




1、概述
简介
CogVideoX是智谱开放平台中最新上线的视频模型,现已支持文生视频、图生视频多个能力,让用户可以在开放平台使用和调用视频模型能力,轻松高效地完成艺术视频创作。体验中心支持多种生成方式,包括文本生成视频、图片生成视频,可应用于广告制作、电影剪辑、短视频制作等领域。
相关演示信息可查看github主页


历史版本信息
2022/5/19: 开源了 CogVideo 视频生成模型,这是首个开源的基于 Transformer 的大型文本生成视频模型,发表于 ICLR'23 论文 。2024/8/6: 开源 CogVideoX 系列视频生成模型的第一个模型, CogVideoX-2B。2024/8/27: 开源 CogVideoX 系列更大的模型 CogVideoX-5B 。2024/9/19: 开源 CogVideoX 系列图生视频模型 CogVideoX-5B-I2V 。该模型可以将一张图像作为背景输入,结合提示词一起生成视频,具有更强的可控性。
本篇博客将主要介绍CogvideoX-5B、CogVideoX-5B-I2V的文生视频及图生视频的功能。
具体配置要求

官方链接
体验平台:智谱清言
Github链接:https://github.com/THUDM/CogVideo
modelscope链接:魔搭社区(5b-I2V),魔搭社区(5b)
论文地址:https://arxiv.org/pdf/2408.06072
官方飞书文档:Docs
2、论文
这篇论文其实并没有提供太多的信息,个人建议想要学习的朋友还是着眼于代码,论文和代码同时理解。
整体其实是diffusion结构,不过论文中没有提,论文中提到的整体架构其实是Diffusion的去噪模型,也就是使用VAE+Transformer进行去噪处理。
去噪模块
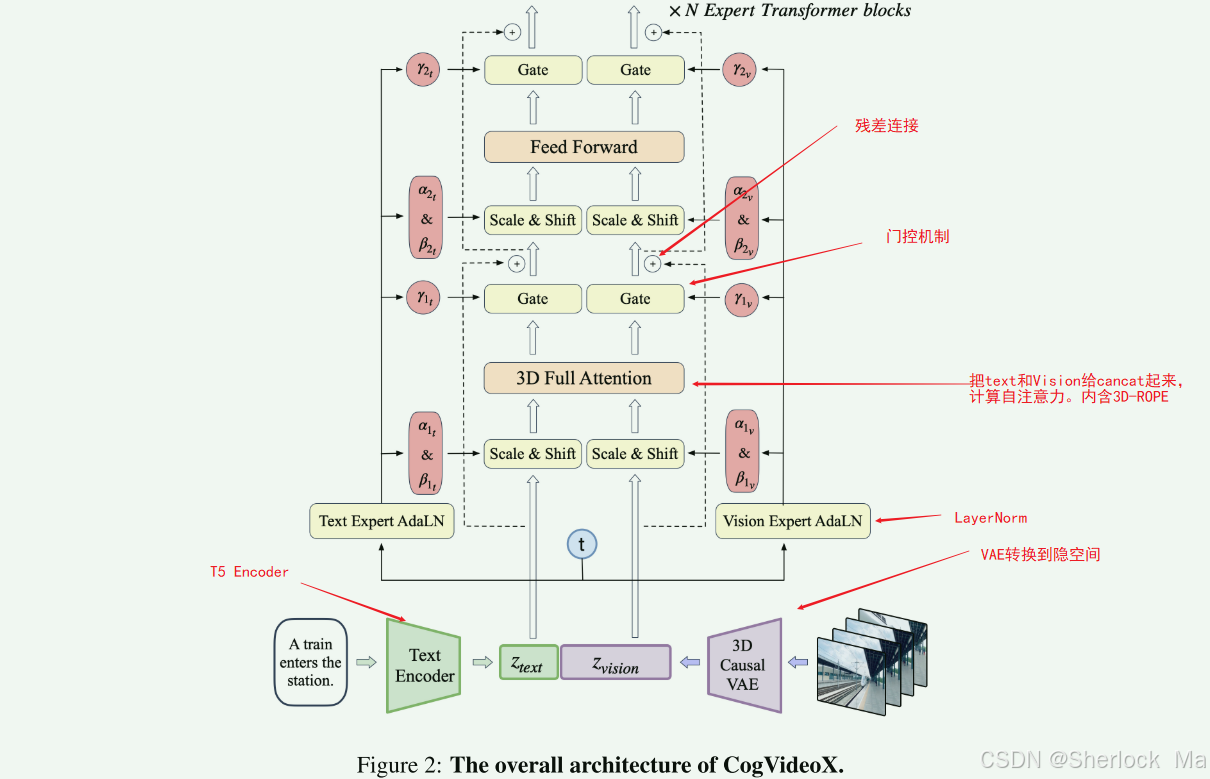
Transformer的整体架构如下,和其他的Transformer没有太大区别,主要增加了Gate(门控机制),将attention替换为3D Full Attention,并加入了3D-ROPE,虽然看起来是新东西,解析代码可知,这个attention其实是将text和Vision的隐空间concat起来,然后计算多头自注意力。
VAE
