






说明:本篇blog是一篇自学笔记,cr:哔哩站up主白月黑羽编程,源于原理与安装 - 白月黑羽和黑马程序员软件测试web自动化测试,Web自动化流程精讲和移动自动化测试环境_哔哩哔哩_bilibili,基于自身基础做的学习笔记,如需更多详细学习讲解,建议直接看原视频❀
一、原理
Selenium是一套web网站 的程序自动化操作 解决方案
通过它,可以写出自动化程序,像人一样在浏览器里操作web界面。比如点击页面按钮,在文本输入框输入文字操作。而且还能从web界面获取信息,比如获取 火车、汽车票务信息、招聘网站信息,然后利用程序进行分析处理
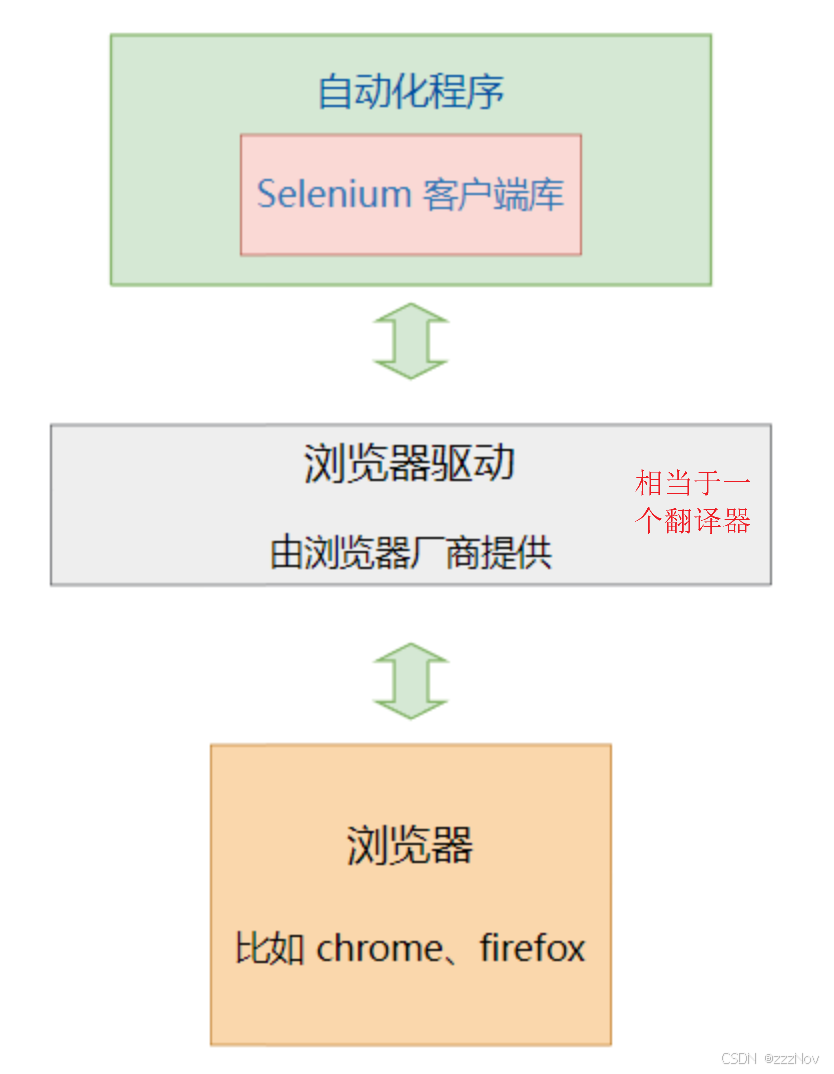
selenium 自动化流程如下:
- 自动化程序调用Selenium 客户端库函数(比如点击按钮元素)
- 客户端库会发送Selenium 命令 给浏览器的驱动程序
- 浏览器驱动程序接收到命令后 ,驱动浏览器去执行命令
- 浏览器执行命令
- 浏览器驱动程序获取命令执行的结果,返回给我们自动化程序
- 自动化程序对返回结果进行处理
---------------------------------------------------------------------------------------------------------------------------------
1.元素操作

1.1操作浏览器
方法:
- maximize_window() 窗口最大化,一般在获取driver后,直接编写最大化浏览器
- set_window_size(w,h) 设置窗口大小
- set_window_position(x,y)设置窗口位置
- back() 后退
- forward() 前进
- refresh()刷新,在后面的cookie章节会使用到
- close()关闭当前窗口,当前窗口指的是driver启动的首个窗口
- quit()关闭驱动对象,关闭由driver启动的所有窗口,如果当前只有一个窗口,与close()无差别
- title获取页面title--后面没有括号,一般判断上步操作是否执行成功
- current_url获取当前页面url--后面没有括号,一般判断上步操作是否执行成功
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
driver=webdriver.Chrome()
driver.get('http://120.79.134.189/page/xiaoyu-authority_management/login.html')
# driver.find_element_by_name("username").send_keys("15679790909")#查找并输出
# driver.find_element_by_name("password").send_keys("123456")
# driver.find_element_by_id("login").click()
driver.maximize_window()
sleep(2)
driver.set_window_size(800,500)
sleep(2)
driver.set_window_position(10,50)
sleep(2)
driver.maximize_window()
driver.find_element_by_css_selector("input").send_keys("15679790909")
driver.find_element_by_css_selector("input").clear()
driver.find_element_by_css_selector("input").send_keys("15679790909")
sleep(2)
driver.find_element_by_css_selector("input[name='password']").send_keys(123456)
driver.find_element_by_css_selector("input[id*='in']").click()
driver.back()
driver.forward()
driver.title
driver.current_url
driver.find_element_by_xpath("//*[@id='login']").click()
sleep(1)
driver.quit()1.2 获取元素信息

获取元素信息:
- size 返回元素大小
- text 返回元素的文本
- get_attribute("xxxx") 获取属性值,传递的参数为元素的属性名
- is_displayed() 判断元素是否可见
- is_enabled() 判断元素是否可用
- is_selected() 判断元素是否选中,用来检查复选框或单选按钮是否被选中
test和size调用时无括号
get_attribute一般应用场景:判断一组元素是否为想要的元素或者判断元素属性值是否正确
is_displayed,is_enabled,is_selected在特殊应用场景中使用
1.3 鼠标操作
1.为什么使用鼠标操作?
为了满足丰富 的HTML鼠标效果,必须使用对应的方法
2.鼠标事件对应的方法在哪个类中?
