




一、个人电脑(客户端)CPU
1.1 不同型号的CPU电路不同,下面是 Intel Core i7-3960 的结构图

-
core
core 表示物理核,英特尔利用超线程技术将一个物理核可以变为2个逻辑核,效率可以提供20% -
Shared L3 Cache
L3缓存,缓存内存数据,加速cpu的访问速度 -
Memory Controller
内存管理器,与内存互联,是一个用于管理与规划从内存到CPU间传输速度的总线电路控制器
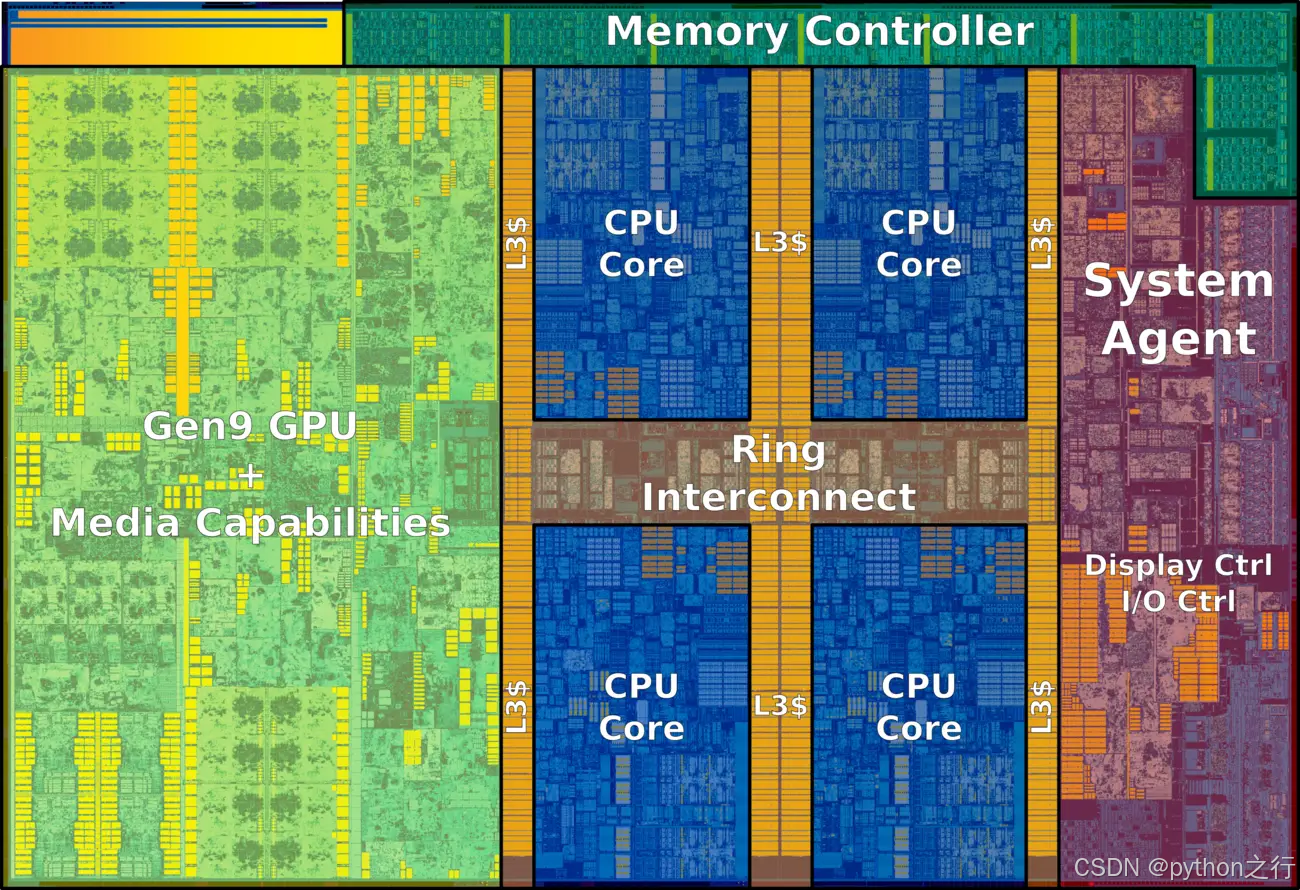
1.2 双核4线程cpu内部架构图
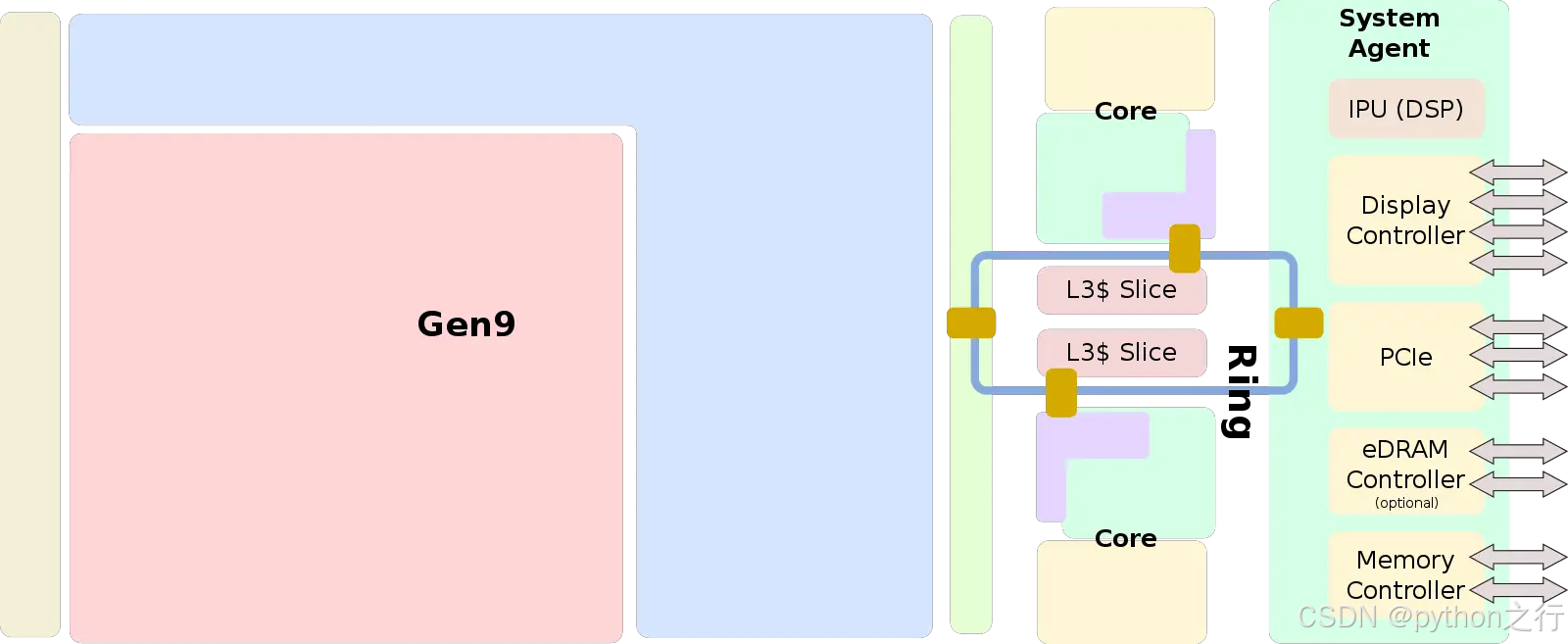
-
Gen9
表示个人cpu的集成显卡 -
PCIe
