







个人学习总结,图片相关感谢李宏毅老师,李哥的ppt,部分理解内容来自王木头老师的讲解。
1,深度学习和特征
深度学习可以这样理解,就是要把我们输入的内容通过网络能有效提取出来,转换为一个高维度的向量,要更好的提取出内容的特征,这样我们就可以用提取的特征去完成我们需要完成的任务,比如,分类又或者回归等。
我们自己也可以决定分类的特征到底需要提取什么样的。
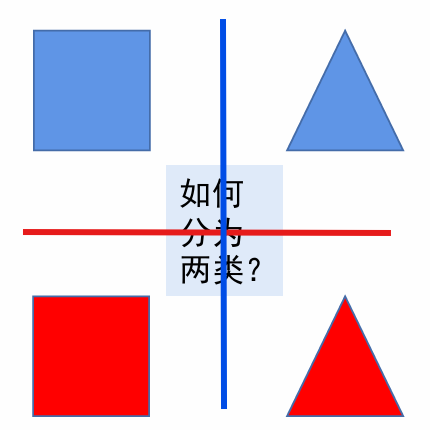
比如这个图,我们要分类既可以按照形状来分,又可以按照颜色来分。你的模型朝着哪个方向压缩特征,由你的标签来定。
2,无监督学习
无监督学习,就是我们只有所需的数据,比如图片,但没有对应的标签。从实际来看,绝大部分数据都是无标签的,对于一个含有成千上万个数据的数据集,打标签是十分麻烦的,因此就引出了无监督学习。
机器学习的方法有: 降维PCA(主成分分析) 、聚类。
深度学习的方法有:生成对抗网络、自监督学习(对比学习和生成式自监督)。
那么怎么自己监督自己呢,对于人来说当我们见到两种不同科不同属的动物时,我们一般都可以比较明确的将其分开,知道这不是一种动物,尽管我们并不知道这动物具体是什么,叫什么...似乎我们人类就可以不需要标签学习。


又比如这些车标,尽管我们可能不认得这些车标是什么,但我们看到两个不同的标时,我们知道这是两个不同的牌子的车。
那么对于机器来讲,它怎么能分辨呢,怎么可以不用标签进行学习呢。
那么就是要让相同的类的特征离得更近。我们没有标签无法分类,但我们知道同一张图,不管它怎么进行数据增强图像的变换,它都是和原图属于一类的。于是就把自己和自己的增强图像当作一对, 把别人当作敌人。亲近自己, 远离别人。


把自己和自己的增强同类放一起,就可以提取特征了。例如simsaim用两个不同增强的图像进行比较,用一侧的向量预测另一侧的。
对抗生成网络GAN
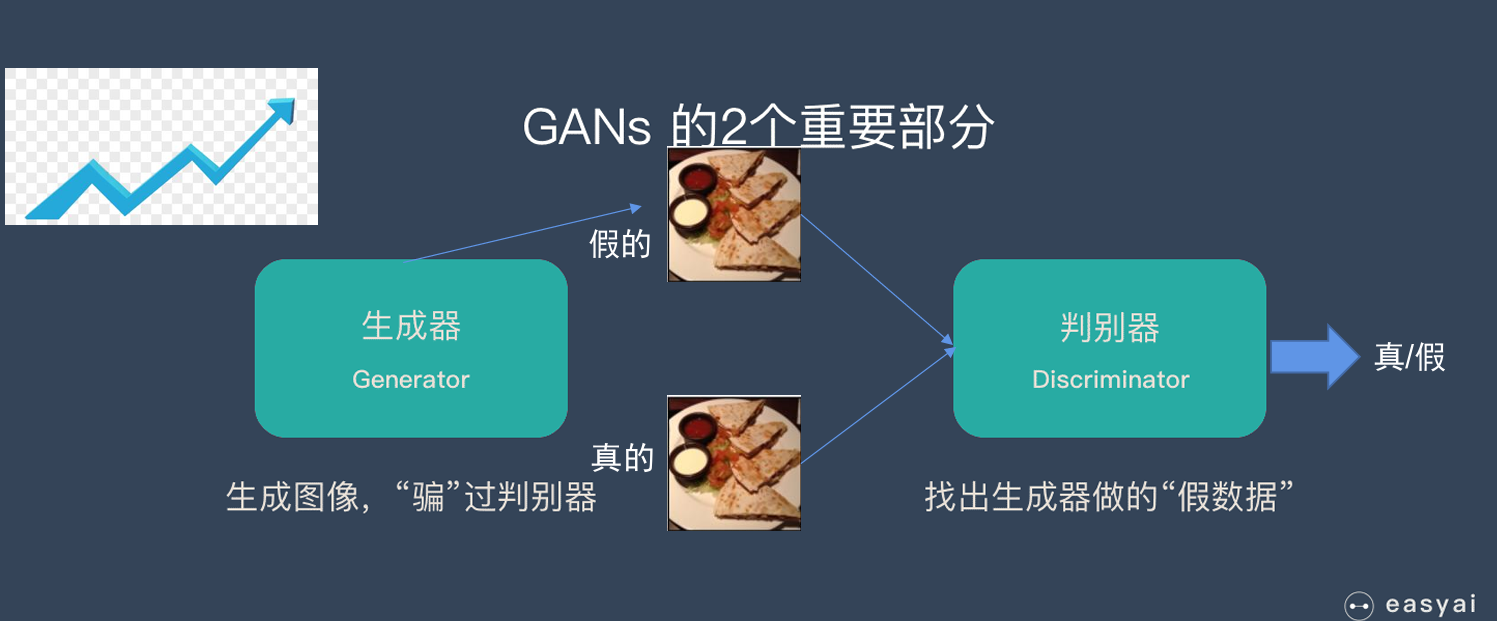