ActionChains类-->导包
from selenium.webdriver.common.action_chains import ActionChains
3.鼠标事件常用的操作方法:
- context_click() #右击
应用:
ActionChains(driver).contex_click(元素定位).perform()
- double_click() #双击
应用:
ActionChains(driver).double_click(元素定位).perform()
- drag_and_drop() #拖拽
应用:
ActionChains(driver).drag_and_drop(控制的元素,指定位置).perform()
- move_to_element() #悬停
应用:
Action Chains(driver).move_to_click(元素定位).perform()
- perform() #执行以上事件方法
提示:selenium框架中,虽然提供了鼠标右击方法,但是没有提供选择右击菜单的方法,可以通过发送快捷键的方式解决(经测试,谷歌浏览器不支持)。
1.4 键盘操作


username=driver.find_element_by_name("username")
username.send_keys("15679790909")
username.send_keys(Keys.BACK_SPACE)
username.send_keys(Keys.CONTROL,"a")
sleep(1)
username.send_keys(Keys.CONTROL,"c")
sleep(1)
driver.find_element_by_name("password").send_keys(Keys.CONTROL,"v")
sleep(1)
driver.find_element_by_name("password")1.5 元素等待
- 为什么要设置元素等待
由于网络或配置,在查找元素时,元素代码未在第一时间内被加载出来,而抛出未找到元素异常
- 什么是元素等待
元素在第一次未找到时,元素等待设置的时长被激活,如果在设置的有效时长内找到元素,继续执行代码,如果超出设置的时长未找到元素,抛出未找到元素异常
- 元素等待分类
隐式元素等待(针对所有元素生效) 和 显示元素等待(针对单个元素生效)
1.5.1 隐式元素等待

driver.implicitly_wait(timout)
(timout:为等待最大时长,单位秒)
特点:
- 针对所有元素生效
- 一般情况下为前置必写代码(1.获取浏览器驱动对象 2.最大化浏览器 3.隐式元素等待)
1.5.2 显式元素等待


1.6 使用css定位下拉框
html对于下拉框使用的标签是<select>
1.导包:from selenium.webdriver.suport.select import Select
2.实例化:s=select(element)
3.调用方法:s.select_by_index()
提供哪些方法:
- select_by_index() 通过下标定位
- select_by_value() 通过value值
- select_by_visible_text() 显示文本
注意事项:
1.Select类是通过select标签来控制其下的option元素
2.element只能是select标签
1.7 弹出框
对话框类型:
- alert 警告框
- confirm 确认框
- prcmpt 提示框
如果页面有弹出警示框,不处理,接下来的操作不生效

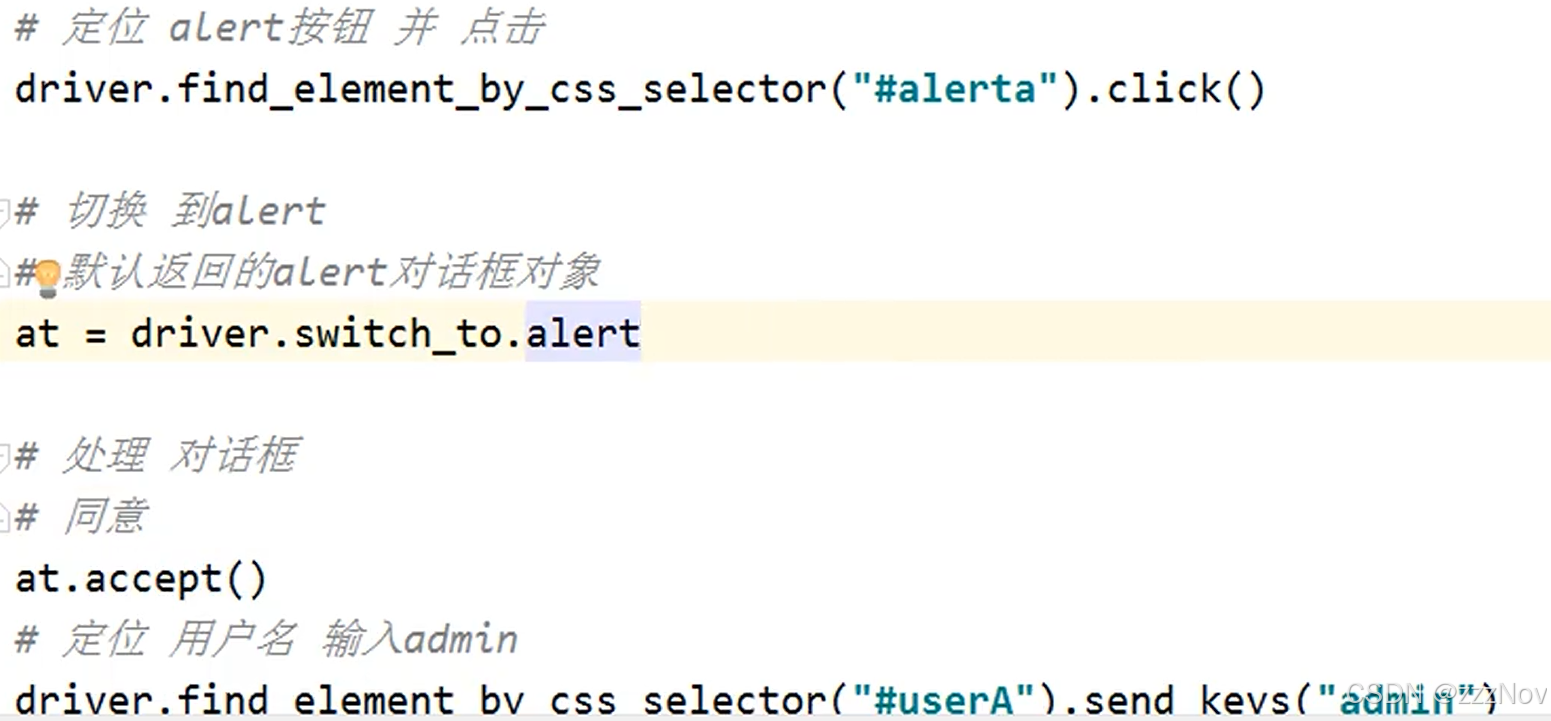
注意:
- driver.switch_to.alert方法适合以上三种类型对话框,调用时没有括号
- 获取文本的方法调用时没有括号 如alert.text
- 在项目中不是所有的小窗口都是以上三种对话框
1.8 滚动条
selenium 中没有直接定位滚动条的方法,可以通过js语句间接控制
1.设置js语句:
js="window.scrollTo(0,100000)"
0:x轴 100000:y轴
2.调用js方法
driver.execute_script(js)
1.9 frame表单切换
常见Frame表单:frame,iframe
- 为什么切换?
当前主目录内没有iframe表单页面元素信息,不切换,找不到元素
- 如何切换:
方法:driver.switch_to.frame("id\name\element")
- 为什么要回到主目录:
iframe或frame只有在主目录采用相关元素信息,不回到主目录,切换语句会报错
- 如何回到主目录:
方法:driver.switch_to.default_content()
- 注意:
切换frame时,可以使用name,id,iframe元素
1.10 切换多窗口
为什么要切换多窗口:
页面存在多个窗口时,selentium默认焦点只会在主窗口上的所有元湿奴,不切换窗口,无法操作主窗口以外的窗口元素
如何切换:
思路:获取要切换的窗口句柄,调用切换方法进行切换
方法:
- driver.current_window_handle 获取当前主窗口句柄
- driver.window_handles 获取当前由driver启动所有窗口句柄
- driver.switch_to.window(handle)
步骤:
- 获取当前窗口句柄
- 点击连接,启动另一个窗口
- 获取当前所有窗口句柄
- 遍历所有窗口句柄
- 判断当前遍历的窗口句柄不等于主窗口句柄
- 切换窗口操作
cu=diver.current_window_handle
cr=diver.window_handles
for j in cr:
if j!=cu:
diver.switch_to.window(j)1.11 窗口截图
driver.get_screenshot_as_file(图片保存地址)
多次产生截图,可以使用时间戳的形式进行区分
操作:
driver.get_screenshot_as_file("./image/ade.jpg" % (time.strftime("%Y_%m_%d_%H_%M_%S")))
strftime:将时间转为字符串函数
1.12 验证码
处理方式:
1.去掉验证码:项目在测试环境,公司自己的项目
2.设置万能验证码:测试环境或线上环境,公司自己的项目
3.使用验证码识别技术;识别效率低,不推荐
4.使用cookie;推荐
1.13 Cookie

应用:
方法:driver.get_cookies() 获取所有的coolie
driver.get_cookies("BDUSS")会返回value值
driver.add_cookie({字典}) 设置cookie
步骤:
- 打开百度url driver.get("http://www.baidu.com")
- 设置cookie信息: driver.add_cookie({"name":"BDUSS":"value":"根据实际情况编写"})
- 暂停2秒以上
- 刷新操作
2. UnitTest框架
UnitTest的作用:
- 批量执行用例
- 提供丰富的断言
- 可以生成测试报告
UnitTest是python自带的一种单元测试框架
UnitTest的核心要素:
- TestCase测试用例
- TestSuite测试套件
- TextTestRunner以文本的形式运行测试用例
- TestLoader批量执行测试用例-搜索指定文件夹内指定字母开头的模块--推荐
- Fixture固定装置,两个固定的函数,一个初始化使用,一个结束的时候使用
2.1 TestCase
import unittest
def add(a,b):
return a+b
class Test01(unittest.TestCase):
# 执行要测试的函数
def test_add(self):
print("结果为:",add(1,2))
def test_add2(self):
print("结果为:", add(2, 2))
if __name__ == '__main__':
print("if判断语句里的代码不会被执行,因为__name__不等于__main__而等于模块名")
unittest.main()
- if __name__ == '__main__':
当一个 Python 文件被直接运行时,Python 解释器会将 __name__ 的值设置为 __main__。而当这个文件作为一个模块被导入到其他文件中时,__name__ 的值会被设置为该模块的名称。
- 关于test_add()测试方法虽然没有显式创建对象,但在使用 unittest 框架时,当执行测试时,框架会为 Test01 类创建一个实例。这是因为 unittest 框架会自动实例化 Test01 类,并调用其以 test_ 开头的方法。
步骤:
- 导包
- 新建测试类并继承unittest.TestCase
- 测试方法必须以test开头
运行:
1.运行测试类所有的测试方法,光标定位到当前类运行
2.运行单个测试方法,光标放在当前测试方法运行
2.2 TestSuite

unittest_TestCsae.py
import unittest
def add(a,b):
return a+b
class Test01(unittest.TestCase):
# 执行要测试的函数
def test_add(self):
print("结果为:",add(1,2))
def test_add2(self):
print("结果为:", add(2, 2))
if __name__ == '__main__':
