






python实现
这里使用的是selenium,调用谷歌浏览器从而获取网页信息。
import os
import time
#切换到谷歌浏览器的驱动位置
os.chdir(r'F:\py_drivers\119\chromedriver-win64')
from selenium import webdriver
#打开谷歌浏览器
options = webdriver.ChromeOptions()
options.binary_location = r"E:\Google\Chrome\Application\chrome.exe"
browser = webdriver.Chrome(options)
from selenium.webdriver.common.by import By
#天气信息的获取,加上一定的休眠时间来简单模拟正常的浏览
url = "https://www.weather.com.cn/weather/101020100.shtml"
browser.get(url)
browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
time.sleep(6)
browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
time.sleep(7)
html0 = browser.page_source
print(html0)
browser.close()
网页信息的解析
#使用bs4解析获取到的html页面
import bs4
soup = bs4.BeautifulSoup(html0,"html.parser")
#使用正则表达式查询到7天的天气情况
import re
list_res = soup.find_all(class_ = re.compile("sky skyid"))
list_res
提取天气信息
#创建一个有长度的空列表存放
soups = [None for _ in range(len(list_res))]
list_final = []
#遍历7天天气情况列表,将每一天的日期、天气、温度、风向、风级加入到最终的列表中
for i in range(len(list_res)):
it = []
soups[i] = bs4.BeautifulSoup(str(list_res[i]),"html.parser")
it.append(soups[i].find("h1").text)
it.append(soups[i].find("p",class_ = "wea").text)
it.append(soups[i].find("p",class_ = "tem").find("span").text+"/"+soups[i].find("p",class_ = "tem").find("i").text)
it.append([span["title"] for span in soups[i].find("p",class_ = "win").find_all("span")])
it.append(soups[i].find("p",class_ = "win").find("i").text)
list_final.append(it)
list_final
#最后转换成DataFrame
import pandas as pd
df = pd.DataFrame(list_final,columns=["日期","天气","温度","风向","风级"])
最后的结果如下所示:
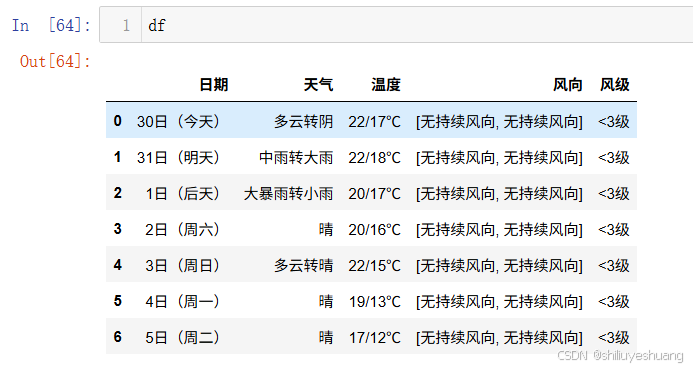 将其写入到excel表中
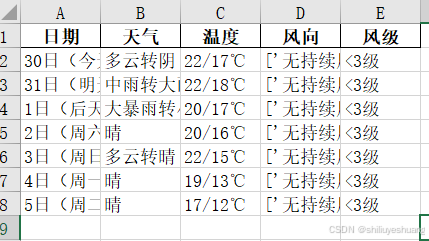
将其写入到excel表中
writer = pd.ExcelWriter("F:\spider_test_xlsx\weather_shanghai_week.xlsx",engine='xlsxwriter')
df.to_excel(writer,sheet_name="weather_shanghai",index=False)
writer.save()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









