







图像修复-CVPR2023-Efficient and Explicit Modelling of Image Hierarchies for Image Restoration
本文提出了一种基于锚条纹自注意力的GRL网络架构,通过引入锚条纹自注意力机制平衡自注意力的空间和时间复杂度,并结合窗口自注意力和通道注意力增强卷积,在全局、区域和局部范围内显式建模图像的层次结构,从而提升了图像恢复任务的性能。
论文链接:Efficient and Explicit Modelling of Image Hierarchies for Image Restoration
主要创新点
- 引入锚条纹自注意力(Anchored Stripe Self-Attention)机制:该机制通过平衡自注意力的空间和时间复杂度,并超越局部范围的建模能力,提升了图像恢复任务的性能。锚条纹自注意力能够更高效地建模图像的跨尺度相似性和各向异性特征。
- 提出GRL网络架构:该架构显式地在全局、区域和局部范围内建模图像的层次结构。具体而言,
GRL架构通过锚条纹自注意力、窗口自注意力(Window Self-Attention)和通道注意力增强卷积(Channel Attention Enhanced Convolution)来实现这一目标。
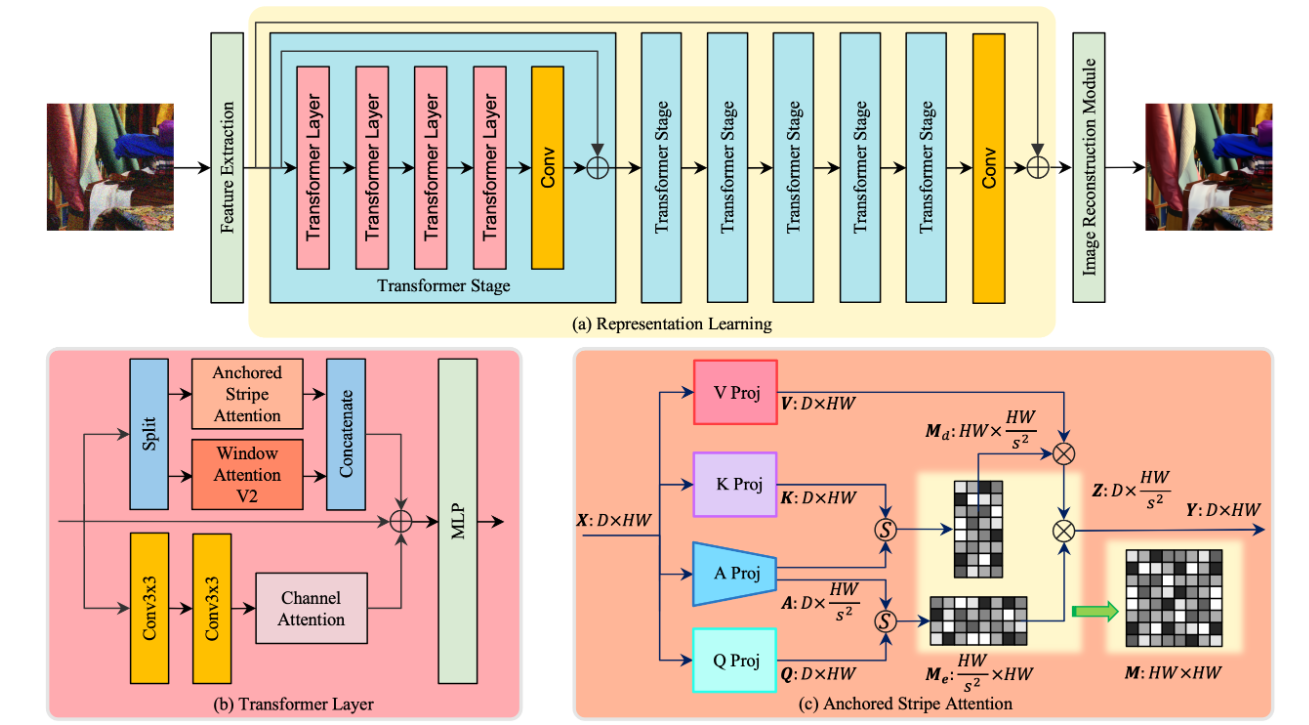
模型机构图
模型总体由一下部分组成:
- 特征提取层(
Feature Extraction Layer):特征提取层实现为一个简单的卷积,将图片转换成特征图形式- 表示学习模块(
Representation Learning Module):该模块的核心是变换器阶段,通过多个变换器层处理输入特征图。特征图经过并行自注意力模块(包括窗口注意力和锚条纹注意力)和通道注意力增强卷积,捕获跨尺度信息和局部结构。窗口注意力采用了Swin Transformer V2的设计,并通过下采样减少了空间和时间复杂度。变换器阶段的输出通过跳跃连接与表示学习模块融合,增强信息流动。- 图像重建模块(
Image Reconstruction Module):该模块负责根据前面操作得到的丰富特征,估计恢复后的高质量图像。通过这一模块,模型能够将经过深度处理的特征映射重新转化为输出的高质量图像。下面将从源码和原来层面来解释表示学习模块(
Representation Learning Module)
启发来源-图像的两个性质
1.跨尺度相似性(cross-scale similarity)
跨尺度相似性指的是图像的基本结构(如边缘、线条等)在不同的尺度下是相似的。这意味着,无论图像在什么分辨率下,某些重要的结构特征(如边缘、轮廓、纹理)都保持一致,尽管图像的细节可能会因为缩放而有所不同。
- 高效建模:在图像处理任务中,跨尺度相似性使得在低分辨率图像上捕获的特征能够有效地映射到高分辨率图像中,减少了模型对不同分辨率图像的冗余计算。通过在不同尺度之间传播相似性信息,模型能够有效地在低分辨率图像中捕捉到全局结构,而不需要在高分辨率图像上重复相同的计算。
- 图像恢复与重建:图像的基本结构在不同尺度之间保持一致,意味着从低分辨率图像到高分辨率图像的恢复可以依赖于跨尺度的相似性,而不需要完全重新计算每个像素之间的关系。这使得模型能够在计算上更加高效,且在重建图像时能够保留重要的结构特征。
实验验证合理性:
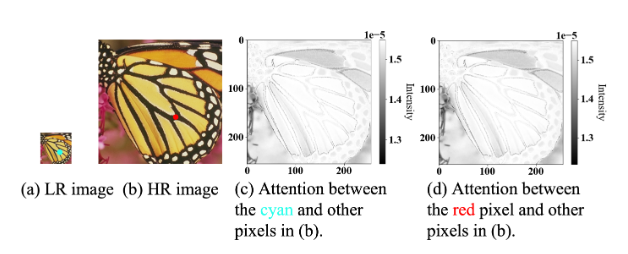
图像解释:© 和 (d) 显示了所选像素与示例高分辨率图像之间的注意力图。尽管 (a) 中的青色像素和 (b) 中的红色像素来自不同分辨率的图像,它们与高分辨率图像的注意力图显示出非常相似的结构。
青色像素和红色像素:尽管它们来自不同分辨率的图像,青色像素来自较高分辨率的图像,而红色像素来自较低分辨率的图像,它们与高分辨率图像的注意力图显示出相似的结构。这意味着,不同分辨率图像中的相似区域在注意力图中表现出相似的关注模式,即它们的相对位置关系、边缘、纹理等基础结构在不同尺度下是一致的。
跨尺度相似性:这种现象表明,图像中的基本结构(如线条、边缘)在不同的尺度下保持了相似性。这对于图像处理任务,如图像恢复和超分辨率等,具有重要意义。因为通过利用跨尺度相似性,模型可以在低分辨率图像中捕捉到在高分辨率图像中也能找到的相似结构,从而提升计算效率和恢复质量。