PCIe(Peripheral Component Interconnect Express)是一种高速串行计算机扩展总线标准,用于连接主板与高性能外设
1.3 4核8线程cpu内部架构图
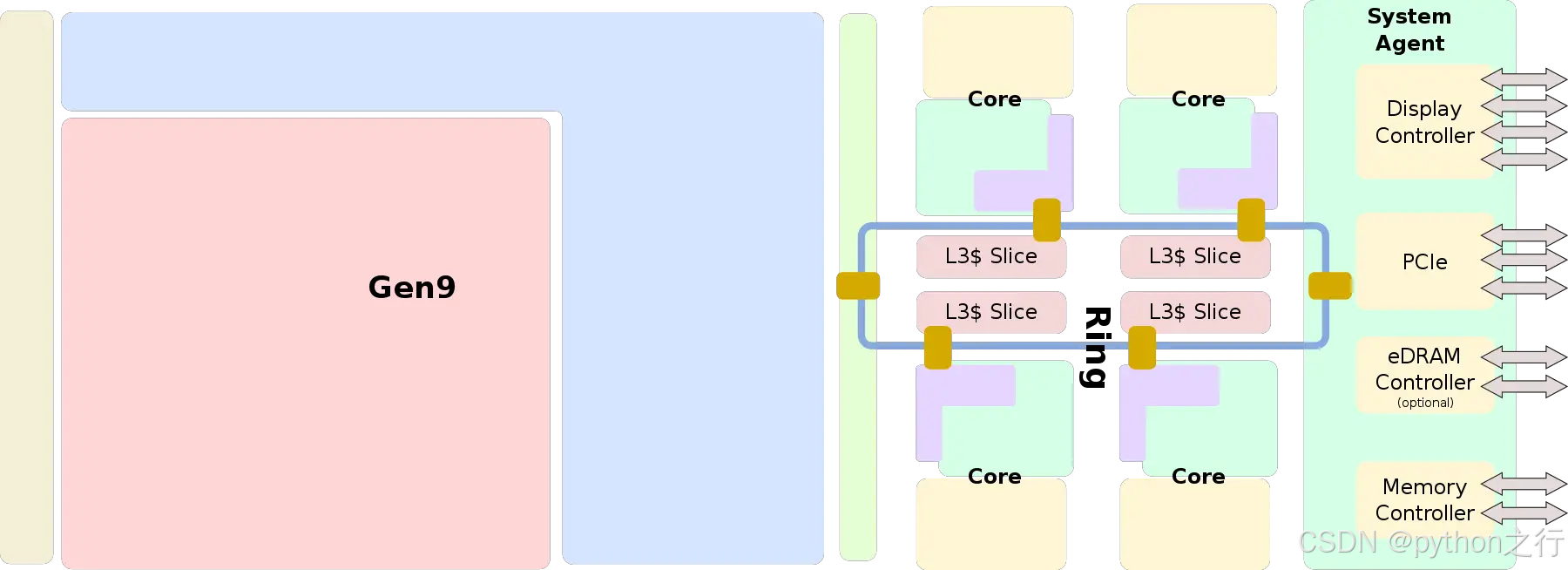
4核8线程Die 图
1.4 不同CPU参数对比
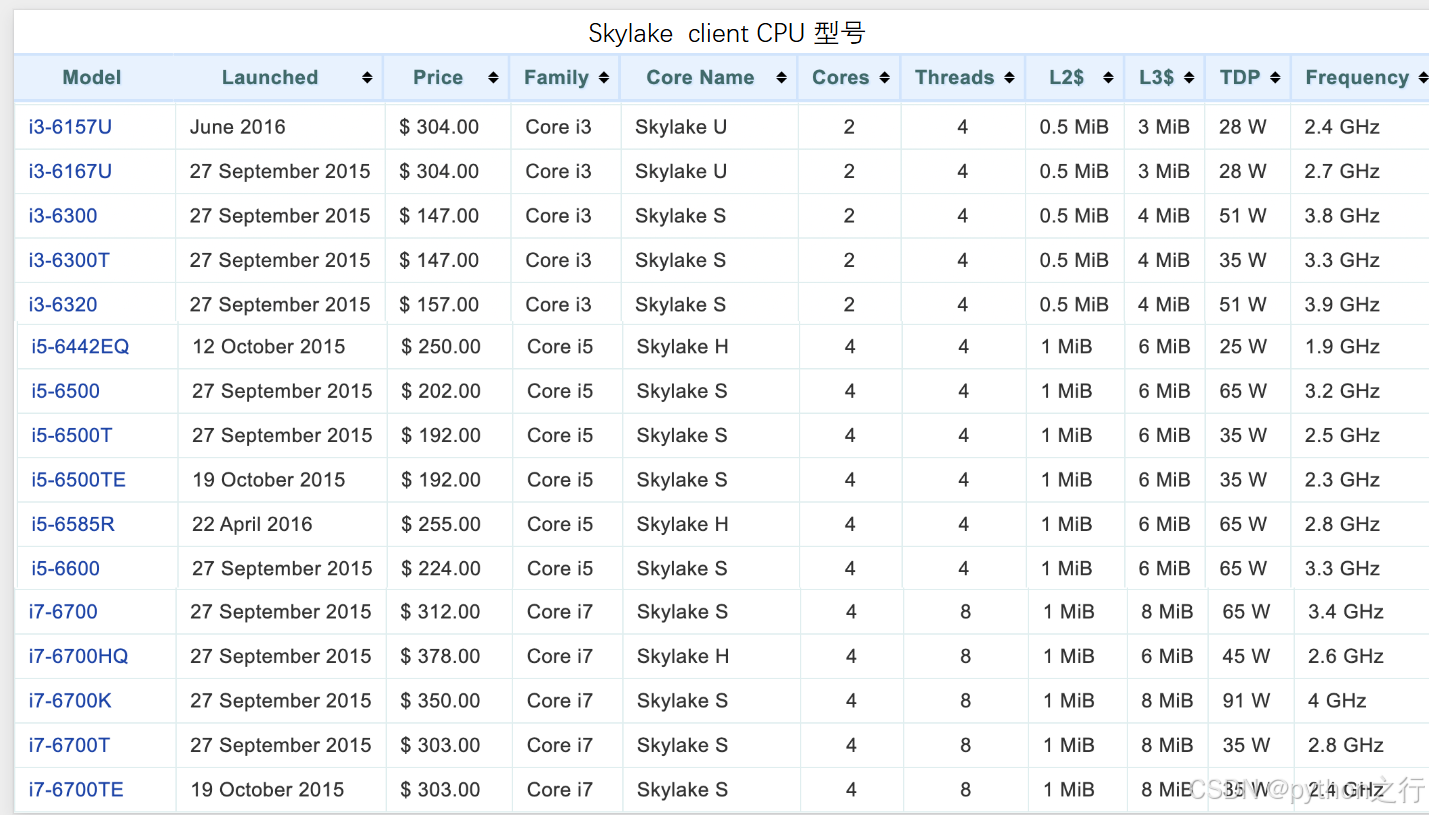
- Frequency
表示CPU的处理速度,比如2.71 GHz 表示其时钟频率为2.71千兆赫兹(GHz),即每秒执行27.1亿个时钟周期。时钟频率越高,CPU处理指令的速度通常越快,但实际性能还受架构、核心数、缓存等因素影响。因此,2.71 GHz仅反映CPU的基本运行速度,不能完全代表整体性能。
1.5 个人服务器CPU core 架构
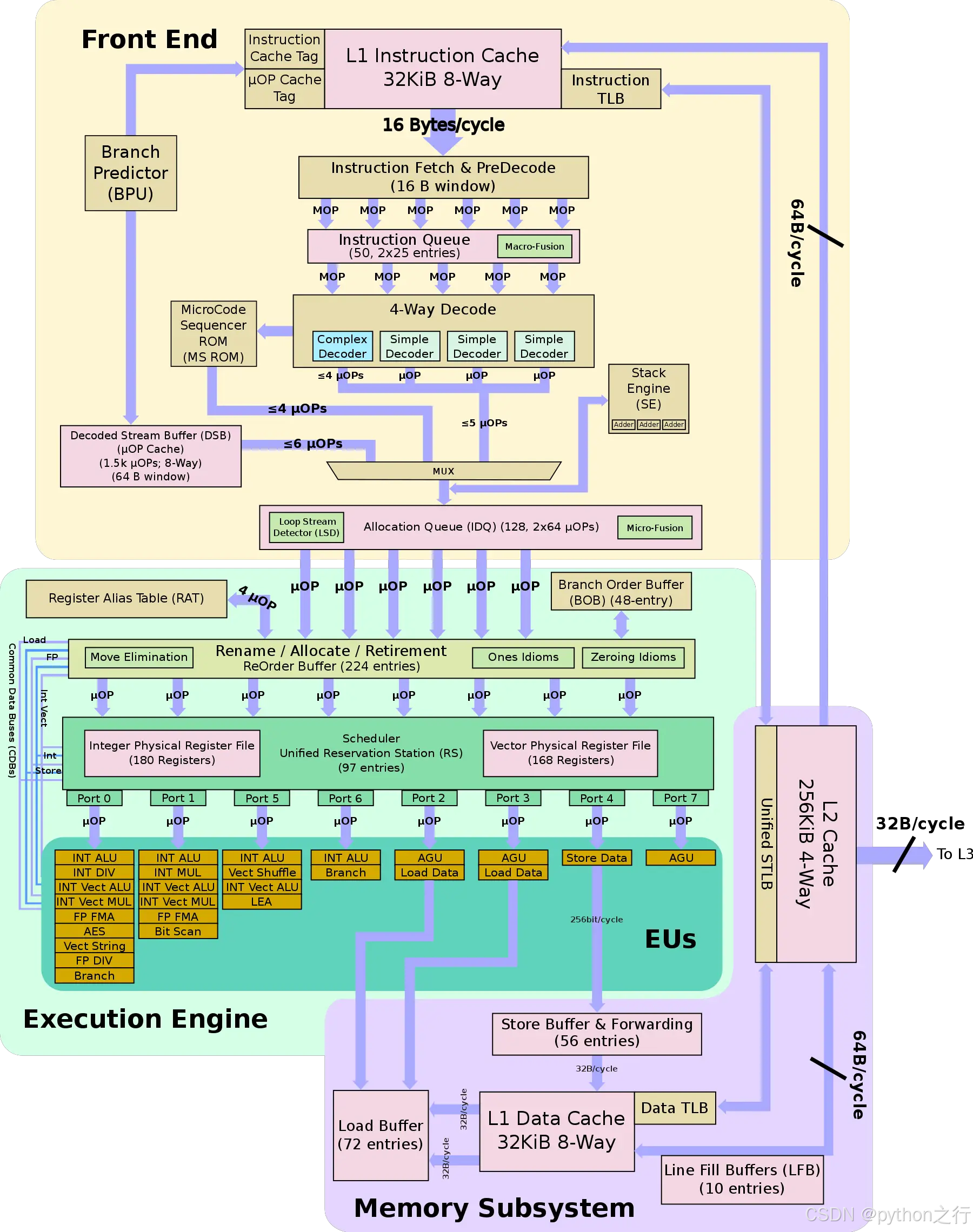
