample-Based Planning:基于采样的规划
Trajectory Sampling:轨迹采样
Online and Real-Time Methods(在线和实时方法)
On-line Planning:在线规划
Real-time Dynamic Programming (RTDP):实时动态规划
Model Improvement and Efficiency Methods(模型改进与效率方法)
Prioritized Sweeping:优先级扫描

3-4值函数逼近(Value Function Approximation)
1) Optimization Methods(优化方法)
-
Gradient Descent:梯度下降
-
Stochastic Gradient Descent:随机梯度下降
-
Semi-gradient Methods:半梯度方法
2)Linear Function Approximation(线性函数近似)
-
Feature Vectors:特征向量
-
Linear methods:线性方法
3) Prediction Algorithms(预测算法)
-
Monte-Carlo with Value Function Approximation:蒙特卡洛方法与价值函数近似
-
TD Learning with Value Function Approximation:时序差分学习与价值函数近似
4)Off-policy Methods with Approximation(带近似的离线策略方法)
Off policy: 离线策略:能够在不从该策略生成新样本的情况下改进策略
On policy: 在线策略:每次策略发生变化,哪怕只有一点点,都需要生成新的样本
5)Feature Construction for Linear Methods(特征构造)
特征构造是机器学习中的一个重要步骤,尤其是在线性方法中。线性方法(如线性回归、线性分类器等)通常假设数据与目标变量之间存在线性关系。然而,许多实际问题中的数据是非线性的。为了使线性方法能够处理非线性问题,需要通过特征构造将原始数据转换为更易于线性模型处理的形式。
多项式(Polynomials)
多项式是一种常见的特征构造方法,用于增加数据的非线性表达能力。通过将原始特征的幂次扩展为高次项(如 x2, x3 等),可以捕捉数据中的非线性关系。例如,对于一个一维特征 x,构造多项式特征后,新的特征空间可能包括 1,x,x2,x3 等。这种方法在多项式回归中被广泛应用。
傅里叶基(Fourier Basis)
傅里叶基是另一种特征构造方法,它利用傅里叶变换将数据从时域(或空间域)转换到频域。傅里叶基函数通常包括正弦和余弦函数,能够捕捉数据中的周期性模式。例如,对于时间序列数据,使用傅里叶基可以提取出数据中的周期性成分,从而更好地表示数据的特征。这种方法在信号处理和某些机器学习任务中非常有用。
粗编码(Coarse Coding)
粗编码是一种用于处理连续数据的特征构造方法,通过将连续值映射到离散的“桶”或区间中,从而减少数据的复杂性并提高模型的泛化能力。例如,对于一个连续的特征 x,可以将其划分为若干个区间(如 x∈[0,1), x∈[1,2) 等),并将每个区间用一个二进制特征表示。这种方法在强化学习和某些分类任务中被广泛应用,特别是在处理高维连续状态空间时。
小结
这些方法都属于特征构造的范畴,目的是将原始数据转换为更适合线性模型处理的形式。它们各自适用于不同的场景:
多项式适用于捕捉非线性关系。
傅里叶基适用于处理周期性数据。
粗编码适用于处理连续数据,特别是当数据维度较高时。
通过合理选择和组合这些特征构造方法,可以显著提升线性模型的性能。
3-5优化方法
1)n-step Bootstrapping(n步自举法)
n步自举法是一种用于强化学习中值函数估计的方法。它结合了蒙特卡洛方法(Monte Carlo)和时序差分(Temporal Difference, TD)学习的优点。
自举,这里大概是自己产出的预测结果当作给自己下一轮做原料(大雾,我不知道理解的对不对)。
2)Eligibility traces(资格迹)
资格迹是一种用于加速学习过程的技术,特别是在时序差分学习中。它通过为每个状态或状态-动作对分配一个“资格值”,来记录它们在最近的轨迹中被访问的频率和时间。
3-6反推(backups)
在强化学习中,backups(反推)是一个关键概念,它指的是更新价值函数(value function)或策略(policy)时所使用的信息。【我不知道为什么和计算机算法中的回溯backtrack不是同一个单词,但感觉很像】反推过程涉及利用新获得的信息来修正或更新现有的估计值,以便更好地反映在给定状态下采取某个动作的价值或预期回报。以下是反推概念的几个关键方面:
1)反推的类型
-
完整(Full Backups):在动态规划中,完整反推意味着使用所有可能的未来信息来更新当前状态的价值。这通常涉及到解决一个完整的贝尔曼方程(Bellman equation)。
-
取样(Sample Backups):在蒙特卡洛方法中,取样反推意味着仅使用一个或少数几个样本路径来更新价值估计。这种方法不需要模型信息,但可能需要更多的样本来获得稳定的估计。
2) 反推的深度
-
浅(Shallow Backups):如时序差分(Temporal Difference, TD)学习,只考虑一步或几步的回报来更新价值函数。
-
深(Deep Backups):如蒙特卡洛方法,考虑整个序列的回报来更新价值函数,这通常涉及到等待一个完整的episode结束。
3) 反推的方法
-
动态规划(Dynamic Programming):使用模型信息进行完整反推,通常在已知环境模型的情况下使用。
-
时序差分学习(Temporal Difference Learning):结合了蒙特卡洛方法和动态规划的特点,使用样本反推但不需要完整的episode。
-
蒙特卡洛方法(Monte Carlo Methods):使用样本反推,但需要完整的episode信息来计算回报。
4) 反推的应用
反推过程是强化学习算法更新其策略或价值函数的核心。通过不断地反推,算法能够逐渐学习到在不同状态下采取不同动作的最优策略,从而最大化累积奖励。
总之,反推是强化学习中更新价值估计或策略的基本机制,它涉及到如何利用新获得的信息来改进现有的估计。不同的反推方法和深度适用于不同的学习场景和算法设计。

