



前言
在上一篇文章中,介绍了 Android 利用 OpenGLES 进行通用计算的方法
https://blog.youkuaiyun.com/shouhengboy/article/details/151177060
之前只是用简单的浮点数运算验证可行性,本文就实际利用此技术来做些有用的运算,计算 MD5。并在实际的过程融会贯通上一篇中计算着色器的使用,并完善一些细节。
MD5
MD5信息摘要算法(英语:MD5 Message-Digest Algorithm),可将任意长度数据转换为128位(16字节)的离散值,常用于密码存储提高数据安全性。
MD5具有不可逆性,无法直接还原原始数据,只能利用穷举字符组合的方式才能找到其"可能的"原始数据(多个不同的原始数据可能有相同的MD5)。
MD5具体算法网上可以找到很多版本,我使用的是这个版本
https://pajhome.org.uk/crypt/md5/md5.html
根据上面的 js 代码,改写成 GLSL 的版本,包括处理一些语言差异的问题,最终代码如下:
// 数据原数组的长度
uniform int u_arrLen;
int safe_add(int x, int y) {
int lsw = (x & 0xFFFF) + (y & 0xFFFF);
int msw = (x >> 16) + (y >> 16) + (lsw >> 16);
return (msw << 16) | (lsw & 0xFFFF);
}
int bit_rol(int num, int cnt) {
// return (num << cnt) | (num >>> (32 - cnt));
// glsl 没有 >>> 运算符,需特殊处理
int n1 = (num << cnt);
int n2;
int shift = (32 - cnt);
if(shift <= 0) {
n2 = num;
} else {
if(num >= 0) {
n2 = num >> shift;
} else {
// 原始值 x = 0b11000000000000000000000000000000
// 如果是 x >>> 2,会变成 0b00110000000000000000000000000000
// 如果是 x >> 2,会变成 0b11110000000000000000000000000000
// 如果把 0b11110000000000000000000000000000 & 0b00111111111111111111111111111111 可以变成 0b00110000000000000000000000000000
// 0b01111111111111111111111111111111 >> (2 - 1) = 0b00111111111111111111111111111111
int mask = 0x7FFFFFFF;
if(shift > 1) {
mask = mask >> (shift - 1);
}
n2 = num >> shift;
n2 = n2 & mask;
}
}
return n1 | n2;
}
int md5_cmn(int q, int a, int b, int x, int s, int t) {
// return safe_add(bit_rol(safe_add(safe_add(a, q), safe_add(x, t)), s),b);
return (bit_rol(((a + q) + (x + t)), s) + b);
}
int md5_ff(int a, int b, int c, int d, int x, int s, int t) {
return md5_cmn((b & c) | ((~b) & d), a, b, x, s, t);
}
int md5_gg(int a, int b, int c, int d, int x, int s, int t) {
return md5_cmn((b & d) | (c & (~d)), a, b, x, s, t);
}
int md5_hh(int a, int b, int c, int d, int x, int s, int t) {
return md5_cmn(b ^ c ^ d, a, b, x, s, t);
}
int md5_ii(int a, int b, int c, int d, int x, int s, int t) {
return md5_cmn(c ^ (b | (~d)), a, b, x, s, t);
}
ivec4 core_md5(int arr[4]) {
// arr2binl
int bin[16] = int[16](0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0);
int CHRSZ = 8;
{
int len = u_arrLen * CHRSZ;
int mask = (1 << CHRSZ) - 1;
for (int i = 0; i < len; i += CHRSZ) {
bin[i>>5] |= (arr[i / CHRSZ] & mask) << (i%32);
}
}
// core_md5
int x[16] = bin;
int len = u_arrLen * CHRSZ;
x[len >> 5] |= 0x80 << ((len) % 32);
/*
原始代码 x[(((len + 64) >>> 9) << 4) + 14] = len;
>> 带符号右移:空位补符号位(正补0,负补1)。
>>> 无符号右移:无论正负空位都补0,是Java特有运算符。
glsl不支持 >>> ,先用 >> 处理,到时有问题再改
目前只考虑短数据的md5,len+64 不会是负
