







https://t.zsxq.com/cudh6
从前,有一只聪明的狐狸,它发现了一块神奇的“知识星球”。这颗星球上有各种神奇的工具和资源,可以帮助它解决各种问题。狐狸首先找到了“开源”这把万能钥匙,接着用“图像编辑”工具为自己制作了一副炫酷的太阳镜。然后,它决定制作一个“播客”来分享自己的冒险故事。
在它的旅程中,狐狸遇到了“Midjourney”——一个可以生成美丽图像的AI助手,它们一起创作了许多精美的作品。接下来,狐狸碰到了“大模型”和“GUI”,这些工具帮助它更好地理解和操作复杂的界面。为了收集更多信息,它还使用了“信息收集”工具。
狐狸的冒险故事迅速传播开来,引来了许多动物的关注。为了方便大家使用这些工具,狐狸创建了一个“工具箱”,并将其命名为“webAR XR”。最终,狐狸用“nut.js”开发了一个自动化系统,让大家都能轻松使用这些资源。这个故事告诉我们,掌握多种工具和资源,可以让生活变得更丰富多彩。
📝 Topic 1
📅 2024-10-28 08:43
🏷️ 开源, 图像编辑
RexanWONG/text-behind-image 是一个基于 Next.js 创建的项目,旨在轻松制作图片背后文字设计。用户可以通过运行开发服务器并编辑 app/page.tsx 文件来开始项目开发。项目还集成了 next/font 用于优化和加载 Geist 字体。推荐使用 Vercel 平台进行部署,并提供了 Next.js 的相关资源和文档供进一步学习。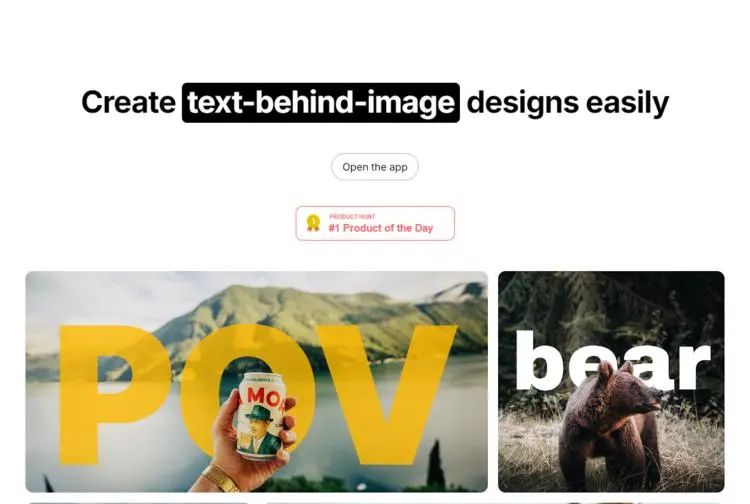
📝 Topic 2
📅 2024-10-27 22:16
🏷️ 播客
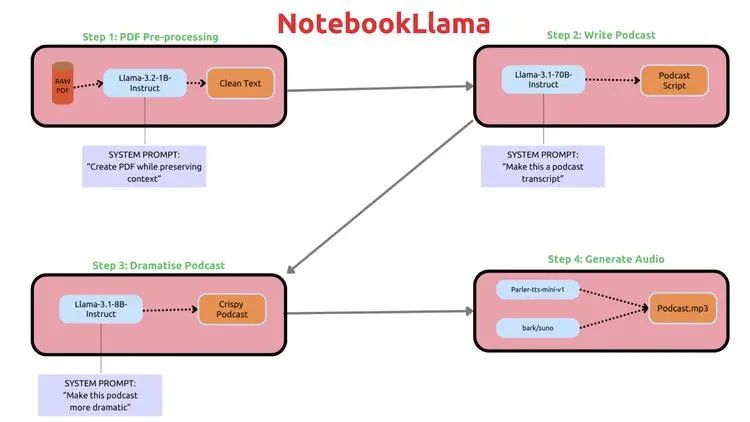
NotebookLlama是一个开源的教程系列,指导用户如何将PDF文件转换为播客。该流程包括四个步骤:预处理PDF、生成播客脚本、增强脚本的戏剧性以及将文本转换为语音。教程使用了不同版本的Llama模型和TTS模型,并提供了详细的操作步骤和改进建议,适合零基础用户学习。
