







 本文深入解析XGBoost算法,从基础知识出发,详细介绍了回归树、梯度提升等核心概念,探讨了目标函数、正则化项及优化方法,并阐述了决策树的生成与优化过程。
本文深入解析XGBoost算法,从基础知识出发,详细介绍了回归树、梯度提升等核心概念,探讨了目标函数、正则化项及优化方法,并阐述了决策树的生成与优化过程。
从入门到放弃(1):XGBoost
一、基础知识
1.Notation
| 标记 | 意义 |
|---|---|
| x i x_i xi | 第 i i i个样本 |
| y i y_i yi | 第 i i i个样本的真实值 |
| y ^ i \hat{y}_i y^i | 第 i i i个样本的预测值 |
| Θ \Theta Θ | 包括 { w j , j = 1 , … , d } \{w_j,j=1,\dots,d\} {wj,j=1,…,d},是我们需要学习的参数 |
2.Objective Function
O
b
j
(
Θ
)
=
L
(
Θ
)
+
Ω
(
Θ
)
Obj(\Theta) = L(\Theta)+\Omega(\Theta)
Obj(Θ)=L(Θ)+Ω(Θ)
其中
L
(
Θ
)
L(\Theta)
L(Θ)表示损失函数,
Ω
(
Θ
)
\Omega(\Theta)
Ω(Θ)是正则化项,可以是对参数的
l
1
l_1
l1-norm(lasso)或者
l
2
l_2
l2-norm(岭回归),用来控制模型的复杂程度。
二、Regression Tree and Ensemble (What are we learning)
2. Regression Tree (CART)
2.1 目标函数
C α ( T ) = C ( T ) + α ∣ T ∣ C_\alpha(T) = C(T)+\alpha|T| Cα(T)=C(T)+α∣T∣,其中 C ( T ) C(T) C(T)表示决策树 T T T的损失函数,|T|表示决策树 T T T的复杂度,为叶节点的个数, α \alpha α是一个平衡两部分的参数。
2.2 Classification Tree
接下来我们复习一下回归树。在ID3, C4.5, CART三种决策树学习算法中,能够完成回归任务的就是CART。
2.2.1生成过程
(1) 最优属性的选择
CART中选择最优属性时,与其他两种算法用到的信息增益、信息增益率不同,使用的是基尼指数。
当前样本集
D
D
D,有
G
i
n
i
(
D
)
=
1
−
Σ
i
∣
Y
∣
(
1
−
p
i
2
)
Gini(D) = 1-\Sigma_i^{|Y|}(1-p_i^2)
Gini(D)=1−Σi∣Y∣(1−pi2),
其中
∣
Y
∣
|Y|
∣Y∣表示类别数,
p
i
p_i
pi表示第
i
i
i类样本在当前数据集的占比,
G
i
n
i
(
D
)
Gini(D)
Gini(D)的物理意义即为从当前样本集中任意取出两个样本不属于同一个类别的概率。CART使用基尼指数来选择最优划分属性。
G
i
n
i
_
i
n
d
e
x
(
D
,
a
)
=
Σ
v
V
∣
D
v
∣
∣
D
∣
G
i
n
i
(
D
v
)
Gini\_index(D,a) = \Sigma_v^V\frac{|D^v|}{|D|}Gini(D^v)
Gini_index(D,a)=ΣvV∣D∣∣Dv∣Gini(Dv)
基尼指数越小,表示纯度越高。我们选择最优属性
a
∗
=
a
r
g
min
a
G
i
n
i
_
i
n
d
e
x
(
D
,
a
)
a^* = arg \min_aGini\_index(D,a)
a∗=argaminGini_index(D,a)
(2) 停止划分的条件
1.当前属性集为空或者当前样本集在划分属性上都属于同一类。
2.当前结点包含的样本都属于同一类别,无需划分
3.当前结点包含的样本集合为空,不能划分。
