







 本文探讨了未来20年微处理器面临的晶体管速度放缓和能量限制问题,以及如何通过并行性、异构核心和缓存优化来提升性能和能效。文章还讨论了微体系结构技术如流水线、分支预测和缓存对性能的影响,以及内存层次结构优化和封装功率限制。面对这些挑战,未来研究将侧重于增加晶体管密度、降低数据移动能耗和开发多核、定制化解决方案。
本文探讨了未来20年微处理器面临的晶体管速度放缓和能量限制问题,以及如何通过并行性、异构核心和缓存优化来提升性能和能效。文章还讨论了微体系结构技术如流水线、分支预测和缓存对性能的影响,以及内存层次结构优化和封装功率限制。面对这些挑战,未来研究将侧重于增加晶体管密度、降低数据移动能耗和开发多核、定制化解决方案。
The future of microprocessors (2011)
-
在未来20年中,晶体管的缩小速度缩减和实际的能量限制会对持续的性能提升带来新的挑战。这些问题会导致操作的频率增加缓慢,能耗成为性能的关键限制因素,迫使设计使用大规模并行性,异构核心和加速器来实现性能和能效。另一方面软硬件协同实现高效的数据编排(orchestration)也更加的重要
-
微处理器的定义特性仍旧是 体现了计算机系统中的主要计算引擎(数据转换)的 单个半导体芯片
-
20年内性能的指数提升的三个主要技术
-
晶体管速度的减少:主力军,晶体管性能提上了接近5个数量级
- 晶体管尺寸缩小30%(0.7),面积缩小50%,每一代技术都使得晶体管密度增加一倍(摩尔定义的根本原因)
- 晶体管尺寸缩小30%,性能提升约40%(延迟降低0.7倍,频率增加1.4)
- 为了保持电势恒定,电源电压降低30%,能耗降低65%,功率降低50%(有功功率= CV^2f)。即每一代技术中,晶体管密度翻倍,电路速度提升40%,功耗保持不变(晶体管数量增加一倍)
- 过去20年,这种技术使得微处理器性能提升了3个数量级
-
核心的微体系结构技术:流水线,分支预测,乱序执行,推测执行,缓存
-
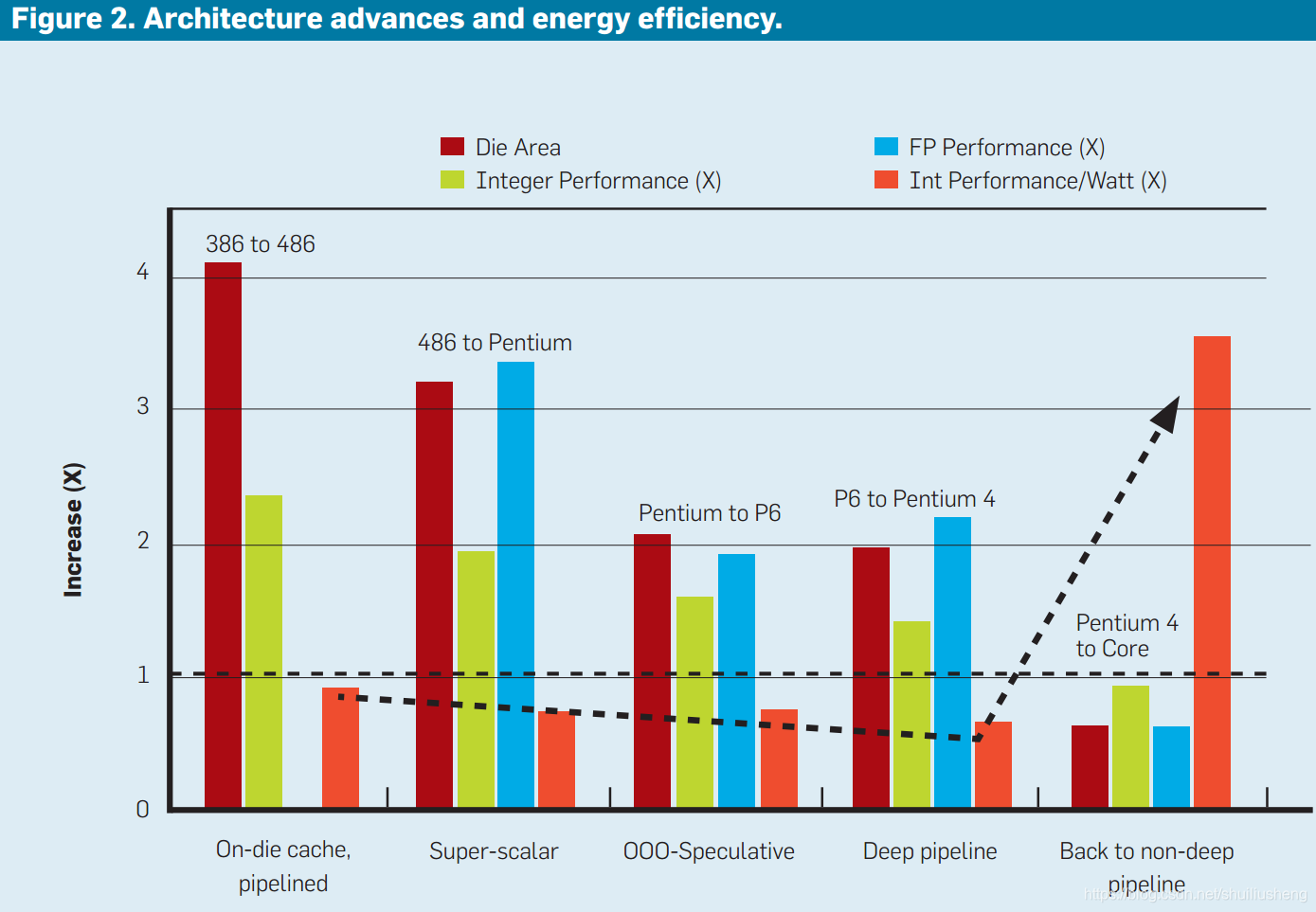
图中概述了微体系结构的发展,显示了在同一个工艺技术下 归一化之后的芯片面积,性能和能效的增加情况。