*/
x[(((len + 64) >> 9) << 4) + 14] = len;
int a = 1732584193;
int b = -271733879;
int c = -1732584194;
int d = 271733878;
for(int i = 0; i < x.length(); i += 16)
{
int olda = a;
int oldb = b;
int oldc = c;
int oldd = d;
a = md5_ff(a, b, c, d, x[i+ 0], 7 , -680876936);
d = md5_ff(d, a, b, c, x[i+ 1], 12, -389564586);
c = md5_ff(c, d, a, b, x[i+ 2], 17, 606105819);
b = md5_ff(b, c, d, a, x[i+ 3], 22, -1044525330);
a = md5_ff(a, b, c, d, x[i+ 4], 7 , -176418897);
d = md5_ff(d, a, b, c, x[i+ 5], 12, 1200080426);
c = md5_ff(c, d, a, b, x[i+ 6], 17, -1473231341);
b = md5_ff(b, c, d, a, x[i+ 7], 22, -45705983);
a = md5_ff(a, b, c, d, x[i+ 8], 7 , 1770035416);
d = md5_ff(d, a, b, c, x[i+ 9], 12, -1958414417);
c = md5_ff(c, d, a, b, x[i+10], 17, -42063);
b = md5_ff(b, c, d, a, x[i+11], 22, -1990404162);
a = md5_ff(a, b, c, d, x[i+12], 7 , 1804603682);
d = md5_ff(d, a, b, c, x[i+13], 12, -40341101);
c = md5_ff(c, d, a, b, x[i+14], 17, -1502002290);
b = md5_ff(b, c, d, a, x[i+15], 22, 1236535329);
a = md5_gg(a, b, c, d, x[i+ 1], 5 , -165796510);
d = md5_gg(d, a, b, c, x[i+ 6], 9 , -1069501632);
c = md5_gg(c, d, a, b, x[i+11], 14, 643717713);
b = md5_gg(b, c, d, a, x[i+ 0], 20, -373897302);
a = md5_gg(a, b, c, d, x[i+ 5], 5 , -701558691);
d = md5_gg(d, a, b, c, x[i+10], 9 , 38016083);
c = md5_gg(c, d, a, b, x[i+15], 14, -660478335);
b = md5_gg(b, c, d, a, x[i+ 4], 20, -405537848);
a = md5_gg(a, b, c, d, x[i+ 9], 5 , 568446438);
d = md5_gg(d, a, b, c, x[i+14], 9 , -1019803690);
c = md5_gg(c, d, a, b, x[i+ 3], 14, -187363961);
b = md5_gg(b, c, d, a, x[i+ 8], 20, 1163531501);
a = md5_gg(a, b, c, d, x[i+13], 5 , -1444681467);
d = md5_gg(d, a, b, c, x[i+ 2], 9 , -51403784);
c = md5_gg(c, d, a, b, x[i+ 7], 14, 1735328473);
b = md5_gg(b, c, d, a, x[i+12], 20, -1926607734);
a = md5_hh(a, b, c, d, x[i+ 5], 4 , -378558);
d = md5_hh(d, a, b, c, x[i+ 8], 11, -2022574463);
c = md5_hh(c, d, a, b, x[i+11], 16, 1839030562);
b = md5_hh(b, c, d, a, x[i+14], 23, -35309556);
a = md5_hh(a, b, c, d, x[i+ 1], 4 , -1530992060);
d = md5_hh(d, a, b, c, x[i+ 4], 11, 1272893353);
c = md5_hh(c, d, a, b, x[i+ 7], 16, -155497632);
b = md5_hh(b, c, d, a, x[i+10], 23, -1094730640);
a = md5_hh(a, b, c, d, x[i+13], 4 , 681279174);
d = md5_hh(d, a, b, c, x[i+ 0], 11, -358537222);
c = md5_hh(c, d, a, b, x[i+ 3], 16, -722521979);
b = md5_hh(b, c, d, a, x[i+ 6], 23, 76029189);
a = md5_hh(a, b, c, d, x[i+ 9], 4 , -640364487);
d = md5_hh(d, a, b, c, x[i+12], 11, -421815835);
c = md5_hh(c, d, a, b, x[i+15], 16, 530742520);
b = md5_hh(b, c, d, a, x[i+ 2], 23, -995338651);