分为生成器和判别器,生成器学习图中的特征,然后自己用学到的特征生成一张“假图”,把假图和真图一起发给判别器判别,判别器判别真假,对比判别是否准确的概率产生损失更新,然后生成器用判别器判别的准确率来计算损失,准确率越低,说明生成器水平越高。
Cycle-Gan
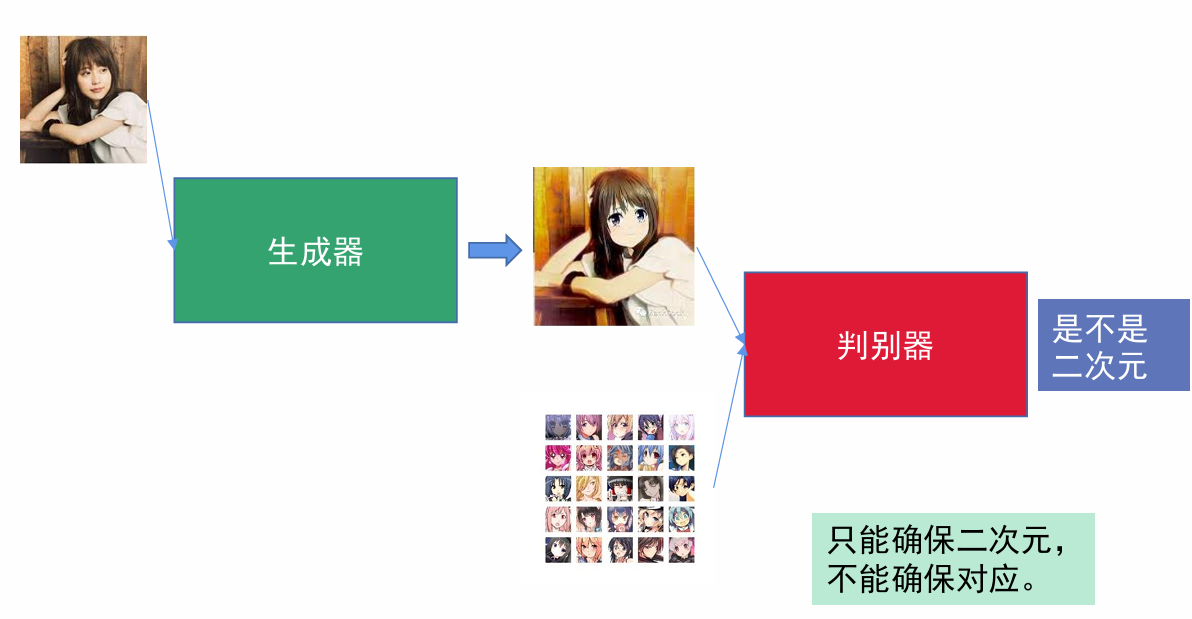
大家应该都知道那种根据真人图片来生成二次元或者其他风格图片的那种软件吧,它以前就有用Gan来做的,导入一个图片,生成器生成一个二次元图片,然后判别器判别是否是二次元,但这有一个小问题,就是生成的图片虽然是二次元但不能保证和原图真人比较相似
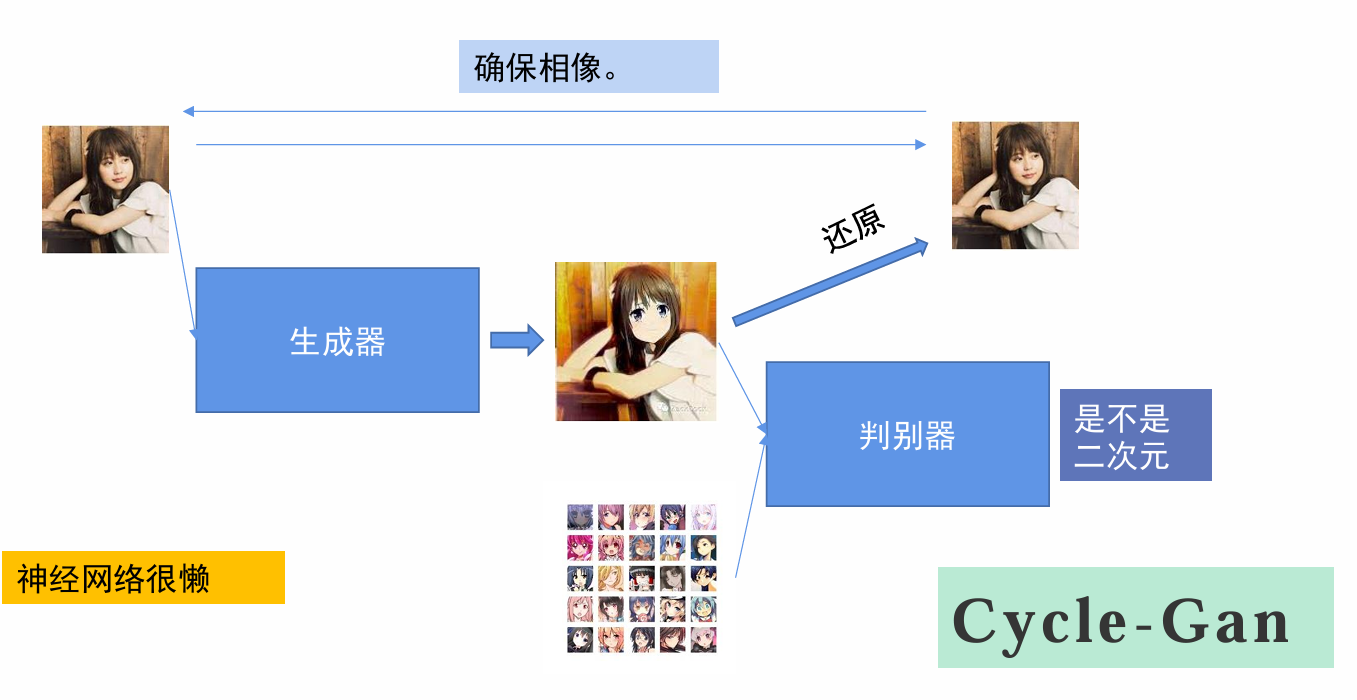
那么就可以再加入一个对比,用生成出来的二次元图片再生成一个真人图片,进行图像还原,然后用还原的图片和原图进行对比,以确保生成的二次元图和真人图相似度比较高。
生成式自监督学习
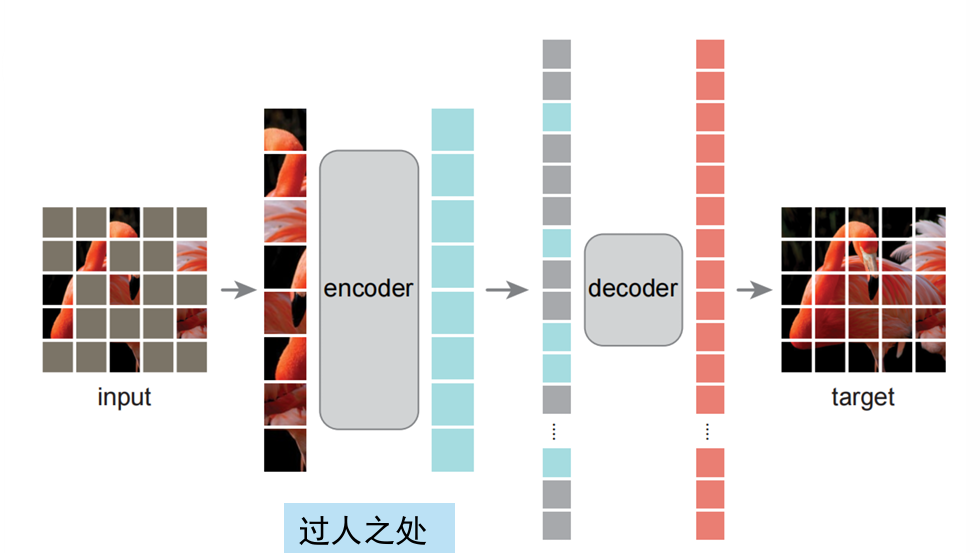
还可以将自己的图片的一部分作为训练生成的目标,盖住一部分数据,用模型生成另一部分,然后对比产生loss更新模型。
或者也可以将原图变成黑白的,然后用模型预测颜色这样的。
不光是图片,对于文字也一样,可以将某段文字去掉一些字,然后让模型进行训练,模型可以很好的还原原文字。下面会详细说这个。
我们用无监督训练的模型这个过程叫无监督预训练,之后就可以拿这些有很好的特征的模型进行各种下游任务。另外用无监督学习可以训练出一个很好的模型,甚至比有监督和半监督还好。
自编码器的特征
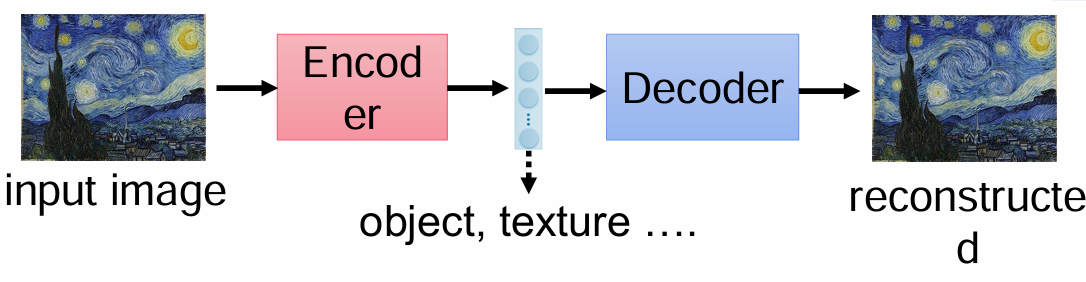
模型可以作为这个编码器,提取特征其实包含这一整张图片的信息,比如图片里的事物,图片画风材质,等各种信息,我们用这些提取出的特征是可以还原出原图的。包括音频,文字等也一样。
那么如果我们能把特征中不同的特征分离开来,然后用将不同图片不同部分的特征拼接在一起,