📝 Topic 3
📅 2024-10-26 21:28
🏷️ Midjourney, 图像编辑
Midjourney是由前Magic Leap工程师David Holz创立的AI图像生成初创公司,近日推出了新的AI图像编辑功能。用户可以上传任意图像并使用AI进行局部编辑或改变图像风格和质感。该功能目前仅限于Midjourney 6.1版本,并对生成超过10,000张图像、年费会员和订阅一年以上的用户开放。此外,Midjourney还计划推出3D或视频编辑功能。
📝 Topic 4
📅 2024-10-26 21:17
🏷️ 大模型, GUI
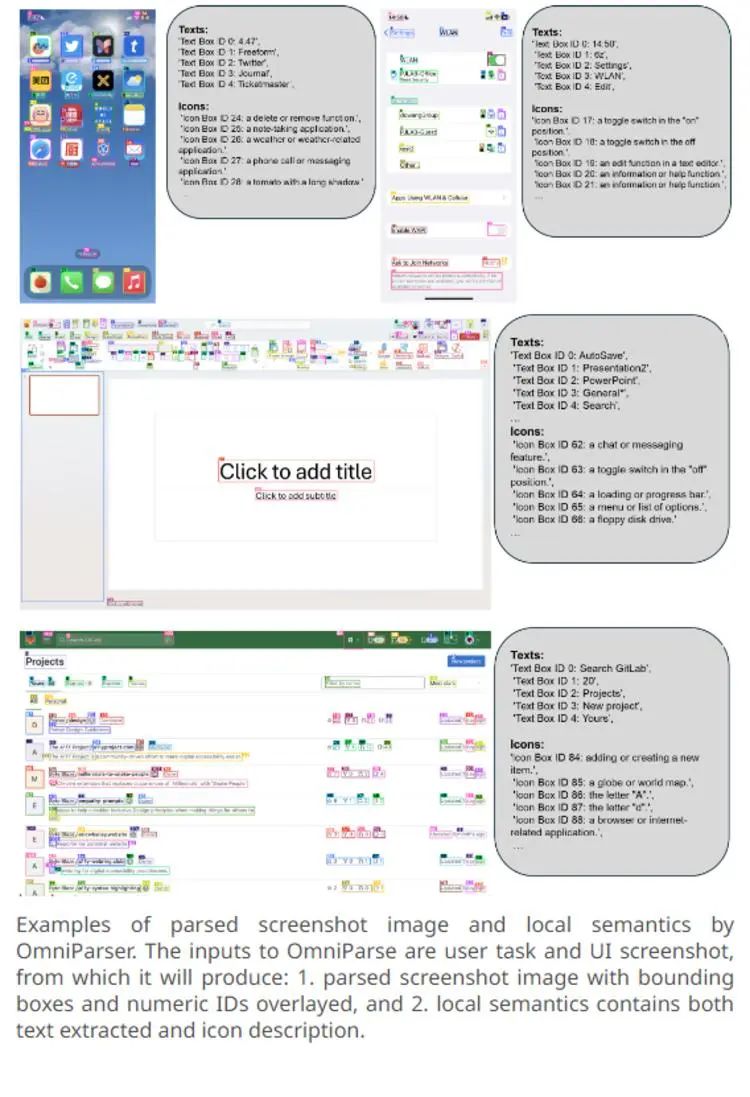
近期的large vision language models成功展示了其在用户界面操作代理系统中的巨大潜力。然而,由于缺乏强大的屏幕解析技术,这些多模态模型如GPT-4V在跨不同操作系统和应用中的能力被低估。为解决这一问题,我们引入了OMNIPARSER,这是一种将用户界面截图解析为结构化元素的综合方法,大大增强了GPT-4V在生成与界面对应区域准确匹配的动作的能力。我们首先使用热门网页和图标描述数据集创建了可交互图标检测数据集,并利用这些数据集微调了检测模型和功能语义提取模型。OMNIPARSER显著提高了GPT-4V在ScreenSpot、Mind2Web和AITW基准测试中的性能,且仅使用截图输入就超越了需要额外信息的GPT-4V基线模型。
📝 Topic 5
📅 2024-10-26 10:03
🏷️ 信息收集
NewsNow是一个优雅的实时和热门新闻阅读平台。项目支持在Cloudflare Pages和Docker上部署,并提供GitHub OAuth登录功能。用户可以通过设置环境变量和数据库来完成部署,也可以根据需要添加数据源。项目具有简单的结构和完善的类型,易于开发和扩展。...