前端:预解码、解码、分支预测、L1指令缓存、指令TLB缓存
后端:顺序重排缓存器ROB处理依赖,调度器送到执行引擎
执行引擎:8路超标量,每一路可以进行独立的微操作处理
Port0、1、5、6支持整数、浮点数的加法运算,
Port2、3用于地址生成和加载,
Port4用于存储操作
缓存:L1、L2、数据TLB缓存
L1缓存(一级缓存)是计算机系统中速度最快、容量最小的缓存,通常集成在CPU内部,用于存储最常用的数据和指令,以减少访问主内存的延迟。
主要特点
速度快:L1缓存的访问速度最快,通常在1-2个时钟周期内完成。
容量小:容量通常在几十KB到几百KB之间。
位置近:直接集成在CPU核心内部,与核心距离最近。
分体结构:通常分为L1数据缓存(L1d)和L1指令缓存(L1i),分别存储数据和指令。
作用
减少延迟:通过存储常用数据,减少CPU访问主内存的时间。
提升性能:加快数据访问速度,提高整体系统性能。
TLB缓存
L1缓存(一级缓存)是计算机系统中速度最快、容量最小的缓存,通常集成在CPU内部,用于存储最常用的数据和指令,以减少访问主内存的延迟。
主要特点
速度快:L1缓存的访问速度最快,通常在1-2个时钟周期内完成。
容量小:容量通常在几十KB到几百KB之间。
位置近:直接集成在CPU核心内部,与核心距离最近。
分体结构:通常分为L1数据缓存(L1d)和L1指令缓存(L1i),分别存储数据和指令。
作用
减少延迟:通过存储常用数据,减少CPU访问主内存的时间。
提升性能:加快数据访问速度,提高整体系统性能。
工作原理
地址转换:当CPU需要访问内存时,首先将虚拟地址发送给MMU。
TLB查找:MMU首先在TLB中查找虚拟地址对应的物理地址。
