




 本文主要介绍了C++中进程的四个内存区域,包括代码区与常量区、栈区、堆区和静态变量区。详细说明了各区域的特点和用途,如栈区为函数执行提供空间,函数执行完栈内存销毁;堆区用于灵活分配内存,手动释放才销毁。还通过代码演示说明,强调栈区和堆区对程序运行缺一不可。
本文主要介绍了C++中进程的四个内存区域,包括代码区与常量区、栈区、堆区和静态变量区。详细说明了各区域的特点和用途,如栈区为函数执行提供空间,函数执行完栈内存销毁;堆区用于灵活分配内存,手动释放才销毁。还通过代码演示说明,强调栈区和堆区对程序运行缺一不可。
程序被执行后就被称为一个进程,一个进程可以被划分为很多区域,我们只需要理解以下的四个区:
-
代码区与常量区:进程按照代码区的代码执行,真正的常量也存储在这里,比如"abc"字符串,“1”,"88"等数字。这些是真正的常量。再看一下const关键字。const只不过是让编译器将变量视为常量罢了,和真正的常量有本质上的区别。
-
栈区:函数的执行所需的空间,注意,当函数执行完毕,函数对应的栈内存全部销毁。
-
堆区:进程用来灵活分配内存的地方,只有手动释放时才会销毁内存。
-
静态变量区:用来存储静态变量与全局变量的区域
-
静态变量:我们常常需要一些局部作用范围,生命周期却很长的变量。
-
全局变量:重要性就不必说了,在c语言程序中经常用到,但在C++中不推荐使用,因为会破坏封装性。
具体的存储方式如图所示:
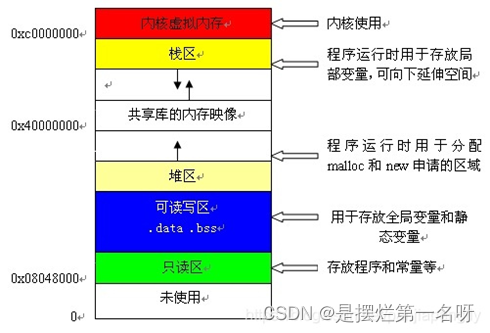
接下来用代码演示一下这几个区域。
堆区和栈区,是程序运行的主要地方。我们用一个最简单的程序来显示栈的用途。
代码演示:
#include<iostream> #include<vector> std::vector<int> iVec; void test(){ /*这是一个服务端程序,用来接受客户端发送的数据*/ int i = rand(); iVec.push_back(i); } int main(){ test(); return 0; }**上述程序说明:当一个程序执行到main函数处,就会给main函数创建一个栈,执行到test函数处,又会给test函数创建一个栈,然后先执行test函数,然后在test函数的栈中执行test函数中的内容,test函数执行完毕,test函数的栈就会被销毁,然后继续执行,执行完毕,main函数的栈就会被销毁,整个程序执行结束。给函数执行提供空间的。 **
至于堆区,主要意义在于灵活的生命周期,同样是刚才那个例子。
如果需要创建的对象有几十M,每次调用函数都需要创建一个这么大的对象,再复制到对应的容器中,那就太过耗费内存了。而且栈内存非常的小,通常不超过8M。
而使用堆内存,每调用一次函数就可以在堆内存中创建一个对象,容器中只要存储指针就可以了,极大的提高了程序效率。
代码演示:
#include<iostream> #include<vector> std::vector<int> iVec; void test(){ /*这是一个服务端程序,用来接受客户端发送的数据*/ int* pi = new int(rand()); iVec.push_back(pi); } int main(){ test(); return 0; }
-
而静态变量区:
有很多情况下,我们需要作用范围局限在函数之内,但生命周期却很长的变量,比如统计一个函数被调用的次数。
#include<iostream>
#include<vector>
std::vector<int> iVec;
void test(){
/*这是一个服务端程序,用来接受客户端发送的数据*/
int* pi = new int(rand());
iVec.push_back(pi);
//统计函数被调用的次数的静态变量
static unsigned funcCallCount = 0;
++funcCallCount;
return funcCallCount;
}
int main(){
test();
test();
test();
unsigned testFuncCallCount = test();
std::cout << testFuncCallCount << std::endl;
return 0;
}
总结:栈区是函数执行的区域,堆区是函数内灵活分配内存的地方,二者缺一不可。
为什么不能只在栈上运行程序?
因为当函数运行结束时,栈是要销毁的,其上分配的内存全部失效。
也不能只在堆上运行程序,因为堆的唯一寻址方式就是指针,如果没有栈,根本无法使用堆。
注意:栈区远远小于堆区,一般不超过8M,所以主要的内容都在对堆区上。堆区很大,虚拟内存剩下的都是堆区。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









