






 本文详细介绍了如何在CentOS 7环境下从零开始部署Hadoop伪分布式环境,并进一步扩展到完全分布式环境。包括网络配置、防火墙及Selinux关闭、SSH免密登录设置、JDK与Hadoop安装配置等关键步骤。
本文详细介绍了如何在CentOS 7环境下从零开始部署Hadoop伪分布式环境,并进一步扩展到完全分布式环境。包括网络配置、防火墙及Selinux关闭、SSH免密登录设置、JDK与Hadoop安装配置等关键步骤。
伪分布式的搭建
• 下载CentOS7镜像文件
下载网址:http://mirrors.aliyun.com/centos/7.9.2009/isos/x86_64/
选择下载文件:CentOS-7-x86_64-Minimal-2009.iso
建议配置如下
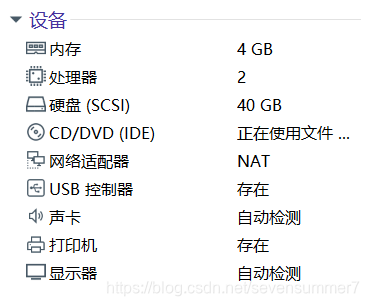
软件选择为默认的“最小安装”
遇到的问题:无法连接网络
解决:启用虚拟网络编辑器的NAT模式的DHCP

只要网络能够连接,那也不必急着编辑网卡,按照默认就好,因为后续也可在虚拟机中编辑。
同时也要注意,IP地址最后不要用101,其他不重复大概都行。
设置网卡
• 在hadp01虚拟机上设置静态网卡,操作步骤如下:
• 查看本机IP:ip addr
• 切换工作目录:cd /etc/sysconfig/network-scripts
• 编辑网卡文件:vi ifcfg-ens33
• 将BOOTPROTO的值修改为static(默认是dhcp)
• 在文件末尾增加以下内容(注意:IPADDR和GATEWAY的值要与本机实际数据保持一致)
IPADDR=192.168.100.128
NETMASK=255.255.255.0
GATEWAY=192.168.100.2
DNS1=114.114.114.114
DNS2=119.29.29.29
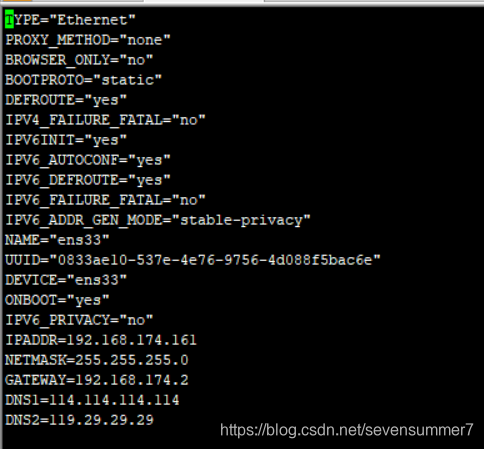
• 保存后,执行systemctl restart network,即可重启网卡,使设置生效
检查是否生效也简单,ip addr
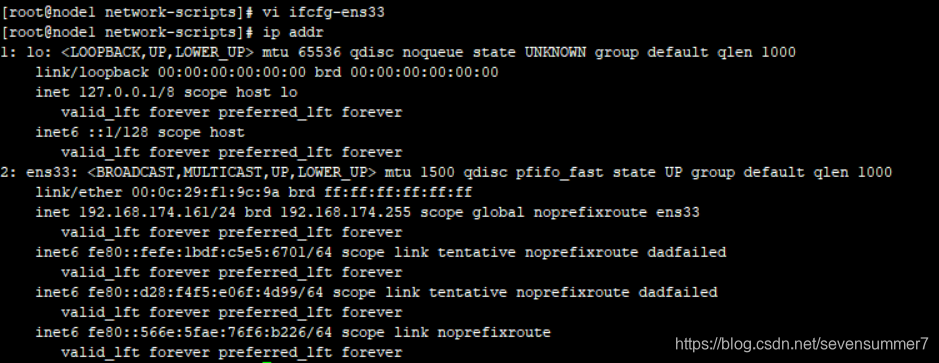
在这里查看inet是否改变
. 配置主机名
• 在虚拟机上编辑hosts文件vi /etc/hosts
• 在虚拟机的hosts文件中增加以下内容
192.168.100.128 hadp01
关闭防火墙和Selinux
• 在虚拟机上关闭防火墙
• systemctl disable firewalld.service禁止防火墙开机时启动。
• 在虚拟机上关闭Selinux
• vi /etc/selinux/config
• 将SELINUX=enforcing修改为SELINUX=disabled
• 执行reboot重启CentOS系统,使设置生效
.配置SSH免密登录
• 在hadp01上执行ssh-keygen -t rsa生成公私钥,按三次回车键,执行完毕后,将在用户主目录下生成.ssh文件夹,其中包括公私钥文件。
• 执行命令ssh-copy-id -i ~/.ssh/id_rsa.pub hadp01把公钥发送到服务器端
o 执行过程中提示Are you sure you want to continue connecting (yes/no)?时,输入yes
o 执行过程中根据提示输入root用户密码(密码输入时没有显示)
.传输jdk和hadoop的安装文件
• 在Win10中下载jdk-8u201-linux-x64.tar.gz和hadoop-2.9.2.tar.gz
• 在hadp01上创建目录用于保存安装文件mkdir -p /home/root/apps
• 通过Xftp软件,将保存在Win10中的jdk-8u201-linux-x64.tar.gz和hadoop-2.9.2.tar.gz传递到hadp01的/home/root目录中