📝 Topic 6
📅 2024-10-25 18:36
Webcam 3D HandControls - Mediapipe Three.js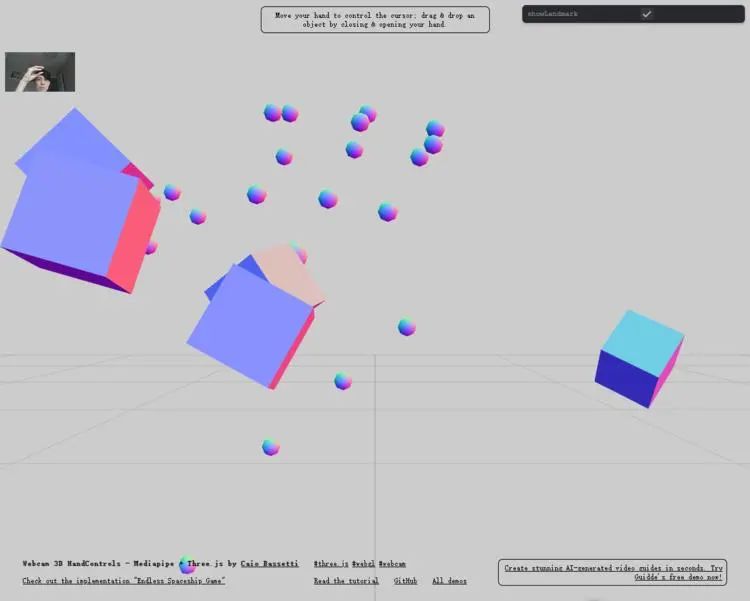
📝 Topic 7
📅 2024-10-25 18:19
《Unbounded》是一款基于生成模型的角色生活模拟游戏,打破了传统有限、硬编码系统的界限。用户可以通过自然语言与定制的虚拟角色互动,角色的饥饿、能量和娱乐值会相应更新,游戏过程充满自发性和无限可能。技术上,该游戏包括一个专门的精炼大型语言模型(LLM)和一个新的动态区域图像提示适配器(IP-Adapter),确保角色在多个环境中的一致性和灵活性。通过定性和定量分析,我们的系统在角色生活模拟、用户指令遵循、叙事连贯性和视觉一致性方面显著优于传统方法。
📝 Topic 8
📅 2024-10-25 16:54
Blendify是一个轻量级的Python框架,提供高层次API用于创建和渲染Blender场景,专注于3D计算机视觉可视化。它简化了对Blender特定功能和对象的访问,具有简单友好的界面,可轻松集成到开发脚本中,支持点云、网格、材质等多种功能。无需独立安装Blender,只需运行pip install blendify即可快速开始使用,并且支持在Google Colab中运行。
📝 Topic 9
📅 2024-10-25 16:42
GLM-4-Voice 是智谱 AI 推出的端到端中英语音对话模型,能够直接理解和生成中英文语音,实现实时语音对话,并根据用户指令调整语音的情感、语调、语速和方言等属性。该模型由三个主要部分组成:GLM-4-Voice-Tokenizer、GLM-4-Voice-Decoder 和 GLM-4-Voice-9B,分别负责将语音输入转化为离散 token、将 token 转化为连续语音输出以及进行语音模态的预训练与对齐。模型通过解耦合 Speech2Speech 任务并设计两种预训练目标,提升了音频理解和建模能力。此外,GLM-4-Voice 采用流式思考架构,确保高质量和低延迟的语音对话体验。
📝 Topic 10
📅 2024-10-25 14:07
HyperHuman提供免费的AI 3D模型生成器,结合了Rodin和ChatAvatar技术。
📝 Topic 11
📅 2024-10-25 13:12
在Connect 2024大会上,Meta开源了Llama 3.2 1B和3B模型,通过量化技术显著提升了模型速度并减少了内存占用。这些量化模型使用了量化感知训练(QAT)和LoRA适配器(QLoRA),在保持高精度的同时,实现了2-4倍的速度提升和56%的模型尺寸减小。新模型适用于移动设备和边缘部署,优化了在低精度环境下的性能,并与多家行业领先的合作伙伴合作,进一步提升了在移动CPU和NPU上的表现。
📝 Topic 12
📅 2024-10-25 12:07
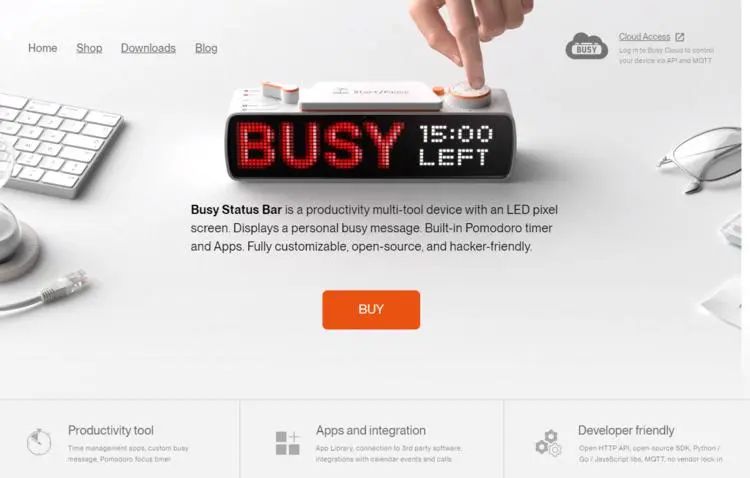
Busy Status Bar是一款集成LED像素屏的生产力多功能设备,支持云端应用和多种编程语言,旨在通过短时间专注工作和五分钟休息的时间管理技术提升工作效率。设备支持自定义忙碌状态消息,可通过多种方式激活,包括手动、远程、以及与常用通讯软件和日历的自动集成。它还可与桌面软件集成,在通话、直播或录音时自动显示“忙碌中”状态,兼容Windows、macOS和Linux系统。
📝 Topic 13
📅 2024-10-25 11:27
🏷️ 工具箱, webAR, XR
Google发布了model-viewer v4.0.0版本。
主要更新包括默认色调映射更改为PBR Neutral,调整了摄像机的默认最小和最大轨道。修复了变体、表面热点更新和withCredentials更新的问题。更新了模型文档,并修复了WebXR模式下的材质选择示例。其他显著的变化包括升级到Three.js r169,并将渲染保真度比较移交给Khronos管理。
