






第一阶段
第一章--基础语法
字面量:被写在代码中固定的值
注释:
- 单行注释:#+空格+注释内容
- 多行注释:以三个引号开头三个引号结束:"""注释内容"""
变量:在程序运行时,记录数据用的
数据类型:type(),括号内输入字面量(或变量)可以得到该字面量(或变量)的数据类型
数据类型的转换:
- int(x)将x转化为一个整数
- float(x)将x转化为一个浮点数
- str(x)将x转化为字符串
标识符命名规则:
- 内容限定:只允许出现英文、中文(不推荐)、数字(不可以在开头)、下划线
- 大小写敏感:区分大小写
- 不可使用关键字:False、True、None、and、as.......
运算符:
(1)算术运算符:
| + | 加 | |
| — | 减 | |
| * | 乘 | |
| / | 除 | |
| // | 取整除 | 9//2输出结果为4,9.0//2.0输出结果为4.0 |
| % | 取余 | |
| ** | 指数 | a**b为a的b次方 |
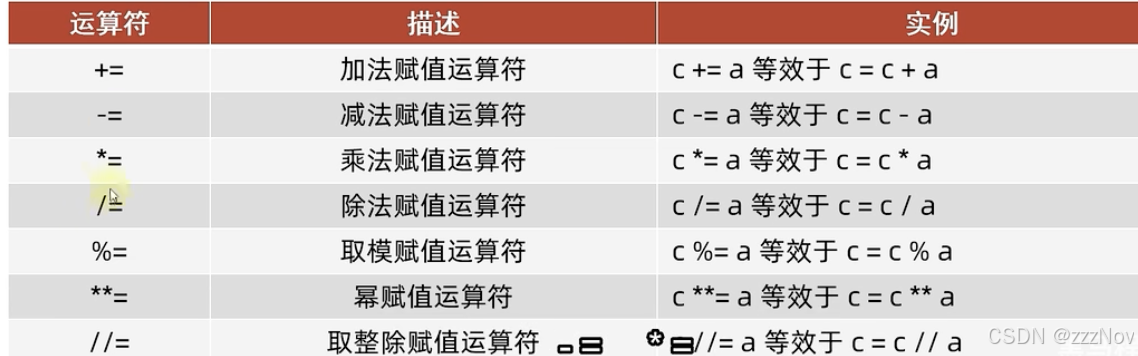
(2)复合赋值运算符:
字符串:
(1)定义方式

(2)拼接
通常用于字面量(字符串类型)和变量(字符串类型)或变量(字符串类型)和变量(字符串类型)之间使用拼接
(3)格式化
字符串无法和数字或其它类型完成拼接,可以使用%s将内容转化为字符串占位,%d将内容转化为整数占位,%f将内容转化为浮点型占位
class_num = 123
avg_salary = 8900
stock_price = 32.09
message = "她的编号是%s,日薪%d,股价%f" % (class_num,avg_salary,stock_price)格式化的精度控制