2.各向异性图像特征(Anisotropic Image Features)
各向异性指的是图像中不同方向上的特征在性质或表现上的不对称性。具体来说,图像中的纹理、边缘、结构等信息可能在不同的方向上有不同的显著性或分布。举个例子,图像中的直线、边缘或纹理在水平方向上可能比在垂直方向上更加明显,或者在某些方向上更加密集和突出。这种不对称性使得图像的局部特征在不同方向上具有不同的处理需求。
- 方向性建模:自注意力机制如果能适应图像中各向异性特征的存在,就能更好地捕捉图像在特定方向上的结构信息。通过引入不同方向的注意力机制(如水平条纹、垂直条纹注意力),可以更高效地捕捉图像中的各向异性结构。
- 局部结构增强:卷积操作本身擅长捕捉局部的结构,但如果能够结合自注意力机制,模型可以更有针对性地捕捉到图像中沿特定方向的结构特征,进一步增强图像的局部信息提取。
实验验证合理性:
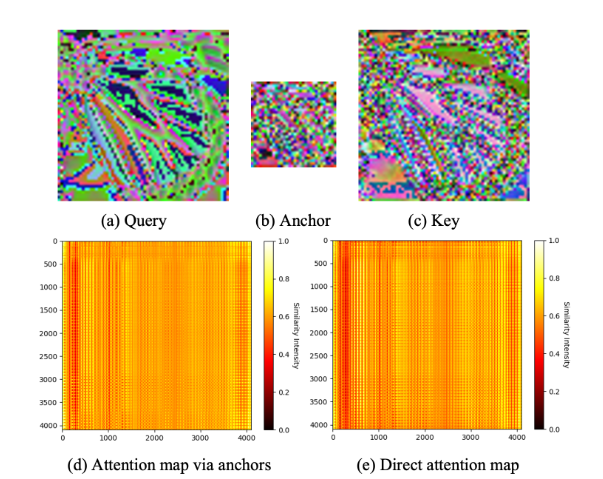
图像解释:展示了所提网络不同层的
(a)查询(queries)、(b) 锚点(anchors)和 (c) 键(keys)。(d) 显示了通过公式 (2) 近似得到的注意力图,即Me⋅Md。 (e) 显示了通过公式 (1) 计算得到的精确注意力图 M
- 近似注意力图(图 d):使用公式 (2) 近似计算得到的注意力图,在实际计算中可能会通过某种降维或简化策略来减少计算复杂度。这种近似方法可以加速计算过程,尤其是在处理大规模图像时。
- 精确注意力图(图 e):通过公式 (1) 计算得到的精确注意力图,通常会保留更多细节和精确的相似性信息。这种方法计算量较大,但能提供更高的准确性。
Transformer Layer
从这个架构图可以看出,最重要的就是这一部分了,其他的无非是将多个
Transformer Layer组合成Transformer Stage,再加上卷积和残差连接,构成整个网路,重中之重就是这个Transformer Layer,上面提到的图像的两个性质也会将会在这里得到应用,下面从源码层面详细解释Transformer Layer的具体实现。
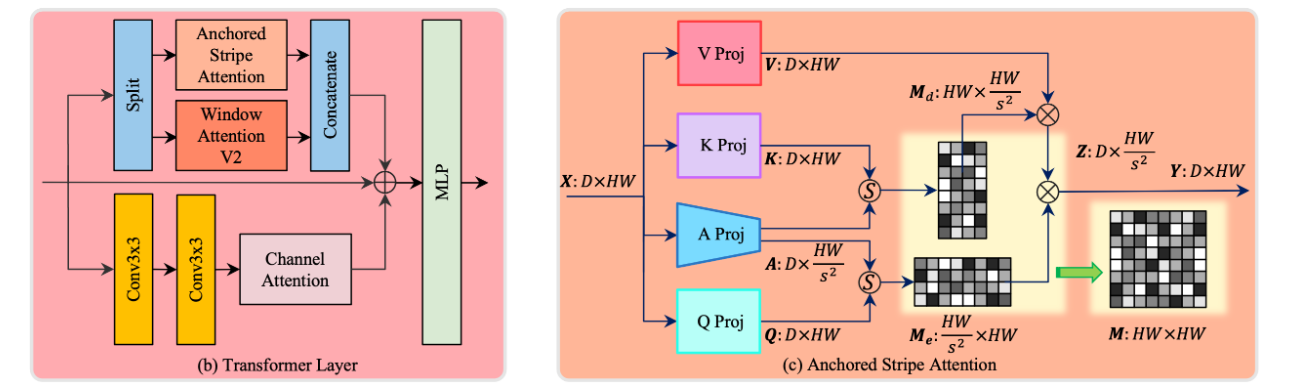
锚条纹注意力(Anchored Stripe Attention)
为了降低全局自注意力计算的复杂度(即 O(NxN)),本文提出了一种新的机制——锚点自注意力(Anchored Self-Attention),其灵感来自于跨尺度相似性(
Cross-Scale Similarity)。通过引入锚点这一概念,锚点作为图像特征图信息的低维总结,帮助减少了计算中涉及的tokens数量,从而降低了计算复杂度。

复杂度从原来的 O(N x N)降低到O(NxM),其中M<<N。
Anchored Stripe Attention源码:
class AnchorStripeAttention(Attention):
r"""条纹注意力机制 (Stripe Attention)
参数:
stripe_size (tuple[int]): 条纹的高度和宽度。
num_heads (int): 注意力头的数量。
attn_drop (float, optional): 注意力权重的丢弃率,默认为 0.0。
pretrained_stripe_size (tuple[int]): 预训练时条纹的高度和宽度。
"""
def __init__(
self,
input_resolution,
stripe_size,
stripe_groups,
stripe_shift,
num_heads,
attn_drop=0.0,
pretrained_stripe_size=[0, 0],
anchor_window_down_factor=1,
args=None,
):
super(AnchorStripeAttention, self).__init__()
# 初始化参数
self.input_resolution = input_resolution # 输入分辨率
self.stripe_size = stripe_size # 条纹的大小 (高, 宽)