2.2.2目标函数
分类决策树目标函数中的损失函数是对训练样本的预测误差(交叉熵损失)。因此叶节点最后输出的目标函数值是一个score,我们通过转换成0-1的值来完成分类。这个目标函数用来进行后剪枝,详细见决策树相关博文。
2.3 Regression Tree
2.3.1 目标函数
回归树处理的是回归问题,损失函数自然是平方误差函数:
C
(
T
)
=
Σ
i
N
(
y
i
−
y
^
i
)
2
C(T)=\Sigma_i^N(y_i-\hat{y}_i)^2
C(T)=ΣiN(yi−y^i)2
2.3.2 生成过程
(1) 对离散变量、连续值的处理
对离散变量,按照常规过程来生成。
对于连续变量,我们的处理方法如下:(C4.5中也可以对连续变量进行处理)
给定样本集
D
D
D和连续属性
a
a
a,假设
a
a
a在
D
D
D上出现了
V
V
V个不同的取值,将这些值从小到大排列,记为
{
a
1
,
a
2
,
…
,
a
V
}
\{a^1,a^2,\dots,a^V\}
{a1,a2,…,aV},我们寻找一个划分点
t
t
t,可将样本集划分为大于
t
t
t和不大于
t
t
t的两部分,我们选择划分点集为
T
a
=
{
a
i
+
a
i
+
1
2
,
1
≤
i
≤
n
−
1
}
T_a = \{\frac{a^i+a^{i+1}}{2},1\leq i \leq n-1\}
Ta={2ai+ai+1,1≤i≤n−1}
接下来我们就可以像离散属性值一样来考察这些划分点,划分的标准也是基于基尼指数。
(2) 回归过程
回归树的生成规则和分类树是相同的,唯一不同的就是我们最后要给叶节点上的样本一个预测值,而不是分类标签。我们采用的方法是将同一个叶节点上的所有样本都预测为同一个值,这个值就是该节点所有样本真实值的均值。
那为什么要预测为该节点所有真实值的均值呢?这与损失函数的定义相关。已知
L
y
^
i
=
Σ
i
N
(
y
i
−
y
^
i
)
2
L_{\hat{y}_i}=\Sigma_i^N(y_i-\hat{y}_i)^2
Ly^i=ΣiN(yi−y^i)2,那么使得损失函数最小的
y
^
i
=
a
r
g
min
y
^
i
=
1
N
Σ
i
N
y
i
\hat{y}_i = arg \min_{\hat{y}_i} = \frac{1}{N}\Sigma_i^Ny_i
y^i=argminy^i=N1ΣiNyi.
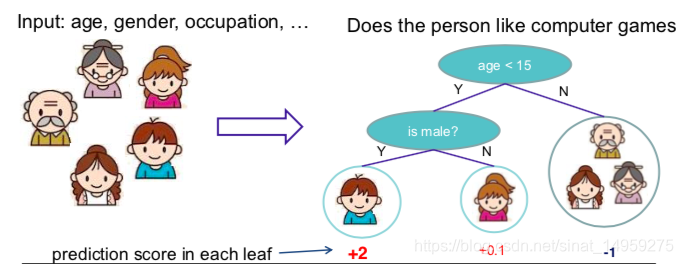
2.3 Regression Tree Ensemble
当我们有两棵及两棵以上的决策树时,就可以进行集成。
2.3.1 Model
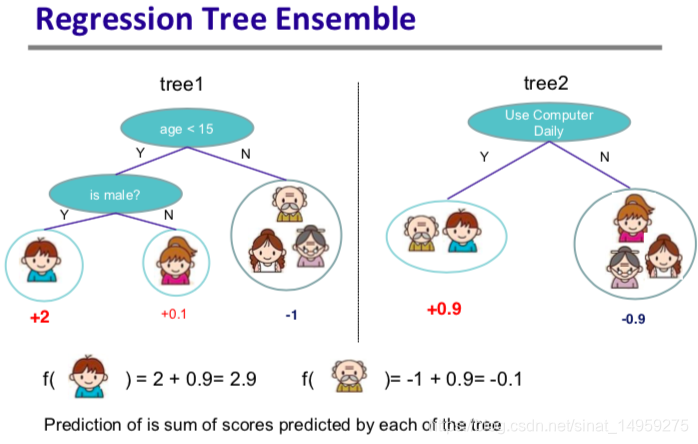
假设我们有K棵树
y
^
i
=
Σ
k
=
1
K
f
k
(
x
i
)
,
f
k
∈
F
\hat{y}_i = \Sigma_{k=1}^Kf_k(x_i),f_k \in F
y^i=Σk=1Kfk(xi),fk∈F
其中
f
k
(
∗
)
f_k(*)
fk(∗)表示第
k
k
k棵树的假设函数,也就是将属性投影成叶节点上得分的函数。
也就是说,在Tree Ensemble methods中,我们希望学习到的,就是这
K
K
K棵树的假设函数,写成公式就是
Θ
=
{
f
1
,
f
2
,
…
,
f
K
}
\Theta = \{f_1,f_2,\dots,f_K\}
Θ={f1,f2,…,fK}
参数不再是单棵树的参数,而是一整棵树,包括树的结构和最后叶节点的得分。
2.3.2 Objective Function
已经有了求解的参数,我们现在需要定义一个目标函数,和之前一样,目标函数需要包括损失函数和正则化项,唯一不同的就是控制模型复杂度项约束的变成了第
k
k
k棵树。
O
b
j
=
Σ
i
=
1
n
l
(
y
i
,
y
^
i
)
+
Σ
k
