



 本文介绍了正则表达式的概述,包括定义和常见元字符,重点讲解了grep命令的使用,如grep的介绍、常用选项及其在shell脚本中的应用案例,展示了如何通过grep配合正则表达式在Linux环境中进行文本搜索和处理。
本文介绍了正则表达式的概述,包括定义和常见元字符,重点讲解了grep命令的使用,如grep的介绍、常用选项及其在shell脚本中的应用案例,展示了如何通过grep配合正则表达式在Linux环境中进行文本搜索和处理。
目录
1.正则表达式的概述
1.概述
2.正则表达式定义
3.常见的元字符(支持的工具:grep、egrep、sed、和awk)
4.扩展正则表达式元字符(支持egrep、awk)
2.grep命令
1.grep的介绍
2.案例
1.正则表达式的概述
1.概述
通常用于判断语句中,用来检查某一个字符串是否满足某一格式。
正则表达式是由普通字符与元字符组成。
普通字符:包括大小写字母、数字、标点符号及一些其他符号;
元字符:是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式。
Linux中常用的有两种正则表达式引擎:
基础正则表达式:BRE
扩展正则表达式:ERE
2.正则表达式定义
(1)正则表达式,又称正规表达式、常规表达式;
(2)使用字符串来描述、匹配一系列符合某个规则的字符串;
(3)正则表达式组成:普通字符与元字符
正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本,正则表达式不只有一种,而且 Linux 中不同的程序可能会使用不同的正则表达式。
3.常见的元字符(支持的工具:grep、egrep、sed、和awk)
基础正则表达式是常用的正则表达部分,除了普通的字符外,常见到以下元字符。
| 元字符 | 作用 | 案例 |
| \ | 转义字符,用于取消特殊符号的含义 | !,\n,$ |
| ^ | 匹配字符串开始的位置 | a,the,#,[a-z] |
