







 本文详细解析了HTML文档中的DOM模型,包括Document对象的特性、如何通过不同的方法查找页面元素,以及如何利用document对象进行文档信息的读取与修改。通过实际代码示例,读者可以了解到getElementById、getElementByTagName等方法的具体应用。
本文详细解析了HTML文档中的DOM模型,包括Document对象的特性、如何通过不同的方法查找页面元素,以及如何利用document对象进行文档信息的读取与修改。通过实际代码示例,读者可以了解到getElementById、getElementByTagName等方法的具体应用。
document对象是HTMLDocument的一个实例.表示整个HTML文档.
document也是window对象中的一个属性.
Document节点特征:
- nodeType值为9
- nodeName值为"#document"
- nodeValue值为null
- parentNode的值为null
- ownerDocument值为null
- 其子节点可能是一个DocumentType(最多一个) Element(最多一个) ProcessingInstruction或Comment
1.文档的子节点
如上所说,文档的子节点可能为DocumentType(最多一个) Element(最多一个) ProcessingInstruction或Comment
存在两个访问子节点的方式
- documentElement
- childNodes列表
2.文档信息
- document.title 文档标题
- document.URL 网页请求中完整的URL
- document.domain 域名
- document.reffer 来源页面的URL
//取得文档信息
var originTitle = document.title;
console.log(originTitle);
document.title = '汪苏泷好帅!';
console.log(document.title);
3.查找元素
页面代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<div id="myDiv">汪苏泷</div>
<img src="https://cube.elemecdn.com/0/88/03b0d39583f48206768a7534e55bcpng.png">
<img src="https://cube.elemecdn.com/0/88/03b0d39583f48206768a7534e55bcpng.png">
<ul>
<li name='color'>汪苏泷</li>
<li name='color'>汪苏泷</li>
<li name='color'>汪苏泷</li>
</ul>
</body>
</html>
3.1getElementById
该方法接收一个参数,就是元素的id,id在整个页面中是唯一的.
<div id="myDiv">汪苏泷</div>
//2.1 根据id查找元素
var div = document.getElementById("myDiv");
console.log(div);
输出结果
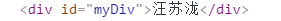
3.2getElementByTagName()
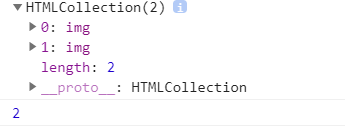
该方法接收一个参数,就是元素的标签名,返回包含零或多个元素的NodeList
//2.2 根据元素标签名
var images = document.getElementsByTagName('img');
console.log(images);
console.log(images.length);
输出结果
3.3 HTMLCollection集合
var lis = document.getElementsByName('color');
console.log(lis);
console.log(lis.length);
当使用getElementsByName方法,返回集合,尽管li的id不同,name的特性值相同,就会返回相同的
**namedItem()**方法只能返回第一项
3.4文档写入
| 方法 | 描述 |
|---|---|
| write | 原样写入 |
| writeln | 在字符串末尾添加一个换行符(\n) |
| open | 打开网页输出流 |
| close | 关闭网页输出流 |
<p>汪苏泷</p>
<script>
document.write("<strong>"+(new Date()).toString()+"</strong>");
//加载页面执行的函数
window.onload = function(){
alert("帅!");
}
</script>


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