=
1
K
Ω
(
f
k
)
Obj = \Sigma_{i=1}^nl(y_i,\hat{y}_i)+\Sigma_{k=1}^K\Omega(f_k)
Obj=Σi=1nl(yi,y^i)+Σk=1KΩ(fk)
Regression Tree并不仅仅只能用于回归问题,还可以用于解决分类问题,这都取决于损失函数。
- Gradient boosted machine: l ( y i , y ^ i ) = ( y i − y ^ i ) 2 l(y_i,\hat{y}_i)=(y_i-\hat{y}_i)^2 l(yi,y^i)=(yi−y^i)2
- LogitBoost: l ( y i , y ^ i ) = y i l n ( 1 + e − y ^ i ) + ( 1 − y i ) l n ( 1 + e y ^ i ) l(y_i,\hat{y}_i) = y_iln(1+e^{-\hat{y}_i})+(1-y_i)ln(1+e^{\hat{y}_i}) l(yi,y^i)=yiln(1+e−y^i)+(1−yi)ln(1+ey^i)
三、Gradient Boosting (How do we Learn)
Objective:
Σ
i
=
1
n
l
(
y
i
,
y
^
i
)
+
Σ
k
=
1
K
Ω
(
f
k
)
\Sigma_{i=1}^nl(y_i,\hat{y}_i)+\Sigma_{k=1}^K\Omega(f_k)
Σi=1nl(yi,y^i)+Σk=1KΩ(fk)
要优化这个目标函数,常规的SGD等方法已经无法满足我们的要求,因此我们需要一种新的优化方法去找到最优的决策树集合
f
f
f。
3.1 Additive Training
从一个最简单的常数预测开始,我们的Model就是每次都增加一棵新的树。
y
^
i
(
0
)
=
0
\hat{y}_i^{(0)}=0
y^i(0)=0
y
^
i
(
1
)
=
f
1
(
x
i
)
=
y
^
i
(
0
)
+
f
1
(
x
i
)
\hat{y}_i^{(1)}=f_1(x_i)=\hat{y}_i^{(0)}+f_1(x_i)
y^i(1)=f1(xi)=y^i(0)+f1(xi)
y
^
i
(
2
)
=
f
1
(
x
i
)
+
f
2
(
x
i
)
=
y
^
i
(
1
)
+
f
2
(
x
i
)
\hat{y}_i^{(2)}=f_1(x_i)+f_2(x_i)=\hat{y}_i^{(1)}+f_2(x_i)
y^i(2)=f1(xi)+f2(xi)=y^i(1)+f2(xi)
⋯
\cdots
⋯
y
^
i
(
t
)
=
Σ
k
=
1
t
f
k
(
x
i
)
=
y
^
i
(
t
−
1
)
+
f
t
(
x
i
)
\hat{y}_i^{(t)}=\Sigma_{k=1}^tf_k(x_i)=\hat{y}_i^{(t-1)}+f_t(x_i)
y^i(t)=Σk=1tfk(xi)=y^i(t−1)+ft(xi)
也就是说,我们在第
t
t
t轮的优化目标包括已知的前
t
−
1
t-1
t−1轮产生的树,和本轮需要求解的第
t
t
t棵树。
3.2 求解目标函数
O
b
j
(
t
)
=
Σ
i
=
1
n
l
(
y
i
,
y
^
i
(
t
)
)
+
Σ
k
=
1
t
Ω
(
f
k
)
Obj^{(t)}= \Sigma_{i=1}^nl(y_i,\hat{y}_i^{(t)})+\Sigma_{k=1}^t\Omega(f_k)
Obj(t)=Σi=1nl(yi,y^i(t))+Σk=1tΩ(fk)
将
y
^
i
(
t
)
=
y
^
i
(
t
−
1
)
+
f
t
(
x
i
)
\hat{y}_i^{(t)}=\hat{y}_i^{(t-1)}+f_t(x_i)
y^i(t)=y^i(t−1)+ft(xi)代入,有
O
b
j
(
t
)
=