| $ | 匹配字符串结束的位置 | wordKaTeX parse error: Expected group after '^' at position 2: ,^̲匹配空行 |
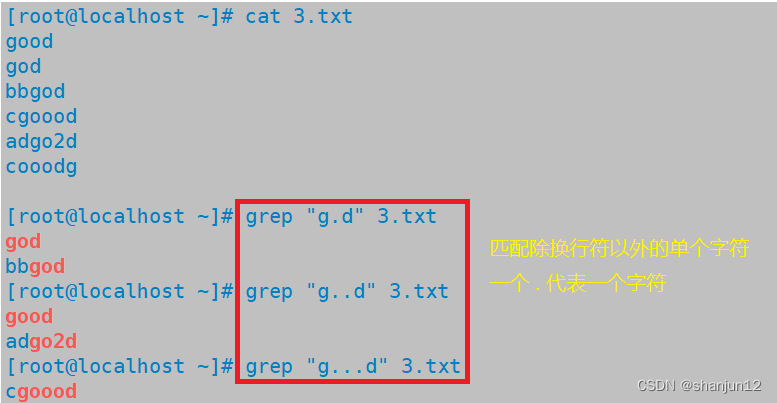
| . | 匹配除\n之外的任何一个字符 | go.d , g…d |
| * | 匹配前面子表达式0次或者多次 | goo*d,go.*d |
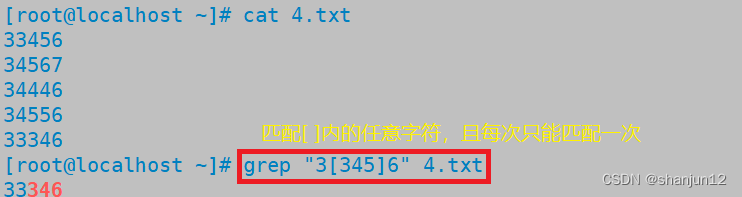
| [list] | 匹配list列表中的一个字符 | go[loa]d,[a-z],[0-9]匹配任意一位数字 |
| [^list] | 匹配任意非list列表中的一个字符 | [0-9],[a-z]匹配任意一位非小写字母 |
| {n} | 匹配前面子表达式n次 | go{2}d,'[0-9]{2}'匹配两位数字 |
| {n,} | 匹配前面子表达式至少n次 | go{2,}d,'[0-9]{2,}'匹配两位及两位以上的数字 |
| {,n} | 匹配前面子表达式最多n次 | go{,2}d,'[0-9]{,2}'匹配最多两位的数字 |
| {n,m} | 匹配前面子表达式n到m次 | go{2,3}d,'[0-9]{2,3}'匹配两位到三位数字 |
注意:
1.egrep,awk使用{n}、{n,}、{n,m} 匹配时“{}”前面不用加“\”
2. egrep -E -n 'wo{2}d' test.txt1/-E用于显示文件中符合条件的字符
3.egrep -E -n 'wo{2,3}d' test.txt
(1)^表示匹配字符串开始的位置,匹配行首
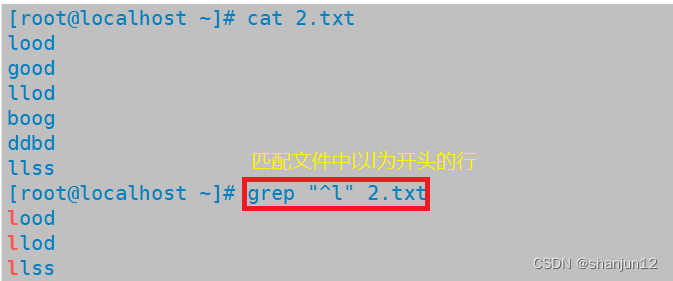
(2)$表示匹配字符串末尾的位置,匹配行尾

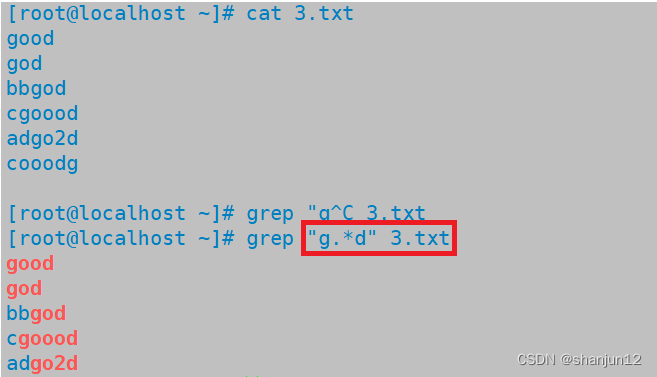
(3)*匹配前面子表达式0次或者多次

(4) . 匹配除\n之外的任意一个字符
(5).*表示任意长度的任一字符
(6) [ ] 表示匹配[ ]中包含的任一字符
(7)[ ^ ] 表示匹配除[ ]中包含的任一字符