图中通过一个二维坐标系来表示不同的算法,其中横轴表示深度(从浅到深),纵轴表示完整性(从取样到完整)。
图中的关键元素:
Dynamic Programming(动态规划)
位于图的左上角,表示需要完整的(full backups),即需要知道所有可能的状态和转移。Exhaustive Search(穷举搜索)
位于图的右上角,表示也需要完整的,但更侧重于通过搜索来找到最优解。Temporal-difference Learning(时序差分学习)
位于图的左下角,表示只需要样本(sample backups),即通过单个样本来更新估计值。Monte Carlo Methods(蒙特卡洛方法)
位于图的右下角,表示需要较深的(deep backups),但只需要取样反推,即通过完整的样本序列来更新估计值。5.Bootstrapping(自举法)
横轴中间部分,表示使用自举法进行反推,即利用当前估计值来更新下一个估计值,反推深度介于浅和深之间。
3-7Deep Reinforcement Learning(深度强化学习)
这部分开始引入神经网络(neural network,nn)
1)Imitation Learning(模仿学习)
-
Imitation Learning:模仿学习
2)Value-based Methods(基于价值的方法)
-
Value-based:基于价值
-
Fitted value iteration:拟合值迭代
-
DQN algorithms:DQN算法(Deep Q-Network算法)
-
Deep RL with Q-Functions:基于Q函数的深度强化学习
3)Model-based Methods(基于模型的方法)
-
Model-based:基于模型
-
Model-based Reinforcement Learning:基于模型的强化学习
-
Trajectory Optimization:轨迹优化
-
Model-Predictive Control:模型预测控制
-
Inverse Reinforcement Learning:逆强化学习
4)Policy Gradient Methods(策略梯度方法)
-
Policy gradients:策略梯度
-
Actor-critic:演员-评论家方法
-
Advanced Policy Gradient:高级策略梯度
-
Policy Performance Bounds:策略性能界限
-
Monotonic Improvement Theory:单调改进理论
-
Approximate Monotonic Improvement:近似单调改进
-
Natural Policy Gradient:自然策略梯度
-
Trust Region Policy Optimization:信任域策略优化
-
Proximal Policy Optimization (PPO):近端策略优化
5)Probabilistic Methods(概率方法)
-
Probabilistic Graphical Model:概率图模型
-
Variational Inference:变分推断
6)Other Methods(其他方法)
-
Guided Cost Learning:引导成本学习



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











