






目录
1数组创建
x = np.array([1, 2, 3])
"""[1 2 3]"""使用np.array创建一个np数组
x = np.zeros((3,2))
"""
[[0. 0.]
[0. 0.]
[0. 0.]]
"""
x = np.ones((2,3))
"""
[[1. 1. 1.]
[1. 1. 1.]]
"""创建一个三行二列的全零数组和一个三行二列的全一数组
x = np.arange(4, 10)
"""[4 5 6 7 8 9]"""
x = np.arange(4, 10, 2) # 指定步长为2
"""[4 6 8]"""创建一个4到9的递增序列,如果添加前面那个数后面加小数的话,就是创建出来的数组都带一样的小数
x = np.linspace(1, 8, 5)
"""[1. 2.75 4.5 6.25 8. ]"""给定1-8的区间,按等间距生成五个数
np.random.random():生成 均匀分布(Uniform Distribution) 的随机数,范围是 [0.0, 1.0)。
np.random.randn():生成 标准正态分布(Standard Normal Distribution) 的随机数,均值为 0,标准差为 1。
2运算
首先是相同的维度的数组都可以进行四则运算。
然后如果维度不同的话。
a = np.random.randn(2, 3) # a.shape = (2, 3)
b = np.random.randn(2, 1) # b.shape = (2, 1)
c = a + b
print(a,b,c)b的维度小,会将b广播扩展成和a一样的大小,和a进行运算
c = a + b.T 如果b是1,2的话可以将b转置后再和a相加
a = np.random.randn(3, 3)
b = np.random.randn(3, 3)
c = b * a仅维度相同的两个数组可以做乘法,不一样报错,这个是两个数组对应位置相乘,不是正常那个矩阵乘法。维度相同是指行或者列相同,且不相同的那个维度能正好广播扩展几倍能和另一个数组相同,如下:
a = np.random.randn(3, 3)
b = np.random.randn(3, 1)
c = a * b 这个维度虽然不一样,但是np会帮你自动扩展b到a一样
c = np.dot(a, b) 这个是将两个数组进行点乘运算,可以计算一维向量内积
x = np.array([[1, 2],
[3, 4]])
y = np.array([[0, 1],
[2, 0]])
print(x @ y)
"""
[[4 1]
[8 3]]
"""@可以进行矩阵的乘法运算,二维的时候,@和dot计算结果是一样的
np.sqrt(x)
np.sin(x)
np.cos(x)
np.log(x)
np.power(x, 2) #2表示几次方
对所有数求平方根,sin,cos,对数,指数运算,都是对每个元素进行的
x.max()
x.min()
x.argmax()
x.argmin()求x数组中最大最小值,arg的会返回最值所在的最小的索引,从0开始排
x.sum()
x.mean()
np.average(x) # 可以计算加权平均
np.median(x)
x.var()
x.std()
x = np.array([1, 2, 3, 4])
weights = np.array([0.1, 0.2, 0.3, 0.4])
print(np.average(x, weights=weights)) # 输出: 3.0
sum是对x所有元素求和,mean是去平均值,median是算中位数,var是方差,std是标准差
np比较自由,有的比如x.var()和np.var(x)是一个结果,但有的不行,没有x.median这个用法
s = 1/(1+np.exp(-x))使用np.exp对数据每个元素都求指数,如上是sigmoid的式子
ds = s * (1-s)用对应位置相乘的方法,计算sigmoid的导数的结果
"""x=
1,2,3
4,5,6
"""
x_norm = np.linalg.norm(x, axis=1, keepdims=True)计算向量的 L2 范数(各元素平方和的平方根)
按axis=1就是行计算,
keepdims=True:保持输出维度与输入一致。例如,输入是二维数组,输出也是二维,有时py会把一个数组简化变为一维的
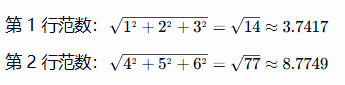 《-计算方式
《-计算方式
然后使用x = x/x_norm进行归一化处理
3细节语法
x = np.linspace(1, 8, 5, dtype=np.int32)数组默认数据类型为64位浮点数,使用dtype可以指定需要的类型,int32是整形
也可以使用x.dtype来看当前数组的格式
x = x.astype(int)对于已有的数组,可以这样来转换数据类型
x_sum = np.sum(x, axis=1, keepdims=True)按行求和
对于二维数组,axis=0时表示对每一列的数据进行运算,axis=1表示对每一行的数据进行运算
按行求和的结果是变成一个列向量,按列求和的结果是变成一个行向量
4其他操作
print(x.ndim, x.shape, x.size)
"""2 (2, 2) 4"""ndim表示维度数,shape表示数组形状,size表示数组的元素个数
x = np.array([[1, 2],
[3, 4]])
print(x[0, 1])
"""2"""通过下标索引元素
v = np.arange(9).reshape((3, 3))
print(v > 3)
"""
v:
[[0 1 2]
[3 4 5]
[6 7 8]]
结果:
[[False False False]
[False True True]
[ True True True]]
"""因为用数组直接和不等号可以得到每个元素的bool值,因此可以用下面的方法来筛选元素
print(x[x < 3])