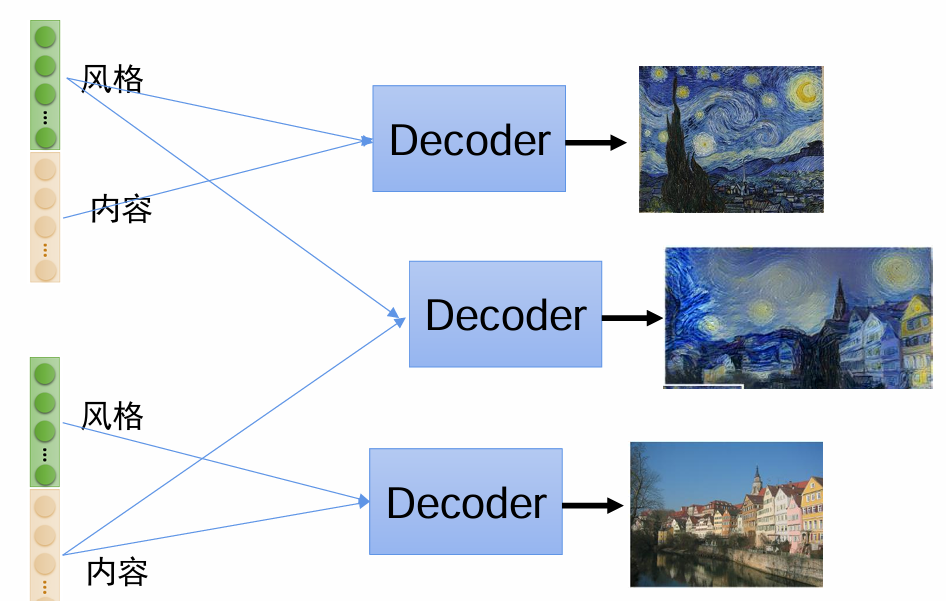
就可以像图中这样,将两个不同图的一些特征拼在一起,形成一个融合图。
3,自注意力机制
可以用矩阵来表示图片,那么文字呢,我本来想的是用传统的计算机文字编码,比如UTF-8,ASCII这样的东西。但实际上使用的是向量编码,因为ai训练需要用张量,还有就是传统编码都是一个维度的,难以体现一些文字关系,使用独热编码,但首先也需要一个编码词汇表,类似传统编码,但编码更密集一些,包含内容只是所需内容,使得向量维度不那么大,这里使用一共21128个汉字的词汇表来说明,另外就算这样的字数,其向量维度也太多,而且不同意思的词之间向量距离也一样,体现不出来字之间的关系。
于是就有了Word Embedding,要让同类的词距离更近,不同的距离更远,我们还是使用独热编码,但是要缩减维度,同时调整距离,我们不太可能手动编码,但我们可以让模型来学习生成。
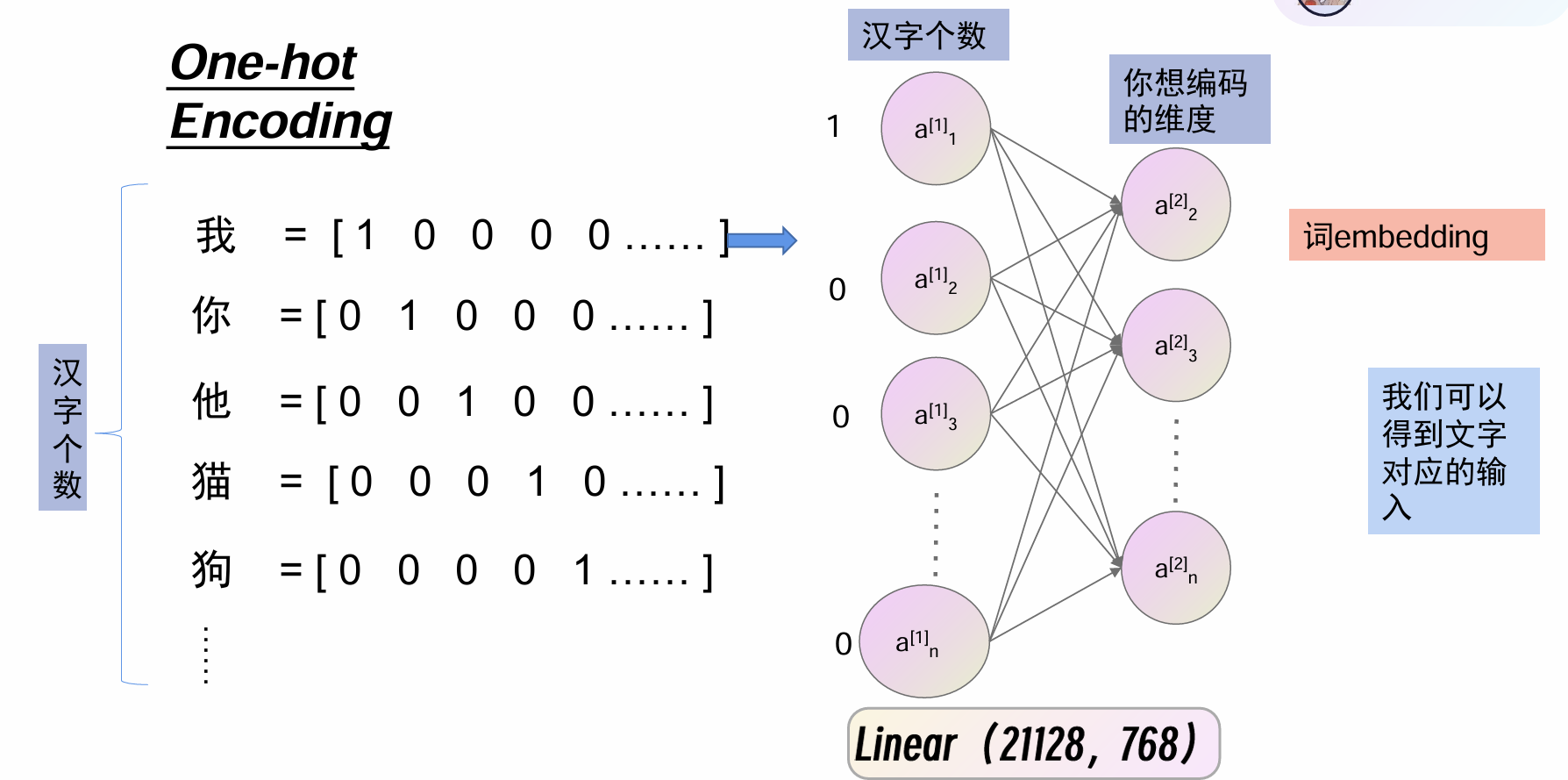
输入维度是21128,中间也可以有隐藏层,输出768维的一个全连接网络,就可以将其转为想要维度的编码。
得到这样的合适维度的词向量以后,就可以输出做各种各样的任务。
文字输出有三种,一种是每个字对应一个输出,比如词性识别
还有一句话对应一个输出,比如情感识别
最后是最复杂的多个字对应多个不同数量的字输出,比如翻译任务。
本次讨论前两个。
RNN和LSTM
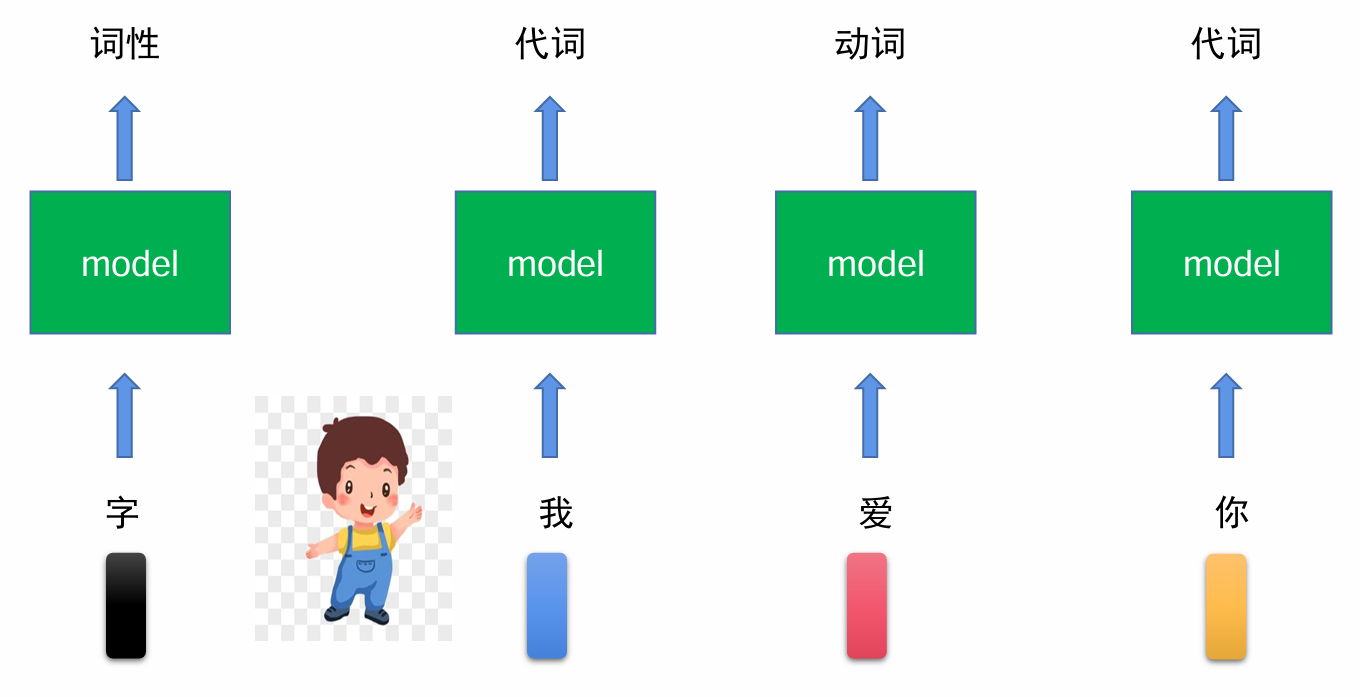
对应词性识别,简单的句子可能只需要考虑单个字就行
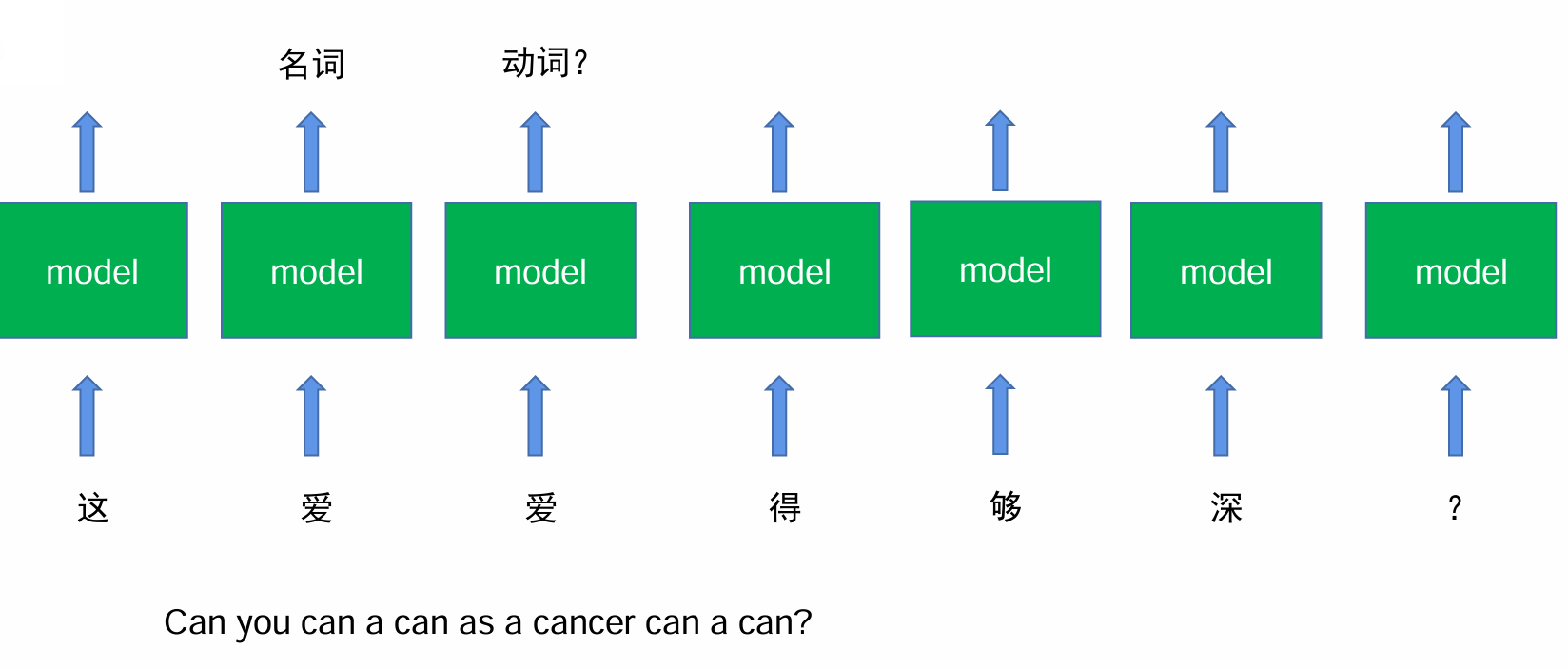
但对于复杂句子,以及有些字在不同情况下词性不同,就不能只考虑单个字了。
就需要考虑前后关系。于是就有了RNN,循环神经网络。
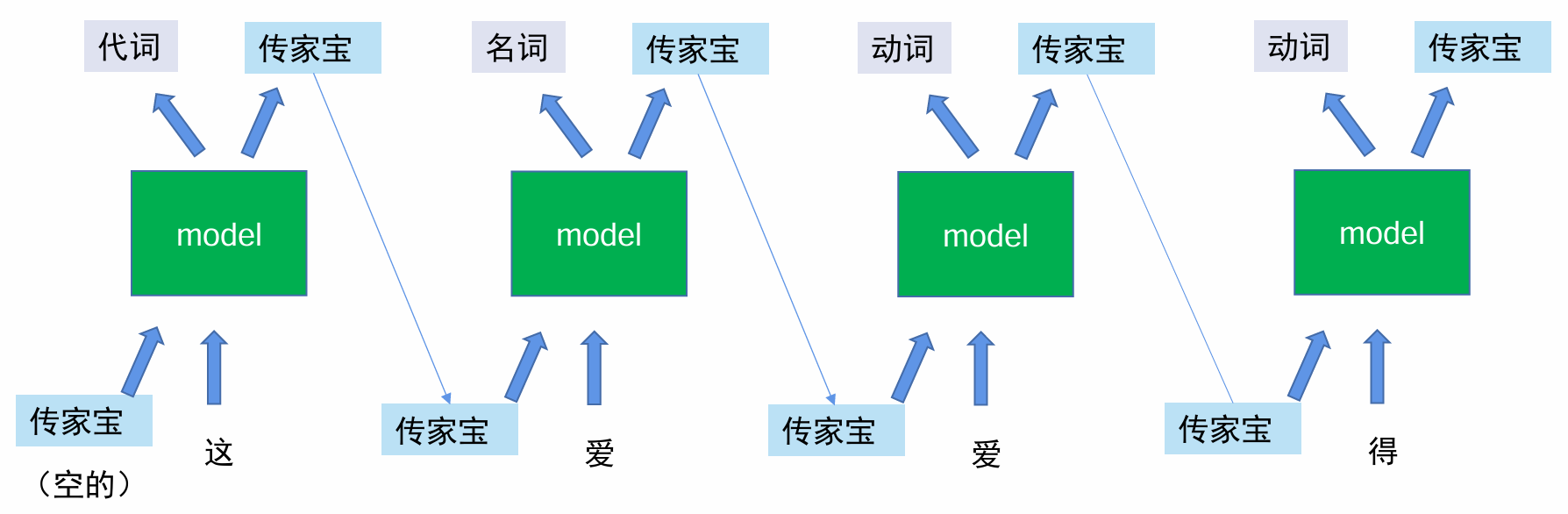
先产生一个空的”传家宝“,对于每个字,输出代词,然后将自己的内容放入传家宝中,传给下一个字,这样依次传下去,就能让每个字都能考虑前面字。