命中与未命中:
TLB命中:如果TLB中存在该虚拟地址的映射,直接使用该物理地址访问内存。
TLB未命中:如果TLB中不存在该虚拟地址的映射,MMU需要访问页表来获取物理地址,并将该映射存入TLB中。
替换策略:当TLB满时,使用替换算法(如LRU)移除旧条目,为新条目腾出空间
示例
假设CPU需要访问虚拟地址V:
MMU首先在TLB中查找虚拟地址V的映射。
如果TLB中存在V的映射,直接使用对应的物理地址P访问内存。
如果TLB中不存在V的映射,MMU访问页表,找到V对应的物理地址P,并将该映射存入TLB中,然后使用P访问内存。
总结
TLB缓存通过加速虚拟地址到物理地址的转换,显著减少了地址转换的开销,从而提升了系统的整体性能。它是现代计算机系统中不可或缺的组件之一。
二、服务器CPU
2.1 服务器cpu

-
DDR4
第四代双倍数据率同步动态随机存储器(英语:Double-Data-Rate Fourth Generation Synchronous Dynamic Random Access Memory,简称为DDR4 SDRAM),一个存储器上有2个内存条槽,用于连接内存和cpu的通道 -
UPI
用于外联CPU设备,通过UPI,CPU可以互联
2.2 服务器CPU架构
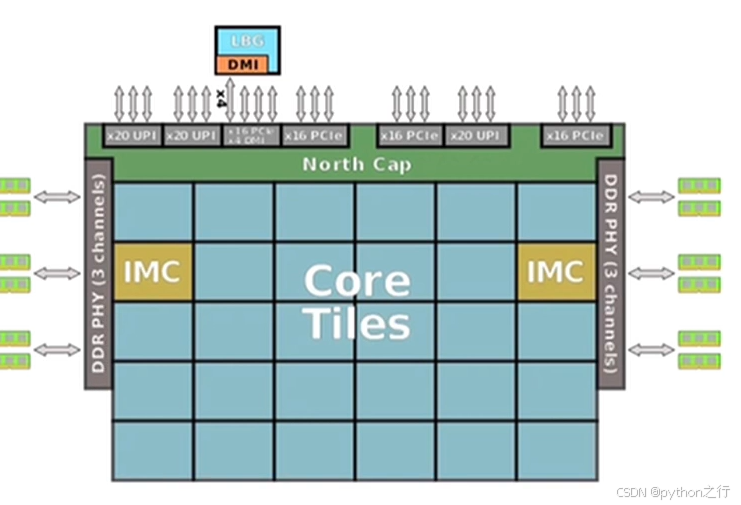
-
IMC
IMC(integrated memory controller)内存控制器。共有两个IMC,每个IMC支持 3 个channels(就是DDR4),每个通道支持两个 DIMM 内存条,总共支持最大 2*3*2 = 12 个内存条。 -
物理核阵列
这个代际中采用的是 Mesh 架构,5行6列。 -
