








 超级会员免费看
超级会员免费看

阿里因为特有的大平台流量,在各种智能内容生成上都涉足较多,而且公之于众的成果颇多。
9月26日,阿里巴巴在杭州云栖大会上首次公布了人工智能调用规模:AI每天调用超1万亿次,服务全球10亿人,日处理图像10亿张、视频120万小时、语音55万小时及自然语言5千亿句,已经成为中国最大的人工智能公司。
阿里还首次披露人工智能的完整布局,在AI芯片、AI云服务、AI算法、AI平台、产业AI的进展。
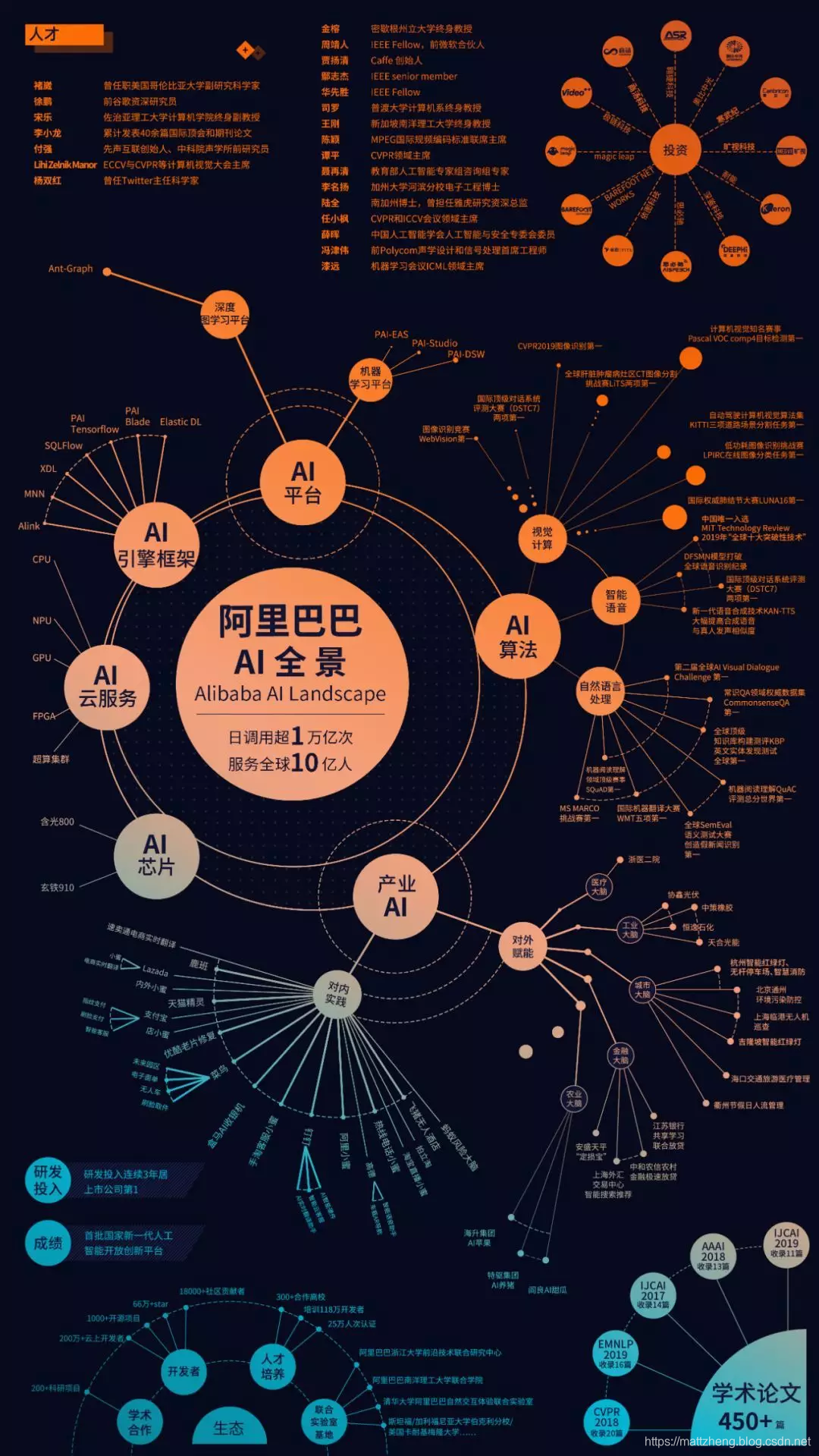
阿里首发AI全阵型,每天调用超1万亿次;与FB合作,PyTorch进驻阿里云机器学习平台
我们来看看阿里系的一些视频生成的成果:
视频’鹿班’ alibabawood
阿里的鹿班很早就在电商制图领域崛起了,而且鹿班应该属于比较成熟的商业产品形态了,不过视频方面,阿里也有新的产品——alibabawood

网站链接:
ht

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1035
1035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