但如果字太多,比如我们做语文阅读理解,一篇文章可能几百几千字,这样一篇文章,要问作者在文章开头做的事对结尾有什么影响,就这样一次一次的传传家宝会有问题,比如有个字训练结果可能不好,那么它往传家宝放的东西也会不好,会影响后面的字,再个传到后面就不一定是什么样子了,可能就很难处理了。
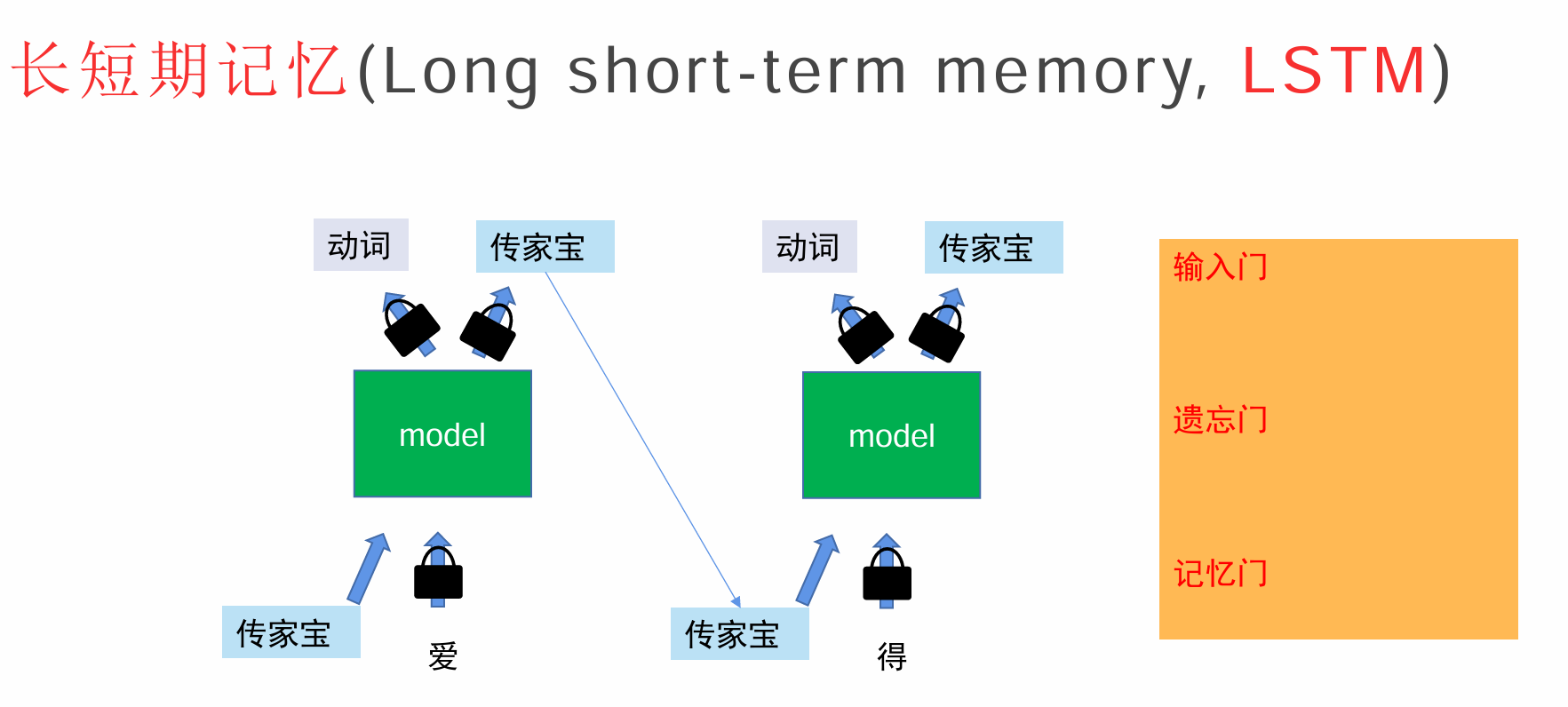
于是有了长短期记忆,输入门控制该字是否要被输入,不输入,我们内容就减少了,我们就关注我们要的开头和结尾内容即可,记忆门,控制该字是否往传家宝里面放东西,如果本次训练不好就不放,遗忘门的主要作用是决定在当前时间步中,记忆单元应该遗忘多少之前的信息,通过遗忘一些内容来保持记忆单元的有效性和简洁性。
不过缺点都是太慢,要一个字一个字串行处理。
于是,就引入自注意力机制。
自注意力机制
 引入transformer
引入transformer
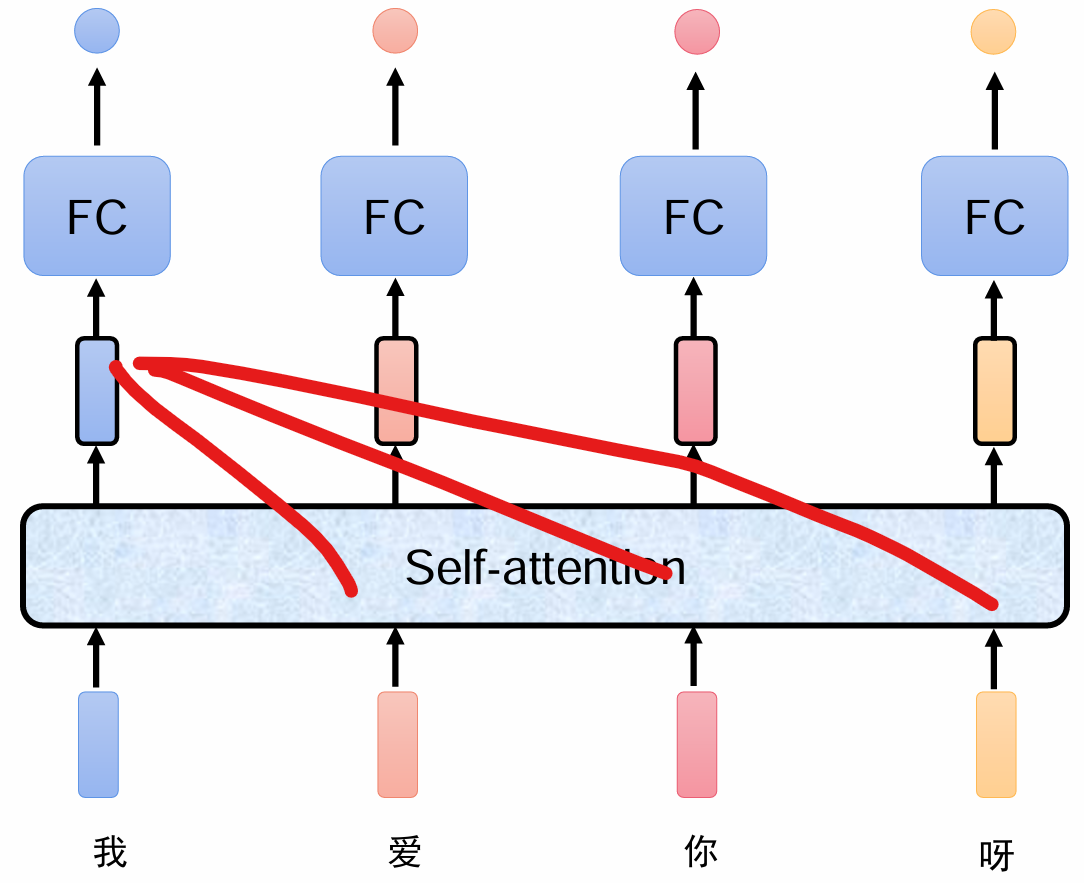
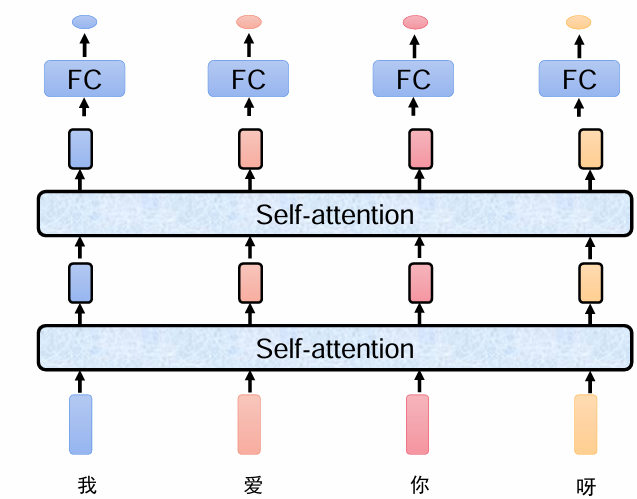
把整句话输入进到自注意力机制里面,处理以后得到特征,再加上一个全连接分类就可以得到最终的结果,这个特征是考虑到整句话所有内容的。
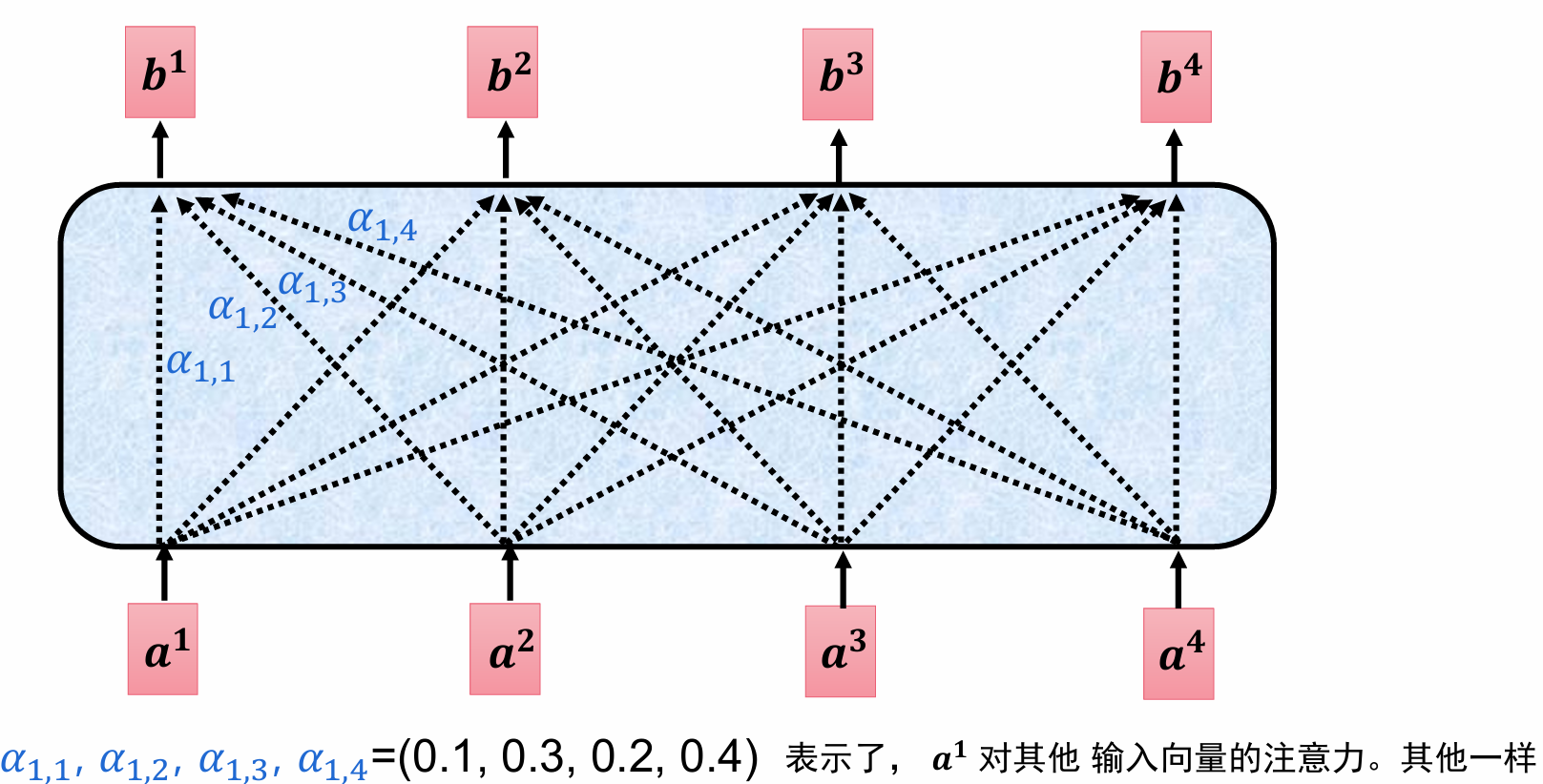
注意力就是每个字对每个内容,某几个字多少的这样一个权重。
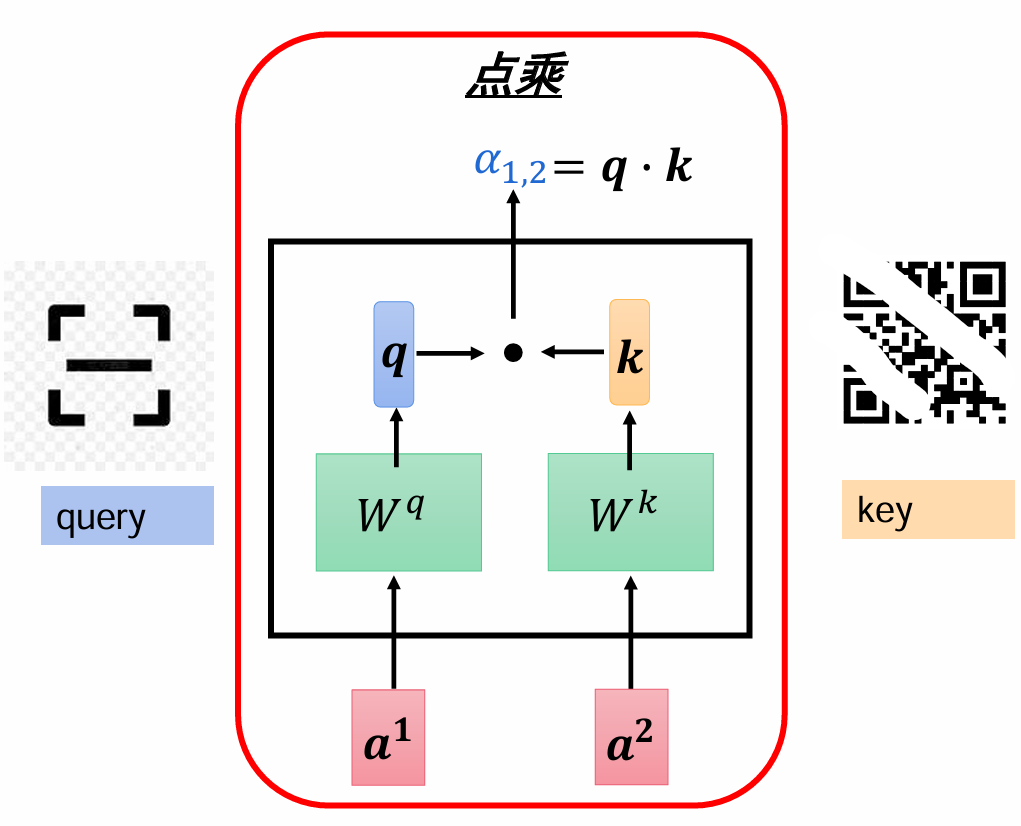
那要计算这个注意力的话,我们可以用点乘的方式,a1和a2是处理好的词向量,比如每个是1*768,那就对每个字都用一个Wq和Wk矩阵,大小都是768*768(如果输出维度要改变,需要改变列数),让初始向量和它们相乘,结果向量大小还是不变的1*768。q表示query,k表示key,就像一个扫码器,一个是编码器,用扫码Wq得到的向量q去点乘Wk得到的向量k,得到一个字对另一个字的注意力α1,2.