a = md5_ii(a, b, c, d, x[i+ 0], 6 , -198630844);
d = md5_ii(d, a, b, c, x[i+ 7], 10, 1126891415);
c = md5_ii(c, d, a, b, x[i+14], 15, -1416354905);
b = md5_ii(b, c, d, a, x[i+ 5], 21, -57434055);
a = md5_ii(a, b, c, d, x[i+12], 6 , 1700485571);
d = md5_ii(d, a, b, c, x[i+ 3], 10, -1894986606);
c = md5_ii(c, d, a, b, x[i+10], 15, -1051523);
b = md5_ii(b, c, d, a, x[i+ 1], 21, -2054922799);
a = md5_ii(a, b, c, d, x[i+ 8], 6 , 1873313359);
d = md5_ii(d, a, b, c, x[i+15], 10, -30611744);
c = md5_ii(c, d, a, b, x[i+ 6], 15, -1560198380);
b = md5_ii(b, c, d, a, x[i+13], 21, 1309151649);
a = md5_ii(a, b, c, d, x[i+ 4], 6 , -145523070);
d = md5_ii(d, a, b, c, x[i+11], 10, -1120210379);
c = md5_ii(c, d, a, b, x[i+ 2], 15, 718787259);
b = md5_ii(b, c, d, a, x[i+ 9], 21, -343485551);
// a = safe_add(a, olda);
// b = safe_add(b, oldb);
// c = safe_add(c, oldc);
// d = safe_add(d, oldd);
a = a + olda;
b = b + oldb;
c = c + oldc;
d = d + oldd;
}
return ivec4(a,b, c, d);
}注:
我一开始是先将 md5.js 的代码转成 Java 版本测试,发现这个算法比 Java 自带的 MD5 方法慢很多,耗时是 Java 自带方法的2倍多。
Java 自带的 MD5 方法
// 获取MD5 MessageDigest实例
MessageDigest md = MessageDigest.getInstance("MD5");
// 对字符串进行哈希计算
byte[] digest = md.digest(str.getBytes());后来发现问题关键在于 safe_add 这个方法,其实就是整数相加,但是在 JS 中直接 int32 相加有可能出错,所以才使用 safe_add 方法相加,JS原码注释如下:
/*
* Add integers, wrapping at 2^32. This uses 16-bit operations internally
* to work around bugs in some JS interpreters.
*/
function safe_add(x, y)
{
var lsw = (x & 0xFFFF) + (y & 0xFFFF);
var msw = (x >> 16) + (y >> 16) + (lsw >> 16);
return (msw << 16) | (lsw & 0xFFFF);
}然后,我将 Java 版本的 JsMD5 中整数相加的地方 safe_add(a, b) 直接改成 a + b,执行结果也正确,执行效率比 Java 自带 MD5 方法还略高,整体效率是 safe_add 版本的3倍。
这个相加问题,同样适用于 GLSL,在 Android 使用计算着色器计算时,直接用 a + b 的版本就能算出正确的值,但是在浏览器中 WebGL 的版本,直接 a + b 的版本计算就会出错,需要 safe_add 的版本。
计算着色器返回 MD5 计算结果
此部分是利用计算着色器计算所有2字节的原数据所得的MD5,即 256*256 次 MD5 计算。
256是包含所有可能的字节,包括 ASCII 的控制字符或是2字节才能表示的中文的字节码。如果只考量 ASCII 的可显示字符(密码会用到的字符),那可以只遍历 0x20-0x7E 的96个字符。
OpenGL计算时,输入可当成 256*256 的图片纹理,其中 r、g 颜色就是遍历 -128~127 的值。
在 md5 的核心计算函数 core_md5() 最终的返回值是 int32[4],我们常见的32位字符串,实际就是16字节数据转成的16进制字符串。这16字节就是 int32[4] 小端模式的字节码。我们只要返回 core_md5 得到的这4个int值,相当于得到了MD5的计算结果。
版本1
计算着色器可以支持返回 rgba32f 的纹理,即每个像素输出 4*4 字节的数据,刚好就可以输出这4个int32。具体可参考上一篇的第七部分。
着色器代码
#version 310 es
layout (local_size_x = 8, local_size_y = 8, local_size_z = 1) in;
// 纹理输入
uniform layout (rgba8, binding = 0) readonly highp image2D u_inputImage;
// 纹理输出
uniform layout (rgba32f, binding = 1) writeonly highp image2D u_outputImage;
int u_arrLen = 2;
// md5 计算代码 ...
