




 文章讨论了模型可解释性的挑战,介绍了CNN中的反卷积、导向反向传播和几种可视化方法(如CAM、Grad-CAM和ScoreCAM),以及它们的优势和局限性。着重讲解了如何通过这些方法理解模型决策背后的依据,以及Grad-CAM如何解决模型结构改动的问题。
文章讨论了模型可解释性的挑战,介绍了CNN中的反卷积、导向反向传播和几种可视化方法(如CAM、Grad-CAM和ScoreCAM),以及它们的优势和局限性。着重讲解了如何通过这些方法理解模型决策背后的依据,以及Grad-CAM如何解决模型结构改动的问题。
模型的可解释性问题一直是个关注的热点。注意,本文所说的“解释”,与我们日常说的“解释”内涵不一样:例如我们给孩子一张猫的图片,让他解释为什么这是一只猫,孩子会说因为它有尖耳朵、胡须等。而我们让CNN模型解释为什么将这张图片的分类结果为猫,只是让它标出是通过图片的哪些像素作出判断的。(严格来说,这样不能说明模型是否真正学到了我们人类所理解的“特征”,因为模型所学习到的特征本来就和人类的认知有很大区别。何况,即使只标注出是通过哪些像素作出判断就已经有很高价值了,如果标注出的像素集中在地面上,而模型的分类结果是猫,显然这个模型是有问题的)
可解释性和可视化有很大的区别,模型有很多的可视化方案:
直接可视化:最容易被想到的一种方式就是对特征图进行可视化,想法是对的,直接对 feature map 进行粗暴的 resize, 或者更为精细点的操作是进行反卷积,将 feature map 放大至和原图一样的大小,但是这样只能算是特征图的可视化,并非模型的可视化,模型的可视化要求其对分类有一定的解释性或者说依据。
CAM可视化:所以目前所说的模型可视化或者模型可解释说到是对某一类别具有可解释性,直接画出来特征图并不能说明模型学到了某种特征,这时候就用到了CAM(Class Activation Mapping)
1. 反卷积和导向反向传播
关于CNN模型的可解释问题,很早就有人开始研究了,姑且称之为CNN可视化吧。比较经典的有两个方法,反卷积(Deconvolution)和导向反向传播(Guided-backpropagation),通过它们,我们能够一定程度上“看到”CNN模型中较深的卷积层所学习到的一些特征。当然这两个方法也衍生出了其他很多用途,以反卷积为例,它在图像语义分割中有着非常重要的作用。
从本质上说,反卷积和导向反向传播的基础都是反向传播,其实说白了就是对输入进行求导,三者唯一的区别在于反向传播过程中经过ReLU层时对梯度的不同处理策略。在这篇论文(https://arxiv.org/pdf/1412.6806.pdf)中有着非常详细的说明,如下图所示:
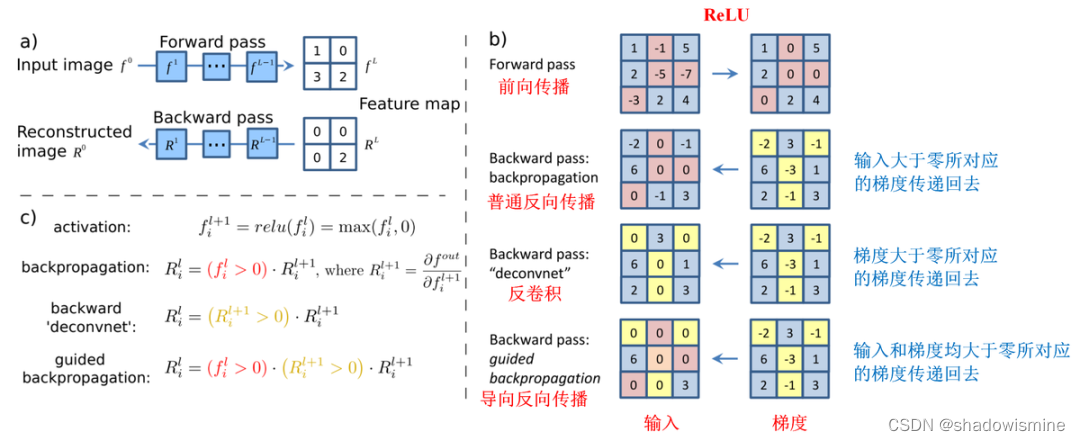
虽然过程上的区别看起来没有非常微小,但是在最终的效果上却有很大差别。如下图所示:

使用普通的反向传播得到的图像噪声较多,基本看不出模型的学到了什么东西。使用反卷积可以大概看清楚猫和狗的轮廓,但是有大量噪声在物体以外的位置上。导向反向传播基本上没有噪声,特征很明显的集中猫和狗的身体部位上。
虽然借助反卷积和导向反向传播我们“看到”了CNN模型神秘的内部,但是却并不能拿来解释分类的结果,因为它们对类别并不敏感,直接把所有能提取的特征都展示出来了。在刚才的图片中,模型给出的分类结果是猫,但是通过反卷积和导向反向传播展示出来的结果却同时包括了狗的轮廓。换句话说,我们并不知道模型到底是通过哪块区域判断出当前图片是一只猫的。要解决这个问题,我们必须考虑其他办法。
2. CAM
大家在电视上应该都看过热成像仪生成的图像,就像下面这张图片。

图像中动
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5万+
5万+



 到【灌水乐园】发言
到【灌水乐园】发言