为什么要用两个矩阵Wq和Wk呢,一种解释是一个矩阵是线性的,而两个矩阵可以形成类似二次型那种,使模型产生非线性。
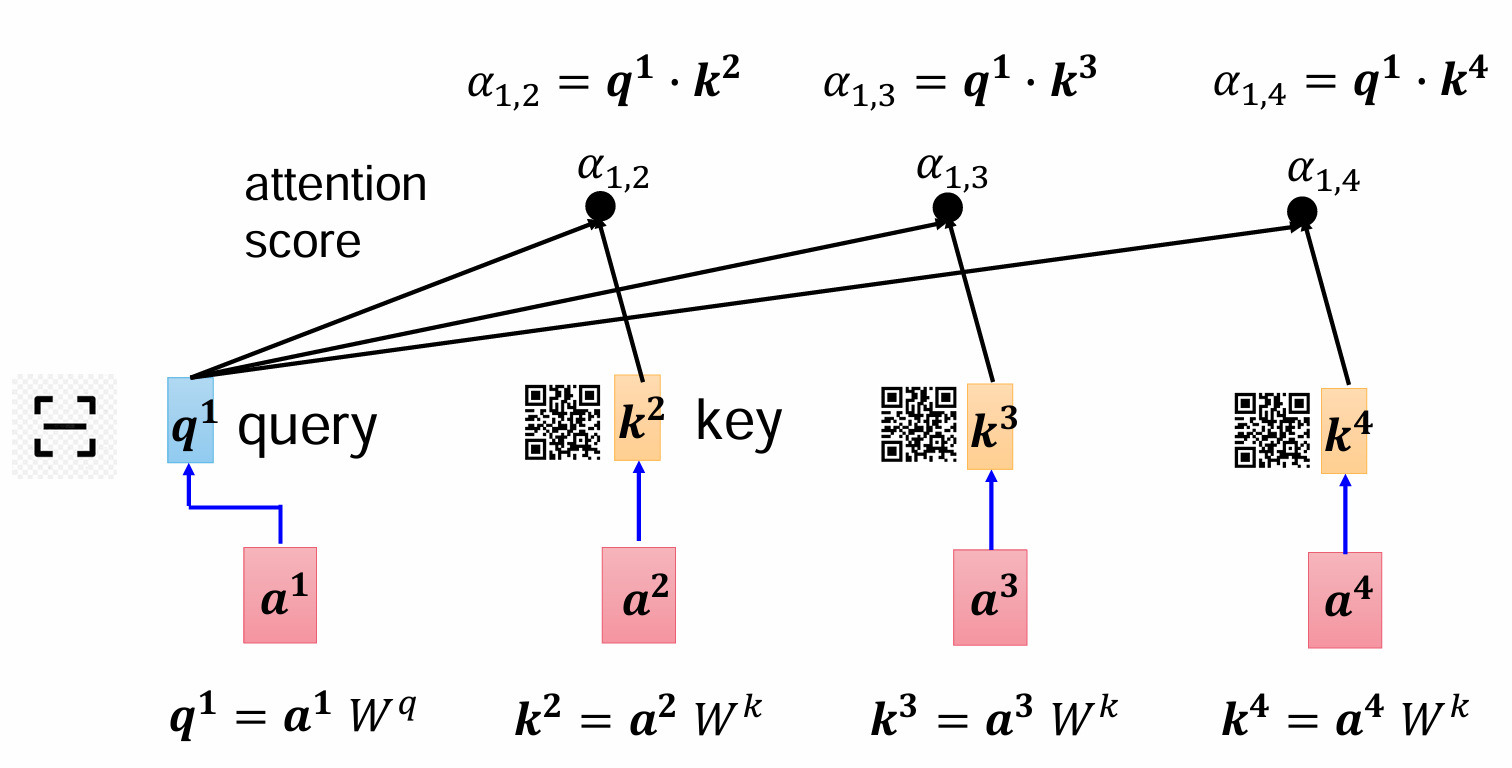
放到整句话里面就是这样,第一个q对后面的每个k都乘一下得到第一个字对后面每个字的注意力
当然a1自己也有一个Wk,a1*Wk=k1,q1*k1=α1,1。
当q和k关系比较密切时,向量就会比较接近,其夹角就会比较小,cos更大,内积更大,反之会更小,90°正交为0。
经过softmax以后变成概率形式,比如(0.1,0.2,0.3,0.4)这样
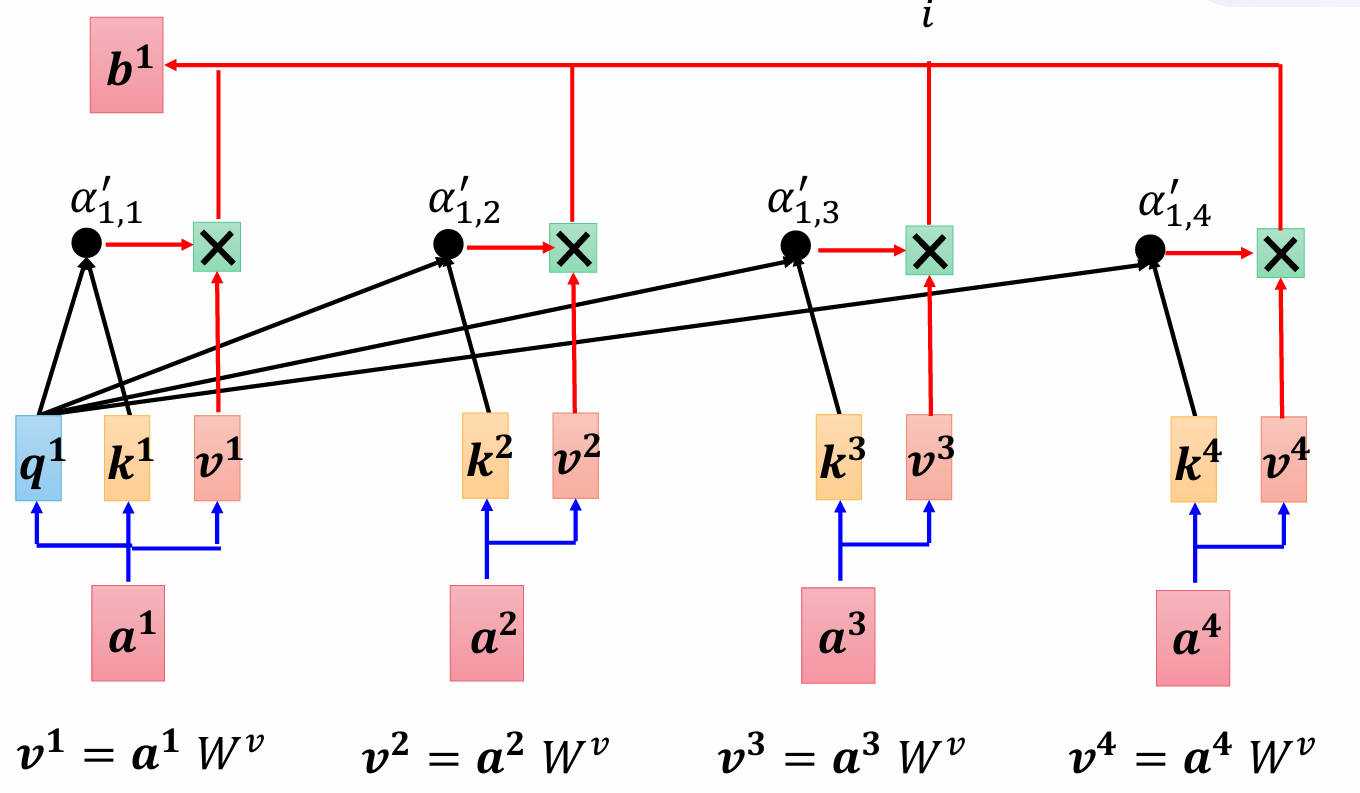
那么怎么把注意力求和,直接加肯定不行的,处理数据肯定还得要向量,于是我们引入一个Wv矩阵(值矩阵,value),用它乘a1得到v向量,数乘每一个注意力,然后再将得到了改变了倍数的vi相加求和得到一个b。
v可以看作一个字典,A'是上下文关联的系数,以字典的词义,通过上下文来得到其主观的含义。
对于其他的a也是一样,这样以后,我们其实对于每个字对其他字的处理这个过程就是完全可以并行了。由于不再需要传家宝,每个字对其他字的处理都是独立的了。
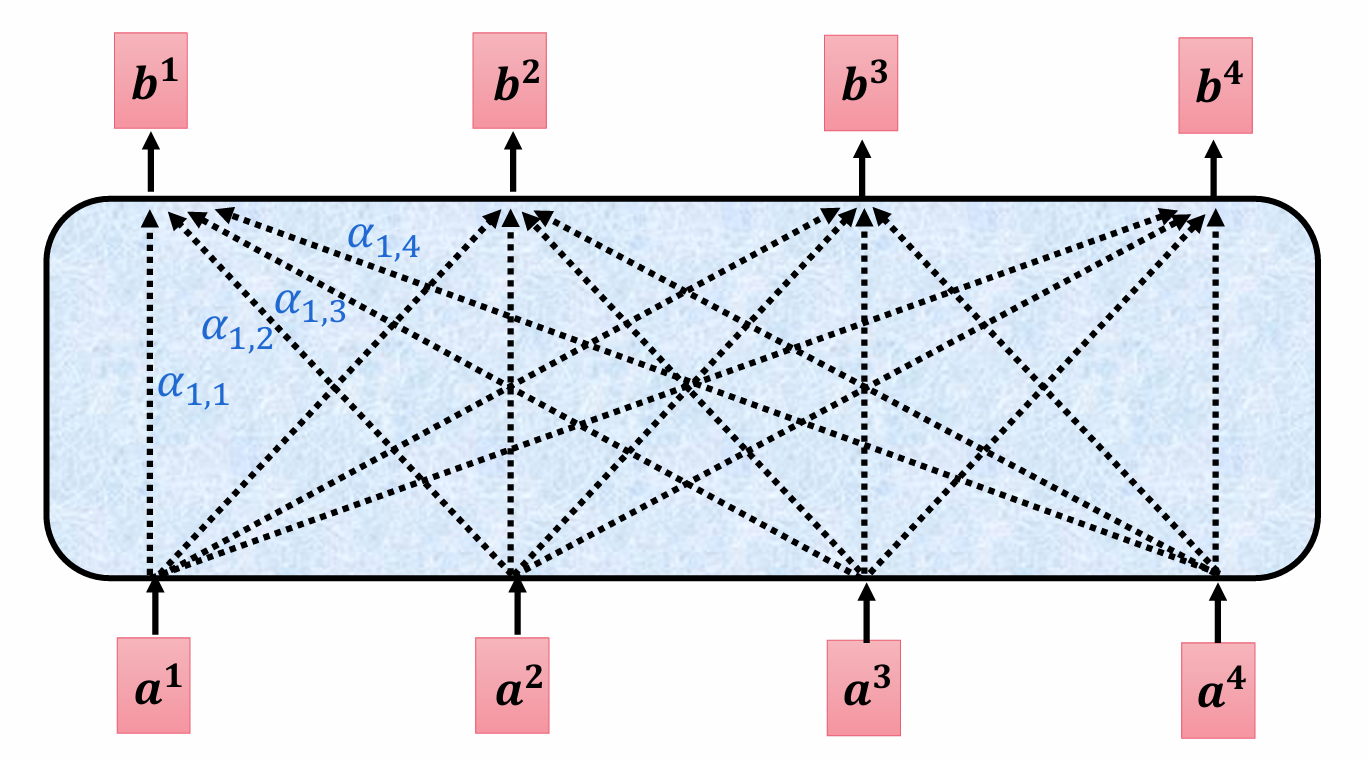
结果就是这样,每个字都最终产生一个b向量,也就是其上下文感知特征向量。
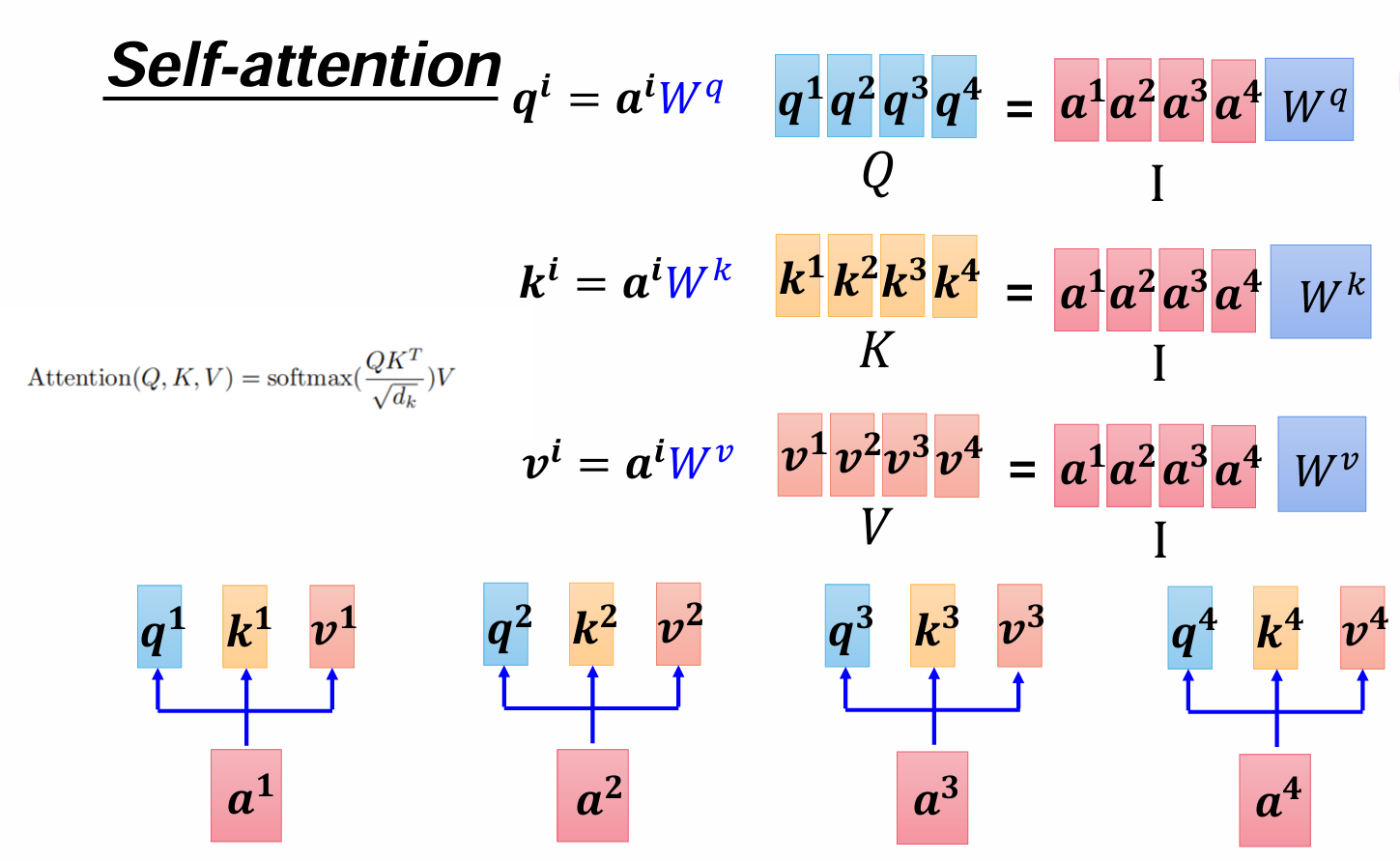