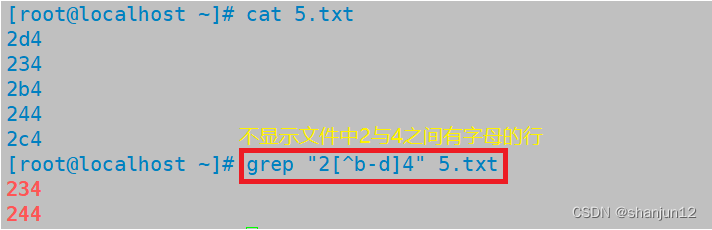
(8) \{n\} 匹配前面的子表达式n次

(9) \{n,\} 匹配前面的子表达式不少于n次

(10) \{n,m\} 匹配前面的子表达式n到m次

4.扩展正则表达式元字符(支持egrep、awk)
| 元字符 | 作用 | 案例 |
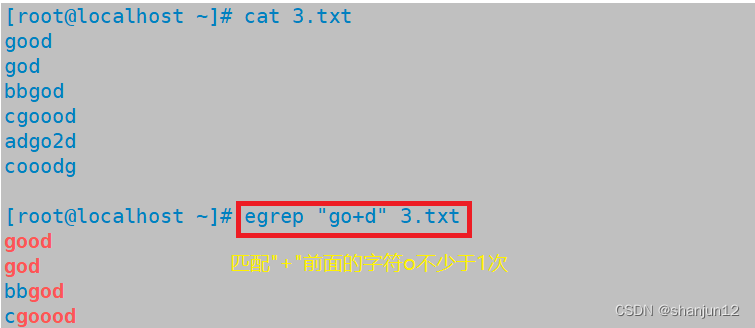
| + | 匹配前面子表达式一次以上 | go+d,将匹配至少一个o,如god,good,goood等 |
| ? | 匹配前面子表达式0次或一次 | go?d,匹配将为gd或者god |
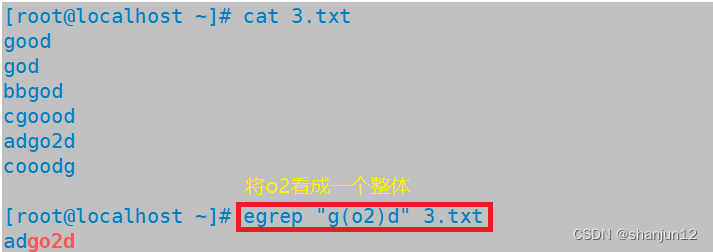
| () | 将括号内的字符创作为一个整体 | g(oo)+d,将匹配oo整体一次以上 |
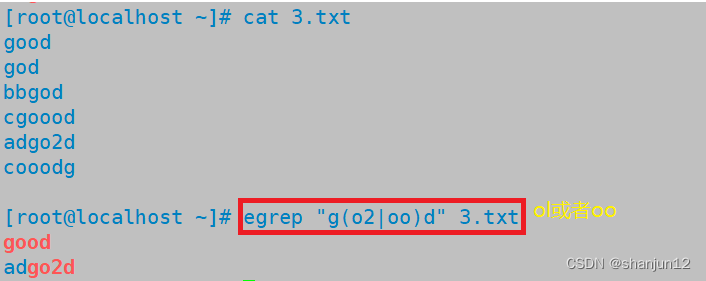
| | | 以或的方式匹配字符条串 | g(oo l la)d,将匹配good或glad |
定位符
^ 匹配输入字符串开始的位置
$匹配输入字符串结尾的位置
非打印字符
\n匹配一个换行符
\r匹配一个回车符
\t匹配一个制表符
(1) + 表示匹配前面的子表达式1次以上
(2) ? 表示匹配前面的子表达式0或者1次

(3)()将括号里的内容看成一个整体
(4)| 以或的方式匹配字符串
2.grep命令
1.grep的介绍
grep命令使用正则表达式来搜索文本,并且把匹配的文本打印出来。grep (global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。Unix的grep家族包括grep、egrep和fgrep。egrep和fgrep的命令只跟grep有很小不同。egrep是grep的扩展,支持更多的re元字符,fgrep就是fixed grep或fastgrep,它们把所有的字母都看作单词,也就是说,正则表达式中的元字符表示回其自身的字面意义,不再特殊。