






可以使用Pinyin2Hanzi库,不得不感叹,大佬真实厉害,各种意想不到的库都有。
话不多说,接下来是具体实现方式。
给定了一个拼音列表:
['běi jīng ',
'tiān jīn ',
'hé běi ',
'shān xī ',
'nèi méng gǔ ',
'liáo níng ',
'jí lín ',
'hēi lóng jiāng ',
'shàng hǎi ',
'jiāng sū ',
'zhè jiāng ',
'ān huī ',
'fú jiàn ',
'jiāng xī ',
'shān dōng ',
'hé nán ',
'hú běi ',
'hú nán ',
'guǎng dōng ',
'guǎng xī ',
'hǎi nán ',
'zhòng qìng ',
'sì chuān ',
'guì zhōu ',
'yún nán ',
'xī cáng ',
'shǎn xī ',
'gān sù ',
'qīng hǎi ',
'níng xià ',
'xīn jiāng ']
这里我第一遍看的时候,没仔细看还有拼音错误。这个列表是一个DataFrame的一部分。
将空格去除,并进行拆分:
from pypinyin import pinyin, Style
# 去掉拼音中的空格
converted_list = [pinyin.strip().split() for pinyin in list(df_city.iloc[:,0].values)]
#去除声调
def remove_tone(pinyin_str):
return ''.join([char for char in unicodedata.normalize("NFKD", pinyin_str).encode("ascii", "ignore").decode("ascii")])
no_tone_list = [[remove_tone(p) for p in item] for item in converted_list]
#拼音转为汉字
def pinyin_2_hanzi(pinyin_list):
dagParams_1 = DefaultDagParams()
res = dag(dag_params=dagParams_1,pinyin_list=pinyin_list,path_num=1,log=True)
for item in res:
res_0 = item.path
print(res_0)
pinyin_2_hanzi(no_tone_list[0])
可以得到第一个为“北京”。
全部遍历一遍:
for item in no_tone_list:
pinyin_2_hanzi(item)
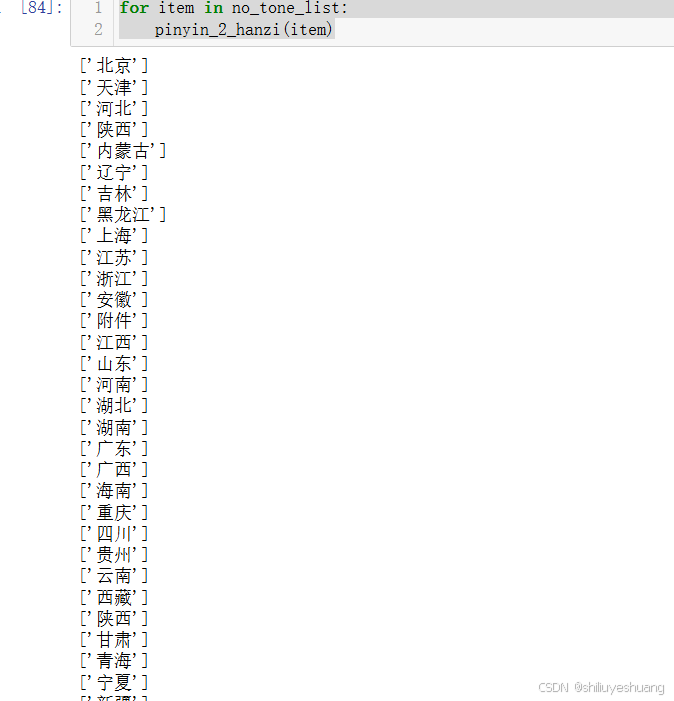
关于重庆和西藏的拼音已修正,操作步骤省略。
可以看出,成功率还是很高的,除了福建错了,其他都是正确的。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