-
使用的Intel微处理器:386,486,Pentium, Pentium Pro, Pentium 4
-
基准测试程序:SpecInt(92, 95, 2000)
-
对于晶体管使用较好的片上缓存和流水线结构能够在不影响能效的情况下提高性能;超标量和乱序能够以能效为代价提高可观的性能;深流水线结构在和乱序和推测结构相同的面积情况下提供了最低的性能提升和功耗提升,但是能效最高
-
深流水线结构(deep pipelined architecture):更深的流水线以及用于实现更高频率的其他电路和微体系结构技术
-
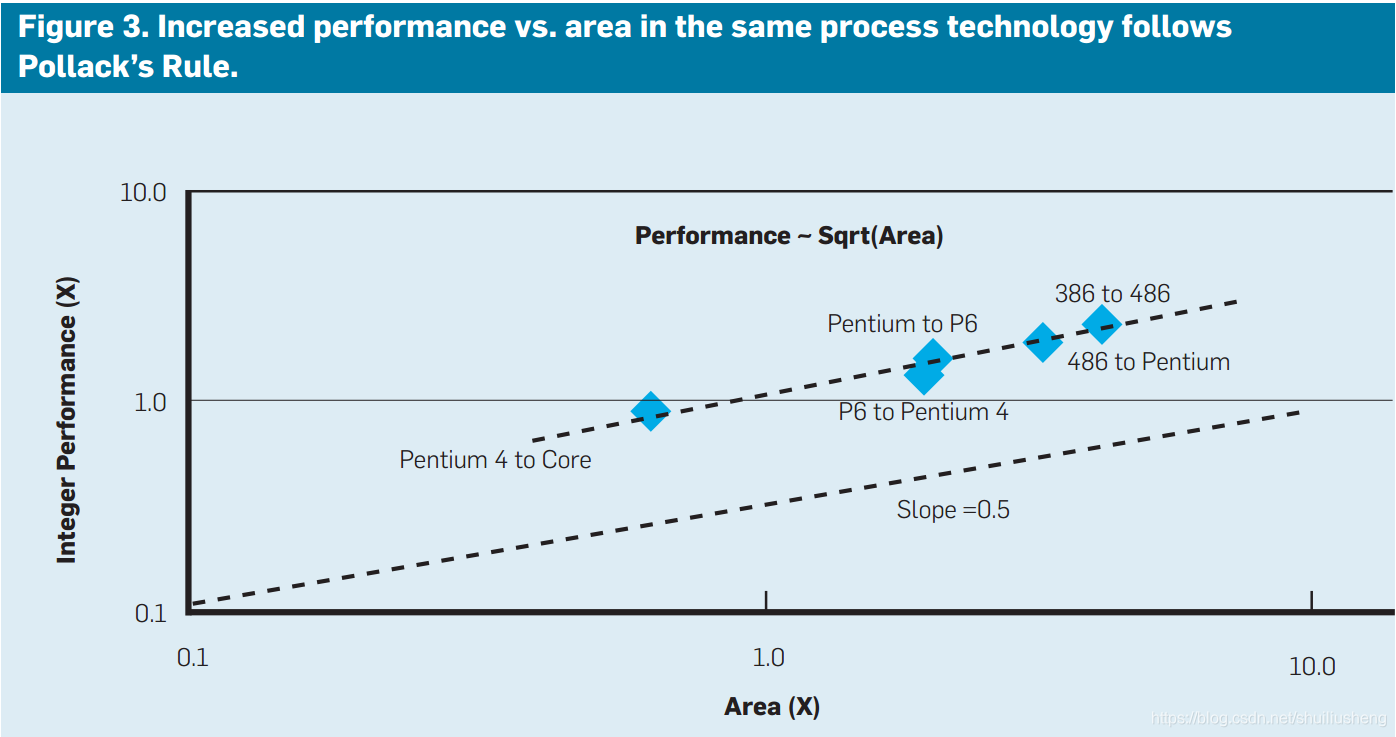
Pollack Rule:同制程工艺下,处理器的芯片面积(晶体管数量)提升2-3倍,性能只能提升至约1.4-1.7倍(面积的平方根)(当不受系统其他部分限制时)
-
图中显示了不同的微体系结构带来的面积和性能增加的情况(面积的增加并没有带来Pollack Rule提出的性能提升)
-
-
缓存存储体系结构