将整体用矩阵表示,每一个q,k,v向量都可以用其对应的词向量乘Wq得到,可以将向量拼成矩阵形式,得到Q=I*Wq,K=I*Wk,V=I*Wv。每一个q都乘所有的k向量,得到内积,就是注意力aij,写成矩阵形式就是,下面分母是缩放标准差,让数据变成标准正态,然后经过按行计算softmax得到和为一的归一化注意力权重。
用得到的结果再乘V,就是最后的每一个特征向量了,整体就可以用左边的那个公式来表示。
可以再来顺一下维度变化,我们处理后的词向量假设是768*1的,然后每个W矩阵都是768*768的,词向量a乘每个W都是维度保持不变,得到q,k,v还是768*1,
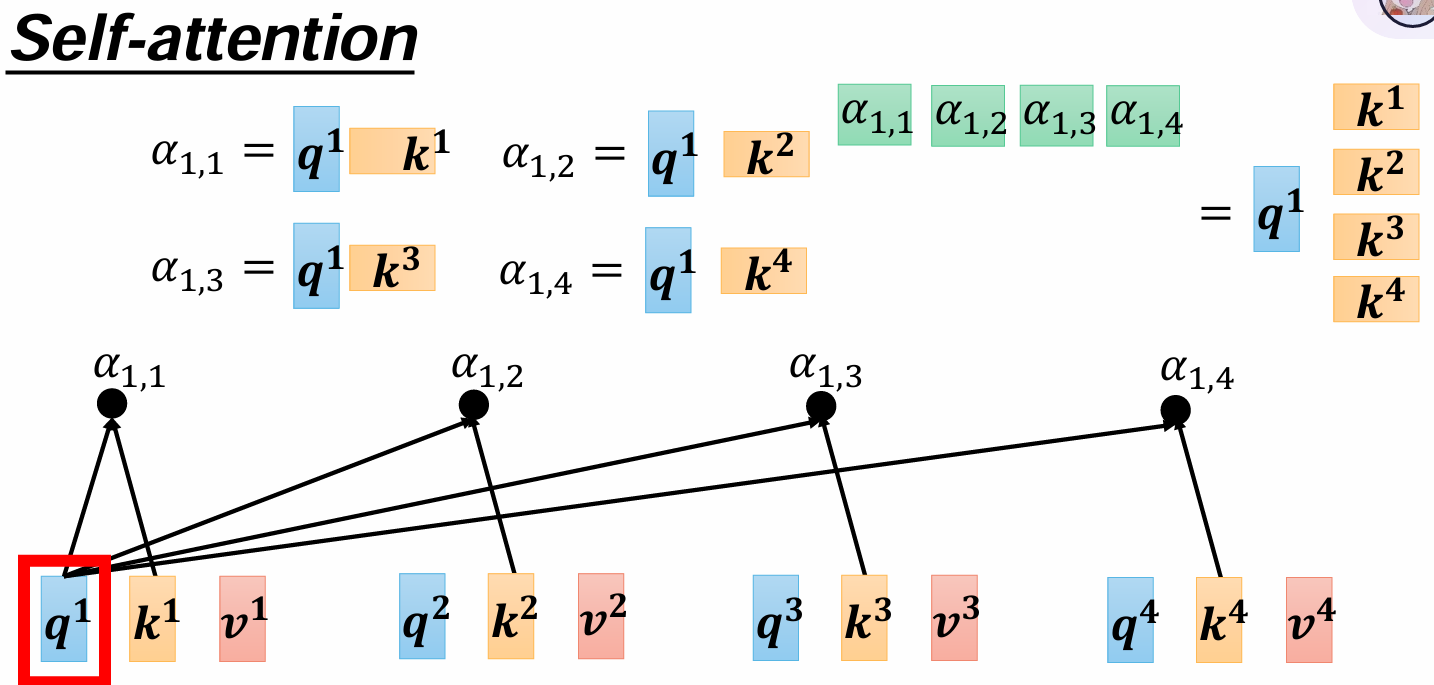
再用q和k做内积,得到每一个注意力权重aij,将其写成合并的矩阵形式,就是上图右侧那样q1是1*768,所有的k组成KT(转置)是768*4,相乘得到1*4的所有aij
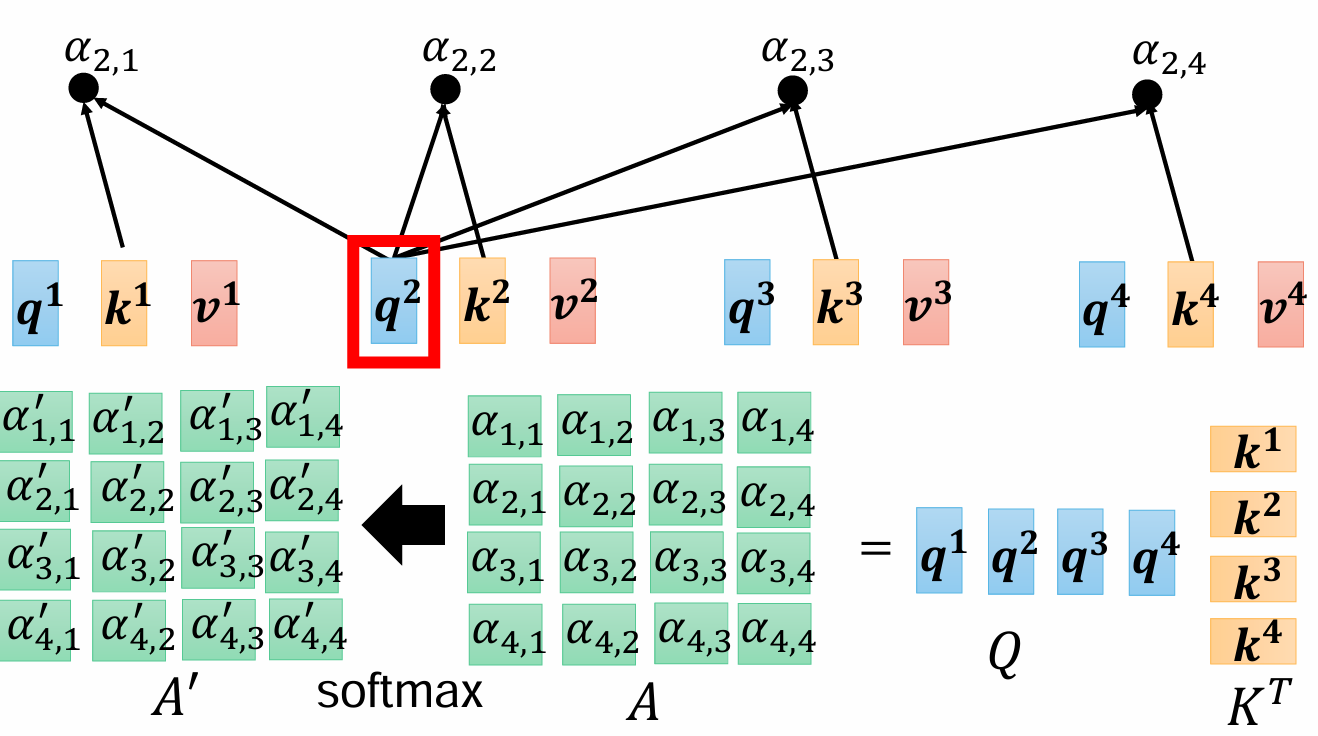
于是对应每个字都这样处理,就是Q(4*768)×KT(768*4),得到4*4的A,再经过归一化得到A'
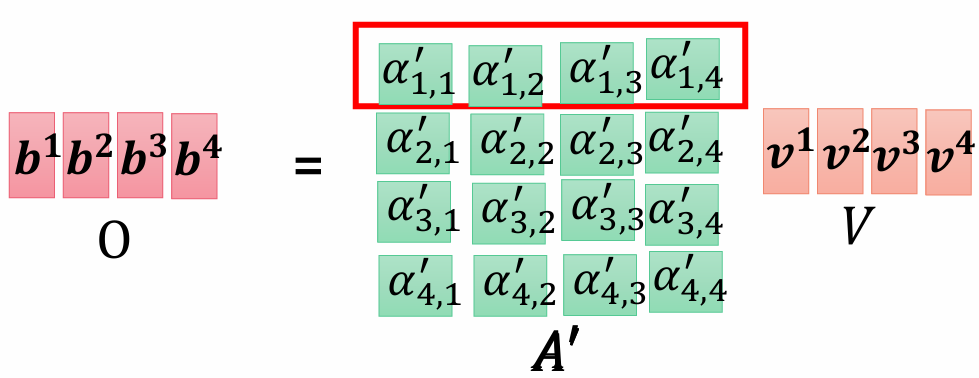
最后由A'4*4乘4*768的所有v向量拼成的V矩阵,得到最后的O(注意这个是数乘求和。)
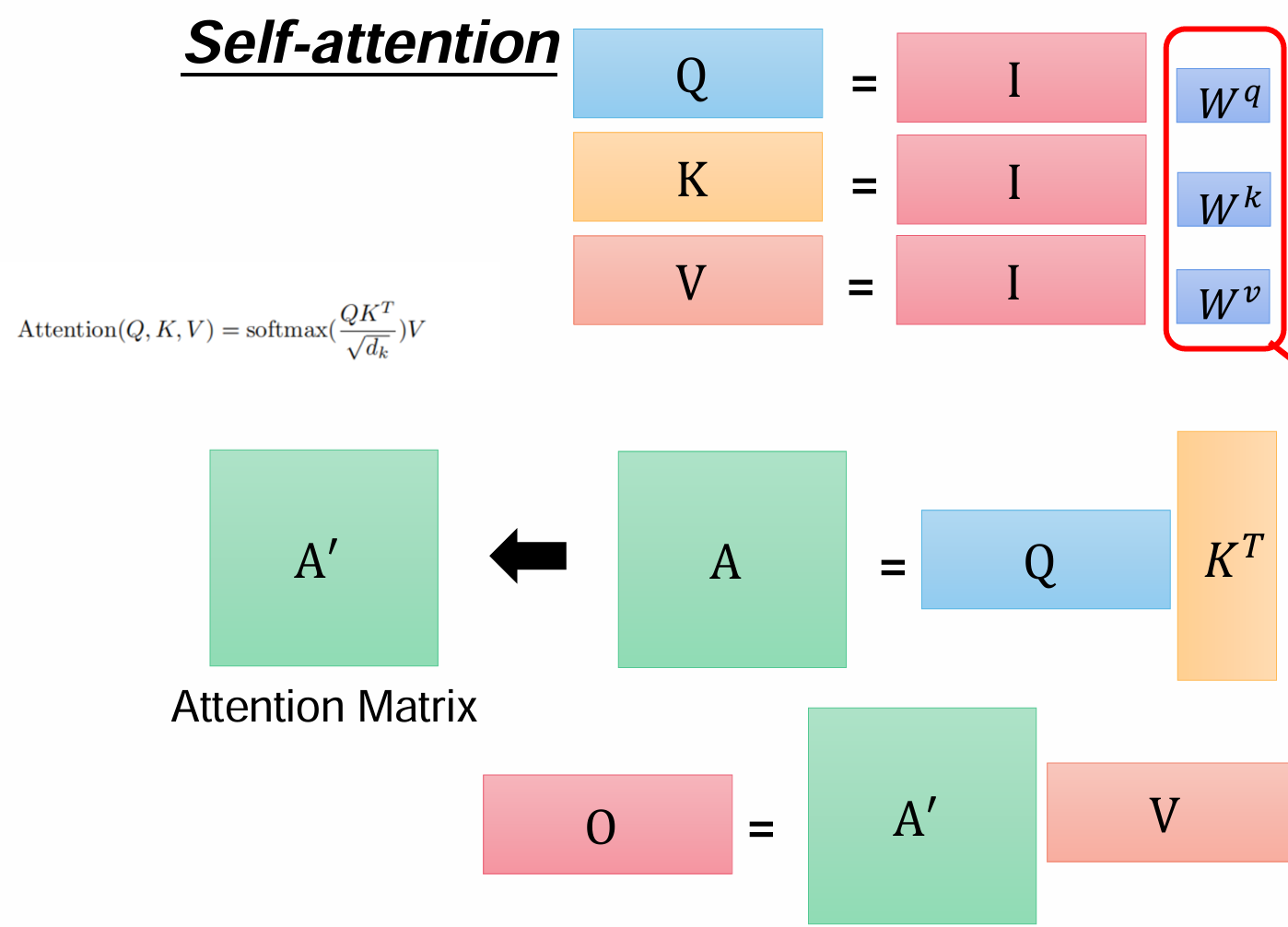
最后就是这样↑
这其中要学习的参数只有Wq,Wk和Wv,其他内容都是由这三个矩阵和词向量乘出来的。
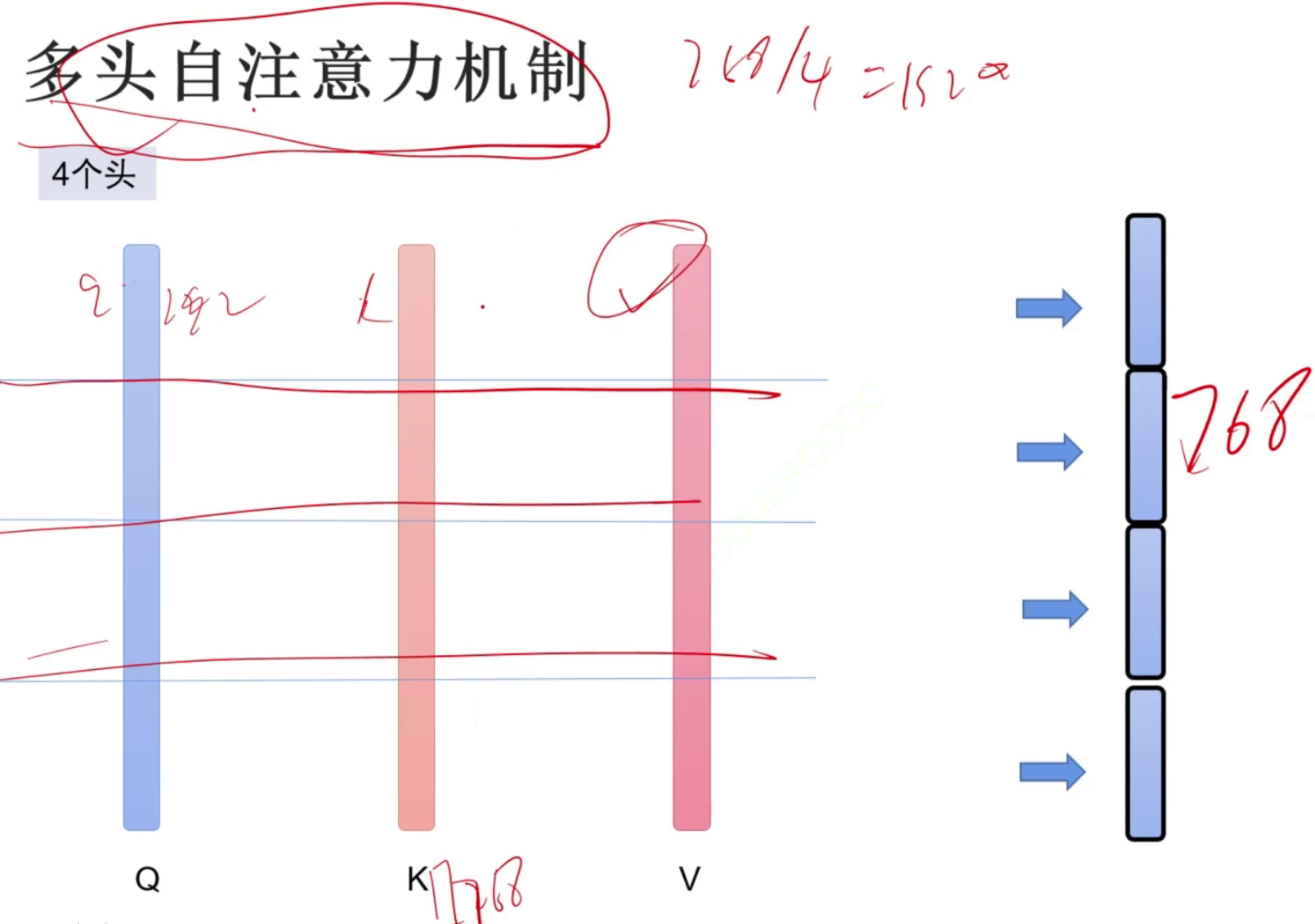