问题:传输文件错误
解决:
1.可能是防火墙未关
2.xftp中登入的用户不是root,退出,使用root
安装jdk
• 在hadp01上执行命令cd /home/root,切换到目录/home/root下
• 执行命令
**tar -xzvf jdk-8u201-linux-x64.tar.gz -C apps/**
将jdk解压到指定目录中(/home/root/apps)
• 执行命令
**vi /etc/profile**
编辑/etc/profile文件,在文件的末尾设置JAVA环境变量
export JAVA_HOME=/home/root/apps/jdk1.8.0_201
export PATH=$PATH:$JAVA_HOME/bin
• 执行命令
source /etc/profile
让/etc/profile文件修改后立即生效
• 查看jdk版本信息java -version ,如果能够显示正确版本信息,说明配置成功
•
安装Hadoop2.9.2
• 在hadp01上执行命令cd /home/root,切换到目录/home/root下
• 执行命令
tar -xzvf hadoop-2.9.2.tar.gz -C apps/将hadoop解压到指定目录中(/home/root/apps)
o 可以删除目录中的文档
cd /home/root/apps/hadoop-2.9.2/share
rm -rf doc

• vi /etc/profile 编辑/etc/profile文件,设置Hadoop环境变量
export JAVA_HOME=/home/root/apps/jdk1.8.0_201
export HADOOP_HOME=/home/root/apps/hadoop-2.9.2
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
• 执行命令source /etc/profile ,让/etc/profile文件修改后立即生效
• 执行命令cd /home/root/apps/hadoop-2.9.2/etc/hadoop,切换到目录/home/root/apps/hadoop-2.9.2/etc/hadoop下
o 可以执行ll命令,查看当前目录中的内容
• 编辑core-site.xml文件vi core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadp01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/root/apps/hadoop-2.9.2/tmp</value>
</property>
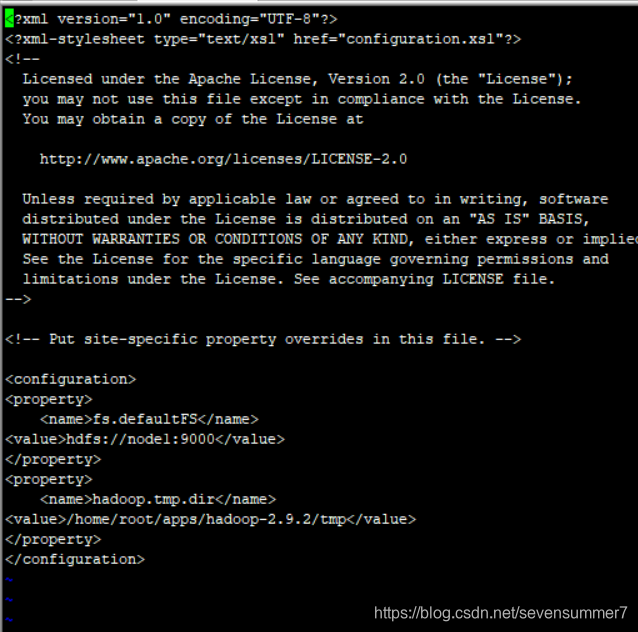
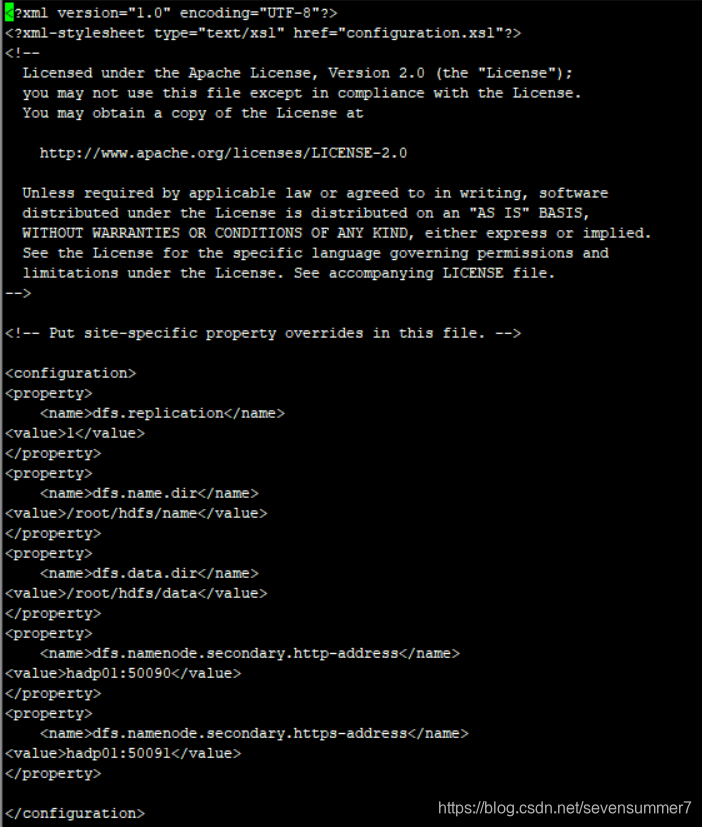
• 编辑hdfs-site.xml文件vi hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/root/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/root/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadp01:50090</value>