"""[1 2]"""通过条件来筛选元素,可以组合逻辑运算符(&,|)与或非配合不等号
print(x[(x < 4) & (x > 2)])要注意给每个条件都要打上括号
切片
print(x[0, ], x[0])这个是取第一行,后面不写表示整行
print(x[0, 0:2])
"""[1 2]"""或者这样也可以取第一行内容,遵循左闭右开的方式进行
x[1][1]和列表索引类似,这样可以取到4
z = np.arange(1, 10)
print(z[0:10:2])
"""[1 3 5 7 9]"""带跨度,2表示跳走两步取一个,就是1,2,3其中一到2一步,2到3一步,就是走两步
print(z[::-2])
"""[9 7 5 3 1]"""步长负数表示倒着取,-1的话就是直接逆置数组
x = np.array([[1, 2],
[3, 4]])
print(x[::-1])
"""
[[3 4]
[1 2]]
"""对二维数组的反转,实际上是把每个小数组位置换了
v = np.arange(9).reshape((3, 3))
print(v)
"""
[[0 1 2]
[3 4 5]
[6 7 8]]"""将生成的数组,重新整形到一个指定形状维度,但你的元素数量要正好合适能填满生成的结果
x = np.array([[1, 2],
[3, 4]])
np.cumsum(x)
"""[ 1 3 6 10]"""
np.diff(x)
"""
[[1]
[1]]
"""累加的效果,不断累加出结果,还有求每个一维数组中,每两个数之间的差
y = np.array([[0, 1],
[2, 0]])
np.nonzero(y)
"""(array([0, 1], dtype=int64), array([1, 0], dtype=int64))"""求出所有非零的元素的索引坐标,第一个数组表示非零元素行下标,第二个表示非零元素列下标,比如y中1那个元素非零,那它的坐标是0行,1列对应结果第一个array的第一个元素0和第二个array的第一个元素1
np.sort(y)
"""
[[0 1]
[0 2]]"""对每一行进行排序,从小到大
z = np.array([[-1, 5, 6],
[5, 9, 13],
[10, 15, 40]])
np.clip(z, 0, 15)
"""
[[ 0 5 6]
[ 5 9 13]
[10 15 15]]"""关于z,对于小于0和大于15的数都分别变成0和15,0到15之间的数保持不变
u = np.array([[1, 2, 3]])
# 1
a = u
u[0][0] = 111
print(a)
"""[[111 2 3]]"""
# 2
a = u.copy()
u[0][1] = 111
print(a)
"""[[1 2 3]]"""赋值操作,直接赋值的话,会让a和u占用一个空间,使它们的修改保持一致
5遍历
for row in z:
print(row)
"""
[-1 5 6]
[ 5 9 13]
[10 15 40]
"""
for col in z.T:
print(col)
"""
[-1 5 10]
[ 5 9 15]
[ 6 13 40]
"""对于行列的遍历
for col in z.T:
for item in col:
print(item)
for item in z.T.flat:
print(item)
"""
-1
5
10
5
9
15
6
13
40
"""对于每个元素进行输出,可以这样,flat是进行展平
z.T.flat
"""<numpy.flatiter object at 0x000001CB7761F5D0>"""
z.T.flatten()
"""[-1 5 10 5 9 15 6 13 40]"""
np.array(z.T.flat)
"""[-1 5 10 5 9 15 6 13 40]"""flat是返回一个扁平迭代器对象(flatiter),flatten是变成一个一维数组,或者可以对flat再转换成array形式也一样的
6堆叠
x = np.array([[1, 2],
[3, 4]])
y = np.array([[0, 1],
[2, 0]])
np.vstack((x, y))
"""
[[1 2]
[3 4]
[0 1]
[2 0]]
"""垂直堆叠的操作,vertical
np.hstack((x, y))
"""
[[1 2 0 1]
[3 4 2 0]]"""水平堆叠的操作,horizontal
u = np.array([[1, 2, 3]])
v = np.array([[4, 5, 6]])
print(np.concatenate((u, v, u, v), axis=1))
"""[[1 2 3 4 5 6 1 2 3 4 5 6]]"""
print(np.concatenate((u, v, u, v), axis=0))
"""
[[1 2 3]
[4 5 6]
[1 2 3]
[4 5 6]]"""这个concat我看好像是更常用一些,具体还不太清楚原因,但感觉掌握这个应该也够用了
7分割
z = np.array([[-1, 5, 6],
[5, 9, 13],
[10, 15, 40]])
np.split(z, 3, axis=0)
"""[array([[-1, 5, 6]]), array([[ 5, 9, 13]]), array([[10, 15, 40]])]"""按列进行分割,分割成3列,一定是要能平均分开,不然会报错,分割后放到一个列表中
np.array_split(z, 2, axis=0)
"""[array([[-1, 5, 6],
[ 5, 9, 13]]), array([[10, 15, 40]])]"""
不等量分割,会把第一部分分的大一些
先写这些,要是再有好用的内容再加
以上内容参考网络各个课程


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