Σ
i
=
1
n
l
(
y
i
,
y
^
i
(
t
−
1
)
+
f
t
(
x
i
)
)
+
Σ
k
=
1
t
Ω
(
f
k
)
Obj^{(t)}= \Sigma_{i=1}^nl(y_i,\hat{y}_i^{(t-1)}+f_t(x_i))+\Sigma_{k=1}^t\Omega(f_k)
Obj(t)=Σi=1nl(yi,y^i(t−1)+ft(xi))+Σk=1tΩ(fk)
那要怎么求解最优的
f
t
(
x
i
)
f_t(x_i)
ft(xi)呢,我们回顾到Taylor展开式:
f
(
x
+
Δ
x
)
≈
f
(
x
)
+
f
′
(
x
)
Δ
x
+
1
2
f
′
′
(
x
)
Δ
x
2
f(x+\Delta x) \approx f(x)+f^{'}(x)\Delta x+\frac{1}{2}f^{''}(x)\Delta x^2
f(x+Δx)≈f(x)+f′(x)Δx+21f′′(x)Δx2
应用Taylor展开式将上式在
y
^
i
(
t
−
1
)
+
f
t
(
x
i
)
\hat{y}_i^{(t-1)}+f_t(x_i)
y^i(t−1)+ft(xi)处展开,有
O
b
j
(
t
)
≈
Σ
i
=
1
n
[
l
(
y
i
,
y
^
i
(
t
−
1
)
)
+
g
i
f
t
(
x
i
)
+
1
2
h
i
f
t
(
x
i
)
2
]
+
Ω
(
f
t
)
+
c
o
n
s
t
a
n
t
Obj^{(t)}\approx \Sigma_{i=1}^n[l(y_i,\hat{y}_i^{(t-1)})+g_if_t(x_i)+\frac{1}{2}h_if_t(x_i)^2]+\Omega(f_t)+constant
Obj(t)≈Σi=1n[l(yi,y^i(t−1))+gift(xi)+21hift(xi)2]+Ω(ft)+constant
其中,
g
i
=
∂
y
^
i
(
t
−
1
)
l
(
y
i
,
y
^
i
(
t
−
1
)
)
g_i={\partial_{\hat{y}_i^{(t-1)}}}l(y_i,\hat{y}_i^{(t-1)})
gi=∂y^i(t−1)l(yi,y^i(t−1)),
h
i
=
∂
y
^
i
(
t
−
1
)
2
l
(
y
i
,
y
^
i
(
t
−
1
)
)
h_i={\partial^2_{\hat{y}_i^{(t-1)}}}l(y_i,\hat{y}_i^{(t-1)})
hi=∂y^i(t−1)2l(yi,y^i(t−1))。
其中损失函数及惩罚项中的
y
i
y_i
yi,
y
^
i
(
t
−
1
)
\hat{y}_i^{(t-1)}
y^i(t−1),
f
t
f_t
ft对于第
t
t
t的求解来说都是常数,所以为了简便,我们归到constant中。当移除所有的常数项后,有
O
b
j
(
t
)
≈
Σ
i
=
1
n
[
g
i
f
t
(
x
i
)
+
1
2
h
i
f
t
(
x
i
)
2
]
+
Ω
(
f
t
)
Obj^{(t)}\approx\Sigma_{i=1}^n[g_if_t(x_i)+\frac{1}{2}h_if_t(x_i)^2]+\Omega(f_t)
Obj(t)≈Σi=1n[gift(xi)+21hift(xi)2]+Ω(ft)
这样我们的目标函数就成了一个二次型。
如果不够直观的话,我们可以考虑损失函数是平方差损失函数的时候:
O
b
j
(
t
)
=
Σ
i
=
1
n
(
y
i
−
(
y
^
i
(
t
−
1
)
+
f
t
(
x
i
)
)
2
+
Σ
k
=
1
t
Ω
(
f
k
)
Obj^{(t)}= \Sigma_{i=1}^n(y_i-(\hat{y}_i^{(t-1)}+f_t(x_i))^2+\Sigma_{k=1}^t\Omega(f_k)