</property>
<property>
<name>dfs.namenode.secondary.https-address</name>
<value>hadp01:50091</value>
</property>
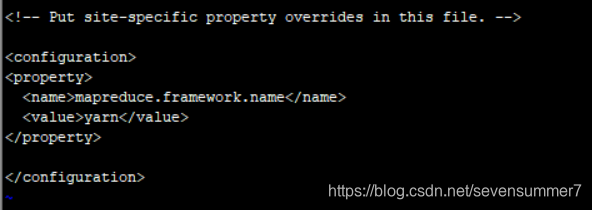
• 根据模板创建mapred-site.xml文件:cp mapred-site.xml.template mapred-site.xml
• 编辑mapred-site.xml文件vi mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
• 编辑yarn-site.xml文件
vi yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadp01</value>
</property>
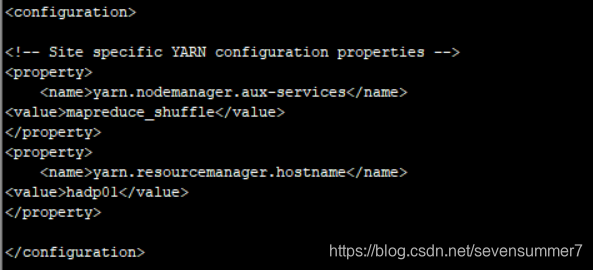
注意:最后的hadp01需要根据主机名来定,在后面搭建完全分布式时,需要更改
• 编辑hadoop-env.sh文件vi hadoop-env.sh
o 将默认的export JAVA_HOME=${JAVA_HOME}替换为export JAVA_HOME=/home/root/apps/jdk1.8.0_201
• 编辑yarn-env.sh文件vi yarn-env.sh
o 将默认的# export JAVA_HOME=/home/y/libexec/jdk1.6.0/替换为export JAVA_HOME=/home/root/apps/jdk1.8.0_201,记得删除这一行最前面的#
• 编辑mapred-env.sh文件vi mapred-env.sh
o 将默认的# export JAVA_HOME=/home/y/libexec/jdk1.6.0/替换为export JAVA_HOME=/home/root/apps/jdk1.8.0_201,记得删除这一行最前面的#
• 编辑slaves文件vi slaves
o 将默认的localhost改为hadp01
• 格式化namenode节点:
hdfs namenode -format
注意:尽量一次格式化,或者在格式化前拍摄快照。
一般没有问题的情况下格式化不需要输入yes
• 启动Hadoop集群
cd /home/root/apps/hadoop-2.9.2/sbin
./start-all.sh
o 提示Are you sure you want to continue connecting (yes/no)?时,输入yes
• 输入jps显示当前所有java进程
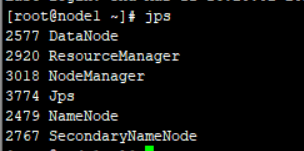
运行Hadoop示例程序
运行计算PI值的实例。
cd /home/root/apps/hadoop-2.9.2/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-2.9.2.jar pi 10 1000