-
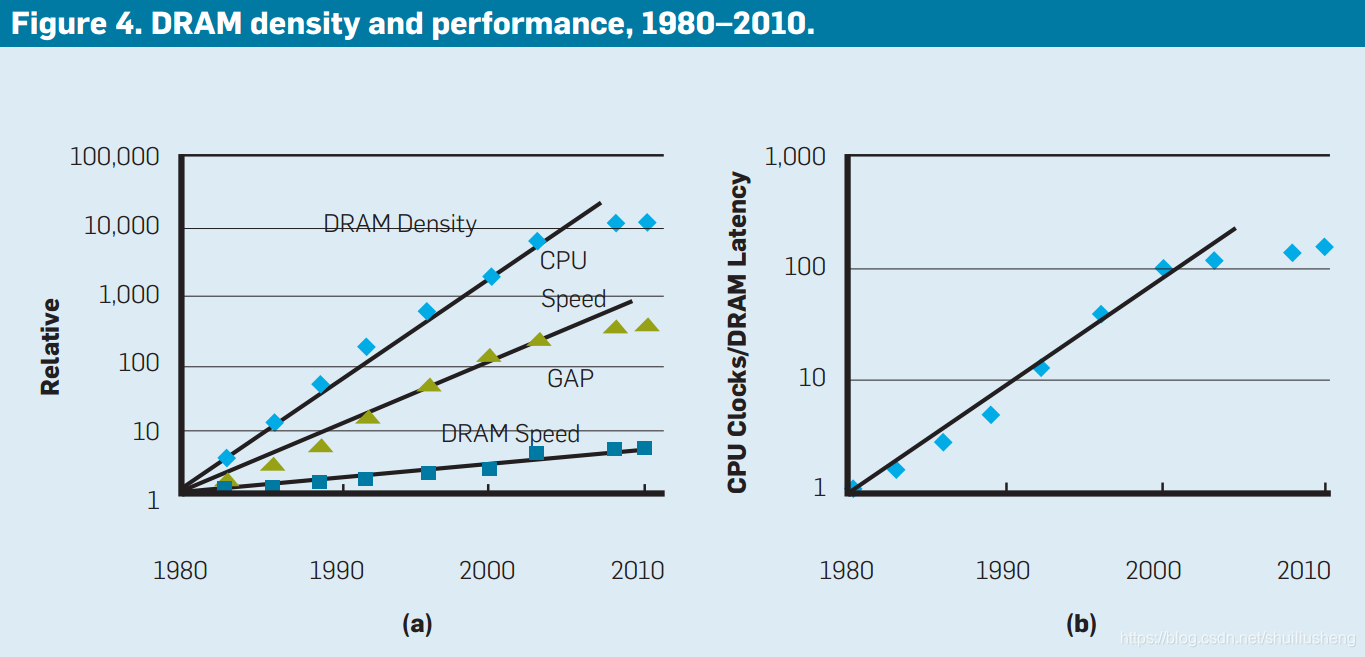
内存密度几乎每两年翻一番,但是性能提高的速度更慢,和CPU之间的速度差距也越来越大,导致了内存瓶颈,降低系统的整体性能
-
内存组织结构是为了针对密度和底层本进行了优化,导致速度更慢。
-
复杂而有效的内存层次结构的出现使得DRAM可以更加强调密度和成本,而不是速度
-
图中为Intel的处理器中cache的容量和占芯片面积的情况。随着能耗更加重要,事实证明,提高缓存大小所带来的性能比额外的微体系结构技术所需要的高能耗(能耗密度高)逻辑的能效更高

-
-
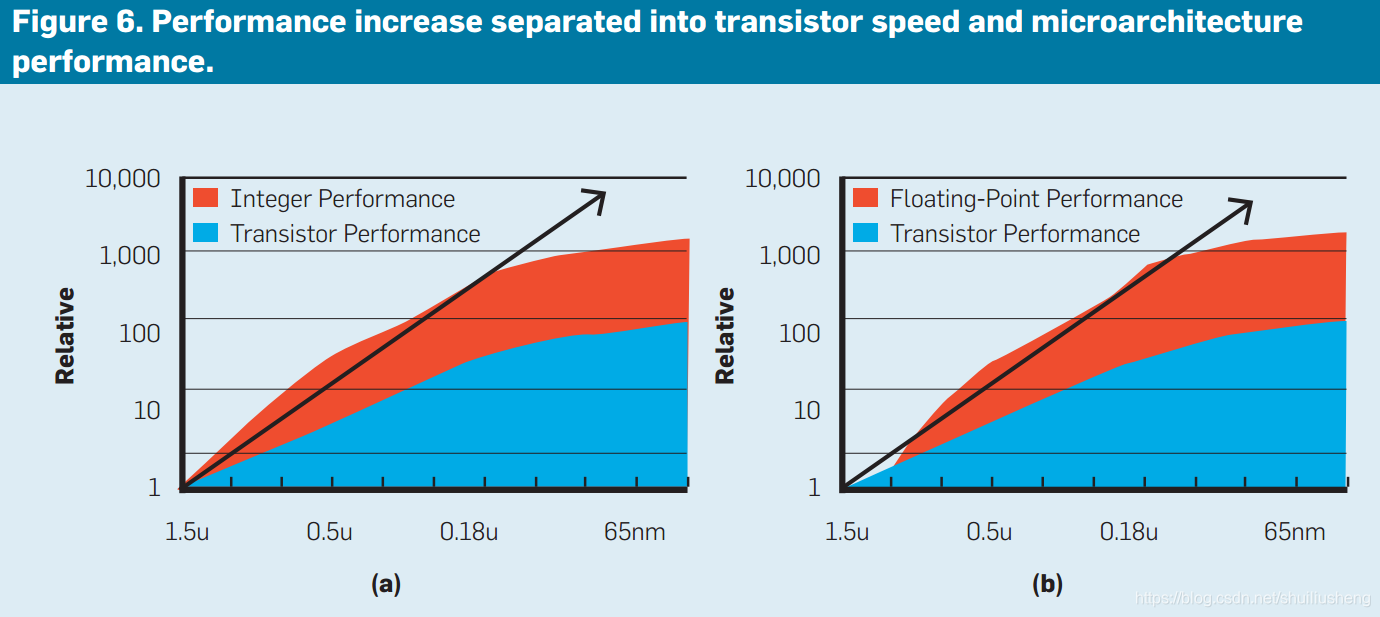
图中显示了过去20年中Intel微处理器累积的1000倍的性能提升,并且将其划分为晶体管速度带来的提升和微体系结构技术而带来的提升(仅有晶体管速度提升而提升的性能大致为两个数量级)
-
-
未来20年的研究
-
新技术发展的挑战
- 晶体管缩小带来的性能降低:尽管持续小型化,但是性能几乎没有改善,晶体管的开关能量几乎没有减少(缩放带来的性能优势下降)
