




1.简介
文章来源:CVPR2024
内容简介:这篇文章介绍了一个名为VideoLLM-online的创新模型,它是为了在流媒体视频中实现实时对话而设计的。VideoLLM-online模型能够实时生成视频内容的叙述,可以识别视频中的人物正在进行的活动,并回答与视频内容相关的问题。此外,VideoLLM-online模型还可以作为智能助手,与用户进行交互,回答用户关于视频内容的问题,提供实时反馈,在。
VideoLLM-online模型在处理流媒体视频方面展现出显著优势,例如在A100 GPU上对Ego4D叙述的5分钟视频片段能够以超过10 FPS的速度运行,同时在公共离线视频基准测试中也展现出了最先进的性能,如识别、描述和预测等任务。此外,该模型在速度和内存效率方面也表现出色,为未来实际应用中连续视频叙述铺平了道路。总的来说,这项研究为构建一个始终在线的、上下文相关的AI助手提供了一个重要的步骤,这种助手能够及时回答任何人类问题,将输入数字化为情景记忆,并根据任何查询预测未来计划。
代码地址:https://github.com/showlab/videollm-online
项目地址:VideoLLM-online
权重文件地址:https://huggingface.co/chenjoya/videollm-online-8b-v1plus
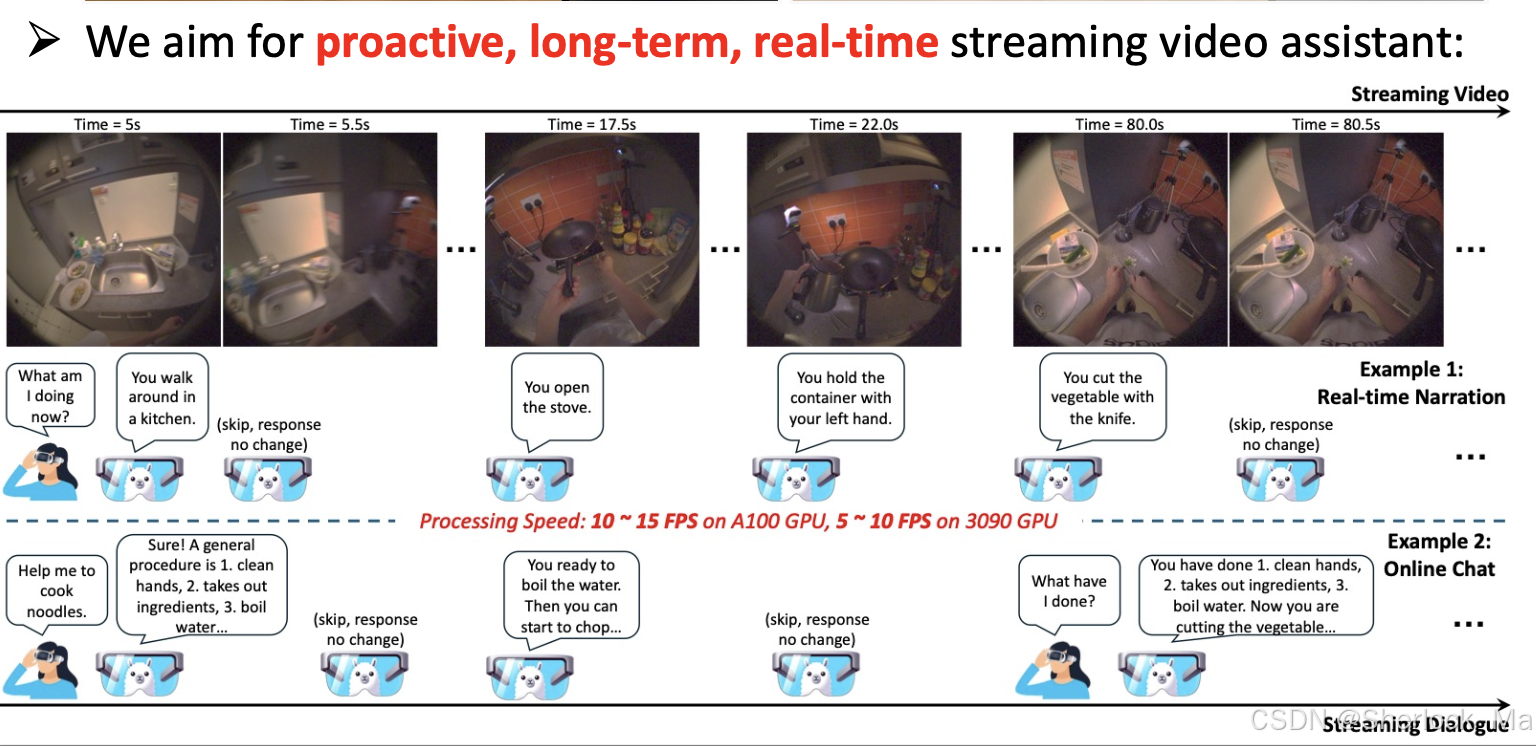
推理效果:
可以看到模型知道什么时候该回答,什么时候不该回答。并且模型知道你当前在干什么,还能根据上下文做推理。
(Video Time = 0.0s) User: Please narrate the video in real time.