void main(){
ivec2 texelCoord = ivec2(gl_GlobalInvocationID.xy);
vec4 inputPixel = imageLoad(u_inputImage, texelCoord);
// 将纹理颜色值 rgba 取出
// inputPixel.r 得到的值会是 float 0.0 ~ 1.0 间的值,原本是 255,得到的是 1.0,所以下方 * 255 是把原本byte复原回来
int ir = int(inputPixel.r * 255.0);
int ig = int(inputPixel.g * 255.0);
int ib = int(inputPixel.b * 255.0);
int ia = int(inputPixel.a * 255.0);
int src[4] = int[](ir, ig, ib, ia);
ivec4 res = core_md5(src);
float o0 = intBitsToFloat(res[0]);
float o1 = intBitsToFloat(res[1]);
float o2 = intBitsToFloat(res[2]);
float o3 = intBitsToFloat(res[3]);
imageStore(u_outputImage, texelCoord, vec4(o0, o1, o2, o3));
}纹理绑定
// 绑定输入纹理
GLES31.glBindTexture(GLES31.GL_TEXTURE_2D, fTexture[0]);
GLES31.glTexStorage2D(GLES31.GL_TEXTURE_2D, 1, GLES31.GL_RGBA8, srcWidth, srcHeight);
GLES31.glBindImageTexture(0, fTexture[0], 0, false, 0, GLES31.GL_READ_ONLY, GLES31.GL_RGBA8);
ByteBuffer buffer = ByteBuffer.wrap(srcData);
GLES31.glTexSubImage2D(GLES31.GL_TEXTURE_2D, 0, 0, 0, srcWidth, srcHeight, GLES31.GL_RGBA, GLES31.GL_UNSIGNED_BYTE, buffer);
// 绑定输出纹理
GLES31.glBindTexture(GLES31.GL_TEXTURE_2D, fTexture[1]);
GLES31.glTexStorage2D(GLES31.GL_TEXTURE_2D, 1, GLES31.GL_RGBA32F, srcWidth, srcHeight);
GLES31.glBindImageTexture(1, fTexture[1], 0, false, 0, GLES31.GL_WRITE_ONLY, GLES31.GL_RGBA32F);
// 绑定缓冲区
GLES31.glBindFramebuffer(GLES31.GL_FRAMEBUFFER, fFrame[0]);
GLES31.glFramebufferTexture2D(GLES31.GL_FRAMEBUFFER, GLES31.GL_COLOR_ATTACHMENT0, GLES31.GL_TEXTURE_2D, fTexture[1], 0);读出计算数据
IntBuffer buf = IntBuffer.wrap(data.dest);
GLES31.glReadBuffer(GLES31.GL_COLOR_ATTACHMENT0);
GLES20.glReadPixels(0, 0, data.width, data.height, GLES20.GL_RGBA, GLES20.GL_FLOAT, buf);其中,srcData 是 byte[256*256*4],对应 256*256 个像素的rgba,其中 r、g 就是遍历 -128~127 的值。
data.dest 是 int[256*256*4],用以读出 256*256 个 MD5 计算结果(每组是4个int)
关于其他计算着色器的代码就详述了,都是通用的,可以参考上一篇
最后,读出的 MD5 再与 Java 计算的结果对比,完全一致,并且效率也显著高于Java计算MD5的效率,这个 OpenGL 计算 MD5 的功能算是走通了。
效率对比,上述计算 256*256个MD5执行256次
Android 14 模拟器
OpenGL:750 ms
Java:12408 ms
模拟器跑通后,再用真机测试,发现计算有部分的计算结果不对(与Java计算的不一致)
后来验证后发现有部分的int32值在转成float32输出后(即 intBitsToFloat 方法),数据会出现误差,所以下方调整了输出计算结果的方式。
版本2
在上一篇的第八部分,有介绍计算着色器的多重纹理的输入输出,所以有个方法就是把 MD5 计算的4个int值分成4个rgba8纹理输出
着色器代码
// 纹理定义部分
uniform layout (rgba8, binding = 0) readonly highp image2D u_inputImage;
uniform layout (rgba8, binding = 1) writeonly highp image2D u_outputImage0;
uniform layout (rgba8, binding = 2) writeonly highp image2D u_outputImage1;
uniform layout (rgba8, binding = 3) writeonly highp image2D u_outputImage2;
uniform layout (rgba8, binding = 4) writeonly highp image2D u_outputImage3;
// ...
// int32转成rgba
vec4 intToVec4(int oi) {
float r = float((oi) & 0xFF) / 255.0;
float g = float((oi >> 8) & 0xFF) / 255.0;
float b = float((oi >> 16) & 0xFF) / 255.0;
float a = float((oi >> 24) & 0xFF) / 255.0;
return vec4(r, g, b, a);
}
// ...
