




开启 GPU 存储探索系列
终于要开启我此前一直不敢触碰的 GPU 存储系列了。先放一张图,把核心关系直观呈现出来,以此作为这个系列的起点,并以此纪念。
AMD的显卡和计算卡驱动中的buffer object(BO)实现,是学习gem和ttm技术使用的完美教程。欢迎想理解和学习这些技术的驱动开发人员一起探讨(请点击文末社区链接,入群探讨与学习)。
注:图中 “kfdm_mm” 为笔误,正确应为 “kgd_mem”,此处不做修改,还望大家理解。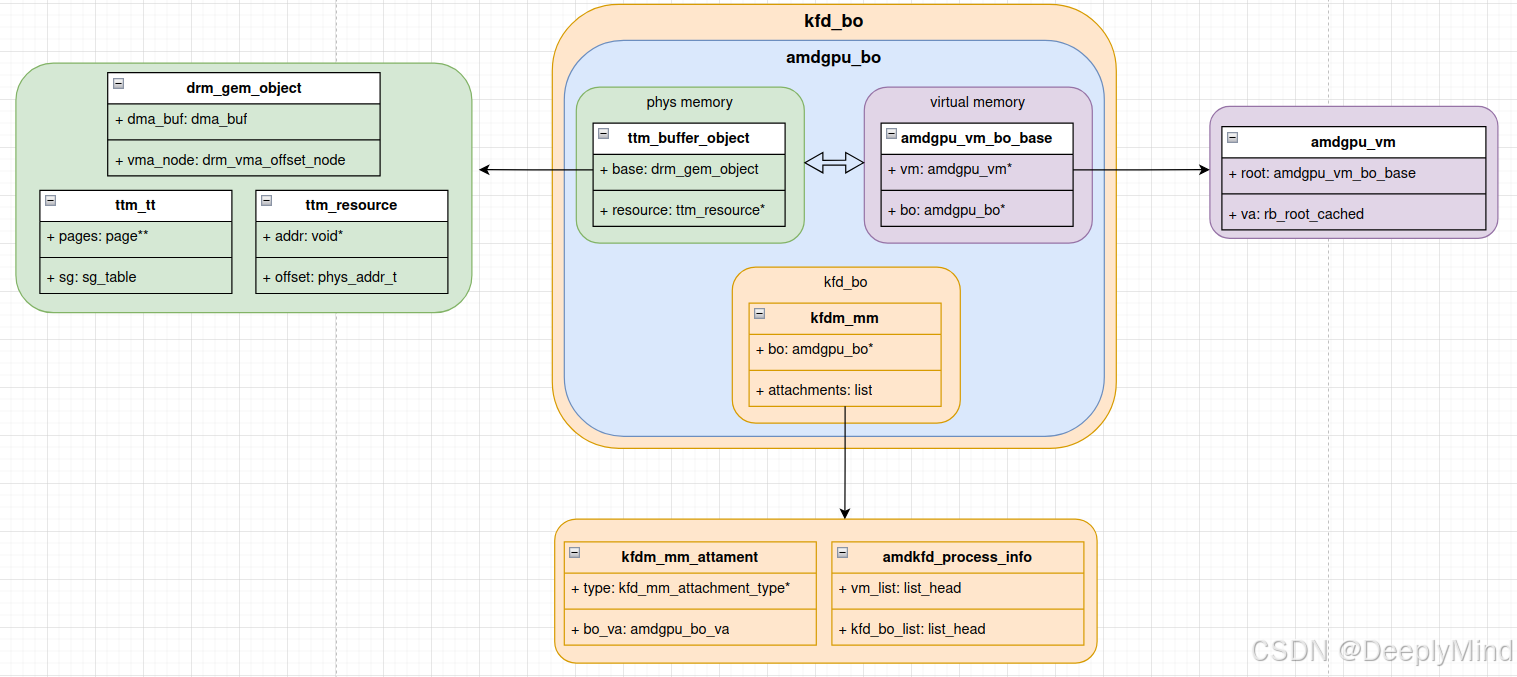
对这个图做个简单解释:一个BO有两部分组成:虚拟地址部分和物理地址部分。
对于普通用户态应用程序,其访问的变量地址均为进程独立的虚拟地址。该虚拟地址通过内存管理单元(MMU)的映射机制,关联到实际的物理内存地址 —— 即 CPU 可直接寻址的物理地址。
在涉及 GPU 的应用场景中,BO需支持 CPU 访问、GPU 访问及 DMA 访问等多场景需求,不同访问者(CPU、GPU、DMA)基于自身的地址映射体系,形成了对同一 BO 的不同地址视角,即对应不同的地址空间。本系列重点聚焦于 GPU 访问视角下的地址空间相关机制和实现。CPU视角就是mmap技术,具体请查看专栏:linux drm子系统专栏介绍 。
-
虚拟地址部分(VA, Virtual Address):由 GPU 虚拟地址空间相关的结构体(如 amdgpu_vm、amdgpu_bo_va、amdgpu_bo_va_mapping 等)管理,负责描述和维护 BO 在 GPU 虚拟空间中的信息。
-
物理地址部分(PA, Physical Address):由 TTM 框架相关结构体(如 ttm_resource、ttm_tt)管理,负责分配和维护 BO 实际对应的物理存储区域(如 VRAM、GTT)。
BO 通过将虚拟地址部分和物理地址部分结合,实现了 GPU 存储对象的完整抽象。再加上 VA 和 PA 各自的管理器,以及两者之间的映射关系结构体,构成了 GPU 存储系统的整体实现框架。这种设计既保证了虚拟空间的灵活映射,也确保了物理资源的高效分配与管理。
本专栏涉及的概念和代码都很多,整个系列最好按我给出的顺序阅读,因为我按照最佳实践对文章进行了排序。通常,每篇博文中都会有承前启后的文档链接。请关注这些链接。
Let's go, enjoy the journey.
对于从事GPU驱动开发或者图形、计算应用的开发人员,对BO的概念有一个较清晰的认识的话,可以直接从框架分析入手。链接如下:
对于还不熟悉BO的朋友,可以从BO的基本概念入手。链接如下:
AMD KFD的BO设计分析系列:Buffer Object概览
当然,最后是殊途同归,理论指导实践,实践验证理论。
技术交流,欢迎加入社区:GPUers。


















 918
918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