(Video Time = 0.0s) Assistant: You walk around the room.
(Video Time = 3.0s) Assistant: You pick up a wooden spoon.
(Video Time = 4.5s) Assistant: You stir the food.
(Video Time = 17.5s) Assistant: You walk around the room.
(Video Time = 19.0s) Assistant: You open the tap.
......
(Video Time = 104.0s) Assistant: You pick a bowl.
(Video Time = 104.5s) Assistant: You put the bowl in the drawer.
(Video Time = 105.0s) Assistant: You pick a bowl.
(Video Time = 105.5s) Assistant: You put the bowl in the drawer.
(Video Time = 106.0s) Assistant: You pick a bowl.
(Video Time = 106.5s) Assistant: You put the bowl in the drawer.
(Video Time = 107.0s) Assistant: You pick a bowl.2.论文解析
问题定义
简单来说,作者想要训练一个实时对话模型,这个模型知道什么时候该闭嘴,什么时候该回答。比如炒菜的时候,你问它怎么做某道菜,他会告诉你先洗菜,期间它会闭嘴,洗完之后它会直接回答“再切菜”,等你切完菜之后,它才指导你做下一步动作。
数据
离线注释
大多数流行的视频数据集用于训练离线模型,并且仅具有与基本语言描述配对的时间片段注释(例如,活动、解说)。为了弥合这一差距,作者提出了一种方法,从这些来源的对话数据合成新数据。作者的关键思想是使用LLM基于视频注释生成用户辅助对话,涉及以下步骤:
- 首先,作者准备了一个问题模板库,包含关于视频的过去式、现在式和将来式的各种query,总共N个query。我们从库中随机抽取一个问题,记为Qi。
- 然后,我们从离线数据集获得视频注释时间轴。这通常包括带时间戳的语言描述,我们将其组织到语言提示中,例如,“time ta~tb:烧水;time tc~td:切菜。",表示为A。我们认为所有的状态变化的关键时间戳作为理想的响应时间。对于本例,ta、tb、tc和td都被视为响应时间。