Obj(t)=Σi=1n(yi−(y^i(t−1)+ft(xi))2+Σk=1tΩ(fk)
=
Σ
i
=
1
n
2
(
y
^
i
(
t
−
1
)
−
y
i
)
f
t
(
x
i
)
+
f
t
(
x
i
)
2
+
c
o
n
s
t
a
n
t
=\Sigma_{i=1}^n2(\hat{y}_i^{(t-1)}-y_i)f_t(x_i)+f_t(x_i)^2+constant
=Σi=1n2(y^i(t−1)−yi)ft(xi)+ft(xi)2+constant
可以看到是与我们推导出的最后结果是相同的。
3.2.1 定义 f t ( x ) f_t(x) ft(x)和 Ω ( f ) \Omega(f) Ω(f)
我们已经将目标函数化简成了看起来能够求解的二次型,接下来我们就进一步给大家说明一下
f
t
(
x
)
f_t(x)
ft(x)和
Ω
(
f
)
\Omega(f)
Ω(f)到底长什么样子。
f
t
(
x
)
f_t(x)
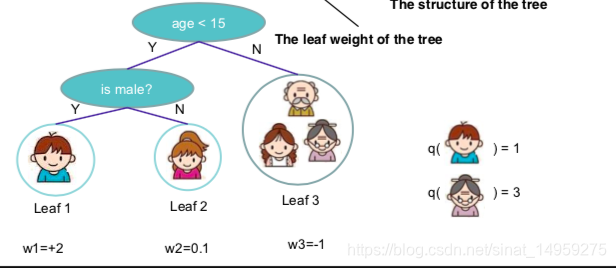
ft(x)是描述树结构的假设函数,包括划分样本的规则和每个叶节点的权重作为输出的分数。综合起来可以写成:
f
t
(
x
)
=
w
q
(
x
)
,
w
∈
R
T
,
q
:
R
d
→
{
1
,
2
,
…
,
T
}
f_t(x)=w_{q(x)},w\in R^T, q:R^d\rightarrow \{1,2,\dots,T\}
ft(x)=wq(x),w∈RT,q:Rd→{1,2,…,T}
q
(
x
)
q(x)
q(x)就是规则集,用来将样本划分到对应的叶节点。
 Ω
(
f
t
)
\Omega(f_t)
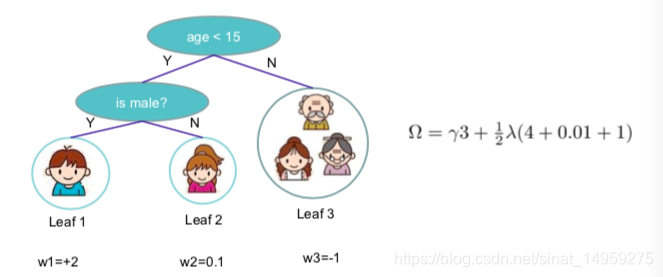
Ω(ft)是控制模型复杂度的项,为了防止过拟合,我们可以限制叶节点的数目,和限制叶节点的权重。
Ω
(
f
t
)
\Omega(f_t)
Ω(ft)是控制模型复杂度的项,为了防止过拟合,我们可以限制叶节点的数目,和限制叶节点的权重。
Ω
(
f
t
)
=
γ
T
+
1
2
λ
Σ
j
=
1
T
w
j
2
\Omega(f_t) = \gamma T+\frac{1}{2}\lambda \Sigma_{j=1}^T w_j^2
Ω(ft)=γT+21λΣj=1Twj2
T
T
T是叶节点的总数。
3.2.2 Revisit the Objectives
我们定义在叶子节点
j
j
j的样本集为
I
j
=
{
i
∣
q
(
x
i
)
=
j
}
I_j = \{i|q(x_i)=j\}
Ij={i∣q(xi)=j},将上面定义的代入到我们的目标函数中,有:
O
b
j
(
t
)
≈
Σ
i
=
1
n
[
g
i
f
t
(
x
i
)
+
1
2
h
i
f
t
(
x
i
)
2
]
+
Ω
(
f
t
)
Obj^{(t)} \approx\Sigma_{i=1}^n[g_if_t(x_i)+\frac{1}{2}h_if_t(x_i)^2]+\Omega(f_t)
Obj(t)≈Σi=1n[gift(xi)+21hift(xi)2]+Ω(ft)
=
Σ
i
=
1
n
[
g
i
w
q
(
x
i
)
+
1
2
h
i
w
q
(
x
i
)
2
]
+
γ
T
+
1
2
λ
Σ
j
=
1
T
w
j
2
=\Sigma_{i=1}^n[g_iw_{q(x_i)}+\frac{1}{2}h_iw_{q(x_i)}^2]+\gamma T+\frac{1}{2}\lambda \Sigma_{j=1}^T w_j^2
=Σi=1n[giwq(xi)+21hiwq(xi)2]+γT+21λΣj=1Twj2
如我们之间提到的,我们最后的优化目标是想找到一个最优的
f
t
(
x
)
f_t(x)
ft(x),既然
f
t
(
x
)
f_t(x)