self.stripe_groups = stripe_groups # 条纹分组数
self.stripe_shift = stripe_shift # 是否使用条纹位移
self.num_heads = num_heads # 注意力头的数量
self.pretrained_stripe_size = pretrained_stripe_size # 预训练时的条纹大小
self.anchor_window_down_factor = anchor_window_down_factor # 锚点窗口下采样因子
self.euclidean_dist = args.euclidean_dist # 欧几里得距离
# 定义两种注意力变换 (Affine Transform)
self.attn_transform1 = AffineTransformStripe(
num_heads,
input_resolution,
stripe_size,
stripe_groups,
stripe_shift,
pretrained_stripe_size,
anchor_window_down_factor,
window_to_anchor=False, # 不从窗口到锚点的变换
args=args,
)
self.attn_transform2 = AffineTransformStripe(
num_heads,
input_resolution,
stripe_size,
stripe_groups,
stripe_shift,
pretrained_stripe_size,
anchor_window_down_factor,
window_to_anchor=True, # 从窗口到锚点的变换
args=args,
)
# 注意力丢弃层
self.attn_drop = nn.Dropout(attn_drop)
self.softmax = nn.Softmax(dim=-1) # Softmax 层
def forward(self, qkv, anchor, x_size):
"""
前向传播
参数:
qkv: 输入特征,形状为 (B, L, C),其中 B 为批大小,L 为特征长度,C 为特征维度
anchor: 锚点,形状通常是较小的尺度,作为计算相似度的参考
x_size: 图像的尺寸,用于确定是否需要重新生成相对位置偏置表和索引
"""
H, W = x_size # 图像的高度和宽度
B, L, C = qkv.shape # B 为批量大小,L 为序列长度,C 为通道数
qkv = qkv.view(B, H, W, C) # 将输入特征转换为形状 (B, H, W, C)
# 获取条纹的尺寸和位移大小
stripe_size, shift_size = self.attn_transform1._get_stripe_info(x_size)
anchor_stripe_size = [s // self.anchor_window_down_factor for s in stripe_size] # 锚点条纹尺寸
anchor_shift_size = [s // self.anchor_window_down_factor for s in shift_size] # 锚点位移尺寸
# 如果启用条纹位移,则对特征进行循环位移
if self.stripe_shift:
qkv = torch.roll(qkv, shifts=(-shift_size[0], -shift_size[1]), dims=(1, 2))
anchor = torch.roll(
anchor,
shifts=(-anchor_shift_size[0], -anchor_shift_size[1]),
dims=(1, 2),
)
# 将特征图分割成窗口
qkv = window_partition(qkv, stripe_size) # nW*B, wh, ww, C
qkv = qkv.view(-1, prod(stripe_size), C) # nW*B, wh*ww, C
anchor = window_partition(anchor, anchor_stripe_size) # 锚点特征图分割成窗口
