



业务侧的一个实例在Windows2008上,一直正常运行,未开归档、无备份的情况,突然断电重启后实例宕机。提示控制文件丢失后,手动从trace文件中重建后修复01113,记录修复过程。
问题概述
Windows2008R2的环境, Oracle 11g,版本11.0.2.4,
现场情况为:未开归档、无备份、强行断电关机后,出现ORA-01113 ORA-01110;
1、startup 提示控制文件丢失,
2、通过trace文件重建了控制文件,
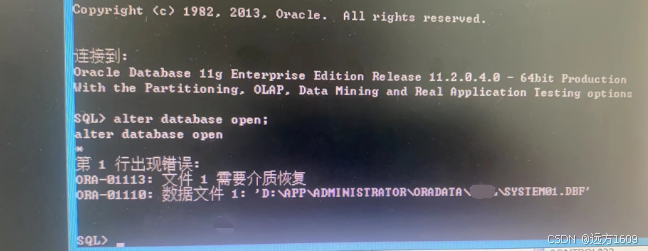
3、重新开库,提示ORA-01113 ORA-01110,system01.dbf需要media recovery
数据库启动时出现错误:
- ORA-01113: file 1 needs media recovery
- ORA-01110: data file 1: D:\APP\ADMINISTRATOR\ORADATA\orcl\system01.dbf'根本原因为系统表空间文件(SYSTEM01.DBF)损坏,需要介质恢复。
错误原因
- 根本原因:数据文件头(Header)记录的检查点SCN(System Change Number)与控制文件记录的该数据文件的检查点SCN不一致,或者数据文件头损坏。
- 常见触发场景:
- 数据文件未正常离线(如实例崩溃、存储异常断电)。
- 数据文件被意外删除或覆盖。
- 存储介质损坏导致数据文件块损坏(特别是文件头块)。
- 恢复过程中断或不完整(如恢复时缺少归档日志或在线日志)。
技术原理
Oracle数据库在打开数据库时,会进行以下检查:
- 检查点同步:确保所有数据文件的检查点SCN与控制文件记录的检查点SCN一致(即数据文件与控制文件同步)。
- 文件状态:检查数据文件状态是否为ONLINE且不需要恢复。
当某个数据文件的检查点SCN低于控制文件记录的SCN时,该数据文件需要介质恢复(Media Recovery),即应用重做日志(Redo Log)将数据文件推进到与控制文件相同的SCN。
如果出现ORA-01113,通常意味着:
- 数据文件头损坏,无法读取检查点SCN。
- 数据文件缺失(或路径错误)。
- 数据文件来自备份,且未应用足够的重做日志。
记录步骤(按照顺序)
第一步:常规介质恢复
-- 启动到mount状态
STARTUP MOUNT;
-- 尝试恢复损坏的数据文件
ALTER DATABASE RECOVER DATAFILE 'D:\APP\ADMINISTRATOR\ORADATA\orcl\system01.dbf';
-- 验证恢复结果
ALTER DATABASE OPEN;
验证脚本:
SELECT FILE#, STATUS, ERROR FROM V$RECOVER_FILE;
第二步:使用隐含参数强制打开(谨慎使用)
若常规恢复失败,修改参数跳过一致性检查:
ALTER SYSTEM SET "_allow_resetlogs_corruption"=TRUE SCOPE=SPFILE;
ALTER SYSTEM SET "_allow_error_simulation"=TRUE SCOPE=SPFILE;
SHUTDOWN IMMEDIATE;
STARTUP MOUNT;
ALTER DATABASE OPEN RESETLOGS;
验证脚本:
SHOW PARAMETER "_allow_resetlogs_corruption"; -- 检查参数是否生效
第三步:重建控制文件
当文件列表完整时重建控制文件:
CREATE CONTROLFILE REUSE DATABASE "ORCL" RESETLOGS ARCHIVELOG
MAXLOGFILES 96
MAXLOGMEMBERS 3
MAXDATAFILES 1024
LOGFILE
GROUP 1 'D:\APP\ADMINISTRATOR\ORADATA\orcl\redo01.log' SIZE 50M,
... -- 完整列出所有REDO日志组
DATAFILE
'D:\APP\ADMINISTRATOR\ORADATA\orcl\system01.dbf',
... -- 完整列出所有数据文件
