







 该文提出了一种名为GANCompression的方法,针对条件生成对抗网络(cGAN)进行压缩,以降低推理时间和计算成本。通过知识蒸馏和神经结构搜索(NAS),解决了GAN训练的不稳定性及生成器的独特性问题。实验显示,该方法能有效减少CycleGAN和GauGAN等模型的计算量,同时保持图像质量,适用于多种监督设置和模型架构,推动了交互式图像合成在移动设备上的应用。
该文提出了一种名为GANCompression的方法,针对条件生成对抗网络(cGAN)进行压缩,以降低推理时间和计算成本。通过知识蒸馏和神经结构搜索(NAS),解决了GAN训练的不稳定性及生成器的独特性问题。实验显示,该方法能有效减少CycleGAN和GauGAN等模型的计算量,同时保持图像质量,适用于多种监督设置和模型架构,推动了交互式图像合成在移动设备上的应用。
实用的对抗神经网络压缩方法
参考论文:GAN Compression: Efficient Architectures for Interactive Conditional GANs
参考代码:https://github.com/mit-han-lab/gan-compression
注:本文的图片均来自以上论文
摘要
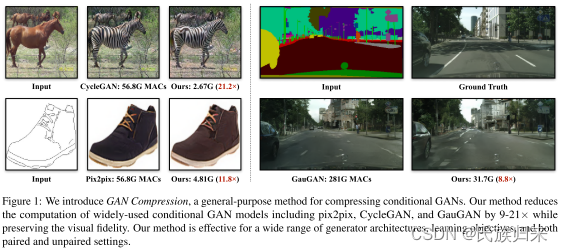
条件生成对抗神经网络(cGAN)能够为许多计算机视觉和图像应用生成可控的图片。然而,近期cGAN的计算量通常比用于识别的CNN高出1~2个数量级。比如说,GauGAN对于每张图片需要消耗218G MACs,而MobileNet-v3只要消耗0.44G MACs,使得其难以部署到交互式的应用上去。在这项工作当中,我们提出了一个通用的压缩框架,以减小cGAN中生成器的推理时间和模型大小。由于 GAN 训练的难度和生成器架构的差异,直接应用现有的 CNN 压缩方法会产生较差的性能。 我们以两种方式应对这些挑战。首先,为了稳定GAN训练,我们将原始模型的多个中间表示的知识转移到其压缩模型中,并统一了非配对和配对学习。其次,我们的方法不是重用现有的CNN设计,而是通过神经结构搜索(NAS)自动找到有效的结构。为了加速搜索过程,我们通过权重共享将模型训练和架构搜索解耦。 实验证明了我们的方法在不同监督设置(配对和非配对)、模型架构和学习方法(例如,pix2pix、GauGAN、CycleGAN)中的有效性。 在不损失图像质量的情况下,我们将 CycleGAN 的计算量减少了 20 倍以上,将 GauGAN 的计算量减少了 9 倍,为交互式图像合成铺平了道路。 代码和演示是公开的。
注1:MACs(Multiply–Accumulate Operations):乘加累积操作数,包含一个乘法操作与一个加法操作,FLOPs(Floating Point Operations Per Second):每秒浮点运算次数,是一个衡量硬件速度的指标。通常MACs与FLOPs存在一个2倍的关系。
注2:配对与非配对学习:其实很好理解,就是训练用的图片是否成对出现,比如Figure1中的鞋子的线条与鞋子的实物照片就是一组配对的图片,如果不配对,就是我只有鞋子的线条的图片
引言
生成对抗神经网络(GAN)擅长生成逼真的图像。它们的条件扩展,条件生成对抗神经网络(cGAN),允许可控的图像生成,并支持许多计算机视觉和图形应用,比如从用户的绘图交互式的创建图像,将跳舞视频中的动作转移到另外一个人身上,或者为远程社交互动创建VR面部画面。所有的这些模型都需要模型与人类的交互,因此需要在设备上具有低延迟的性能,以保证用户能够获得更好的体验。然而,边缘设备(手机、平板电脑、VR头戴设备)收到内存和电池等硬件资源的严格限制。这些计算上的瓶颈阻碍了条件GAN在边缘设备上的部署与应用。
不同于图像识别的CNN,cGAN的计算量十众所周知的。例如,广泛实用的CycleGAN模型的计算量超过50G MACs,是MobileNet的100倍之多。最近的一款叫GauGAN的模型,虽然能够生成必争的高分辨率图像,但需要超过250G MACs,比MobileNet高出500倍。
在这篇工作中,我们提出了GAN压缩,这是一种通用的压缩方法,用于减少cGAN的推理时间和计算成本。我们观察发现压缩生成模型面临两个基本的困难:GAN的训练非常不稳定,尤其是在非成对的数据集上;GAN中的生辰器也不同于CNN,因此很难重用现有的CNN设计。为了解决这个问题,我们首先将知识从原始的教师生成器的中间表示转移到其压缩学生生成器所对应的层。我们还发现,通过教师网络的输出创建伪造的配对对于非配对训练是有益的。这将非配对的学习转换到了配对的学习。其次我们利用升神经网络架构搜索(NAS)来自动找到一个计算成本和参数显著减少的高效网络。为了降低训练成本,我们通过训练一个包含所有通道数组合配置的once-for-all网络,来将模型的训练与架构搜索进行解耦。这个once-for-all网络可以通过权重共享的方式生成多个子网络,使得我们能够在不进行再训练的情况下就可以直接评估每个子网络的性能。我们的方法可以应用到各种的cGAN当中去,而不用考虑模型的结构、学习算法、和监督设置(成对与不成对)。
通过大量实验,我们表明,我们的方法可以将三种广泛使用的cGAN模型(包括pix2pix、CycleGAN和GauGAN)的计算量减少9倍到21倍,而不会损失生成图像的视觉保真度(多个示例见Figure1)。最后,我们在移动设备(Jetson Nano)上部署了我们的压缩pix2pix模型,并演示了一个交互式edges2shoes应用程序。


















 413
413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









