







 本文探讨了如何优化深度学习中的卷积层,提出Factorized Convolutional Neural Networks,通过基层、重叠基层和拓扑连接等方法减少计算复杂度,实现模型提速。实验结果显示,优化后的网络在保持与GoogLeNet、ResNet-18、VGG-16相当精度的同时,模型大小和计算量显著降低。
本文探讨了如何优化深度学习中的卷积层,提出Factorized Convolutional Neural Networks,通过基层、重叠基层和拓扑连接等方法减少计算复杂度,实现模型提速。实验结果显示,优化后的网络在保持与GoogLeNet、ResNet-18、VGG-16相当精度的同时,模型大小和计算量显著降低。
Wang, Min, Baoyuan Liu, and Hassan Foroosh. “Factorized Convolutional Neural Networks.” arXiv preprint arXiv:1608.04337 (2016).
本文着重对深度网络中的卷积层进行优化,独特之处有三:
- 可以直接训练。不需要先训练原始模型,再使用稀疏化、压缩比特数等方式进行压缩。
- 保持了卷积层原有输入输出,很容易替换已经设计好的网络。
- 实现简单,可以由经典卷积层组合得到。
使用该方法设计的分类网络,精度与GoogLeNet1, ResNet-182, VGG-163相当,模型大小仅2.8M。乘法次数 470 × 1 0 9 470\times 10^9 470×109,只有AlexNet4的65%。
#标准卷积层
先来复习一下卷积的运算过程。标准卷积将3D卷积核(橙色)放置在输入数据 I I I(左侧)上,对位相乘得到输出 O O O(右侧)的一个像素(蓝色)。
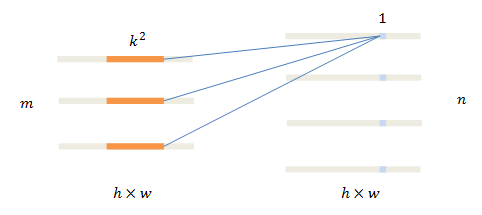
卷积核在一个通道上的尺寸为 k 2 k^2 k2,输入、输出通道数分别为 m , n m,n m,n。
当下流行的网络中,卷积层的主要作用是提取特征,往往会保持图像尺寸不变。缩小图像的步骤一般由pooling层实现。为书写简洁,这里认为输入输出的尺寸相同,都是 h × w h\times w h×w。
计算一个输出像素所需乘法次数为:
k 2 × m k^2\times m k2×m
总体乘法次数为:
k 2 × m × n × h × w k^2\times m \times n \times h\times w k2×m×n×h×w
m , n m,n m,n体现了对于特征的挖掘,取值较大,常为几百;相反, k k
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 787
787

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