linux使用GNU版本的grep。它功能更强,可以通过-G、-E、-F命令行选项来使用egrep和fgrep的功能。grep的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到标准输出,不影响原文件内容。grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。我们利用这些返回值就可进行一些自动化的文本处理工作。
格式:grep [options] pattern [file]
option表示选项,pattern表示匹配的模式。file表示一系列文件名。
常用选项:
-color=auto 对匹配到的文本着色显示
-m # 匹配#次后停止
grep -m 1 root /etc/passwd #多个匹配只取第一个
-v 显示不被pattern匹配到的行,即取反
grep -Ev '^[[:space:]]*#|^$' /etc/fstab
-i 忽略字符大小写
-n 显示匹配的行号
-c 统计匹配的行数
grep -c root /etc/passwd #统计匹配到的行数
-o 仅显示匹配到的字符串
-q 静默模式,不输出任何信息
-A # after, 后#行
grep -A3 root /etc/passwd #匹配到的行后3行业显示出来
-B # before, 前#行-C # context, 前后各#行
-e 实现多个选项间的逻辑or关系,如:grep –e ‘cat ' -e ‘dog' file
grep -e root -e bash /etc/passwd #包含root或者包含bash 的行
grep -E root|bash /etc/passwd
-w 匹配整个单词
grep -w root /etc/passwd
useradd rooter
-E 使用ERE,相当于egrep
-F 不支持正则表达式,相当于fgrep
-f file 根据模式文件,处理两个文件相同内容 把第一个文件作为匹配条件
-r 递归目录,但不处理软链接
-R 递归目录,但处理软链接