// 保存计算结果到输出纹理
ivec4 res = core_md5(src);
imageStore(u_outputImage0, texelCoord, intToVec4(res[0]));
imageStore(u_outputImage1, texelCoord, intToVec4(res[1]));
imageStore(u_outputImage2, texelCoord, intToVec4(res[2]));
imageStore(u_outputImage3, texelCoord, intToVec4(res[3]));纹理绑定
// 绑定输出纹理
GLES31.glBindTexture(GLES31.GL_TEXTURE_2D, fTexture[1]);
GLES31.glTexStorage2D(GLES31.GL_TEXTURE_2D, 1, GLES31.GL_RGBA8, srcWidth, srcHeight);
GLES31.glBindImageTexture(1, fTexture[1], 0, false, 0, GLES31.GL_WRITE_ONLY, GLES31.GL_RGBA8);
GLES31.glBindTexture(GLES31.GL_TEXTURE_2D, fTexture[2]);
GLES31.glTexStorage2D(GLES31.GL_TEXTURE_2D, 1, GLES31.GL_RGBA8, srcWidth, srcHeight);
GLES31.glBindImageTexture(2, fTexture[2], 0, false, 0, GLES31.GL_WRITE_ONLY, GLES31.GL_RGBA8);
GLES31.glBindTexture(GLES31.GL_TEXTURE_2D, fTexture[3]);
GLES31.glTexStorage2D(GLES31.GL_TEXTURE_2D, 1, GLES31.GL_RGBA8, srcWidth, srcHeight);
GLES31.glBindImageTexture(3, fTexture[3], 0, false, 0, GLES31.GL_WRITE_ONLY, GLES31.GL_RGBA8);
GLES31.glBindTexture(GLES31.GL_TEXTURE_2D, fTexture[4]);
GLES31.glTexStorage2D(GLES31.GL_TEXTURE_2D, 1, GLES31.GL_RGBA8, srcWidth, srcHeight);
GLES31.glBindImageTexture(4, fTexture[4], 0, false, 0, GLES31.GL_WRITE_ONLY, GLES31.GL_RGBA8);
// 绑定缓冲区
GLES31.glBindFramebuffer(GLES31.GL_FRAMEBUFFER, fFrame[0]);
GLES31.glFramebufferTexture2D(GLES31.GL_FRAMEBUFFER, GLES31.GL_COLOR_ATTACHMENT0, GLES31.GL_TEXTURE_2D, fTexture[1], 0);
GLES31.glFramebufferTexture2D(GLES31.GL_FRAMEBUFFER, GLES31.GL_COLOR_ATTACHMENT1, GLES31.GL_TEXTURE_2D, fTexture[2], 0);
GLES31.glFramebufferTexture2D(GLES31.GL_FRAMEBUFFER, GLES31.GL_COLOR_ATTACHMENT2, GLES31.GL_TEXTURE_2D, fTexture[3], 0);
GLES31.glFramebufferTexture2D(GLES31.GL_FRAMEBUFFER, GLES31.GL_COLOR_ATTACHMENT3, GLES31.GL_TEXTURE_2D, fTexture[4], 0);读出计算数据
// 读取的方法
private void read(MD5CalculateData2 data, int i) {
IntBuffer buf = IntBuffer.wrap(data.dests[i]);
GLES31.glReadBuffer(GLES31.GL_COLOR_ATTACHMENT0 + i);
GLES20.glReadPixels(0, 0, data.width, data.height, GLES20.GL_RGBA, GLES20.GL_UNSIGNED_BYTE, buf);
}
// 执行读取
read(data, 0);
read(data, 1);
read(data, 2);
read(data, 3);其中,data.dests 是 int[4][256*256] 的二维数组
经过这么一改,真机也能读出正确的计算结果了
不过此方法会比"版本1"略慢,之前的测试条件 Android 14 模拟器耗时 950 ms。
版本3
后来研究了一下,计算着色器除了纹理外,还有一种方法可以读取计算结果,就是使用Buffer
https://cloud.tencent.com/developer/article/2391063
着色器代码
// 定义buffer
layout (binding = 1) buffer OutputData {
highp int data[];
} outputData;
// ...
