







参考论文:Improved Knowledge Distillation via Teacher Assistant.
!声明!文章的图片均来自以上论文
知识蒸馏简单介绍
在介绍论文前,先向大家介绍一下什么是知识蒸馏。知识蒸馏:一种神经网络的压缩方法。知识蒸馏背后的想法是不仅通过真实标签提供的信息,而且通过观察教师网络(T)如何表示和处理数据来培训学生网络(S)。
教师网络(T)就是压缩前的神经网络,学生网络(S)就是压缩后的网络。主流的方式就是让规模与复杂度更小的学生网络(S)通过观察教师网络(T)是如何处理数据的来进行学习。说白了就是把教师网络(T)的softmax前一层都作为标签(软标签)来训练学生网络(S)。
用一个简单的公式来分析一下:
- 令at为
教师网络(T)的softmax前一层的输入。 - 令as为
学生网络(S)的softmax前一层的输入。
然后我们应该都知道,softmax(as)的结果就会是学生网络(S)输出的各类别的概率。然后和真实标签yr做一对比。得到知识蒸馏的第一个损失:
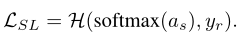
然后还要从老师网络那里进行学习。令ys= softmax(as/t),yt=softmax(at/t),则第二个损失如下(t就是知识蒸馏中常说的温度):
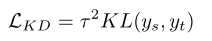
最后学生网络的训练过程就是不断缩小如下损失:
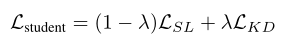
至于具体上面这几个公式中使用的是什么损失函数,感兴趣的可以去看看原文。
摘要
由于目前深度神经网络取得了巨大的成果,但是由于这些优秀的模型都过于庞大,使得他们很难部署在智能手机或者嵌入式传感器上。所以,如果要应用这些深度神经网络,必须要压缩网络。然后比较流行的方法就是知识蒸馏。但是本论文的作者发现,当教师网络和学生网络之间的差异过大时,会出现知识蒸馏效率下降的情况。为了解决这个问题,该论文引入了多步知识蒸馏,即采用中等规模的网络(教师助理TA)来弥合学生和老师之间的差距。大致流程如下图:
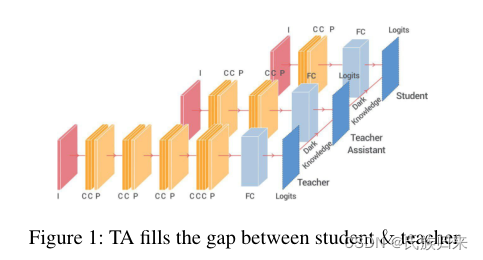
实验数据证明
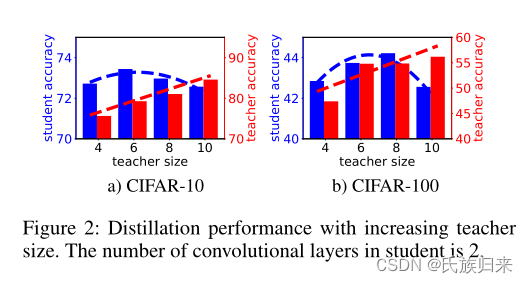
上图的蓝色代表学生,红色代表老师。学生的神经网络深度始终是2。从图中可以看出,随着老师网络准确率的提高(规模的增大),学生网络的的准确率并没有一直呈上升趋势,反而下降了。所以这篇论文就是为了解决这个问题。
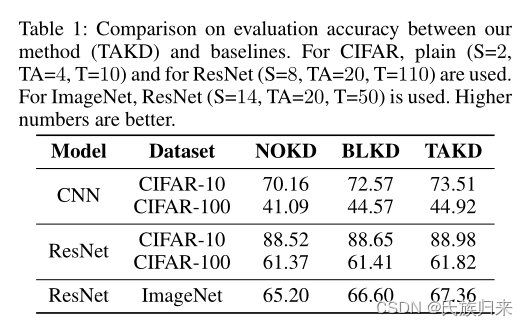
- NOKD: 让学生网络直接从数据进行训练。
- BLKD:普通的知识蒸馏方法。
- TAKD:本论文中的引入助教的知识蒸馏方法。
通过这个表,我们可以得知,该论文的方法就是好。准确率就是高。emmmm
多层助教?
直接看表:
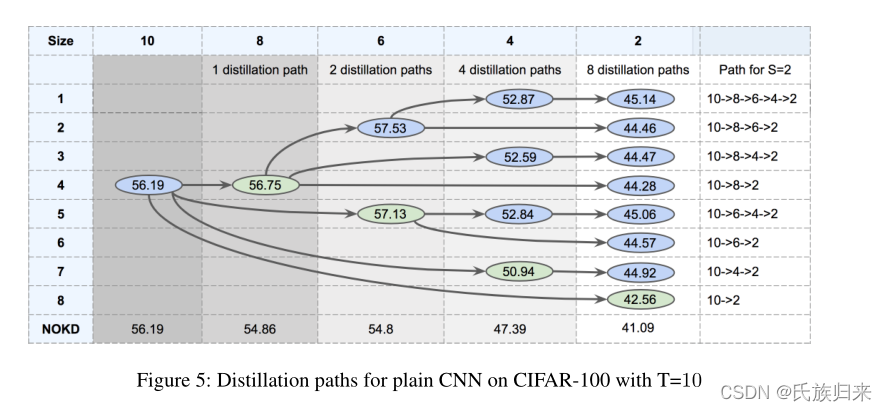
从表中可以看到一些东西,引入了助教的准确率(蓝色部分)比没有引入助教(绿色部分)的知识蒸馏准确率都要高。

















 1087
1087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