如果能运行出结果,成功
记得关闭虚拟机前关闭hadoop集群
完全分布式的搭建
在伪分布式的基础上搭建即可
克隆出3台虚拟机
关机状态即可克隆
修改3台主机IP地址
切换工作目录:cd /etc/sysconfig/network-scripts
• 编辑网卡文件:vi ifcfg-ens33
将IPADDR=192.168.100.128改变即可
修改主机名
sudo vi /etc/hostname
j将三台主机名分别修改为node1,node2,node3
改完后记得重启
reboot
再次登陆会发现有所改变
映射ip地址和主机名
vi /etc/hosts
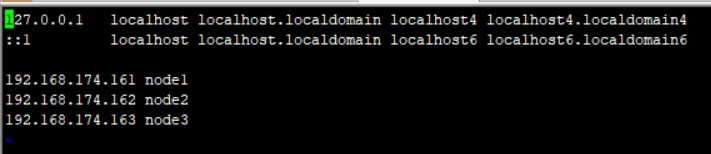
• 在hadp01上执行ssh-keygen -t rsa生成公私钥
• 将node1的公钥复制到node2,node3
ssh-copy-id -i ~ /.ssh/id_rsa.pub node1
ssh-copy-id -i ~ /.ssh/id_rsa.pub node2
ssh-copy-id -i ~ /.ssh/id_rsa.pub node3
验证一下免密登陆

配置hadoop文件
进入hadoop配置文件目录
cd /home/root/apps/hadoop-2.9.2/etc/hadoop
• 编辑core-site.xml文件
vi core-site.xml
将伪分布式的hadp1改为node1
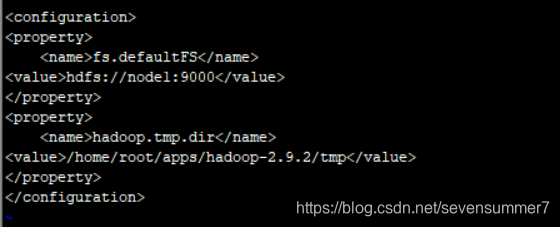
将伪分布式的hadp1改为node1
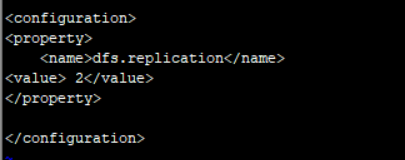
• 编辑hdfs-site.xml文件vi hdfs-site.xml
将1修改为2
• 编辑yarn-site.xml文件vi yarn-site.xml
将hadp1改为node1
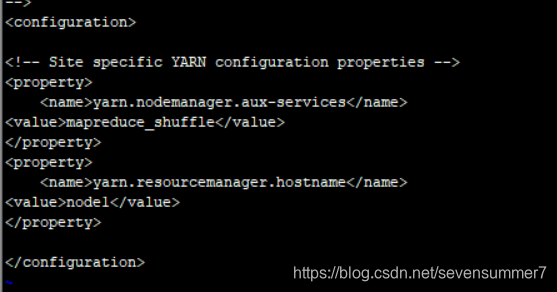
• 编辑slaves文件vi slaves
改为
node1
node2
node3
将node1上的配置文件分给node2和node3
当然,也可以在三台虚拟机上同时修改
格式化HDFS
格式化前建议拍摄快照
注意:只格式化node1
• 格式化namenode节点:hdfs namenode -format
注意:不要多次格式化,可能会缺失jps进程
• 启动Hadoop集群
在node1上启动
cd /home/root/apps/hadoop-2.9.2/sbin
./start-all.sh
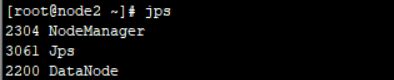
• 输入jps显示当前所有java进程
node1
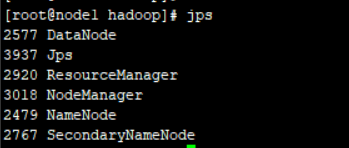
node2和node3
• 在Windows中启动浏览器查看运行情况(推荐使用Google Chrome浏览器)
o HDFS的Web端口号是50070
o YARN的Web端口号是8088