// 保存计算结果到buffer
ivec4 res = core_md5(src);
int x = int(gl_GlobalInvocationID.x);
int y = int(gl_GlobalInvocationID.y);
int index = (x + y * 256) * 4;
outputData.data[index] = res[0];
outputData.data[index + 1] = res[1];
outputData.data[index + 2] = res[2];
outputData.data[index + 3] = res[3];绑定buffer数据
// 绑定buffer数据
IntBuffer intBuffer = IntBuffer.allocate(srcWidth * srcHeight * 4);
GLES31.glBindBufferBase(GLES31.GL_SHADER_STORAGE_BUFFER, 1, fBuffer[0]);
GLES31.glBufferData(
GLES31.GL_SHADER_STORAGE_BUFFER,
intBuffer.capacity() * 4,
intBuffer,
GLES31.GL_STREAM_READ
);读出buffer数据,获取计算结果
Buffer buffer = GLES31.glMapBufferRange(GLES31.GL_SHADER_STORAGE_BUFFER, 0, dest.length * 4, GLES31.GL_MAP_READ_BIT);
ByteBuffer buf = (ByteBuffer) buffer;
buf.order(ByteOrder.LITTLE_ENDIAN);
buf.position(0);
buf.get(data.destBs);其中,data.destBs 是 byte[256 * 256 * 4 * 4],每组 MD5 计算结果是 byte[16]。
此方式也能正确取得计算后的MD5,但效率比"版本2"还低,同样测试条件 1650 ms。
不过此种方式的数值输入、输出方式较自由,不受限于纹理类型要求的参数,可让数据处理有更大的想象空间。
版本4 (2025-10-22补充)
上面的版本在处理纹理数据时,都是使用"规范化"的 float 格式,所以读纹理数据时,有 int(inputPixel.r * 255.0) 将输入纹理转int的操作。
在"版本1"中要输出计算结果时,为了将int计算结果转成 float 输出,用到了 intBitsToFloat() 函数,但也出现了部分整形转换后结果错误的情况。
下面这篇文字介绍了 OpenGL ES 3.0 中其实是支持整数纹理的
https://blog.youkuaiyun.com/u011760195/article/details/102704392
但是,网上介绍怎么使用"整数纹理"的文章很少(我没找到),大多数例子都是用浮点数纹理。
经过我一番研究,总算试成功了,下面就是我测试可行的方法
着色器代码
#version 310 es
layout (local_size_x = 8, local_size_y = 8, local_size_z = 1) in;
// 纹理输入
uniform layout (/*rgba8*/ rgba8i, binding = 0) readonly highp /*image2D*/ iimage2D u_inputImage;
// 纹理输出
uniform layout (/*rgba32f*/ rgba32i, binding = 1) writeonly highp /*image2D*/ iimage2D u_outputImage;
int u_arrLen = 2;
// md5 计算代码 ...
void main(){
ivec2 texelCoord = ivec2(gl_GlobalInvocationID.xy);
// vec4 inputPixel = imageLoad(u_inputImage, texelCoord);
ivec4 inputPixel = imageLoad(u_inputImage, texelCoord);
int ir = inputPixel.r;
int ig = inputPixel.g;
int ib = inputPixel.b;
int ia = inputPixel.a;
int src[4] = int[](ir, ig, ib, ia);
ivec4 res = core_md5(src);
imageStore(u_outputImage, texelCoord, res);
}与版本1差异点
1. 纹理格式 rgba8 -> rgba8i,rgba32f -> rgba32i,image2D -> iimage2D