print("if判断语句里的代码不会被执行,因为__name__不等于__main__而等于模块名")
unittest.main()unittest_TestSuite.py
import unittest
class Test02(unittest.TestCase):
def testOutput01(self):
print("第一个output")
def testOutput02(self):
print("第二个output")
if __name__ == '__main__':
print("当前__name__等于:",__name__)run_main.py
import unittest
from unitest_TestCase import Test01
from unittest_TestSuite import Test02
# 实例化suite
suite = unittest.TestSuite()
# 调用添加方法
# 写法1:类名(“方法名”) 注意:方法名称使用双引号
suite.addTest(Test01("test_add"))
suite.addTest(Test01("test_add2"))
# 执行测试类的所有方法
suite.addTest(unittest.makeSuite(Test02))
# 执行测试套件
runner = unittest.TextTestRunner()
runner.run(suite)
TestSuite步骤:
- 导包
- 获取套件对象,suite = unittest.TestSuite()
- 调用addTest()方法,添加测试用例
添加测试用例方法:
- suite.addTest(类名("方法名称")) 添加指定类中指定的测试方法
- suite.addTest(unittest.makeSuite(类名)) 添加指定类中所有以test开头的方法
TextTestRunner:
说明:执行猜测套件方法
步骤
- 导包
- 实例化后去执行套件对象 runner = unit test.textTestRunner()
- 调用run方法执行runner.run()
2.3 TestLoader
将符合条件的测试方法添加到测试套件中
操作:
- 导包
- 调用TestLoader()
- suite = unittest.TestLoader().discover("目录",”“指定字母开头模块文件“)
- suite = unittest.defaultTestLoader.discover()
import unittest
#suite = unittest.TestLoader().discover("./",pattern="unittest*.py")
suite = unittest.defaultTestLoader.discover("./",pattern="unittest*.py")#defaultTestLoader是#TestLoader()的实例化对象
unittest.TextTestRunner().run(suite)2.4 TestSuite和TestLoader的区别
共同点:都是测试套件
不同点:
TestSuit:要么添加指定的测试类中所有test开头的方法,要么添加指定测试类中指定某个test开头的方法
TestLLoader:搜索指定目录下指定字母开头的模块中以test字母开头的方法并将这些方法添加到测试套件中,最后返回测试套件
2.5 fixture
fixture其实就是两个函数,可以一起使用,也可以单独使用
初始化函数:def setUp()
结束函数:def tearDown()
装置函数:
函数级别:def setUp def tearDown--几个测试函数就执行几次,每个测试函数之前都会执行setUP,之后都会执行tearDown
类级别:def setUpClass tearDownClass--几个类就执行几次,每个类之前都会执行setUpClass ,之后都会执行tearDownClass,类方法必须使用@classmethod修饰
模块级别:def setUpModule sef tearDownModule--模块之前都会执行setUpModule ,之后都会执行tearDownModule
常用场景:
初始化:
1.获取浏览器驱动对象
2.最大化浏览器
3.隐式元素等待
结束:
关闭浏览器驱动对象
import unittest
def setUpModule():
print("ssetUpModule被执行")
def tearDownModule():
print("tearDownModule被执行")
class Test03(unittest.TestCase):
@classmethod
def setUpClass(cls):
print("setUpClass被执行")
@classmethod
def tearDownClass(cls):
print("tearDownClass被执行")
def setUp(self):
print("setUp被执行")
def tearDown(cls):
print("tearDown被执行")
def testOutput01(self):
print("第一个output")
def testOutput02(self):
print("第二个output")
class Test04(unittest.TestCase):
@classmethod
def setUpClass(cls):
print("setUpClass被执行")
@classmethod
def tearDownClass(cls):
print("tearDownClass被执行")
def setUp(self):
print("setUp被执行")
def tearDown(cls):
print("tearDown被执行")
def testOutput01(self):
print("第一个output")
def testOutput02(self):
print("第二个output")2.6 断言
什么是断言:
让程序代替人工判断执行结果是否与预期结果相等的过程
为什么要断言:
自动化不写断言,相当于没有执行
常用断言:
- self.assertEqual(a,b) 判断a是否等于b
- self.assertIn(a,b) 判断b是否包含a
- self.assertTure(a)判断a是否为True
import time
import unittest
from exceptiongroup import catch
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.ie.service import Service
class TestTpShopLogin(unittest.TestCase):
# 初始化
def setUp(self):
#获取浏览器驱动
driver = webdriver.Chrome(service=Service(r'D:\Program_files\chromedriver\chromedriver.exe'))
#打开连接
driver.get("")
# 最大化浏览器
driver.maximize_window()
# 隐式等待
driver.implicitly_wait(30)
# 定义tearDown
def tearDown(self):
# 关闭浏览器驱动
self.driver.quit()
# 定义登录测试方法 验证码为空
def test_verify_null(self):
driver = self.driver
# 点击登录连接
driver.find_element(By.PARTIAL_LINK_TEXT, "登录").click()
#输入用户名
driver.find_element(By.CSS_SELECTOR, "#username").send_keys("admin")
#输入密码
driver.find_element(By.CSS_SELECTOR, "#password").send_keys("123321")
#输入验证码
driver.find_element(By.CSS_SELECTOR, "#verify_code").send_keys("")
# 点击登录
driver.find_element(By.CSS_SELECTOR, "#J-login-submit").click()
#获取错误提示
real_result = driver.find_element(By.CSS_SELECTOR, "#layui-layer-content").text()
# 定义预期结果
expect_result = "验证码不能为空!"
try:
# 断言
self.assertEquals(real_result,expect_result)
except AssertionError:
# 截图
driver.get_screenshot_as_file("../image/error.png".format(time.strftime("%Y_%m_%d_%H_%M_%S")))
raise#raise 重新抛出 AssertionError 异常,这样在测试框架或日志中可以记录这个异常,以便进行进一步的处理或查看
扩展:
断言有两种方法:
方法1:unittest框架中断言
方法2:使用python自带的断言
- assert a==b 判断a是否等于b
- assert a in b 判断 b是否包含a
- assert True/1 判断是否为true
2.7 参数化
为什么需要参数化?
