







 本文分析了公众对马斯克收购Twitter的情绪,使用RoBERTa模型进行情感分类,结果显示94.7%的推文持正面情绪,主要关注点包括言论自由和平台发展。负面情绪中,人们担忧与特朗普相关的问题。
本文分析了公众对马斯克收购Twitter的情绪,使用RoBERTa模型进行情感分类,结果显示94.7%的推文持正面情绪,主要关注点包括言论自由和平台发展。负面情绪中,人们担忧与特朗普相关的问题。
原创 :Prabowo
作者:Prabowo Yoga Wicaksana
译者:LZM

推特董事会已于2022年4月25日同意埃隆·马斯克提出的440亿美元收购要约。支持言论自由是他决定收购Twitter的原因之一。他还想用新特性来增强产品,使算法开源以增加信任,打败垃圾邮件机器人,并建立完善的人类验证系统。
在这篇文章中,我们不会深入探讨这件事的经济学原理或对未来的影响,而是分析公众对这件事的情绪。
在介绍主题之前,我们先来回顾一下BERT和RoBERTa模型。
BERT
BERT,全名为Bi-directonal Encoder Representation from Transformer,是一种基于Transformer结构的双向语言编码模型。
与XLM-R一样,BERT和RoBERTa一起,被归类为预训练型语言模型(Pre-Trained Language Model,PLM)中的掩码语言模型(Masked Language Model,MLM)。MLM的训练目标是:根据给定的上下文,正确地预测被掩掉的单词。掩掉的单词被随机替换为[MASK]或者替换为随机token。
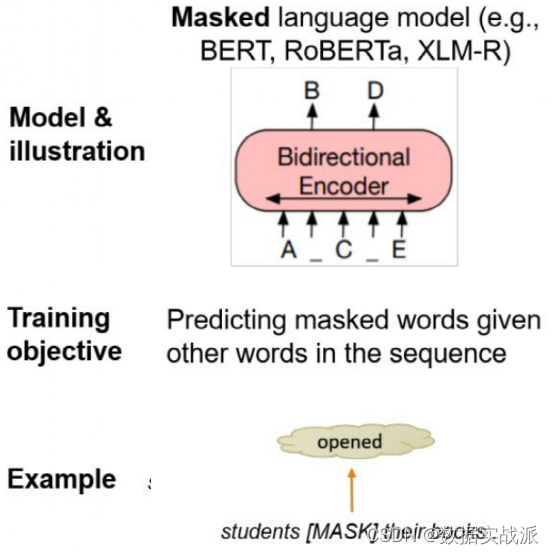
图1. Masked Language Model架构
BERT使用的是Transformer的编码器,而非想GPT家族那样使用Transformer解码器。BERT堆叠多个Transformer编码层来学习复杂的双向表征。RoBERTa使用了10倍的数据量在BERT的基础上改善了2-20%的性能。如果读者对此感兴趣,可以阅读该 Recent Advances in Natural Language Processing via Large Pre-Trained Language Models: A Survey 。
数据收集
这些数据是借助twint库在Twitter上收集(抓取)的。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3044
3044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