2. 纹理读取改用 ivec4 接收
3. 不需从规范化float转int,输入纹理值直接使用,输出也直接保存 ivec4,不需转 vec4 浮点数向量保存
纹理绑定
// 绑定输入纹理
GLES31.glBindTexture(GLES31.GL_TEXTURE_2D, fTexture[0]);
GLES31.glTexStorage2D(GLES31.GL_TEXTURE_2D, 1, /*GLES31.GL_RGBA8*/ GLES31.GL_RGBA8I, srcWidth, srcHeight);
GLES31.glBindImageTexture(0, fTexture[0], 0, false, 0, GLES31.GL_READ_ONLY, /*GLES31.GL_RGBA8*/ GLES31.GL_RGBA8I);
ByteBuffer buffer = ByteBuffer.wrap(srcData);
GLES31.glTexSubImage2D(GLES31.GL_TEXTURE_2D, 0, 0, 0, srcWidth, srcHeight, /*GLES31.GL_RGBA*/ GLES31.GL_RGBA_INTEGER, /*GLES31.GL_UNSIGNED_BYTE*/ GLES31.GL_BYTE, buffer);
// 绑定输出纹理
GLES31.glBindTexture(GLES31.GL_TEXTURE_2D, fTexture[1]);
GLES31.glTexStorage2D(GLES31.GL_TEXTURE_2D, 1, /*GLES31.GL_RGBA32F*/ GLES31.GL_RGBA32I, srcWidth, srcHeight);
GLES31.glBindImageTexture(1, fTexture[1], 0, false, 0, GLES31.GL_WRITE_ONLY, /*GLES31.GL_RGBA32F*/ GLES31.GL_RGBA32I);
// 绑定缓冲区
GLES31.glBindFramebuffer(GLES31.GL_FRAMEBUFFER, fFrame[0]);
GLES31.glFramebufferTexture2D(GLES31.GL_FRAMEBUFFER, GLES31.GL_COLOR_ATTACHMENT0, GLES31.GL_TEXTURE_2D, fTexture[1], 0);读出计算数据
IntBuffer buf = IntBuffer.wrap(data.dest);
GLES31.glReadBuffer(GLES31.GL_COLOR_ATTACHMENT0);
GLES20.glReadPixels(0, 0, data.width, data.height, /*GLES20.GL_RGBA*/ GLES31.GL_RGBA_INTEGER, /*GLES20.GL_FLOAT*/ GLES20.GL_INT, buf);与版本1差异点,看上方注释值修改的地方
经过这么调整,在真机也能读出正确的计算结果了,并且性能跟版本1是一样的(理论上少了格式转换,性能应该更高)
查找MD5
网上的 MD5 破解网站,是先穷举明文的 MD5 记录到数据库。
前面介绍的 OpenGL 计算MD5并返回的方法,可以加速这个穷举过程。
然而,我只是为了学习,不是为了建这个 MD5 数据库,要实现查找 MD5,可以利用 OpenGL 实时穷举。
实际使用上,穷举查找所有3字节原始数据生成的 MD5,在体验上还是可行的。
Android的计算着色器的方法我就不详述了,下面我以网页利用 WebGL 查找 MD5来举例
3字节数据有 256*256*256 个可能,要在二维平面展开这些数据,需要 4096*4096,这样将占用不少内存
我的做法是以 1024*1024 的平面纹理来渲染计算,3字节数据相当于 24 bits,1024*1024 可填充末 20 bits,然后每个像素循环16次(剩下的4 bits),就能计算3字节数据的所有 MD5 了。
片元着色器代码
#version 300 es
precision mediump float;
precision highp int;
in vec2 v_texCoord; //接收从顶点着色器过来的纹理顶点
uniform sampler2D u_sTexture; //纹理内容数据
uniform ivec4 u_target; // 将 md5 转成 int32[4] 的格式传入
uniform int u_arrLen;
out vec4 outColor; //输出显示颜色
// md5 计算代码,在js中使用,相加要用 safe_add 版本,不然计算会出错
void main(){
vec4 inputPixel = texture(u_sTexture, v_texCoord); //取出纹理颜色