多头注意力机制,将权重矩阵分成多个矩阵,每个矩阵关注不同方面,每个头都可以只关注自己的内容,并且还可以分散计算。暂时简单了解。
大家可能也发现了,我们得到的特征向量的维度和原始维度一样,那么这样的话就可以叠好几层不断的来提取其特征。
但还有一个问题就是,每个字只知道有其他的字存在,但却不知道这些字的位置,因此我们还需要给模型加入位置信息。
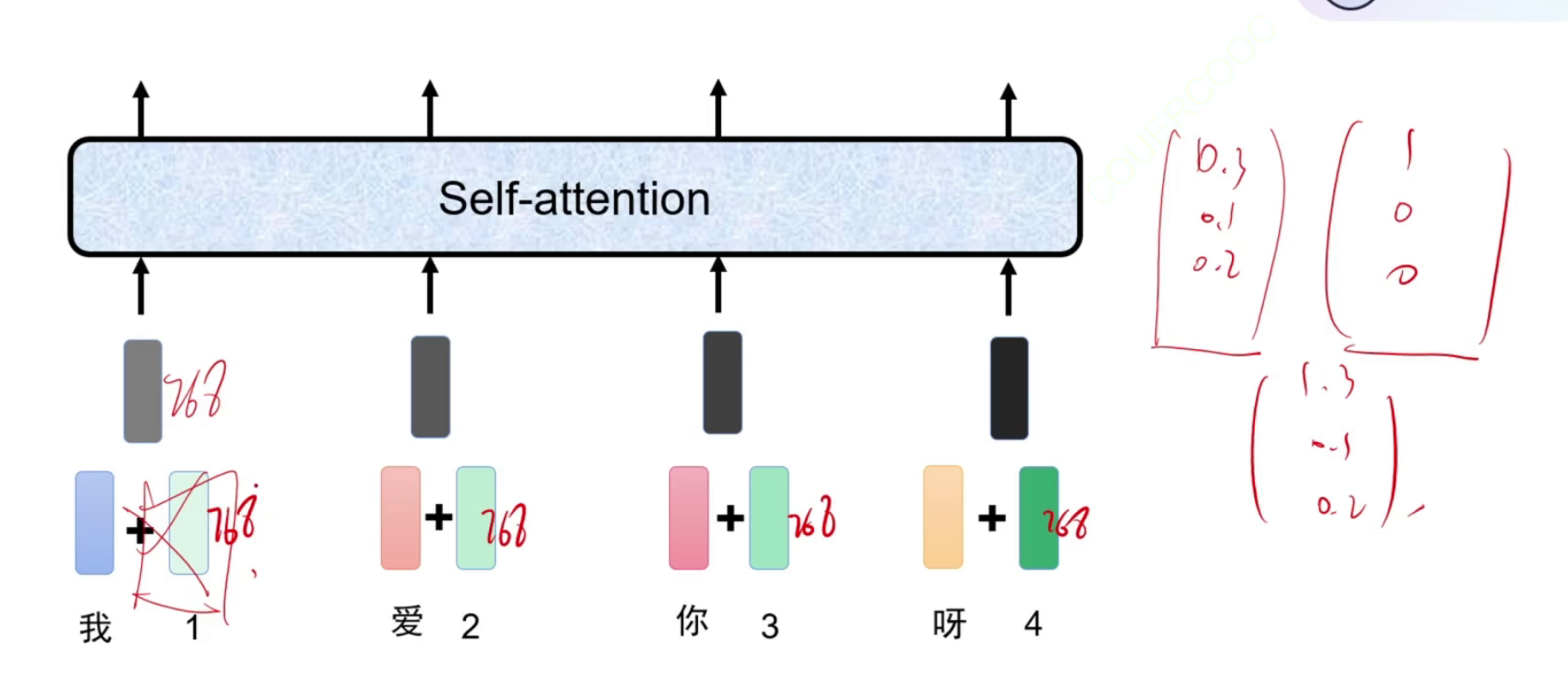
位置信息怎么加呢,这里的方法就是将位置那里值用独热编码对应设置为1,直接加到归一化的向量上就行。还有用乘法以及别的方式进行的。这个地方还有什么相对位置编码和绝对位置编码,但我没搞懂,就不说了。
这样我就可以通过注意力矩阵,给文章开头和结尾信息分配更高的注意力,让模型更多的关注文章的开头和结尾。
另外每个字加上自己的位置信息也被称为一个token
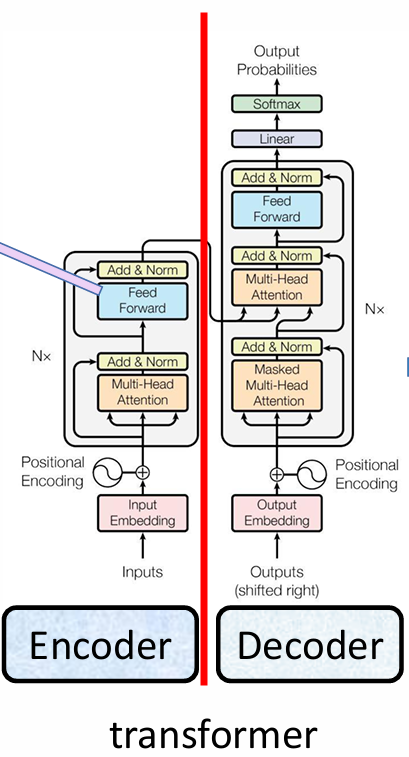
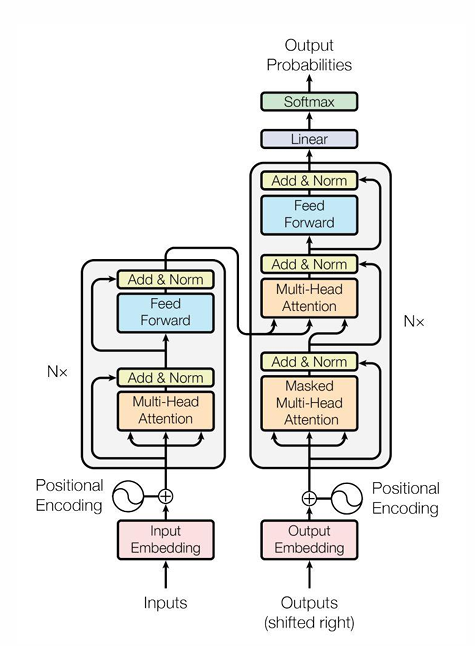
再回来看这个图,我们目前讨论的都是左边的编码器,input embedding是输入的词向量,position encoding是位置信息,multi-head attention是多头注意力机制,add&norm求和并归一化,旁边那根线条是resnet的把输入加到输出上,能让注意力机制学到前后变化的程度。feed forward是前向的一个FC,最后还输出768维度,Nx表示这个网络可以叠加很多层。