North Cap
PCIe 总线(用来连接显卡硬盘等)
UPI 总线(用于多 CPU 片间互联)
2.3 Ring架构
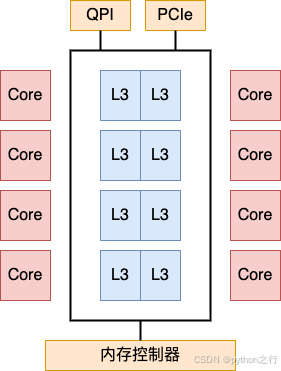
2017年之前的Ring架构
为了减少访问内存延迟,距离越远,访问内存延迟就越大,所以环上的物理核设计的数量非常有限
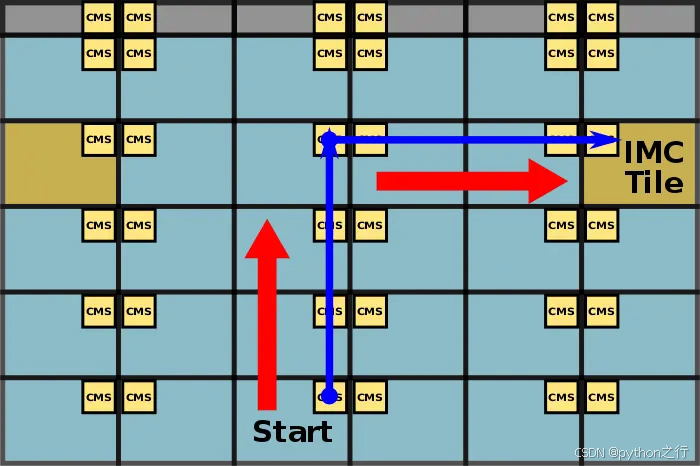
2.4 Mesh 架构
现在物理核最多可以有40个

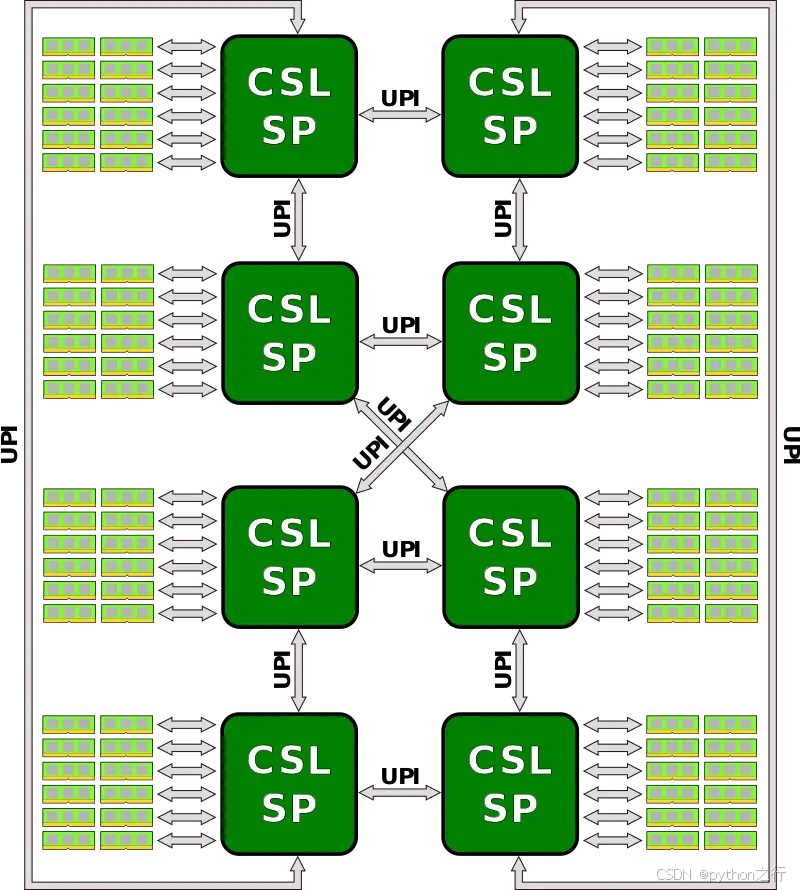
2.5 UPI总线 cpu互联

















 1886
1886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