anchor = anchor.view(-1, prod(anchor_stripe_size), C // 3) # 锚点通道数为 C//3
B_, N1, _ = qkv.shape # qkv 的形状
N2 = anchor.shape[1] # 锚点的形状
qkv = qkv.reshape(B_, N1, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4) # 重塑 qkv 为多头注意力的形式
q, k, v = qkv[0], qkv[1], qkv[2] # q, k, v 分别表示查询、键和值
anchor = anchor.reshape(B_, N2, self.num_heads, -1).permute(0, 2, 1, 3) # 重塑锚点
# 计算注意力
x = self.attn(anchor, k, v, self.attn_transform1, x_size, False) # 锚点与键值进行计算
x = self.attn(q, anchor, x, self.attn_transform2, x_size) # 查询与锚点进行计算
# 合并窗口
x = x.view(B_, *stripe_size, C // 3) # 将结果重新调整为条纹大小
x = window_reverse(x, stripe_size, x_size) # 反向合并窗口,恢复为原图尺寸
# 如果启用了条纹位移,则恢复位移
if self.stripe_shift:
x = torch.roll(x, shifts=shift_size, dims=(1, 2))
x = x.view(B, H * W, C // 3) # 调整输出形状为 (B, H*W, C//3)
return x
窗口注意力(Window Attention)
该注意力机制源自于Swin Transformer V2,它通过在局部窗口内进行注意力计算来捕捉图像的局部结构,同时在不同尺度下对图像的全局信息进行处理。这种局部-全局的分层建模有助于有效地捕捉图像中不同尺度的相似性。窗口注意力帮助模型聚焦于图像中的局部细节,而同时通过层次化处理保留了跨尺度的结构信息。
了解更新细节可以可以查看之前的文章:Swin Transformer
Window Attention源码:
class WindowAttention(Attention):
r"""窗口注意力机制。QKV 是输入到前向传播方法的特征。
参数:
num_heads (int): 注意力头的数量。
attn_drop (float, optional): 注意力权重的丢弃率。默认为 0.0。
pretrained_window_size (tuple[int]): 预训练时窗口的高度和宽度。
"""
def __init__(
self,
input_resolution,
window_size,
num_heads,
window_shift=False,
attn_drop=0.0,
pretrained_window_size=[0, 0],
args=None,
):
# 初始化窗口注意力的各个参数
super(WindowAttention, self).__init__()
self.input_resolution = input_resolution # 输入图像的分辨率
self.window_size = window_size # 窗口的大小,通常是一个高宽元组
self.pretrained_window_size = pretrained_window_size # 预训练时的窗口大小
self.num_heads = num_heads # 注意力头的数量
self.shift_size = window_size[0] // 2 if window_shift else 0 # 是否进行窗口偏移,默认偏移窗口的一半
self.euclidean_dist = args.euclidean_dist # 欧几里得距离,用于计算位置偏置
# 定义一个仿射变换,用于调整输入特征
self.attn_transform = AffineTransform(num_heads)