右侧的Masked多头注意力是要生成的词只受前面词的影响,不能受未来的词的影响,因为实际上每个词和上下文都有联系
Bert
encoder的一个代表就是Bert
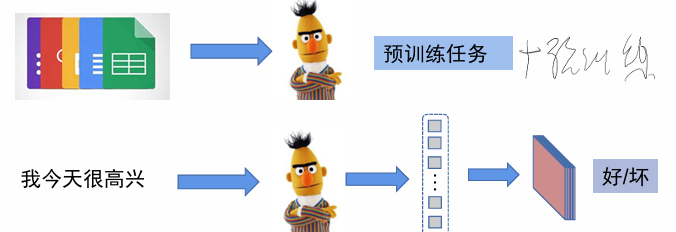
bert就是一个特征提取器,我们可以用各种文本进行预训练,然后再输入一段话,bert可以判断其类型。预训练就是无监督的,对一些文本其中挑出一部分,覆盖住,还有的写成错的,让模型来推断正确的文字内容,同一句话的不同向量之间都有一定的关联(可以想象成对于一个稳定物品受力分析那种)
还有推测句子前后文,让模型判断两句话是否具有上下文关系
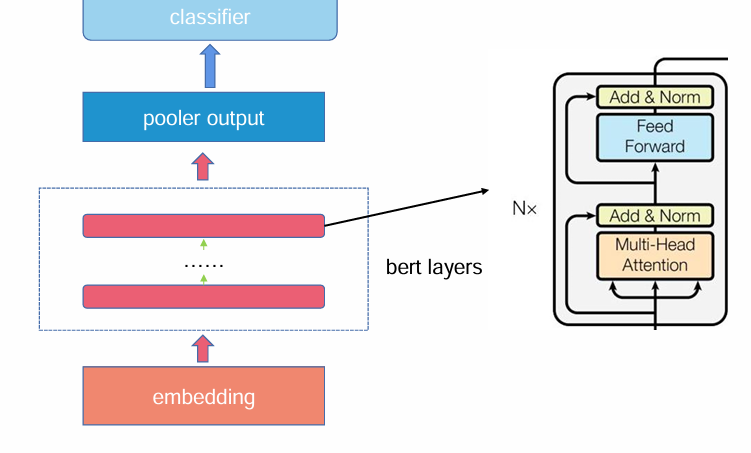
bert的结构如上,pooler就是池化
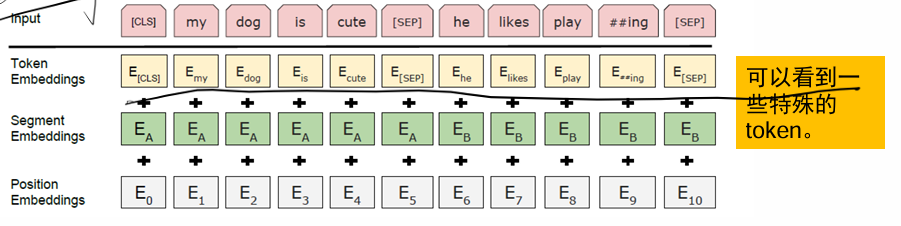
bert比原本的transformer多了一层,其中token emb就是词向量,下面segment emb是用来划分不同句子的,这个原本transformer没有,最下面就是位置编码
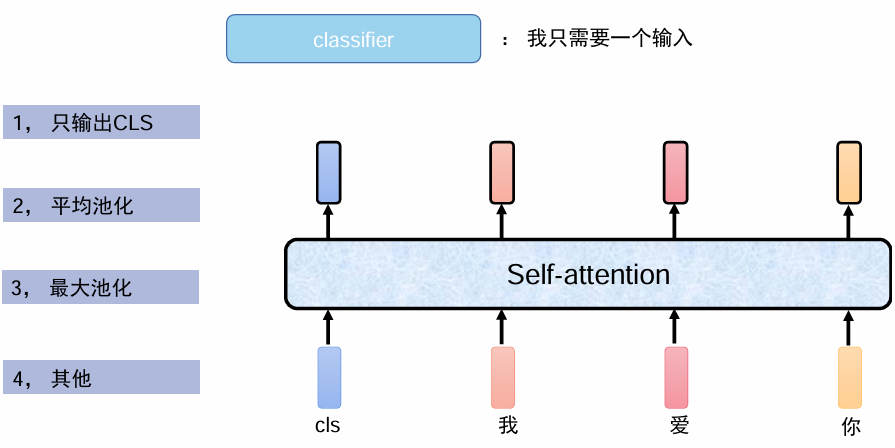
classifier是分类器,它只需要一个输入,进行FC,有这样几种方法,一般常用第一种,只输出CLS
目前就先这样吧,这里面很多内容要深究的话,会涉及很多各方面的数学知识,超出我的能力范围了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