解决冗余代码问题
根据需求动态获取参数并引用的过程
解决相同业务逻辑,不同测试数据问题
应用
1.下载插件:
2.导包:from parameterized import parameterized
3.修饰测试函数 @parameterized.expand(数据)
数据格式:
1.单个参数,类型为列表
2.多个参数,类型为列表嵌套元组
3.在测试函数中的参数设置变量引用参数值,变量的数量必须和数据值的个数相同
import unittest
from parameterized import parameterized
def get_data():
return [(1,2,3),(3,0,3),(1,3,4)]
class Test01(unittest.TestCase):
# # 单个参数使用方法
# @parameterized.expand(["1","2","3"])
# def test_add_one(self,num):
# print("num:",num)
# # 多个参数使用方法1
# @parameterized.expand([(1,2,3),(3,0,3),(1,3,4)])
# def test_add_two(self,a,b,c):
# print(f"{a}+{b}={c}")
# # 多个参数使用方法2
# data = [(1,2,3),(3,0,3),(1,3,4)]
# @parameterized.expand(data)
# def test_add_two(self, a, b, c):
# print(f"{a}+{b}={c}")
#
# 多个参数使用方法3
@parameterized.expand(get_data())
def test_add_two(self, a, b, c):
print(f"{a}+{b}={c}")2.8 跳过方法
分类:
1.直接跳过:语法:@unittest.skip(说明)
场景:一般功能还未实现完成用例
2.条件满足跳过:语法:@unittestif.skip(说明)
场景:判断条件满足,就跳过,如达到指定版本,此功能就失效
说明:以上两种方式都可以修饰类和方法
import unittest
from xml.sax.handler import version
version = 30
class Test01(unittest.TestCase):
@unittest.skip("功能未完成")
def test01(self):
print("test01")
"""功能未完成"""
pass
@unittest.skipIf(version > 25,"跳过")
def test02(self):
print("test02")
3. HTML报告生成
根据TextTestRunner改编而来
操作
- 导包 from xx.HTMLTestRunner import HTMLTestRunner
- 定义测试套件 suite=unittest.defaultTestLOader.discover("../casse",patten="test*.py")
- 获取报告文件名并执行 report_dir = "../report/{}.html".format(time.strfTime("%Y_%m_%d_%H_%M_%S))
with open(report_dir,“wb”) as f 注:生成html报告,必须使用wb,以二进制形式写入
#实例化HTMLTestRunner类
HTMLTestRunner(stream=f,verbosity=2,title="XX项目自动化测试报告",descrition="操作系统 win 7").run(suite)
4.PO模式

4.1 V1版本
缺点:无法批量运行
test_login_username_not_exist.py
# 导包
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 获取driver对象
driver = webdriver.Chrome(service=Service(r'D:\Program_files\chromedriver\chromedriver.exe'))
# 最大化浏览器
driver.maximize_window()
# 隐式等待
driver.implicitly_wait(30)
# 打开url
driver.get("")
# 点击登录连接
driver.find_element(By.PARTIAL_LINK_TEXT, "登录").click()
#输入用户名
driver.find_element(By.CSS_SELECTOR, "#username").send_keys("aliixe")
#输入密码
driver.find_element(By.CSS_SELECTOR, "#password").send_keys("123321")
#输入验证码
driver.find_element(By.CSS_SELECTOR, "#verify_code").send_keys("")
# 点击登录
driver.find_element(By.CSS_SELECTOR, "#J-login-submit").click()
#获取错误提示
msg = driver.find_element(By.CSS_SELECTOR, "#layui-layer-content").text()
# 断言
assert msg == "账号不存在! "
# 点击提示框确定按钮
driver.find_element(By.CSS_SELECTOR, ".layui-layer-btn0").click()
# 关闭
driver.quit()test_login_password_error.py
# 导包
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 获取driver对象
driver = webdriver.Chrome(service=Service(r'D:\Program_files\chromedriver\chromedriver.exe'))
# 最大化浏览器
driver.maximize_window()
# 隐式等待
driver.implicitly_wait(30)
# 打开url
driver.get("")
# 点击登录连接
driver.find_element(By.PARTIAL_LINK_TEXT, "登录").click()
#输入用户名
driver.find_element(By.CSS_SELECTOR, "#username").send_keys("admin")
#输入密码
driver.find_element(By.CSS_SELECTOR, "#password").send_keys("453321")
#输入验证码
driver.find_element(By.CSS_SELECTOR, "#verify_code").send_keys("")
# 点击登录
driver.find_element(By.CSS_SELECTOR, "#J-login-submit").click()
#获取错误提示
msg = driver.find_element(By.CSS_SELECTOR, "#layui-layer-content").text()
# 断言
assert msg == "密码错误!"
# 点击提示框确定按钮
driver.find_element(By.CSS_SELECTOR, ".layui-layer-btn0").click()
# 关闭
driver.quit()4.2 V2版本
缺点:业务脚本与页面对象没有分开
test_login.py
# 导包
import unittest
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 新建测试类继承
class TestLogin(unittest.TestCase):
driver = None
@classmethod
#初始化 setUp
def setUpClass(cls):
# 获取driver对象
cls.driver = webdriver.Chrome(service=Service(r'D:\Program_files\chromedriver\chromedriver.exe'))
# 最大化浏览器
cls.driver.maximize_window()
# 隐式等待
cls.driver.implicitly_wait(30)
# 打开url
cls.driver.get("")
# 点击登录连接
cls.driver.find_element(By.PARTIAL_LINK_TEXT, "登录").click()
# 结束 tearDown
@classmethod
def tearDownClass(cls):
# 关闭浏览器
cls.driver.quite()
# 新建测试方法 用户名不存在
def test_login_username_not_exist(self):
# 输入用户名
self.driver.find_element(By.CSS_SELECTOR, "#username").send_keys("aliixe")
# 输入密码
self.driver.find_element(By.CSS_SELECTOR, "#password").send_keys("123321")
# 输入验证码
self.driver.find_element(By.CSS_SELECTOR, "#verify_code").send_keys("")
# 点击登录
self.driver.find_element(By.CSS_SELECTOR, "#J-login-submit").click()
# 获取错误提示
msg = self.driver.find_element(By.CSS_SELECTOR, "#layui-layer-content").text()
try:
# 断言
self.assertEquals(msg,"账号不存在! ")
# 点击提示框确定按钮
self.driver.find_element(By.CSS_SELECTOR, ".layui-layer-btn0").click()
except AssertionError:
#截图
self.driver.get_screenshot_as_file("../image/fail.png")
# 新建测试方法 密码错误
def test_login_password_error(self):
# 输入用户名
self.driver.find_element(By.CSS_SELECTOR, "#username").send_keys("admin")
# 输入密码
self.driver.find_element(By.CSS_SELECTOR, "#password").send_keys("1567321")
# 输入验证码
self.driver.find_element(By.CSS_SELECTOR, "#verify_code").send_keys("")
# 点击登录
self.driver.find_element(By.CSS_SELECTOR, "#J-login-submit").click()
# 获取错误提示
msg = self.driver.find_element(By.CSS_SELECTOR, "#layui-layer-content").text()
try:
# 断言
self.assertEquals(msg, "密码错误! ")
# 点击提示框确定按钮
self.driver.find_element(By.CSS_SELECTOR, ".layui-layer-btn0").click()
except AssertionError:
# 截图
self.driver.get_screenshot_as_file("../image/fail.png")4.3 V3版本
缺点:代码冗余量大
page_login.py页面层
"""
页面层
页面对象编写技巧:
类名:使用大驼峰将模块名抄进来,有下划线就去掉下划线
方法:根据业务需求每个操作步骤单独封装到一个方法
"""
from selenium.webdriver.chrome import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
class PageLogin:
def __init__(self):
# 获取driver对象
self.driver = webdriver.Chrome(service=Service(r'D:\Program_files\chromedriver\chromedriver.exe'))
# 最大化浏览器
self.driver.maximize_window()
# 隐式等待
self.driver.implicitly_wait(30)
# 打开url
self.driver.get("")
# 点击登录
def page_click_login_link(self):
self.driver.find_element(By.PARTIAL_LINK_TEXT, "登录").click()
# 输入用户名
def page_inpput_username(self,username):
self.driver.find_element(By.CSS_SELECTOR, "#username").send_keys(username)
# 输入密码
def page_input_password(self,password):
self.driver.find_element(By.CSS_SELECTOR, "#password").send_keys(password)
# 输入验证码
def page_input_verify(self,code):
self.driver.find_element(By.CSS_SELECTOR, "#verify_code").send_keys(code)
# 获取异常提示信息
def page_get_error(self):
return self.driver.find_element(By.CSS_SELECTOR, "#layui-layer-content").text()
# 点击提示框确定按钮
def page_click_err_btn(self):
self.driver.find_element(By.CSS_SELECTOR, ".layui-layer-btn0").click()
# 组装登录业务方法 给业务层调用
def page_login(self,username,password,code):
self.page_click_login_link()
self.page_inpput_username(username)
self.page_input_password(password)
self.page_input_verify(code)
self.page_get_error()
self.page_click_err_btn()
test_login.py
# 导包
import unittest
from PO.v3.page.page_login import PageLogin
from parameterized import parameterized
# 新建测试类
class TestLogin(unittest.TestCase):
# 初始化方法
def setUp(self):
self.login = PageLogin()
# 结束方法
def tearDown(self):
self.login.driver.quit()
# 新建测试方法
@parameterized([('aslid','123321','8888','账号不存在!'),('admin','123325671','8888','密码错误!')])