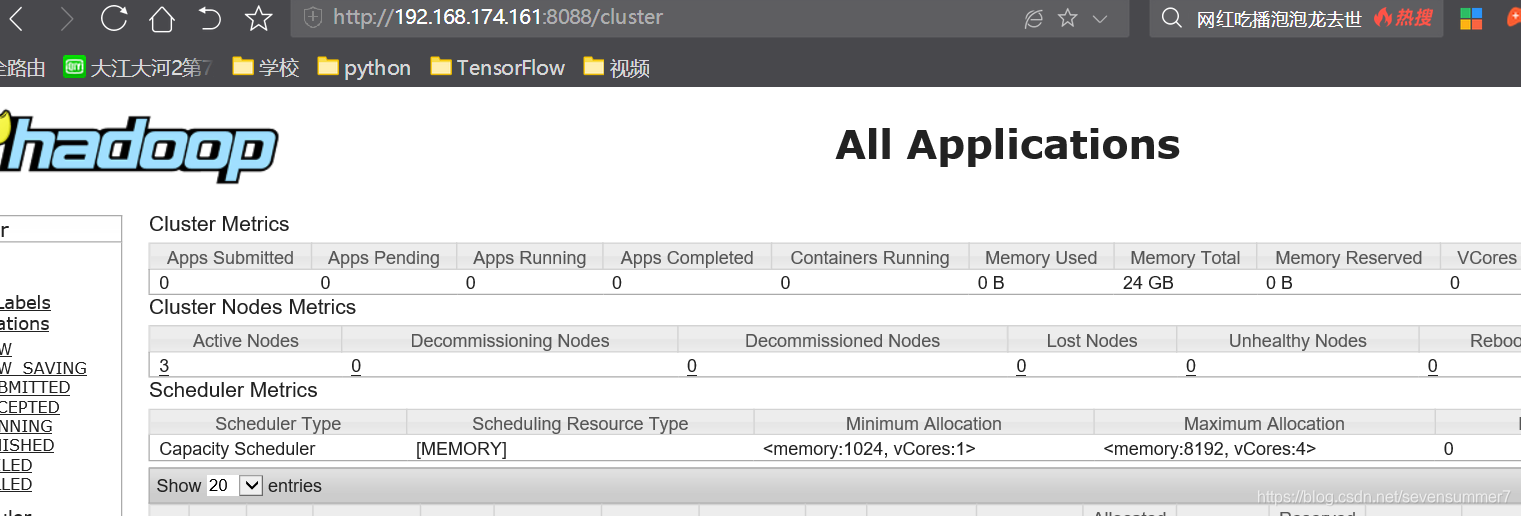
最后也可以运算下pi

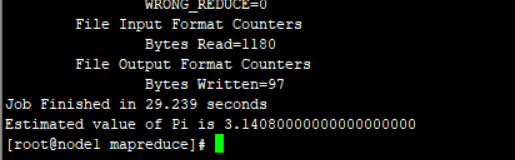
如此,搭建成功

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