ft(x)是由各节点的权重组成的,那么我们将函数化为自变量为
w
i
w_i
wi的会更容易分析。
O
b
j
(
t
)
≈
Σ
j
T
[
(
Σ
i
∈
I
j
g
i
)
w
j
+
1
2
(
Σ
i
∈
I
j
h
i
+
λ
)
w
j
2
]
+
γ
T
Obj^{(t)} \approx \Sigma_j^T[(\Sigma_{i\in I_j}g_i)w_j+\frac{1}{2}(\Sigma_{i\in I_j}h_i+\lambda)w_j^2]+\gamma T
Obj(t)≈ΣjT[(Σi∈Ijgi)wj+21(Σi∈Ijhi+λ)wj2]+γT
让
G
j
=
Σ
i
∈
I
j
g
i
G_j = \Sigma_{i\in I_j}g_i
Gj=Σi∈Ijgi,
H
j
=
Σ
i
∈
I
j
h
i
H_j = \Sigma_{i\in I_j}h_i
Hj=Σi∈Ijhi,
O
b
j
(
t
)
≈
Σ
j
T
[
G
j
w
j
+
1
2
(
H
j
+
λ
)
w
j
2
]
+
γ
T
Obj^{(t)} \approx \Sigma_j^T[G_j w_j+\frac{1}{2}(H_j+\lambda)w_j^2]+\gamma T
Obj(t)≈ΣjT[Gjwj+21(Hj+λ)wj2]+γT
这样,我们复杂的目标函数就完全变成了小学生的二次型求最优解。
w
j
∗
=
−
G
j
H
j
+
λ
w_j^* = -\frac{G_j}{H_j+\lambda}
wj∗=−Hj+λGj
O
b
j
=
−
1
2
Σ
j
T
G
j
2
H
j
+
λ
+
γ
T
Obj = -\frac{1}{2}\Sigma_j^T\frac{G_j^2}{H_j+\lambda}+\gamma T
Obj=−21ΣjTHj+λGj2+γT

3.2.3 Searching Algorithm for Single Tree
(1) 生成方法
我们想要找到使目标函数最小的决策树,如果遍历所有可能的决策树,从中选择最优的决策树,这样工作量是巨大的。
我们采用贪婪算法生成一棵符合目标函数最小的决策树,做法:
- 从深度为0的一棵决策树开始,即只有一个根节点。
- 遍历所有属性,在属性
a
a
a上寻找使
增益 G a i n = G L 2 H L + λ + G R 2 H R + λ − ( G L + G R ) 2 H L + H R + λ − γ Gain = \frac{G_L^2}{H_L+\lambda}+\frac{G_R^2}{H_R+\lambda}-\frac{(G_L+G_R)^2}{H_L+H_R+\lambda}-\gamma Gain=HL+λGL2+HR+λGR2−HL+HR+λ(GL+GR)2−γ
最大的点。以这个属性、这个分裂点去分裂下一个节点。 - 重复,直到不能再继续分裂。
这种生成一棵深度为 K K K树的时间复杂度为
O ( n d K l o g ( n ) ) O(n d K log(n)) O(ndKlog(n)) 其中,我们在寻找最优切分点时,对属性 a a a的 n n n个值进行排序,为 O ( n l o g ( n ) ) O(nlog(n)) O(nlog(n)),有 d d d个特征,每增加一层深度就要重复一遍这个过程。
(2) 对离散变量
对离散值进行one-hot编码。
(3) 正则化与剪枝
XGBoost也有防止过拟合的措施,也有预剪枝和后剪枝的操作。
预剪枝:当本次最佳分裂点的增益为负值时停止剪枝,但有可能会错过对下面几次划分有利的分裂。
后剪枝:从下往上,剪掉所有负增益的枝。
Summary
至此,我们就得到了完成了XGBoost的推导,只要有了第 t − 1 t-1 t−1棵树,我们就能够生长出第 t t t棵树。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