// 将纹理颜色值 rgba 取出
// inputPixel.r 得到的值会是 float 0.0 ~ 1.0 间的值,原本是 255,得到的是 1.0,所以下方 * 255 是把原本byte复原回来
int ir = int(inputPixel.r * 255.0);
int ig = int(inputPixel.g * 255.0);
int ib = int(inputPixel.b * 255.0);
int ia = int(inputPixel.a * 255.0);
int or = 0;
int og = 0;
int ob = 0;
int oa = 0;
for(int i = 0 ; i < 16 ; i++) {
int ib2 = ib | (i << 4);
int src[4] = int[](ir, ig, ib2, 0);
ivec4 res = core_md5(src);
if(res[0] == u_target[0] && res[1] == u_target[1] && res[2] == u_target[2] && res[3] == u_target[3]) {
or = ir;
og = ig;
ob = ib2;
break;
}
}
float o0 = float(or) / 255.0;
float o1 = float(og) / 255.0;
float o2 = float(ob) / 255.0;
float o3 = float(oa) / 255.0;
// 如果有找到,原文 3 bytes 会赋值返回
outColor = vec4(o0, o1, o2, o3);
}JS中传入1024*1024的纹理数据
let ii = 0;
const src = Array(1024 * 1024);
for (let i = 0 ; i < 1024 ; i++) {
for (let j = 0 ; j < 1024 ; j++) {
src[ii] = i * 1024 + j;
ii++;
}
}
const dataBuffer = new Uint8Array(new Int32Array(src).buffer);
gl.texImage2D(gl.TEXTURE_2D, 0, gl.RGBA, 1024, 1024, 0, gl.RGBA, gl.UNSIGNED_BYTE, dataBuffer);渲染后js读出查找结果
function readFindRes(gl: WebGLRenderingContext) {
let outArrI32 = new Int32Array(1024 * 1024);
let outArrUi8 = new Uint8Array(outArrI32.buffer)
gl.readPixels(0, 0, 1024, 1024, gl.RGBA, gl.UNSIGNED_BYTE, outArrUi8);
const len = outArrUi8.byteLength;
for(let i = 0 ; i < len ; i += 4) {
const b0 = outArrUi8[i];
if(b0 !== 0) {
return [b0, outArrUi8[i + 1], outArrUi8[i + 2]];
}
}
return null;
}如此,实时遍历 MD5 反查原文的功能就完成了,下面是我的查找页面
https://shouhengboy.github.io/MyWebPages/web/findMd5.html
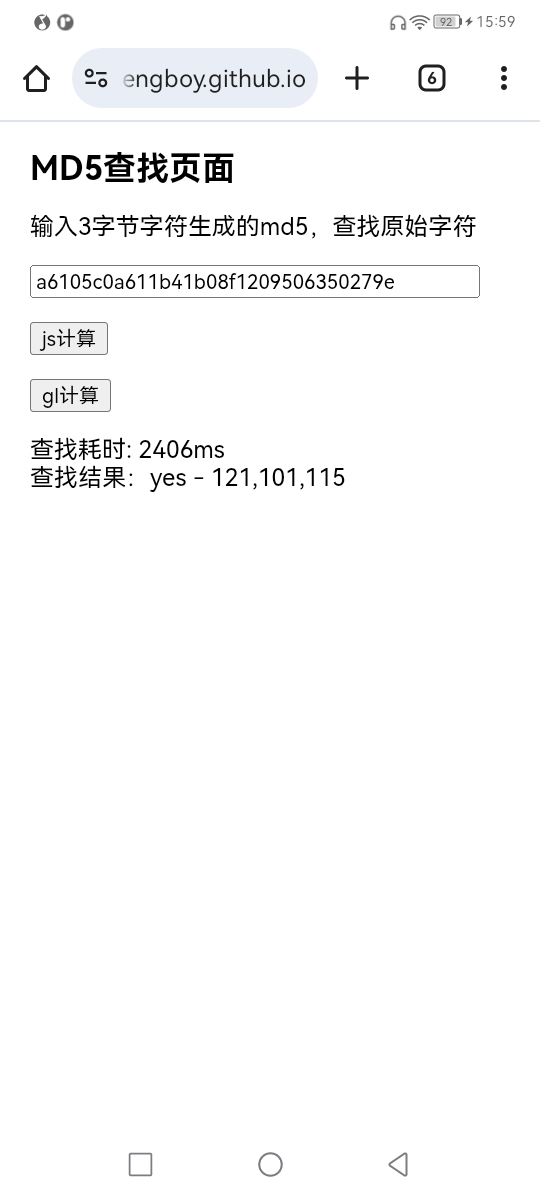
实测查找效率
Windows PC i5+集成显卡
WebGL:285 ms
Javascript:4419 ms
荣耀V20
WebGL:600 ms
Javascript:24938 ms
红米 Note 11T Pro
WebGL:250 ms
Javascript:20469 ms
硕王 MX670pro
WebGL:2381 ms
Javascript:13811 ms
iPhoneX
WebGL:290 ms
Javascript:9815 ms
Mac mini
WebGL:45 ms
Javascript:5780 ms
不同设备表现差异还是蛮大的,不同浏览器效果也不同,不过使用 WebGL 的效率都明显高于 JS 计算。
上面是网页中 Javascript WebGL 的版本,安卓中用计算着色器查找效率还会高于 WebGL(没有 safe_add 的损耗),例如:硕王 740 ms,荣耀V20 250ms。

















 506
506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