- 固定总能源预算:封装功率和移动/嵌入式计算推动了能效要求
-
正在研究的技术
- 增加晶体管密度和数量:技术创新,封装创新
- 增加局部性,降低每次操作的带宽:应用的数据集不断地增大
-
晶体管在关断时的泄露电流随着阈值电压的降低呈指数增长,导致功耗的很大一部分来自于泄露,因此在实际上必须提高阈值电压,从而导致晶体管性能降低。晶体管的尺寸到达原子尺寸是,光刻和可变性会导致新的挑战,从而影响电压缩放比例的变化。
-
封装功耗/总能耗限制了逻辑晶体管的数量。
-
图中显示了在45nm工艺下,100mm2的芯片面积情况下,逻辑电路的晶体管数和整体功耗以及缓存大小之间的关系(Core2 Duo,45nm,两个核各25million晶体管,共6MB缓存,100mm2)
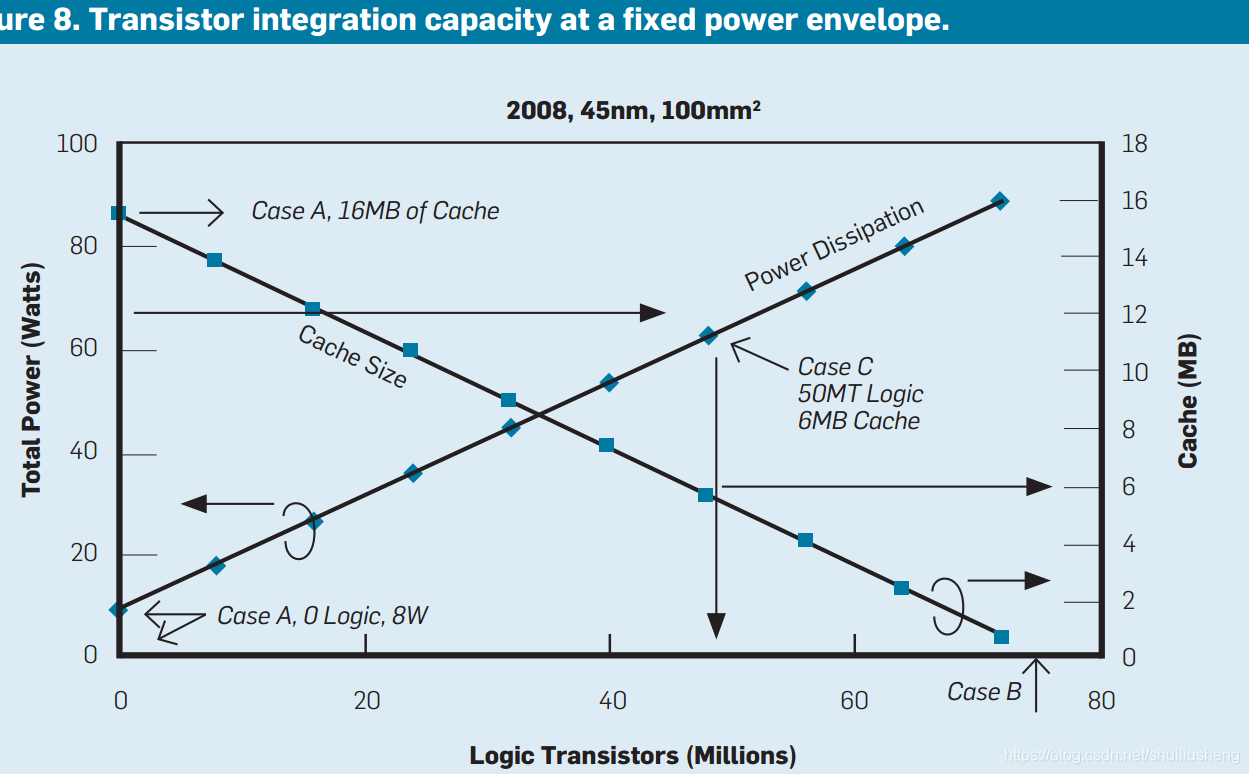
-
