






 本文介绍了一种名为JSMA的生成对抗样本的方法。该方法通过计算前向导数,建立对抗显著图,最后修改样本输入特征,以实现对深度学习模型的攻击。实验表明,JSMA能够以高成功率生成对抗样本,同时对人类识别能力构成挑战。
本文介绍了一种名为JSMA的生成对抗样本的方法。该方法通过计算前向导数,建立对抗显著图,最后修改样本输入特征,以实现对深度学习模型的攻击。实验表明,JSMA能够以高成功率生成对抗样本,同时对人类识别能力构成挑战。
论文标题:对抗环境下深度学习的局限性
1、摘要
与之前的基于损失函数的梯度方向,使得损失越来越大,这篇文章提出直接增加神经网络对目标类别的预测值。该论文生成的对抗样本的扰动方向是目标类别标记的预测值的梯度方向,作者将这个梯度称为前向梯度(forward derivative)。提出JSMA生成对抗样本的方法,此方法属于目标攻击。
2、JSMA算法核心三步走
1、计算前向导数
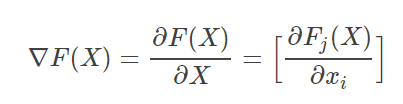
本质是雅克比矩阵(雅克比矩阵:描述空间伸缩变换的工具,是一阶偏导数以一定方式排列成的矩阵)
前向导数计算的梯度与Backpropagation反向传播计算的梯度不同,分别是:
(1)本文前向导数是直接对神经网络函数F进行梯度计算,而Backpropagation计算的梯度是对代价函数而言的;
(2)本文是对输入特定求偏导数,而Backpropagation是对神经网络的参数求偏导数的。
2、建立对抗显著图
显著图:表示不同的输入特征对分类结果的影响程度。说白了就是显著突出那些对预测结果影响较大的输入X,实这个方法也可以理解为根据雅可比矩阵和目标分类为输入向量的每一个特征打分。将所求的所有函数F对输入x的导数构成一个雅克比矩阵,着重关注那些导数大的值,来进行攻击。为了达到将对抗样本误分类成 t 的目的,F t ( X ) 的概率必须不断增大,且当j ! = t 时F j ( X ) 应该不断减小,直到预测结果为 t 的特征最大。
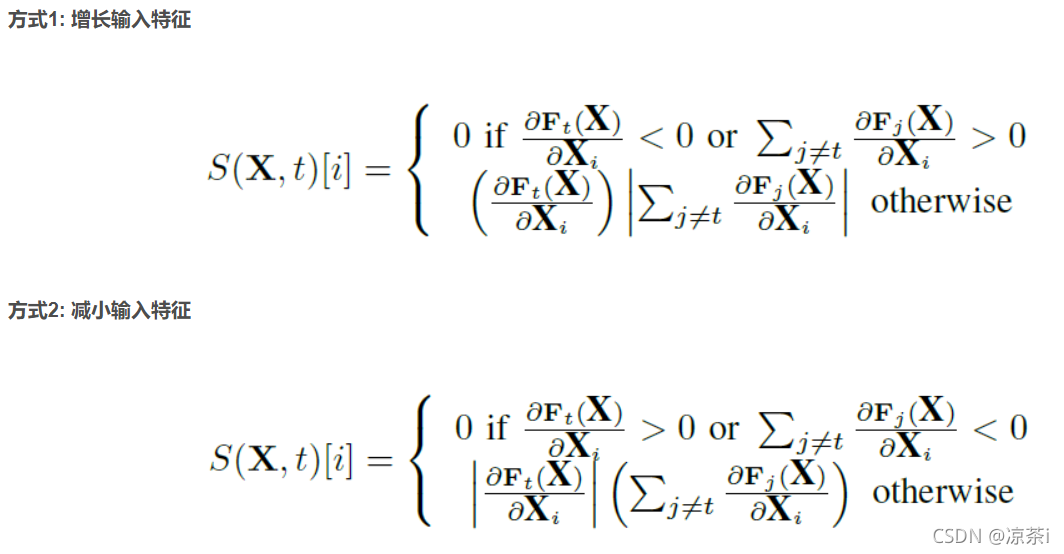
下面对方式1进行解读,方式2类似:
- 方式1第一行:Ft对Xi的导数小于0说明此导数对 t 类的预测起负作用,或者其他非 t 类的预测整体呈正向作用时,将显著图对应的映射设为0
- 方式1第二行:如果不是上面的情况,则说明特征 i 对将输入预测为 t 是有帮助的,并为它设置相应的值(考虑所有偏导数,结果仍然是正向)这一步其实文中没说清楚,我个人理解是修改了这个有帮助的特征 i ,进而帮助预测为 t 。(下一步才是修改了样本,为什么这里也要改动,有点懵)
针对我的疑惑,查阅了后应该是这样的,雅克比矩阵和显著图是两个东西,显著图根据雅克比矩阵来生成,进而确定需要修改的点,也就是最突出的那个点,所以显著图的计算并不会影响雅克比矩阵,或者说原来的特征。
3、样本的修改
通过对抗性显著图确定需要修改的输入特征后,对应的特征(像素点)应该修改为多少呢?文章引入参数 θ 表示输入特征的修改量。在MNIST实验中,作者设置参数为θ=+1 。
但是在实际操作时,每次选择一个像素点太严格(很难满足otherwise的条件,(上面的方式1和方式2)),于是作者提出了采用一组像素点而不是一个像素点的方法。


个人理解是因为单一像素点可能生成的对抗样本不够好,而去多改变几个像素点,至于到底改变哪几个,最终的计算只能用穷举法,然后看最终预测值。
方法2是改变了两个像素点的值。
方法3则是重新生成了两个新的矩阵,α和β,然后在其中寻找需要改变的像素点。
3、实验和结论
实验主要从三方面评估JSMA攻击方法的效果:
- 是否可以利用JSMA攻击任何样本?
- 如何确定样本被攻击的难易程度?
- 与DNN相比,人类是否可以正确认知JSMA攻击样本?
对于第一个问题,作者分别从MNIST数据中training、validation和Testing数据中选择10000个样本,每个样本产生对应的9个targeted对抗样本,从而总共产生270000个对抗样本。实验结果如下图所示,

JSMA攻击对任何样本能够以97%以上的成功概率产生对抗样本,并且修改的输入特征平均百分比在4%左右。意味着,一个样本784个像素中平均只要32个像素点被修改就能达到生成对抗样本的目的。(其实手写数字有用的像素点很少,大部分都是空白,所以4%不太能说明问题)
对于第二个问题,作者定义了Hardness measure 来度量原类别source被扰动成target类的难易程度;定义Adversarial distance
表示样本
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/6ce37be68c2df90fbb8ad8fe13a3f033.png) 到类别
到类别 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/91e93ec0042f21b4aa7cf7e1038ee392.png) 之间的距离,A距离越大表示越难将误分类成类。
之间的距离,A距离越大表示越难将误分类成类。
对于第三个问题,作者利用Mechanical Turk在线众包系统,分析人类判断JSMA对抗样本的结果。试验发现,人类不能发现无法发现JSMA对抗样本中添加的扰动,也就是满足了对抗样本“被DNN误分类,但是能被人类正确分类”的第二个条件。

















 2875
2875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