-a --text #不要忽略二进制的数据。 将 binary 文件以 text 文件的方式搜寻数据
-A<显示行数> --after-context=<显示行数> #除了显示符合范本样式的那一列之外,并显示该行之后的内容。
-b --byte-offset #在显示符合样式的那一行之前,标示出该行第一个字符的编号。
-B<显示行数> --before-context=<显示行数> #除了显示符合样式的那一行之外,并显示该行之前的内容。
-c --count #计算符合样式的行数。
-C<显示行数> --context=<显示行数>或-<显示行数> #除了显示符合样式的那一行之外,并显示该行之前后的内容。
-d <动作> --directories=<动作> #当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
-e<范本样式> --regexp=<范本样式> #指定字符串做为查找文件内容的样式。
-E --extended-regexp #将样式为延伸的普通表示法来使用。
-f<规则文件> --file=<规则文件> #指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
-F --fixed-regexp #将样式视为固定字符串的列表。
-G --basic-regexp #将样式视为普通的表示法来使用。
-h --no-filename #在显示符合样式的那一行之前,不标示该行所属的文件名称。
-H --with-filename #在显示符合样式的那一行之前,表示该行所属的文件名称。
-i --ignore-case #忽略字符大小写的差别。
-l --file-with-matches #列出文件内容符合指定的样式的文件名称。
-L --files-without-match #列出文件内容不符合指定的样式的文件名称。
-n --line-number #在显示符合样式的那一行之前,标示出该行的列数编号。
-q --quiet或–silent #不显示任何信息。