CHARACTER SET ZHS16GBK;
验证脚本:
SELECT NAME FROM V$DATAFILE; -- 检查文件是否全部识别
第四步:推进SCN(极端情况以下为举例)
若SCN不一致导致无法打开:
-- 获取最高SCN并计算新值
SELECT MAX(CHECKPOINT_CHANGE#) FROM V$DATAFILE_HEADER;
-- 计算新SCN(示例增加1000000)
SELECT TO_CHAR(1049041170 + 1000000, 'XXXXXXXX') FROM DUAL; -- 输出3E965B52
-- 修改内存SCN
ORADEBUG SETMYPID
ORADEBUG POKE 0x06001AE70 8 0x3E965B52 -- 地址需根据实际调整
-- 强制打开
ALTER DATABASE OPEN RESETLOGS;
验证脚本:
ORADEBUG DUMPVAR SGA kcsgscn_ -- 检查SCN是否更新
第五步:禁用事务恢复
添加事件参数阻止SMON恢复:
ALTER SYSTEM SET EVENT='10513 TRACE NAME CONTEXT FOREVER, LEVEL 2' SCOPE=SPFILE;
ALTER SYSTEM SET UNDO_MANAGEMENT=MANUAL SCOPE=SPFILE;
SHUTDOWN IMMEDIATE;
STARTUP;
第六步:重建UNDO和TEMP表空间
CREATE UNDO TABLESPACE UNDOTBS2 DATAFILE 'D:\APP\ADMINISTRATOR\ORADATA\orcl\undotbs02.dbf' SIZE 10G;
CREATE TEMPORARY TABLESPACE TEMP_NEW TEMPFILE 'D:\APP\ADMINISTRATOR\ORADATA\orcl\temp01.dbf' SIZE 20G;
ALTER SYSTEM SET UNDO_TABLESPACE='UNDOTBS2' SCOPE=BOTH;
ALTER DATABASE DEFAULT TEMPORARY TABLESPACE TEMP_NEW;
最终验证
-- 检查数据库状态
SELECT OPEN_MODE, DATABASE_ROLE FROM V$DATABASE;
-- 检查文件状态
SELECT FILE#, NAME, STATUS FROM V$DATAFILE WHERE FILE#=1;
关键注意事项
- 备份优先执行任何操作前必须备份:(Linux和Windows拷贝命令不一样哈)
# 物理备份关键文件
copy ${ORACLE_BASE}\oradata\orcl\*.dbf \backup
copy ${ORACLE_HOME}\dbs\spfileorcl.ora \backup
- 操作风险
- 隐含参数和SCN推进可能导致数据逻辑损坏
- RESETLOGS后原有备份不可用
- 成功打开后需立即导出数据并重建数据库
- 自动化检查脚本
-- 检查损坏块
ANALYZE TABLE SYS.OBJ$ VALIDATE STRUCTURE CASCADE;
--Table analyzed.
-- 检查事务一致性
SELECT KTUXEUSN, KTUXESIZ FROM X$KTUXE WHERE KTUXECFL='DEAD';
SYS@CDB$ROOT> SELECT KTUXEUSN, KTUXESIZ FROM X$KTUXE WHERE KTUXECFL='DEAD';
no rows selected
- 手册最佳建议优先使用RECOVER DATAFILE和RMAN恢复:
--示例
rman target /
RMAN> RECOVER DATAFILE 1;
最后的最后,最后开库成功:
成功打开数据库后,使用expdp或exp全库导出同时也用工具连接导出可以插入的sql文件,迁移到新库。杜绝继续在生产环境使用修复后的库。

















 4271
4271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