def test_login(self,username,password,code,expect_result):
self.login.page_login(username,password,code)
# 获取登陆后的信息
msg = self.login.page_get_error()
# 断言
assert msg == expect_result
# 点击确定
self.login.page_click_login_link()4.4 V4版本
1.base(基类),page页面一些公共的方法
# base类
- 初始化方法
- 查找元素对象
- 点击元素对象
- 输入方法
- 获取文本方法
- 截图方法
注意:
以上方法封装的时候,解包只需一次,在查找元素解包
driver为虚拟,谁调用base时,谁传入,无需关注从哪来
loc真正使用loc的方法只有查找
2.page(页面对象):一个页面封装成一个对象
应用:继承base
实现:
- 模块名。page+实际操作模块名称 如:page_login.py
- 页面对象名:以大驼峰方法将模块名抄进来,有下划线的去掉下划线
- 方法:涉及元素,将每个元素操作单独封装一个操作方法
- 组装:根据需求组装以上操作步骤:
3.scripts(业务对象):导包,调用page页面
实现:
- 模块:test+实际操作模块名称 如:test login.py
- 测试业务名称,以大驼峰方法将模块名抄进来,有下划线的去掉下划线
- 方法:
- 初始化方法:setup(),注意:在unittest框架中不能使用def __init__()初始化方法
- 实例化页面对象
- 前置操作:如打开等等
- 初始化方法:setup(),注意:在unittest框架中不能使用def __init__()初始化方法
2.结束方法 tearDown()
关闭驱动
3.测试方法:根据要操作的业务来实现
扩展:loc变量:类型为元组,*loc为解包
base.py
from selenium.webdriver.chrome import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.wait import WebDriverWait
class Base:
# 初始化方法
def __init__(self):
# 获取driver对象
self.driver = webdriver.Chrome(service=Service(r'D:\Program_files\chromedriver\chromedriver.exe'))
# 最大化浏览器
self.driver.maximize_window()
# 打开url
self.driver.get("")
# 查找元素(提供给以下三个方法使用)
def base_find_element(self,loc,timeout=30,poll_frequency=0.5):
return WebDriverWait(self.driver,timeout=timeout,poll_frequency=poll_frequency).until(lambda x : x.find_element(*loc))
# 点击方法
def base_click(self,loc):
self.base_find_element(loc).click()
# 输入方法
def base_input(self,loc,value):
el = self.base_find_element(loc)
# 清空内容
el.clear()
# 输入
el.send_keys(value)
# 获取文本方法
def base_get_text(self,loc):
return self.base_find_element(loc).text()
# 截图方法
def base_get_screenshot(self):
self.driver.get_screenshot_as_file("../image/fail.png")
page/__init__.py
from selenium.webdriver.common.by import By
"""以下为登录页面元素配置信息"""
# 登录链接
login_link = By.PARTIAL_LINK_TEXT, "登录"
# 用户名
login_username = By.CSS_SELECTOR, "#username"
# 密码
login_password= By.CSS_SELECTOR, "#password"
# 验证码
login_verify_code = By.CSS_SELECTOR, "#verify_code"
# 登录按钮
login_btn = By.CSS_SELECTOR,".J-login-submit"
# 获取异常文本信息
login_err_info = By.CSS_SELECTOR, "#layui-layer-content"
# 点击异常提示框 按钮
login_err_btn_ok = By.CSS_SELECTOR, ".layui-layer-btn0"page_login.py
"""
页面层
页面对象编写技巧:
类名:使用大驼峰将模块名抄进来,有下划线就去掉下划线
方法:根据业务需求每个操作步骤单独封装到一个方法
"""
from selenium.webdriver.chrome import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from PO.v4 import page
from PO.v4.base.base import Base
class PageLogin(Base):
# 点击登录
def page_click_login_link(self):
self.base_click(page.login_link)
# 输入用户名
def page_inpput_username(self,username):
self.base_input(page.login_username,username)
# 输入密码
def page_input_password(self,password):
self.base_input(page.login_password,password)
# 输入验证码
def page_input_verify(self,code):
self.base_input(page.login_verify_code,code)
# 点击登录按钮
def page_click_login_btn(self):
self.base_click(page.login_btn)
# 获取异常提示信息
def page_get_error(self):
return self.base_get_text(page.login_err_info)
# 点击提示框确定按钮
def page_click_err_btn(self):