-r --recursive #此参数的效果和指定“-d recurse”参数相同。
-s --no-messages #不显示错误信息。
-v --revert-match #显示不包含匹配文本的所有行。
-V --version #显示版本信息。
-w --word-regexp #只显示全字符合的列。
-x --line-regexp #只显示全列符合的列。
-y #此参数的效果和指定“-i”参数相同。
–color=auto :可以将找到的关键词部分加上颜色的显示
2.案例
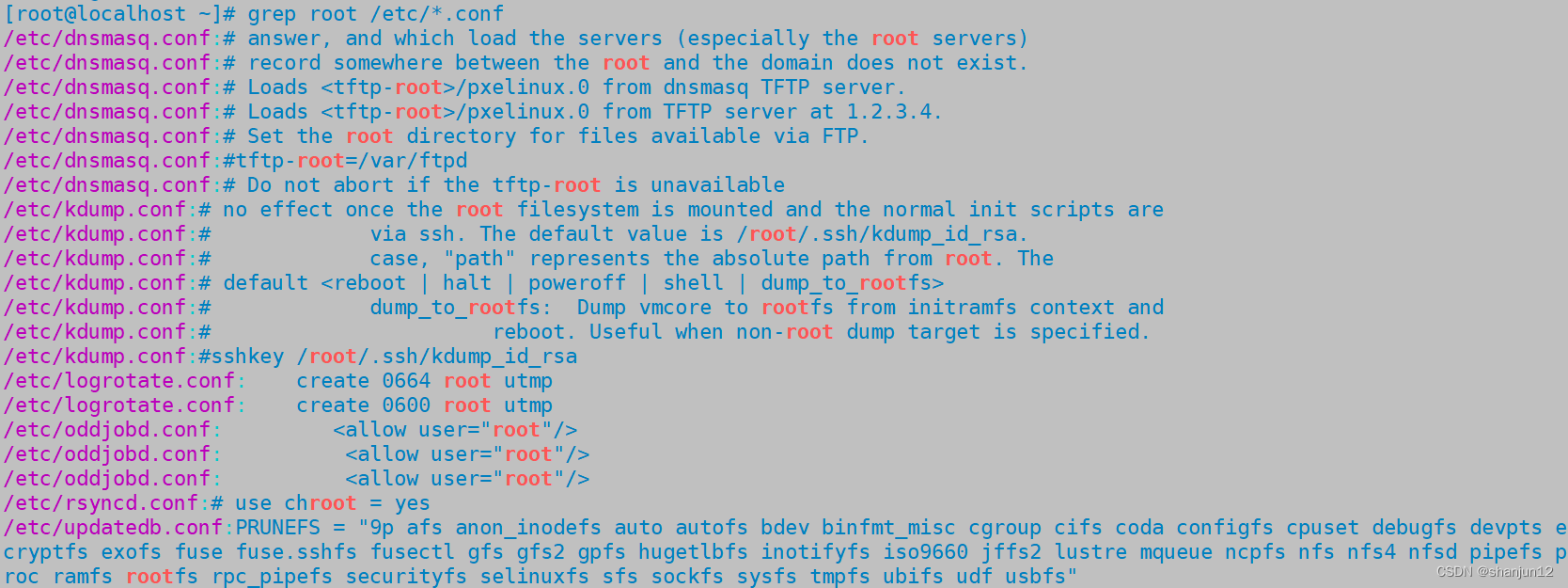
(1)过滤目录下以.conf结尾的文件中含root的文件
(2)grep -i:查找时忽略大小写

(3)grep -v:反向查找 过滤出没有的
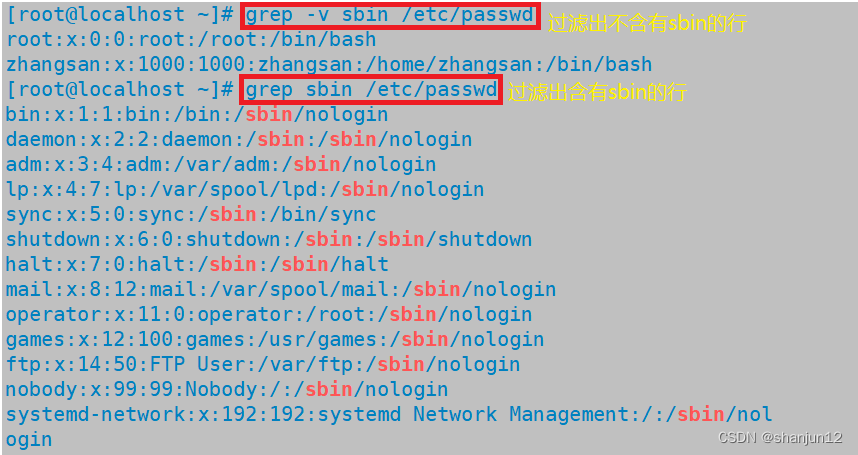
(4)grep -n :显示符合模式要求的行号。
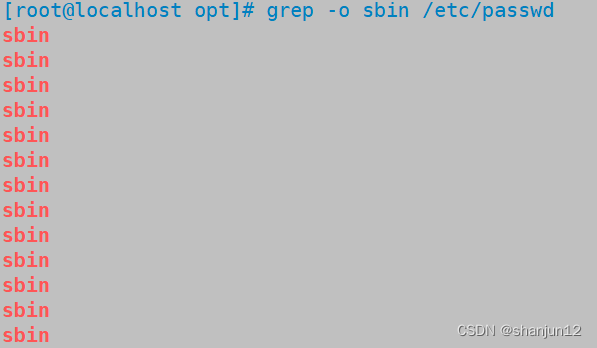
(5)grep -o:只显示匹配的行的内容
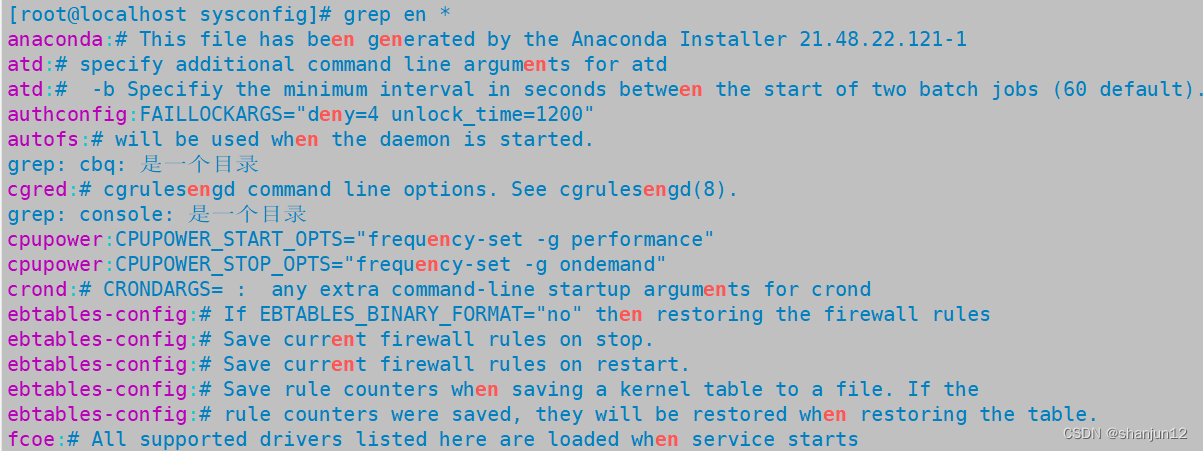
(5)grep -r:递归搜索所有文件以及目录下的所有子文件。(当前目录下)
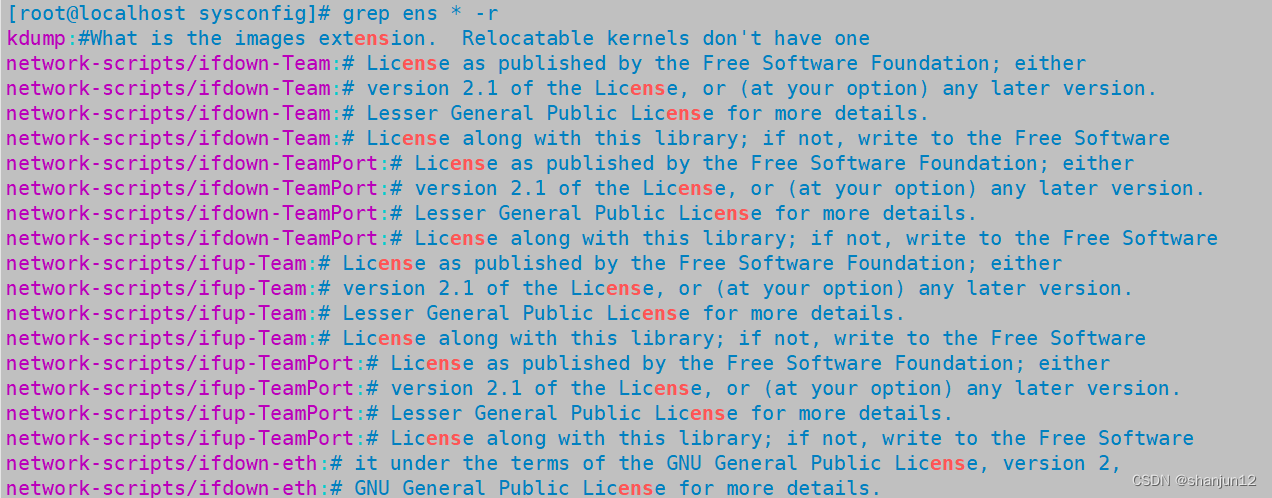
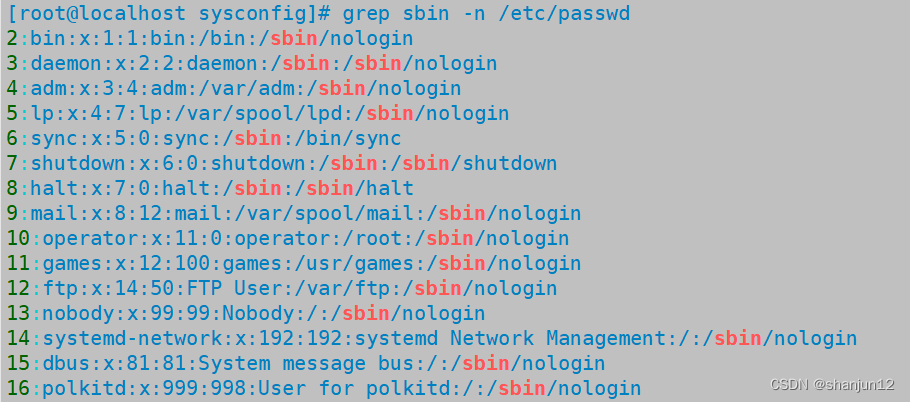
(6) grep sbin -n /etc/passwd #找到/etc/passwd里面的sbin 所在行,并显示行号
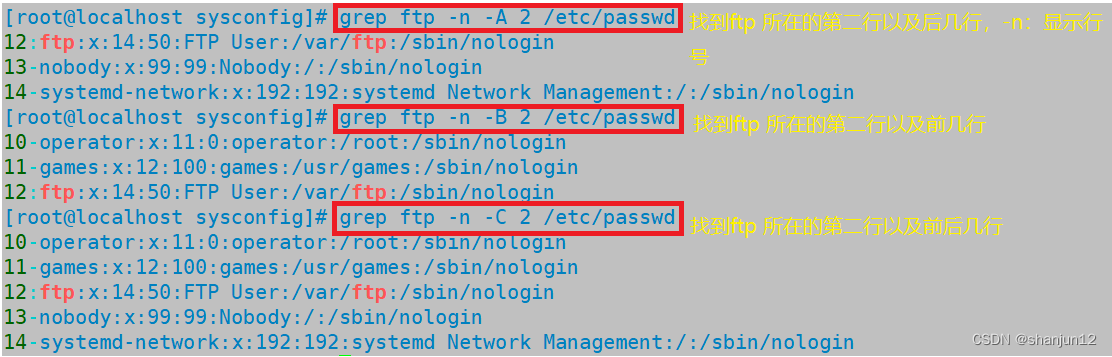
(7)grep -A:找到匹配的行以及后几行
grep -B:找到匹配的行以及前几行
grep -C:找到匹配的行以及前后几行

















 500
500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