# 定义丢弃层,减少过拟合
self.attn_drop = nn.Dropout(attn_drop)
# Softmax 层,用于计算注意力权重
self.softmax = nn.Softmax(dim=-1)
def forward(self, qkv, x_size, table, index, mask):
"""
前向传播方法:
参数:
qkv: 输入的 QKV 特征,形状为 (B, L, 3C),B 为批量大小,L 为序列长度,C 为特征维度。
x_size: 输入特征图的大小,用于决定是否需要重新生成位置偏置表和索引。
table: 相对位置偏置表,用于计算位置注意力。
index: 用于生成窗口内索引的参数。
mask: 用于屏蔽某些区域的掩码。
"""
# 获取输入特征图的高和宽
H, W = x_size
B, L, C = qkv.shape
qkv = qkv.view(B, H, W, C) # 将输入的 QKV 特征图重塑为 (B, H, W, C)
# 如果设置了窗口偏移,执行周期性偏移
if self.shift_size > 0:
qkv = torch.roll(
qkv, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2)
)
# 将特征图划分为窗口
qkv = window_partition(qkv, self.window_size) # 将特征图划分为窗口,形状变为 (nW*B, wh, ww, C)
qkv = qkv.view(-1, prod(self.window_size), C) # 将窗口重塑为 (nW*B, wh*ww, C)
B_, N, _ = qkv.shape
qkv = qkv.reshape(B_, N, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # 分别提取 Q, K, V 特征
# 计算注意力
x = self.attn(q, k, v, self.attn_transform, table, index, mask)
# 将窗口内的结果合并为一个大的特征图
x = x.view(-1, *self.window_size, C // 3)
x = window_reverse(x, self.window_size, x_size) # 将窗口恢复为原始大小
# 如果进行了周期性偏移,反向操作
if self.shift_size > 0:
x = torch.roll(x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
# 重塑输出为原始形状
x = x.view(B, L, C // 3)
return x
通道注意力增强卷积(Channel Attention Enhanced Convolutions)
卷积分支:卷积操作的目的是捕获图像中的局部结构,例如边缘、纹理等。卷积层与自注意力模块结合,使得模型能够同时关注局部和全局的信息。
通道注意力:该部分通过增强通道维度上的注意力来加强模型对特定通道信息的聚焦。通道注意力机制通过加权每个通道的特征,强化对重要通道的关注,并抑制无关通道的干扰,从而提升特征表示的能力。
Channel Attention Enhanced Convolutions源码:
class ChannelAttention(nn.Module):
"""通道注意力机制,应用于 RCAN(Residual Channel Attention Networks)。
参数:
num_feat (int): 中间特征的通道数,通常是输入特征图的通道数。
reduction (int): 通道压缩因子。默认值是 16,用于减少计算量。
"""
def __init__(self, num_feat, reduction=16):
super(ChannelAttention, self).__init__()
# 定义通道注意力的计算步骤
self.attention = nn.Sequential(
# 自适应平均池化,将特征图池化成大小为 (1, 1) 的输出
nn.AdaptiveAvgPool2d(1),