self.base_click(page.login_err_btn_ok)
# 截图
def page_get_screenshot(self):
self.base_get_screenshot()
# 组装登录业务方法 给业务层调用
def page_login(self,username,password,code):
self.page_inpput_username(username)
self.page_input_password(password)
self.page_input_verify(code)
self.page_click_login_btn()
test_login.py
# 导包
import unittest
from PO.v4.page.page_login import PageLogin
from parameterized import parameterized
def get_data():
return [('aslid','123321','8888','账号不存在!'),('admin','123325671','8888','密码错误!')]
# 新建测试类
class TestLogin(unittest.TestCase):
# 初始化方法
def setUp(self):
self.login = PageLogin()
# 点击登录连接
self.login.page_click_login_link()
# 结束方法
def tearDown(self):
self.login.driver.quit()
# 新建测试方法
@parameterized(get_data())
def test_login(self,username,password,code,expect_result):
self.login.page_login(username,password,code)
# 获取登陆后的信息
msg = self.login.page_get_error()
try:
# 断言
assert msg == expect_result
except AssertionError:
# 截图
self.login.page_get_screenshot()
# 点击确定
self.login.page_click_login_link()5. 数据驱动
通过测试数据控制用例的执行,直接影响测试结果
数据驱动是最好结合po+参数化技术使用
优点:将维护关注点放到测试数上,而不去关注测试脚本代码
数据驱动常用的格式:
- json(重要)
- Excel
- csv
- txt
补充:
json与字典转换:
字典转为json字符串---方法:json.dumps()
字符串转字典---方法:json.loads()
ex:
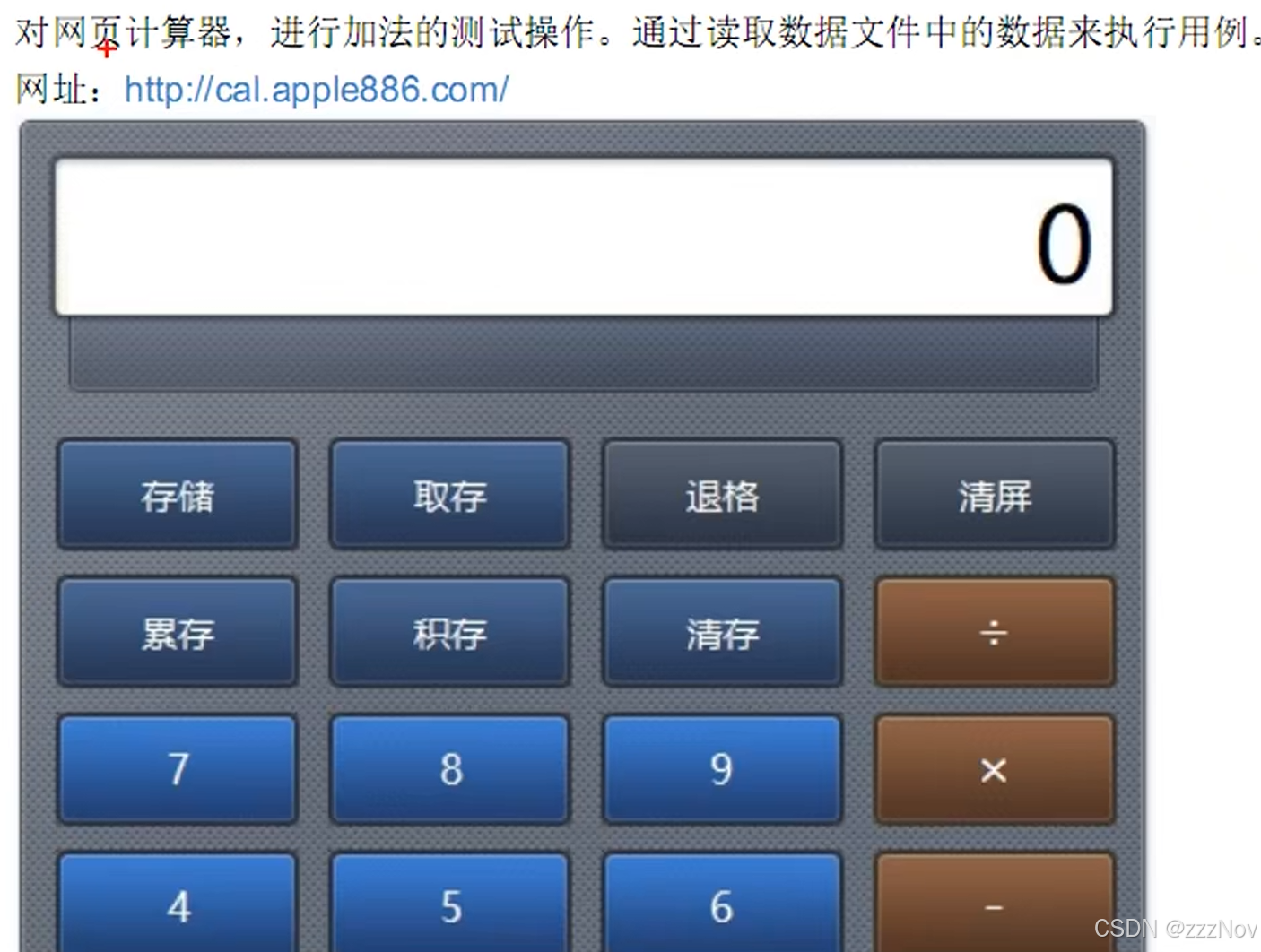
分析:
base:
# 初始化方法
# 查找元素
# 点击元素
# 获取value属性方法封装
# 截图
page:
# 点击数字方法
for n in str(num):
# 拆开单个按钮的定位方法
loc = By.CSS_SELECTOR,"simple{}".format(n)
# 点击加号
# 点击等号
# 获取结果方法
# 点击清屏
# 截图
# 组装
transaction:
#初始化页面对象
获取页面对象
获取driver
#结束方法
关闭driver
# 测试加法方法
调用加法业务方法
断言
截图
driver封装:
@classmethod
# 获取driver对象
@classmethod
# 关闭driver对象
base/base.py
from datetime import time
from selenium.webdriver.support.wait import WebDriverWait
class Base:
# 初始化方法
def __init__(self, driver):
self.driver = driver
# 查找元素
def base_find_element(self, loc, timeout=30, poll_frequency=0.5):
return WebDriverWait(self.driver, timeout=timeout, poll_frequency=poll_frequency).until(
lambda x: x.find_element(*loc))
# 点击元素
def base_click(self, loc):
self.base_find_element(loc).click()
# 获取value属性方法封装
def base_get_value(self, loc):
return self.base_find_element(loc).get_attribute("value")
# 截图
def base_get_screenshot(self):
self.driver.get_screenshot_as_file("../image/{}.png".format(time.strftime("%Y_%m_%d %H_%M_%S")))
base/get_driver.py
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from po1 import page
class GetDriver:
driver = None
@classmethod
def get_driver(cls):
if cls.driver is None:
#实例化driver
cls.driver = webdriver.Chrome(service=Service(r'D:\Program_files\chromedriver\chromedriver.exe'))
# 最大化浏览器
cls.driver.maximize_window()
# 打开浏览器
cls.driver.get(page.url)
return cls.driver
@classmethod
def quit_driver(cls):
if cls.driver:
cls.driver.quit()
# 注意:关闭后要置空
cls.driver = Nonepage/__init__.py
"""以下为浏览器配置"""
url = "http://cal.apple886.com/"
"""
以下为page配置数据
"""
from selenium.webdriver.common.by import By
# 由于数字键有规律,所以暂时先不定位
calc_num = By.CSS_SELECTOR,"simple9"
clac_add = By.CSS_SELECTOR,"#simpleAdd"
calc_eq = By.CSS_SELECTOR,"#simpleEqual"
calc_result = By.CSS_SELECTOR,"#resultIpt"