能效是将会是体系结构设计的关键指标,并且能量比例(use energy in proportion to the work done )计算必须是硬件架构和软件应用程序设计的最终目标。对于有限能量预算下的处理器,能效直接对应于更高的性能。
-
-
组织芯片上的逻辑:多核和定制电路
-
多核和定制化将会是未来微处理器性能的主要驱动力(芯片的整体性能)。前者提高计算吞吐量,后者则减少执行的延迟,两者都可以提高能效
-
在以前,由于定制化加速器的使用范围的限制,软件开发人员没有动力去定制加速器,并且加速器的性能优势也可能被传统微处理器的进步所取代。但是随着单线程性能提升减慢,这种情况发生了显著的改变,并且对于许多应用可能是唯一的方法来提高性能/能效
-
逻辑组织和设计的挑战,趋势和方向

-
-
编排(orchestrate)数据移动:存储层次结构和互连
-
从本地寄存器和缓存中检索数据的能耗远小于进入DRAM/二级缓存的能耗
-
处理单元之间必须有效的移动数据,并且必须针对具有高局部性的互连网络来优化任务的安置和调度
-
图中所表示的延迟和能耗是指在芯片上移动一位数据时的情况。如果操作数平均移动1mm(裸片尺寸的10%),以0.1pJ/bit的速率移动时,则每秒移动576Tb的功耗为58W,即几乎没有任何能量可用于计算。但是如果大多数操作保持在执行单元本地(例如寄存器),则移动距离远小于1mm,功耗此时仅为6W。
-
图(b)显示的是在网络中跨越一点移动1位所消耗的能量。
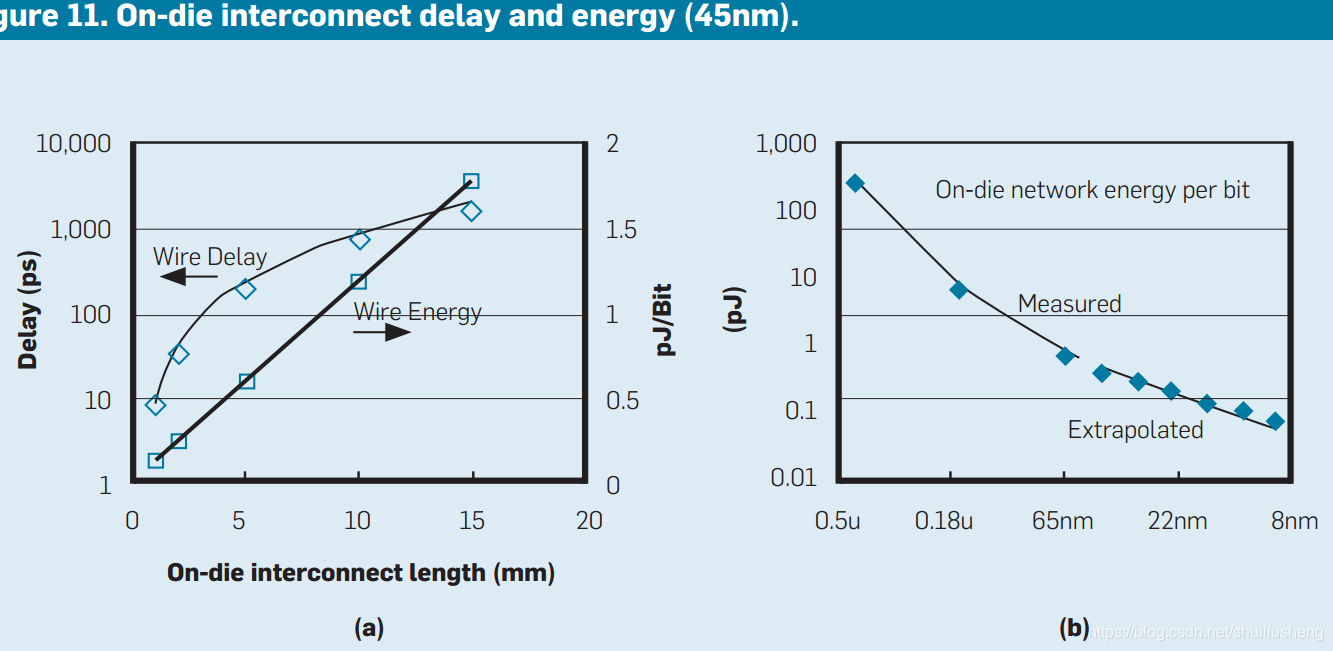
-
通过电压缩放(voltage scaling),无论如何,操作的频率都会降低,因此以牺牲速度为代价来增加本地存储的大小限制数据移动是有意义的
-
数据移动的挑战,趋势和方向
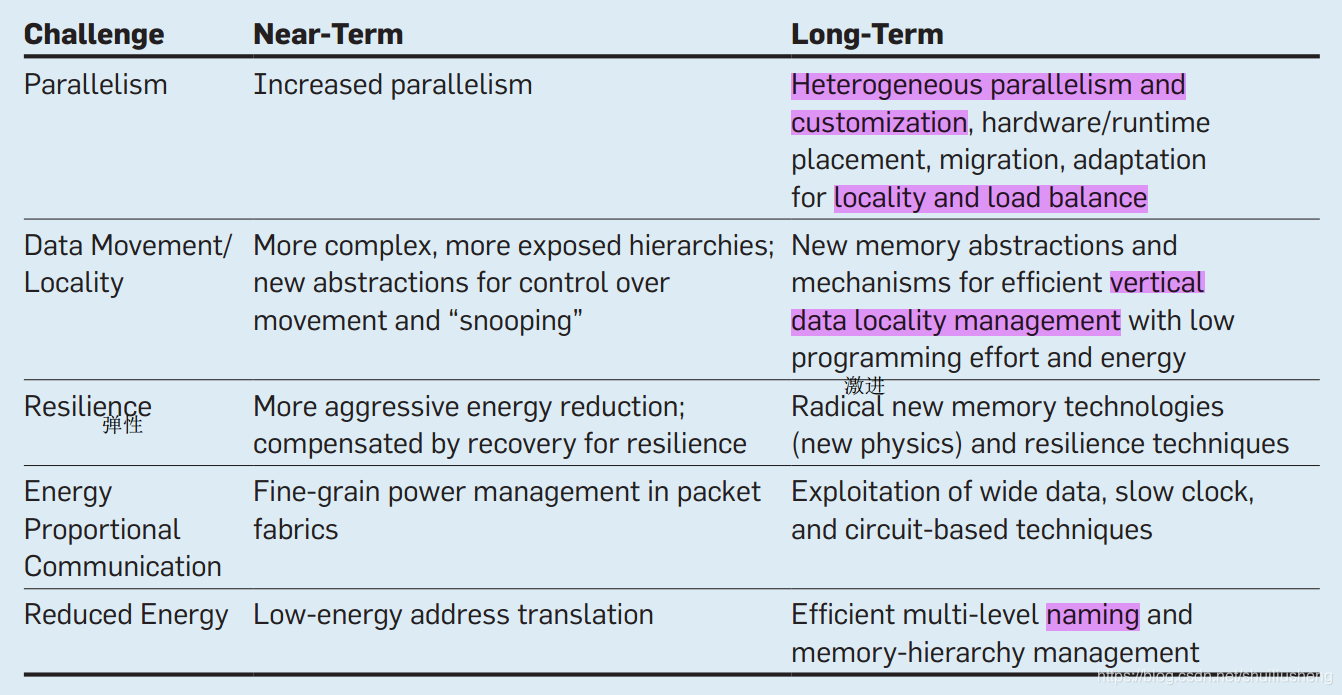
-
-
突破极限:极端的电路,可变性,弹性
-
图中显示了电压缩放技术对晶体管的影响,包括速度,功耗,能效和有源泄露功耗(active leakage power)。随着电压的增加,速度和功耗都会增加,但是能效会减少。当电源电压降到晶体管的阈值时,能量效率将提高一个数量级。但是当电压降到晶体管的阈值电压时,可变性的影响更糟糕。