图3a所展示的VAE(变分自编码器)架构图,为我们揭示了CogVideoX模型中视频数据压缩与重建的核心机制。这一过程涉及到精心设计的上采样(upsampling)和下采样(downsampling)步骤,它们都是基于ResNet架构的改进版本,以适应视频数据的三维特性。
下采样过程(Encoder)
-
视频压缩:Encoder的职责是将输入的视频数据从原始的高分辨率和高帧率压缩到更低的维度。具体来说,它将视频的空间维度从
压缩到
,时间维度从4f+1压缩到f。这一压缩比例大约是4×8×8=256倍,有效地减少了数据量,为后续的处理降低了计算成本。
-
转换到隐空间:压缩后的视频数据被进一步转换到一个隐空间,这个空间捕获了视频的潜在特征。在这个空间中,视频数据被编码为一个潜在表示,这个表示将用于控制视频的生成过程。
上采样过程(Decoder)
-
视频重建:在视频生成的最后阶段,Decoder负责将隐空间中的潜在表示还原回原始的视频空间。它通过上采样过程逐步恢复视频的空间和时间维度,最终生成与输入视频具有相同分辨率和帧率的视频。
-
细节恢复:Decoder的设计确保了在重建过程中,视频的细节和动态变化得以保留。通过精心设计的网络结构,Decoder能够从潜在表示中恢复出丰富的视觉内容,包括颜色、纹理、运动等。
论文中f+1的1为什么要单独编码?
作者回复的答案:因为这个vae模型是从图像的vae迁移过来的,所有图像的vae不适合直接压视频。如果我们把这个1单独编码,其实相当于把第一帧重复成4帧,这样做编码,这样就可以尽可能保留vae原来的预训练能力,也保留第一帧中的视频内容,换句话说,压缩的效果更好。
我的理解:
- VAE最初是为图像设计的,它能够将图像数据压缩到一个潜在空间,并从这个空间重建图像。图像是二维数据,只有空间信息(高度和宽度)。直接将图像VAE应用于视频会导致不匹配,因为视频包含时间维度上的变化。
- 单独编码这一额外帧的原因是,这样做可以模拟视频的时间连续性,即使VAE模型原本是为处理图像设计的。通过这种方式,模型能够更好地处理视频数据,同时保留其在图像上预训练的能力。
- 将第一帧重复成四帧,意味着在时间维度上复制第一帧,从而在VAE的潜在空间中为视频建立一个起点。这样做可以帮助模型在生成视频时保持第一帧的内容和特征,这对于视频的连贯性和质量至关重要。
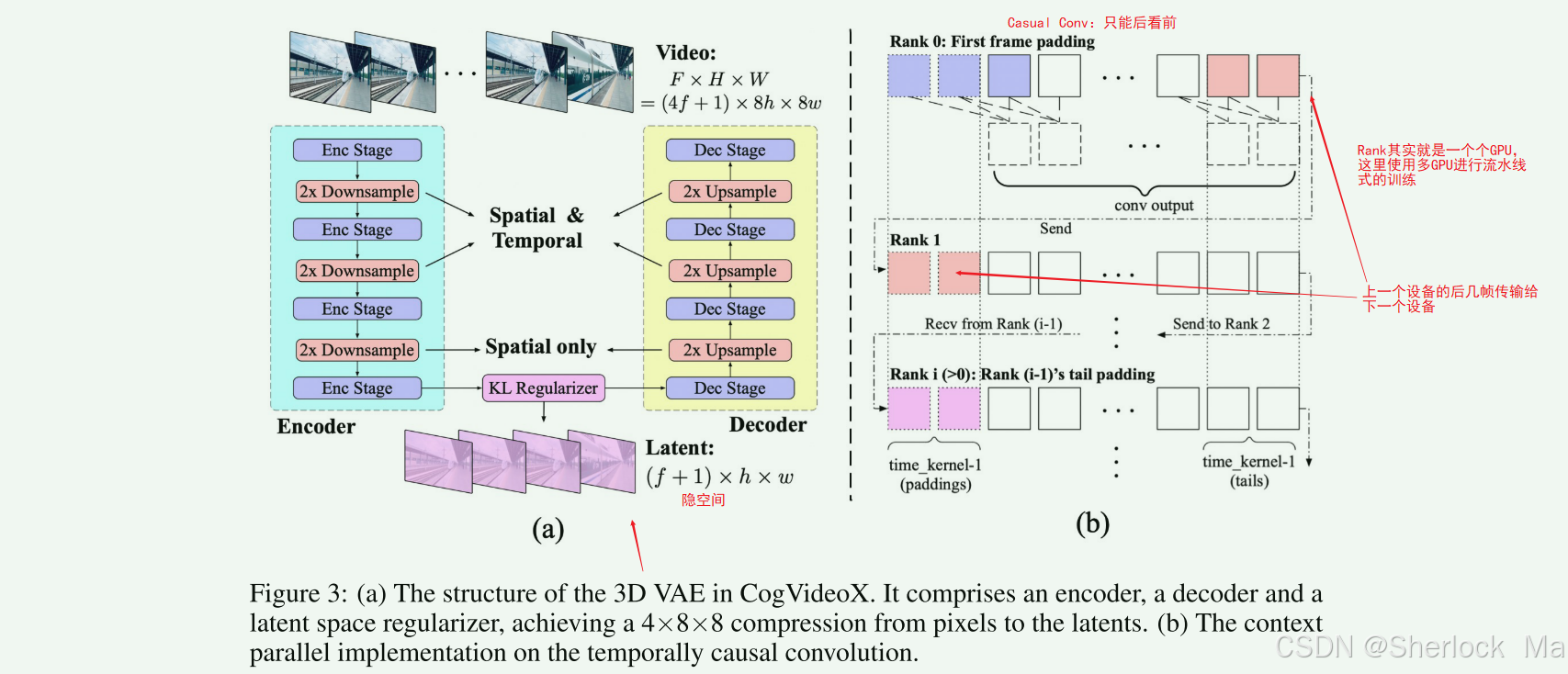
因果卷积(Casual Conv)