📝 Topic 14
📅 2024-10-25 08:44
exo是一款实验性的开源软件,允许用户使用日常设备(如iPhone、iPad、Android、Mac、Linux等)在家中运行AI集群。该软件支持多种模型,并通过动态模型分区和自动设备发现功能,使得用户能够在多设备上运行大型模型。exo还提供了一个兼容ChatGPT的API,方便用户在自己的硬件上运行模型。此外,exo采用点对点连接架构,不需要主从架构,确保设备之间的平等。

📝 Topic 15
📅 2024-10-25 08:44
SingleFile是一款浏览器扩展和命令行工具,兼容多种浏览器,包括Chrome、Firefox、Safari等。它可以帮助用户将完整的网页保存为单个HTML文件。用户可以通过点击扩展工具栏中的按钮来保存网页,还可以通过右键菜单进行更多操作,例如保存选定内容、自动保存、注释和保存页面等。
📝 Topic 16
📅 2024-10-25 08:24
🏷️ nut.js, 开源
《我要放弃开源》
这篇文章是作者写给他的辞职信,他解释了为什么他不再愿意以前的开源做法,并决定收费。他认为开源虽然好,但不可持续,维护者付出了代价,而用户却认为开源是免费的。作者受到了侮辱和抱怨,决定停止在GitHub和npm上公开存在,将软件包变为私有,并要求订阅才能使用。他会继续开发,但更新将延迟。现有订阅者不受涨价影响。
📝 Topic 17
📅 2024-10-25 08:19
🏷️ 工具箱, nut.js
nut.js是一个用于自动化桌面任务的JavaScript/TypeScript API。它提供了一套全面的功能,可以通过鼠标和/或键盘输入、屏幕阅读、搜索特定的UI元素等来自动化你的桌面任务。无论你使用的是Windows、macOS还是Linux,nut.js都被设计成易于使用,并提供一致可靠的体验。它的插件系统允许你混合和匹配额外的功能,以完全满足你的需求。你可以构建和分发自己的插件,或使用官方的插件。
📝 Topic 18
📅 2024-10-24 23:27
Genmo推出了Mochi 1,这是一款强大的开源视频生成AI模型,采用了Asymmetric Diffusion Transformer架构,拥有10亿参数。该模型在高保真运动和强提示依从性方面表现出色,显著缩小了封闭和开放视频生成系统之间的差距。Mochi 1还包括一个高效的上下文并行推理工具,并开源了视频压缩模型AsymmVAE,能够将视频压缩到原始大小的1/128。该模型在480p分辨率下生成视频,并针对真实感风格进行了优化。
📝 Topic 19
📅 2024-10-24 23:20
🏷️ 趋势
OpenAI发布全新模型sCM
OpenAI发布新的模型sCM,该模型在连续时间一致性的理论基础上进行简化,不仅提升训练稳定性,还支持大规模数据集训练。sCM实现了与顶级扩散模型相媲美的样本质量,同时仅需两个采样步骤。这一突破使得sCM能够在ImageNet上以512×512的分辨率扩展至15亿参数的规模。相较于传统方法,sCM生成的样本质量与扩散模型相当,但在采样效率上提高了大约50倍,单个样本在A100 GPU上生成仅需0.11秒,且无需推理优化。通过定制化的系统优化,还能进一步提升性能,为图像、音频及视频等领域中的实时生成应用提供可能。
📝 Topic 20
📅 2024-10-24 23:18
麻省理工科技评论-科学家打造轻量级解码模型,成功研发静默语音系统,复杂环境下语音解码准确率仍达95%
唐晨宇等人设计了一种能解码无声语音信号的系统,结合纺织应变传感器与机器学习算法,提升了静默语音系统的精度与舒适性。该系统可用于医疗沟通、人机交互、智能穿戴及健康监测。
更多详见:
https://t.zsxq.com/cudh6

备注:AIGC知识库

















 1333
1333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