# 1x1 卷积层,将通道数减少到 num_feat // reduction
nn.Conv2d(num_feat, num_feat // reduction, 1, padding=0),
# 激活函数 ReLU
nn.ReLU(inplace=True),
# 1x1 卷积层,将通道数恢复到原来的 num_feat
nn.Conv2d(num_feat // reduction, num_feat, 1, padding=0),
# Sigmoid 激活函数,得到 0 到 1 之间的权重
nn.Sigmoid(),
)
def forward(self, x):
"""
前向传播函数:
输入:
x: 输入特征图,形状为 (B, C, H, W),B 为批量大小,C 为通道数,H 和 W 为特征图的高和宽。
输出:
经过通道注意力加权后的特征图。
"""
y = self.attention(x) # 计算注意力权重
return x * y # 对输入 x 进行加权操作
Transformer Layer 总体代码
class MixAttnTransformerBlock(nn.Module):
r"""混合注意力 Transformer 块,具有共享的 QKV 投影和输出投影,用于混合注意力模块。
参数:
dim (int): 输入通道的数量。
input_resolution (tuple[int]): 输入的分辨率。
num_heads_w (int): 窗口注意力的头数。
num_heads_s (int): 条纹注意力的头数。
window_size (int): 窗口大小。
mlp_ratio (float): MLP 隐藏层维度与嵌入维度的比率。
qkv_bias (bool, optional): 如果为 True,则在查询、键、值中添加可学习的偏置。默认值: True
drop (float, optional): 丢弃率。默认值: 0.0
attn_drop (float, optional): 注意力丢弃率。默认值: 0.0
drop_path (float, optional): 随机深度率。默认值: 0.0
act_layer (nn.Module, optional): 激活层。默认值: nn.GELU
norm_layer (nn.Module, optional): 归一化层。默认值: nn.LayerNorm
pretrained_stripe_size (int): 预训练时窗口大小。
attn_type (str, optional): 注意力类型。默认值: cwhv。
c: 残差块
w: 窗口注意力
h: 水平条纹注意力
v: 垂直条纹注意力
"""
def __init__(
self,
dim,
input_resolution,
num_heads_w,
num_heads_s,
window_size=7,
window_shift=False,
stripe_size=[8, 8],
stripe_groups=[None, None],
stripe_shift=False,
stripe_type="H",
mlp_ratio=4.0,
qkv_bias=True,
qkv_proj_type="linear",
anchor_proj_type="separable_conv",
anchor_one_stage=True,
anchor_window_down_factor=1,
drop=0.0,
attn_drop=0.0,
drop_path=0.0,
act_layer=nn.GELU,
norm_layer=nn.LayerNorm,
pretrained_window_size=[0, 0],
pretrained_stripe_size=[0, 0],
res_scale=1.0,
args=None,
):
super().__init__()
# 保存各个参数
self.dim = dim # 输入通道的维度
self.input_resolution = input_resolution # 输入分辨率
self.num_heads_w = num_heads_w # 窗口注意力头数