- 第三,我们提示大型语言模型在每个关键时间戳生成响应,例如,ta,tb,tc,td,根据Qi和A.我们可以对每个Qi重复这个过程,直到所有查询都被处理完。响应被保存以在训练期间加载。
- 最后,在训练过程中,我们(1)随机采样查询并在关键时间戳加载其响应,(2)将查询随机插入到视频时间戳tr中,(3)丢弃tr之前出现的响应,并在tr处添加响应。这里,不同的查询可以被插入到一个视频中,这只需要在新的查询插入时间戳之后丢弃先前查询的响应。
简单来说,就是随机随时插入问题库中的问题,然后用已有的视频理解大模型根据数据集里的时间戳和当前问题生成对应的答案。这个过程中只会回答最新的问题,如果没有新问题就会循环回答最近一次的问题。
如下图所示:作者将模板化的问题随机插入视频时间轴,并将真实视频注释(沿着其时间戳)“提供”给LLM,提示他们在一段时间内回答查询。

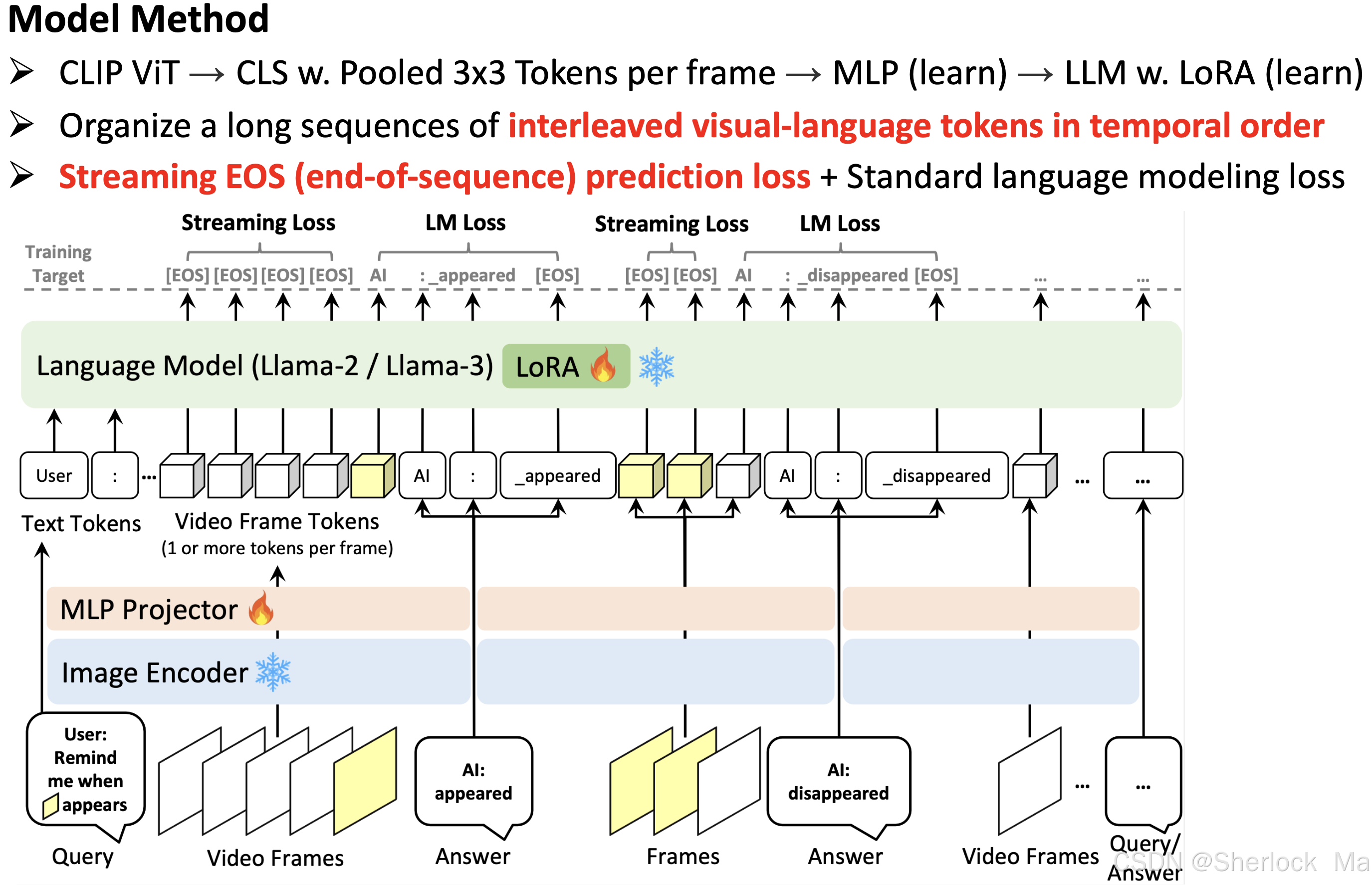
模型架构
类似于LLaVA ,它包括三个关键组件:图像编码器,MLP 和语言模型。
- 对于图像编码器,我们利用CLIP ViT-L 编码器(在DataComp 1B上预训练)以2 FPS提取视频帧嵌入。每个视频帧嵌入具有(1 + hp × wp)× c的形状,其中(1 + hp × wp)表示CLS令牌和平均池化空间令牌。
- 然后将从图像编码器提取的帧嵌入馈送到MLP投影仪中以形成帧令牌,如LLaVA-1.5所示。
- 然后,帧标记与语言标记交织,作为LLM的输入,Llama-2- 7 B-Chat。最后,我们将LoRA纳入LLM的每个线性层以进行有效调谐。
训练方法
简单来说,当模型判断当前帧不需要生成语言响应时(即保持沉默),它会预测EOS token(即直接终结对话,也就是不输出)。这样,模型就可以在不需要生成响应的帧上“跳过”语言生成,从而节省计算资源。而如果判断需要生成内容,就会直接输出内容。
模型将对话数据和视频帧的时间顺序作为输入序列。为了学习模型在视频流中何时回答或保持沉默,作者不仅采用标准语言建模(LM)损失,还引入了流EOS预测损失。当需要生成语言时,这种额外的损失会监督模型,使其能够产生时间对齐的响应,并减少冗余的对话历史。如下图所示。
损失函数
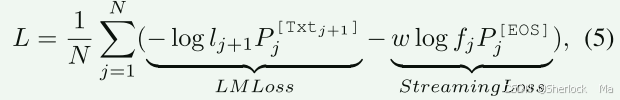