图3b展示的是因果卷积,即在每个时间步,因果卷积只考虑当前和之前的帧,而不包括未来的帧。这可以通过在卷积操作中使用特定的填充(padding)策略来实现,确保未来信息不会“泄露”到当前的预测中。
多GPU流水线式运行
图3b展示了这部分内容。具体来说,在训练过程中将这些视频分割为很多段,每段分配到多个处理单元(如GPU)。每个处理单元(或称为rank)处理一个数据段,并且只将其处理结果的最后几帧发送给下一个处理单元。
所有单元并行运行,以流水线的形式运作,即GPU0处理第1个片段,处理完后把最后几帧传给GPU1,GPU1开始处理第2个片段,同时GPU0开始处理第k个片段。
数据收集:
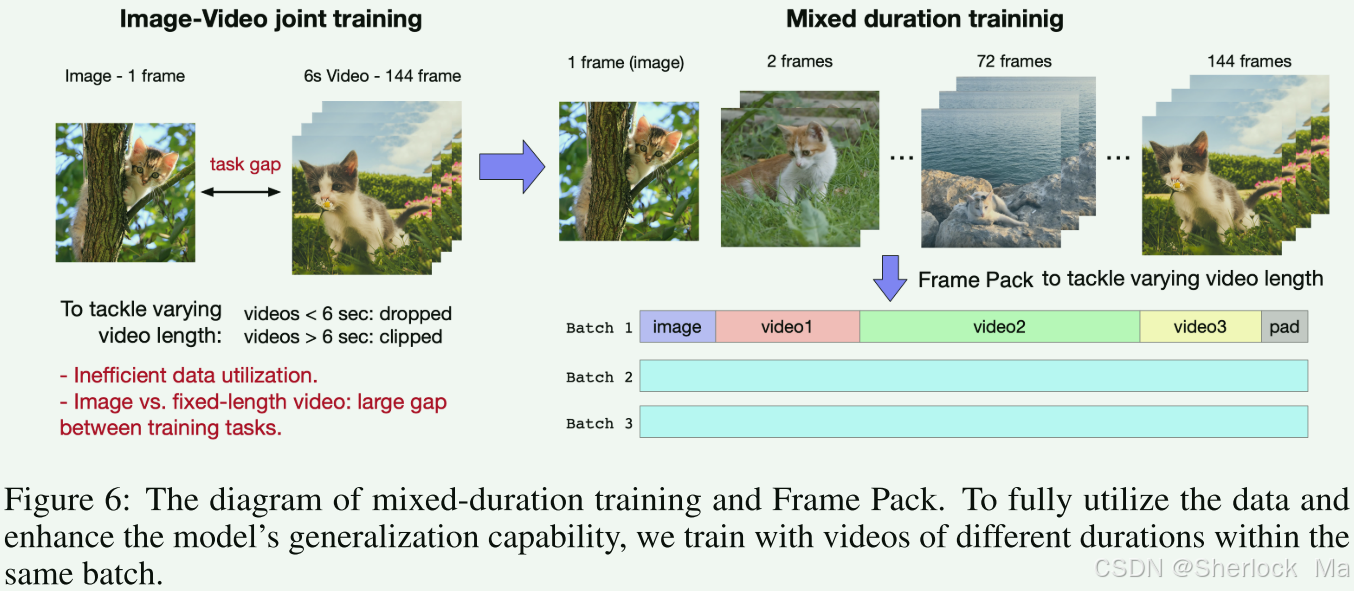
Frame Pack
在标准的深度学习训练中,一个批次内的所有样本通常需要具有相同的形状,以便于并行处理。然而,视频数据通常由不同长度的帧序列组成,这导致了直接处理上的困难。
为了解决这个问题,Frame Pack技术通过将不同长度的视频帧序列填充到相同的长度,使得它们可以被一起处理。具体来说,它通过创建一个虚拟的批次,其中每个视频帧序列都被填充或截断到一个预定的最大长度(图像算1帧视频)。这样,即使原始视频帧数不同,经过Frame Pack处理后,它们在每个批次中都具有相同的维度,从而可以被模型并行处理。
3、代码
环境配置
下载权重及代码,注意检查是不是下全了,尤其是权重。
git clone https://github.com/THUDM/CogVideo
git clone https://modelscope.cn/models/ZhipuAI/CogVideoX-5b把项目文件放在一起,权重位置决定下文的model_path怎么写,列如我是这样的,我的model_path就是CogVideoX-5b
conda新建环境,注意必须是Python3.10-3.12的版本,torch版本为2.4
然后安装所需库
pip install -r requirements.txt注意需要保证diffusers库的版本,要随着版本不断更新,目前已经更新到0.30.3,如果发布0.31.0,还需要继续更新。
pip install diffusers==0.30.3代码讲解
作者提供了一个演示文件cli_demo.py,所有操作通过diffusers库调用。
cli_demo.py
具体来说,这个代码提供了如下的参数供用户调节。
parser.add_argument("--prompt", type=str, required=True, help="The description of the video to be generated")
parser.add_argument(
"--image_or_video_path",
type=str,
default=None,
help="The path of the image to be used as the background of the video",
)
parser.add_argument(
"--model_path", type=str, default="CogVideoX-5b", help="The path of the pre-trained model to be used"
)
parser.add_argument("--lora_path", type=str, default=None, help="The path of the LoRA weights to be used")
parser.add_argument("--lora_rank", type=int, default=128, help="The rank of the LoRA weights")
parser.add_argument(
"--output_path", type=str, default="outputs/output_br.mp4", help="The path where the generated video will be saved"
)
parser.add_argument("--guidance_scale", type=float, default=6.0, help="The scale for classifier-free guidance") # 用于调整生成过程中条件信息(如文本描述)对生成结果的影响程度。
parser.add_argument(
"--num_inference_steps", type=int, default=50, help="Number of steps for th 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 631
631







 到【灌水乐园】发言
到【灌水乐园】发言