self.num_heads_s = num_heads_s # 条纹注意力头数
self.window_size = window_size # 窗口大小
self.window_shift = window_shift # 是否启用窗口平移
self.stripe_shift = stripe_shift # 是否启用条纹平移
self.stripe_type = stripe_type # 条纹类型(水平或垂直)
self.args = args # 附加参数
# 如果条纹类型是 "W",则反转条纹的大小和分组
if self.stripe_type == "W":
self.stripe_size = stripe_size[::-1]
self.stripe_groups = stripe_groups[::-1]
else:
self.stripe_size = stripe_size # 否则按默认大小
self.stripe_groups = stripe_groups
self.mlp_ratio = mlp_ratio # MLP的隐藏层与输入维度的比率
self.res_scale = res_scale # 残差连接的缩放因子
# 初始化混合注意力模块(图中的上半部分组合)
self.attn = MixedAttention(
dim,
input_resolution,
num_heads_w,
num_heads_s,
window_size,
window_shift,
self.stripe_size,
self.stripe_groups,
stripe_shift,
qkv_bias,
qkv_proj_type,
anchor_proj_type,
anchor_one_stage,
anchor_window_down_factor,
attn_drop,
drop,
pretrained_window_size,
pretrained_stripe_size,
args,
)
# 第一层归一化
self.norm1 = norm_layer(dim)
# 如果启用局部连接(local_connection)
if self.args.local_connection:
# 初始化局部连接模块
self.conv = CAB(dim) # 图中的通道卷积
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
# 初始化 MLP 层
self.mlp = Mlp(
in_features=dim,
hidden_features=int(dim * mlp_ratio),
act_layer=act_layer,
drop=drop,
)
# 第二层归一化
self.norm2 = norm_layer(dim)
def forward(self, x, x_size):
"""
前向传播:
参数:
x: 输入特征,形状为 (B, L, C),B为批量大小,L为序列长度,C为特征维度。
x_size: 输入的分辨率,用于确定是否需要重新生成位置偏置表和索引。
"""
# 混合注意力计算
if self.args.local_connection:
# 如果启用了局部连接,执行如下操作:
x = (
x
+ self.res_scale * self.drop_path(self.norm1(self.attn(x, x_size))) # 注意力输出与输入相加
+ self.conv(x, x_size) # 局部连接(卷积)
)
else:
# 如果没有启用局部连接,直接进行注意力计算
x = x + self.res_scale * self.drop_path(self.norm1(self.attn(x, x_size)))
# 进行 FFN(前馈神经网络)计算
x = x + self.res_scale * self.drop_path(self.norm2(self.mlp(x)))
return x


















 1812
1812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