- LM Loss(Language Modeling Loss)通常指的是自回归语言模型的损失。在自回归语言模型中,目标是预测给定前文(context)的下一个词(token)的概率分布。因此,LM Loss通常计算的是模型输出的概率分布与真实下一个词的概率分布之间的差异,这通常通过交叉熵损失(Cross-Entropy Loss)来实现。
- Streaming Loss 的目的是让模型学会在视频流中适当的时间点生成语言响应。具体来说,它通过最大化EOS token的预测概率来实现这一点,当模型判断当前帧不需要生成语言响应时(即保持沉默),它会预测EOS token。这样,模型就可以在不需要生成响应的帧上“跳过”语言生成,从而节省计算资源,并保持模型的实时响应能力。
lj+1是一个指示器,表示是否应该计算该位置的损失(即该位置是否为语言模型需要预测的token)。如果lj+1为1,则计算该位置的损失;如果为0,则不计算损失。fj同理。
推理的细节
纠正偏好预测EOS
模型会偏向EOS token的预测。为了解决这个问题,作者引入阈值θ来校正EOS token的输出概率:如果P[EOS] j < θ,则EOS将不被视为下一个token。在实际使用中,作者发现将θ设置为0.5会产生比没有阈值更好的结果。
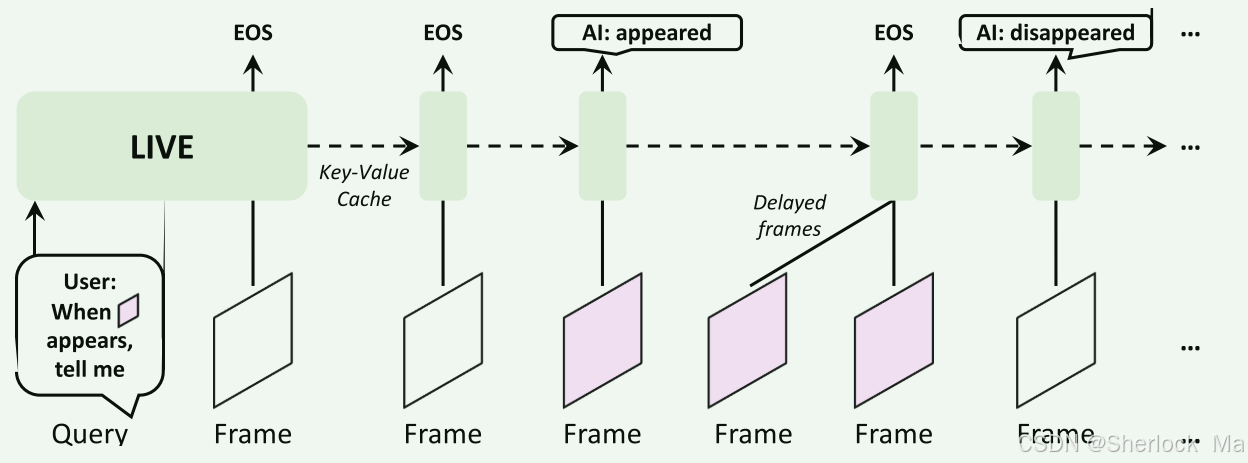
KV Cache
在推理过程中,视频作为逐帧流输入,默认FPS为2。模型将当前帧作为输入,并在运行中生成token。模型在输入过程中保持连续的KV Cache,以加快推理速度。此外,作者并行化快速视频帧编码器和较慢的语言模型,以避免后者的瓶颈。视频帧令牌可以一直被编码和缓冲,无需等待语言解码。
在代码层次,这里其实就是将LLM的use_cache设置为True,这时模型推理的输入就是单个Token。单个Token的Key和Value会与之前缓存的在变量past_key_value中的Key和Value进行torch.cat()拼接操作得到完整Key,Value序列。这些值可以在后续的解码步骤中被重用,以加速生成过程。代码详情请看LiveLlamaForCausalLM
实验部分就不多介绍了,感兴趣的读者请自行查看
3.代码解析
环境配置
使用Python3.10以上的版本
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1295
1295




 到【灌水乐园】发言
到【灌水乐园】发言