calc_clear = By.CSS_SELECTOR,"#simpleClearAllBtn"page/page_calc.py
from selenium.webdriver.common.by import By
from po1 import page
from po1.base.base import Base
class PageCalc(Base):
# 点击数字方法
def page_click_num(self,num):
for n in str(num):
# 拆开单个按钮的定位方法
loc = By.CSS_SELECTOR, "#simple{}".format(n)
self.base_click(loc)
# 点击加号
def page_click_add(self):
self.base_click(page.clac_add)
# 点击等号
def page_click_eq(self):
self.base_click(page.calc_eq)
# 获取结果方法
def page_get_result(self):
return self.base_get_value(page.calc_result)
# 点击清屏
def page_clear(self):
self.base_click(page.calc_clear)
#截屏
def page_get_image(self):
self.base_get_screenshot()
# 组装
def page_add_calc(self,a,b):
self.page_click_num(a)
self.page_click_add()
self.page_click_num(b)
self.page_click_eq()
transaction/test_calc.py
import unittest
from parameterized import parameterized
from po1.base.get_driver import GetDriver
from po1.page.page_calc import PageCalc
from po1 import base
def get_data():
return [(3,4,7),(23,459,482)]
class TestCalc(unittest.TestCase):
driver = None
#setupClass
@classmethod
def setUpClass(cls):
cls.driver = GetDriver.get_driver()
#初始化页面对象
cls.calc = PageCalc(cls.driver)
# tearDown
@classmethod
def tearDownClass(cls):
# 关闭driver
GetDriver.quit_driver()
pass
# 测试加法方法
@parameterized.expand(get_data())
def test_add_calc(self,a,b,expect):
# 调用计算业务方法
self.calc.page_add_calc(a,b)
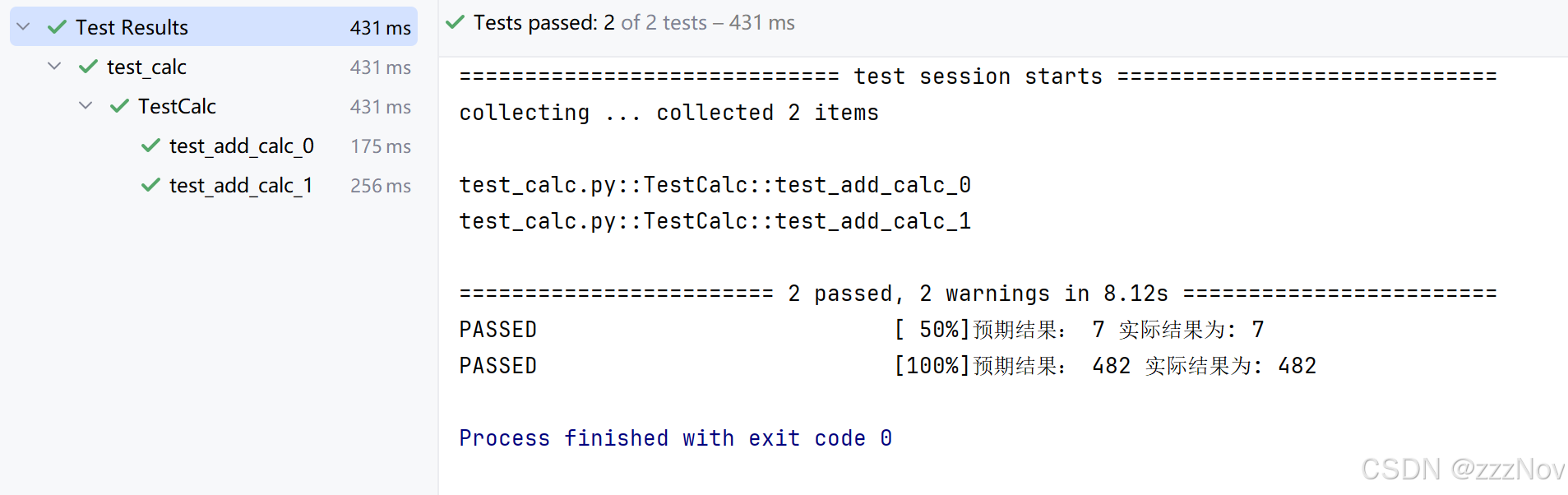
print("预期结果:",expect,"实际结果为:",self.calc.page_get_result())
# 断言
try:
self.assertEquals(self.calc.page_get_result(),str(expect))
except:
# 截图
self.calc.page_get_image()
raise运行结果:
读取json数据封装:
1.准备json数据
{
"calc001":{"a": 1,"b": 2,"c": 3},
"calc002":{"a": 180,"b": 20,"c": 200},
"calc003":{"a": 199,"b": 2,"c": 201}
}2.读取工具封装
import json
def read_json(filename):
filepath = "../data/" + filename
with open(filepath,"r",encoding="utf-8") as f:
return json.load(f)
if __name__ == "__main__":
datas = read_json("calc.json")
print(datas) # {'calc001': {'a': 1, 'b': 2, 'c': 3}, 'calc002': {'a': 180, 'b': 20, 'c': 200}, 'calc003': {'a': 199, 'b': 2, 'c': 201}}
# 需要格式:(1,2,3),(4,5,9)
arr = []
for data in datas.values():
print(data) # {'a': 1, 'b': 2, 'c': 3}
arr.append((data['a'],data['b'],data['c']))
print(arr) # [(1, 2, 3), (180, 20, 200), (199, 2, 201)]3.数据转换
def get_data():
datas = read_json("calc.json")
# print(datas) # {'calc001': {'a': 1, 'b': 2, 'c': 3}, 'calc002': {'a': 180, 'b': 20, 'c': 200}, 'calc003': {'a': 199, 'b': 2, 'c': 201}}
# 需要格式:(1,2,3),(4,5,9)
arr = []
for data in datas.values():
print(data) # {'a': 1, 'b': 2, 'c': 3}
arr.append((data['a'], data['b'], data['c']))
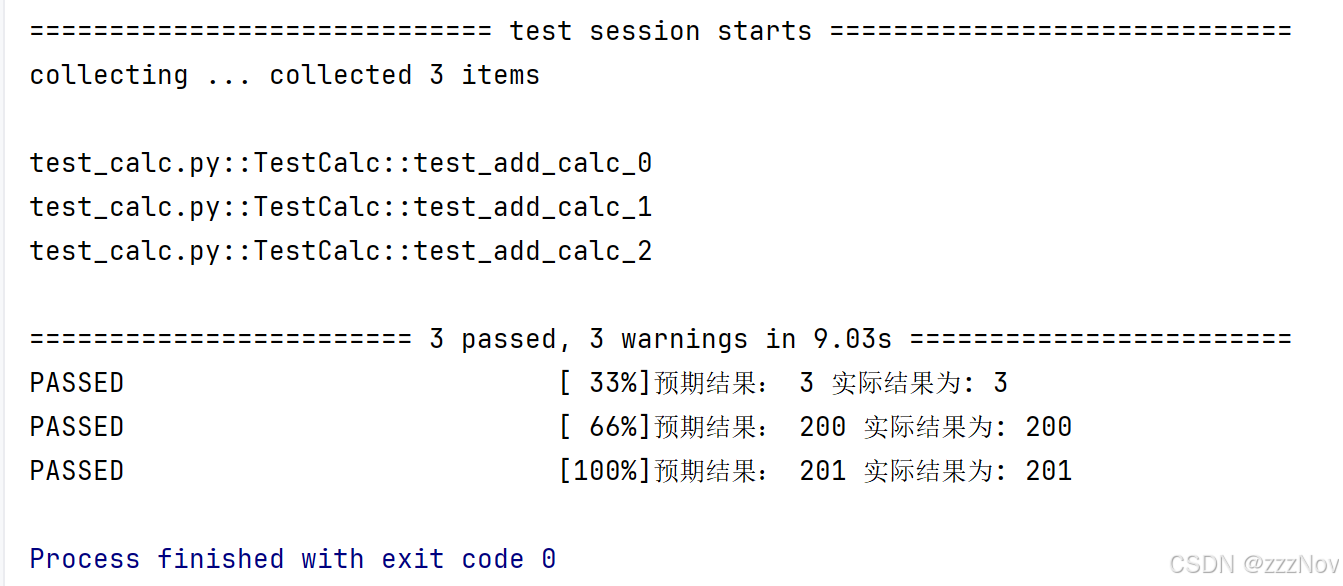
print(arr) # [(1, 2, 3), (180, 20, 200), (199, 2, 201)]
return arr运行结果
6. 日志
说明:记录系统运行程序一些步骤,对一个事件(点击事件),也称为日志
特点:
- 调试程序
- 了解系统程序运行的情况,是否正常
- 系统程序运行故障分析与问题定位
- 分析用户行为分析与数据统计
级别:


logging的基本使用
步骤:
- 导包
- 调用相应的级别方法,记录日志信息 logging.debug("debug.....")
设置级别
logging.basicConfig(level=logging.DEBUG)
提示:
- 默认级别为:logging.WARNING
- 设置级别是调用的是logging文件夹下面的常量,而不是调用的小写方法