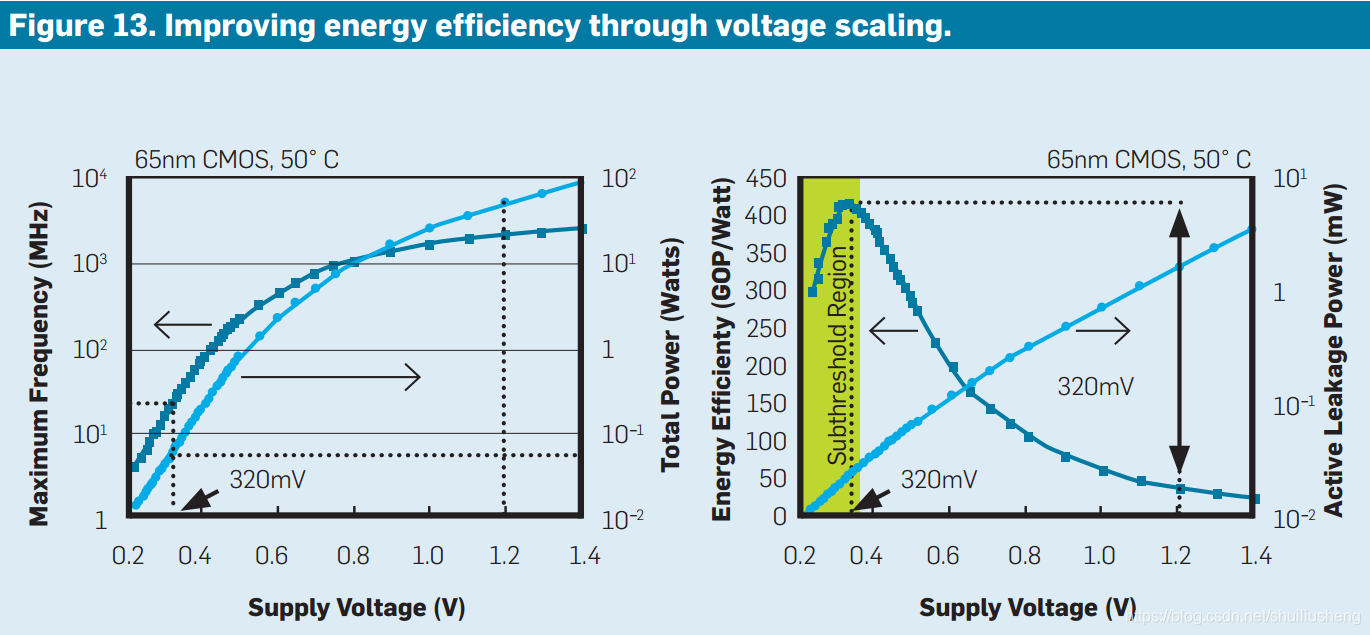
-
异构,激进的电压缩放和细粒度功耗管理相结合,能够更大程度的利用晶体管能力,提供接近目标的性能提升
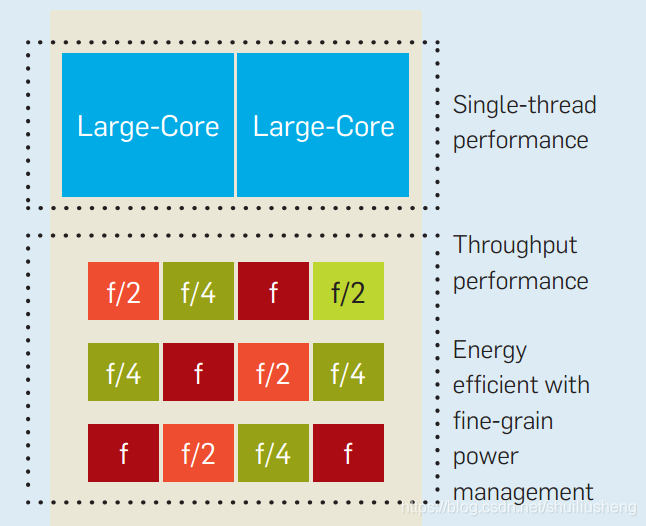
-
-
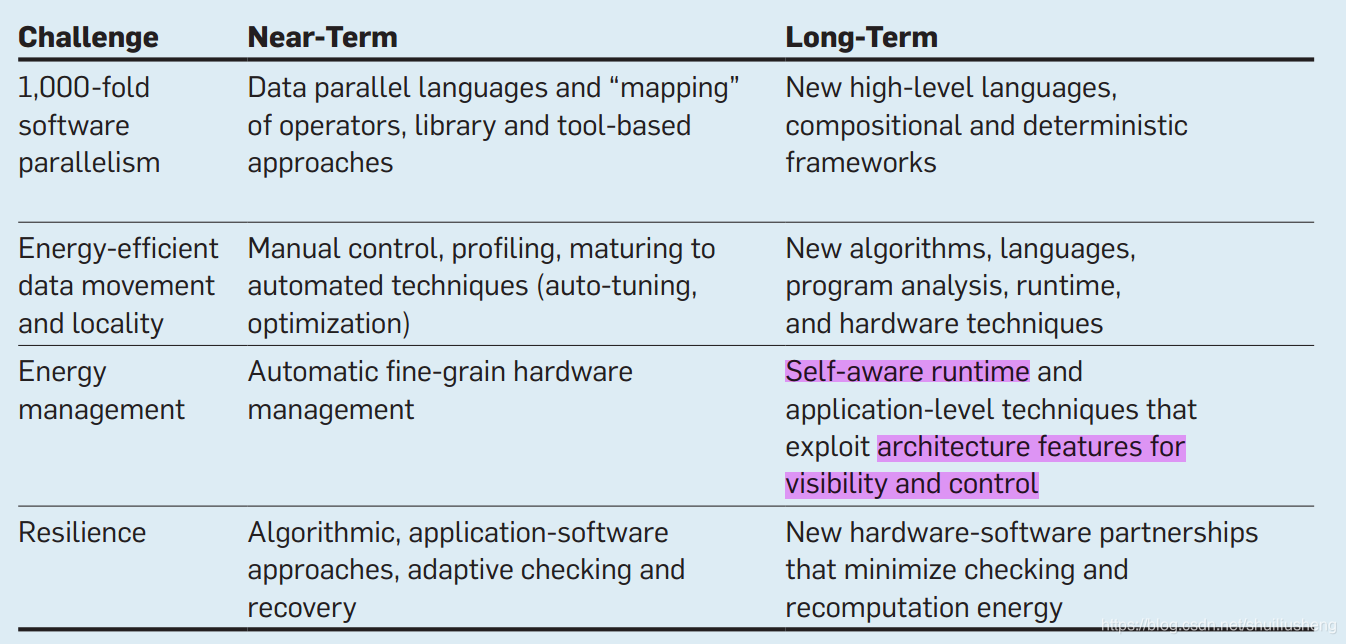
软件上的挑战:可编程性与效率
-
单线程向对称并行性的转变可能是计算历史上最大的软件挑战。
-
将更多的计算和数据在微处理器的计算和存储元素之间的分配责任转移到了软件上。转移责任可以提高潜在的可实现的能源效率
-
软件上的挑战:可编程性与效率
-
单线程向对称并行性的转变可能是计算历史上最大的软件挑战。
-
将更多的计算和数据在微处理器的计算和存储元素之间的分配责任转移到了软件上。转移责任可以提高潜在的可实现的能源效率

















 4986
4986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