- 切记:设置级别后,日志信息只会记录大于等于此级别的信息
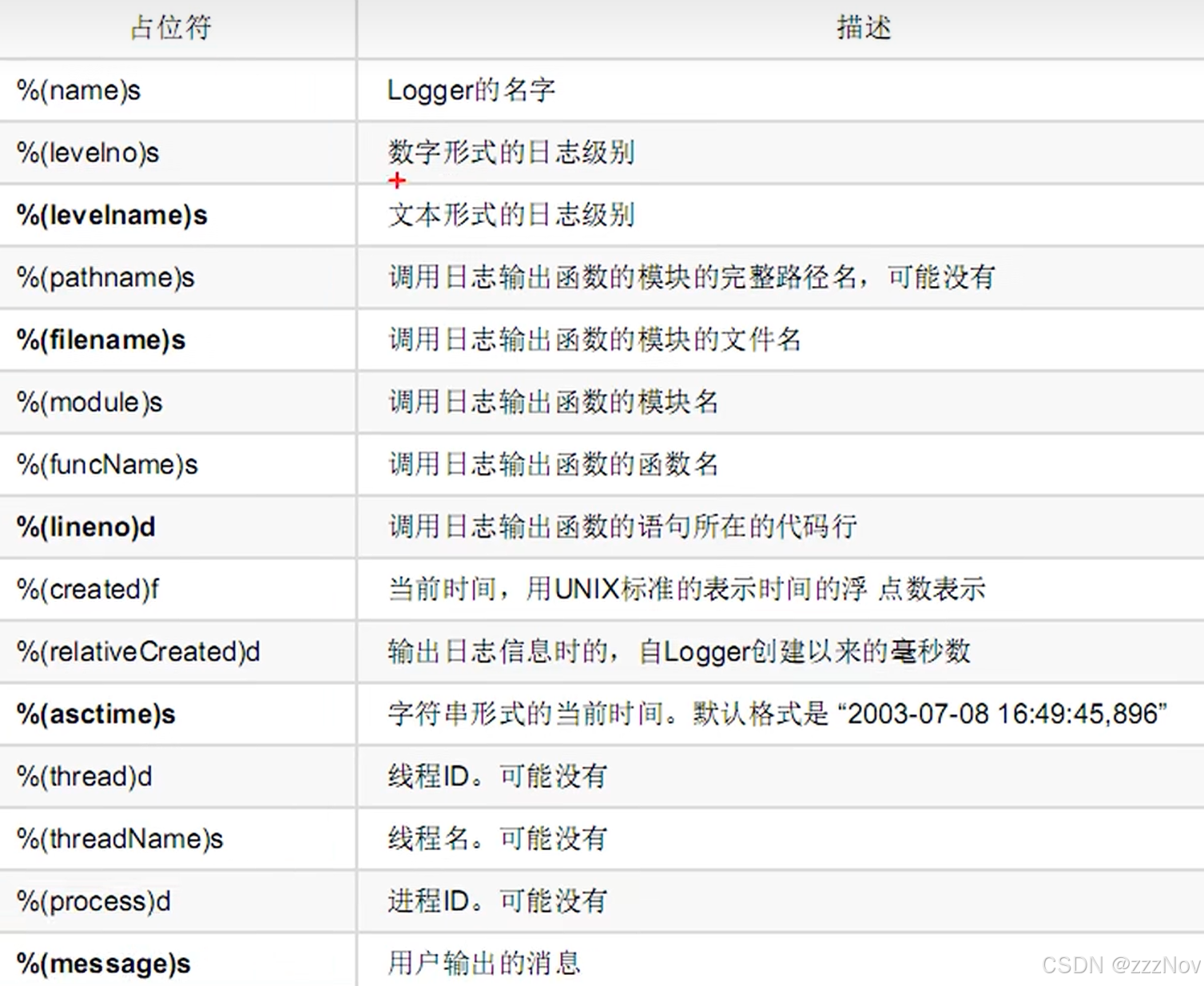
日志的默认格式:
日志级别:Logger 名称:日志内容
自定义日志格式:
fm = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
logging.basicConfig(format=fm)
日志保存到指定的文件:
logging.basicConfig(filename="a.log")
给上次的加法计算器加上日志
新建tool文件夹新建get_log.py
import logging
def get_logging():
fm = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
logging.basicConfig(level=logging.INFO,filename="../log/log01.log",format=fm)
return logging
if __name__ == "__main__":
log = get_logging()
log.info("This is an info message")在base.py添加log代码
import time
from selenium.webdriver.support.wait import WebDriverWait
from po1.tools.get_log import get_logging
class Base:
# 初始化方法
def __init__(self, driver):
get_logging().info("初始化driver{}".format(driver))
self.driver = driver
# 查找元素
def base_find_element(self, loc, timeout=30, poll_frequency=0.5):
get_logging().info("正在查找元素{}".format(loc))
return WebDriverWait(self.driver, timeout=timeout, poll_frequency=poll_frequency).until(
lambda x: x.find_element(*loc))
# 点击元素
def base_click(self, loc):
get_logging().info("正在点击元素{}".format(loc))
self.base_find_element(loc).click()
# 获取value属性方法封装
def base_get_value(self, loc):
get_logging().info("正在获取{}元素的值".format(loc))
return self.base_find_element(loc).get_attribute("value")
# 截图
def base_get_screenshot(self):
get_logging().info("正在截图")
self.driver.get_screenshot_as_file("../image/{}.png".format(time.strftime("%Y_%m_%d %H_%M_%S")))
日志四大模块组件:

组件之间的关系:

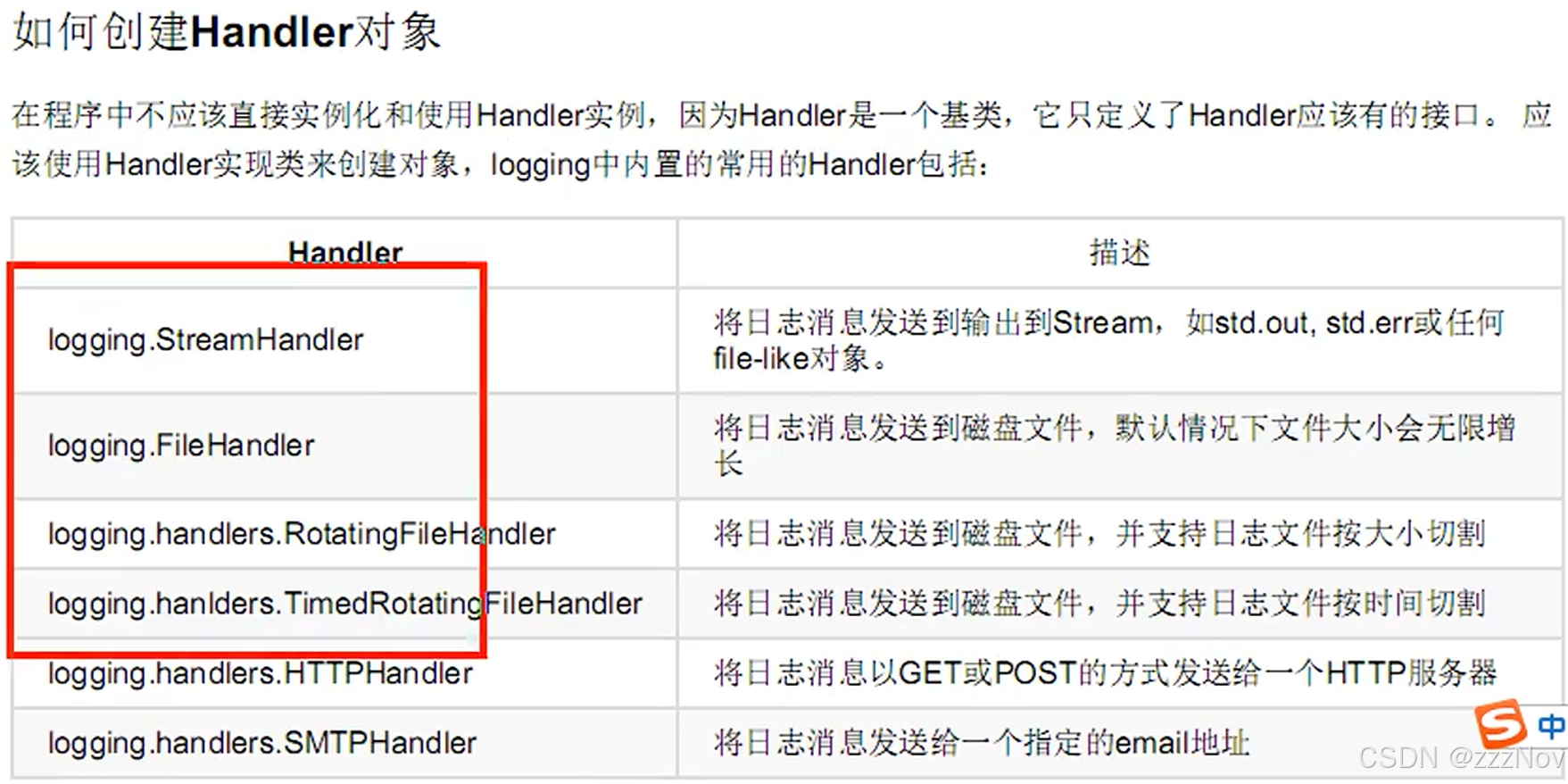
如何创建Handler:
入门:
"""
学习Logging底层模块实现
1.Logger
2.Handler
"""
import logging
# 获取Logger
logger = logging.getLogger()
# 设置级别
logger.setLevel(logging.INFO)
# 获取控制台处理器
console = logging.StreamHandler()
# 将处理器添加到logger
logger.addHandler(console)
# 输入信息
logger.info("info")
logger.debug("debug")TimedRotatingFileHandler
"""
学习Logging底层模块实现
1.Logger
2.TImeRotatingFileHandler
"""
# import logging不推荐这种导包方式
import logging.handlers # 推荐这个,
# 获取Logger
logger = logging.getLogger("admin")
# 设置级别
logger.setLevel(logging.INFO)
# 获取控制台处理器
console = logging.StreamHandler()
log_file= logging.handlers.TimedRotatingFileHandler(filename="../log/loggingHandler.log",when='M',interval=1,backupCount=3)
# 设置log_file的级别,使得error级别的信息在日志中
log_file.setLevel(logging.ERROR)
# 添加格式器
fmt = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
fm = logging.Formatter(fmt)
# 将格式器添加到Handler中
console.setFormatter(fm)
log_file.setFormatter(fm)
# 将处理器添加到logger
logger.addHandler(console)
logger.addHandler(log_file)
# 输入信息
logger.info("info")
logger.debug("debug")
logger.error("error1")
logger.warning("warning")
logger.error("error2")
日志的封装:
# 定义获取日志的类
# 定义类属性 logger = None
@classmethod
# 定义获取logger日志器 的类方法
if cls.logger is Not None # 判断类属性logger是否为空,为空则执行下列步骤
# 获取日志对象
# 设置日志级别
# 获取控制台处理器
# 获取文件处理器
# 获取格式器
# 将格式器添加到处理器中
# 将处理器添加到日志器中
return 类属性logger
注意:
- 以上条件无论是否成立,最后都会返回类属性logger
- 当第一次调用时,条件一定会成立,将类属性logger设置为不为空
- 当第二次及以上调用时,永远返回第一次设置的类属性对象
7. 自动化测试流程


















 1179
1179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