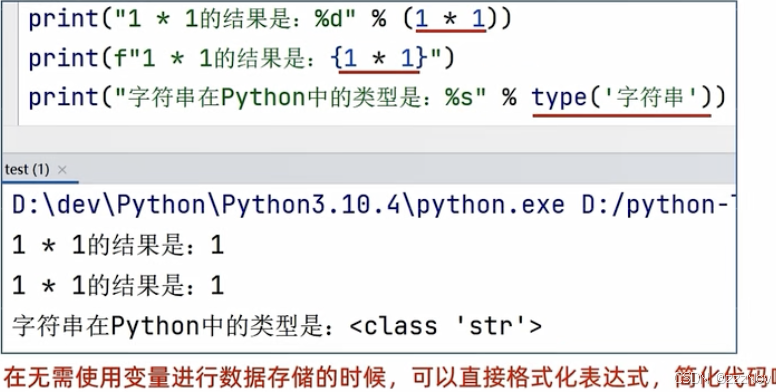
其他格式化方法

对表达式格式化
name = "XXX"
stock_price = 19.99
stock_code = "003032"
stock_price_daily_growth = 1.2 # 股票每日增长系数
growth_days = 7 # 增长天数
print(f"公司:{name},股票代码:{stock_code},当前股价:{stock_price}")
final_stock_price = stock_price * stock_price_daily_growth ** growth_days
print("每日增长系数:%.1f,结果%d天的增长后,股价达到了:%.2f") % (stock_price_daily_growth,growth_day, final_stock_price)数据输入-- input
- 可以读取键盘的输入内容,有一个变量接收读取的内容
- input(提示信息),使用者在输入内容之前可以收到提示信息
- 无论键盘输入的是什么类型的数据,获取到的数据永远是字符串类型
第二章--基础实例
ex:猜数字
num = 100
if int(input("请输入你猜想的数字:")) == num: #代表第一次就猜对
print("恭喜你猜对了!")
elif int(input("猜错了,请再猜一次:")) == num: #代表第二次就猜对
print("恭喜你猜对了!")
elif int(input("猜错了,请再猜一次:")) == num: #代表第三次就猜对
print("恭喜你猜对了!")
else:#第三次也猜错
print("很遗憾,没有通关!")ex:数字随机产生1~100,猜大或猜小会给出提示,猜完后提示猜了几次
import random
num = random.randint(1, 100)
i = 1
flag = True
while flag:
guess_num = int(input("请输入第%d次猜的数字:" % i))
if guess_num == num:
print(f"恭喜你,第{i}次答对了!")
flag = False
else:
if guess_num > num:
print("猜大了")
else:
print("猜小了")
i += 1 ex:使用while,计算1到100的和
# 使用while,计算1到100的和
i = 1
sum = 0
while i <= 100:
sum += i
i += 1
print(f"1到100的和为:{sum}")ex:使用while,打印九九乘法表
# 使用while,打印九九乘法表
# print 语句会自动换行,加上end=''可以输出不换行,\t制表符使得多行字符串对齐
i = 1
while i < 10:
j = 1
while j <= i:
print(f"{j}*{i}={i * j}\t",end='')
j += 1
i += 1
print()# 输出一个换行ex:定义一个变量,统计有多少个a
""""
for循环同while循环不同,for循环是无法定义循环条件的
只能从被处理的数据集中,依次取出内容进行处理
"""
name = "itheima is a brand of itcast"
count = 0
for x in name:
if x == 'a':
count += 1
print(f"{name}中共含有:{count}个字母a")ex:使用for循环打印九九乘法表
""""range(num)获取一个从0开始,到num结束的数字序列,注意不包含num本身
如range(5)取得的数据是:【0,1,2,3,4】
range(num1,num2)获取从num1开始,到num2结束的数字序列,注意不包含num2本身
如range(5,10)取得数据是【5,6,7,8,9】
range(num1,num2,step)获取从num1开始,到num2结束的数字序列,注意不包含num2本身
数字之间的步长,以step为准(默认为1)
如range(5,10,2)取得数据是【5,7,9】
"""
# 使用for打印九九乘法表
for i in range(1,10):
for j in range(1,i+1):
print(f"{j} * {i} = {i * j}\t",end='')
print()ex: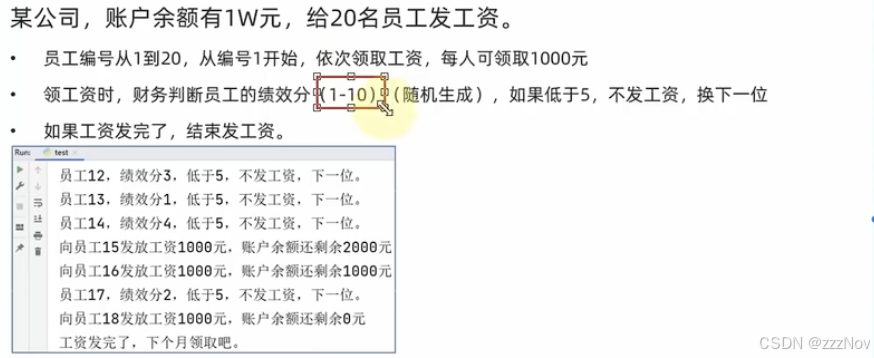
# continue 中断本次循环,直接进入下一次循环
# break 直接结束循环
import random
total = 10000
for p in range(1,21):
if(total > 0):
num = random.randint(1,10)
if(num < 5):
print(f"员工{p},绩效分{num},低于5,不发工资,下一位。")
continue
else:
total -= 1000
print(f"向员工{p}发工资1000元,账户余额还剩余{total}元")
else:
print("工资发完了,下个月")
break
第三章--函数
定义:
def 函数名 (传入参数):
函数体
return 返回值
调用:
函数名()
说明文档:
def func (x,y):
"""
:param x:形参x的说明
:param y:形参y的说明
:return:返回值的说明
"""
函数体
return 返回值
ex:


# 定义全局变量 money、name
money = 50000
name = None
# 要求用户输入姓名
name = input("请输入您的姓名:")
# 定义查询函数
def check(showHeader):
if showHeader:
print("-----查询存款------")
print(f"{name},您的余额为{money}元")
# 定义存款函数
def saving(saveMoney):
global money
money += saveMoney
print("-----存款------")
print(f"{name},您存款{saveMoney}元成功")
check(False)
# 定义取款函数
def getting(getMoney):
print("-----取款------")
global money
if money < getMoney:
printf(f"{name},您取款{getMoney}元失败,余额不足")
else:
money -= getMoney
print(f"{name},您取款{getMoney}元成功")
check(False)
# 定义主菜单函数
def main():
print("----------主菜单----------")
print(f"{name}您好,欢迎使用ATM,请选择你要进行的业务操作")
print("查询余额\t【输入1】")
print("存款\t【输入2】")
print("取款\t【输入3】")
print("退出\t【输入4】")
return input()
# 设置无限循环,确保循环不退出
while True:
i = main()
if i == "1":
check(True)
continue
elif i == "2":
saveMoney = int(input("请输入存款金额:"))
saving(saveMoney)
continue
elif i == "3":
getMoney = int(input("请输入取款金额:"))
getting(getMoney)
continue
else:
print("退出程序")
break
第四章--数据容器
一种可以容纳多份数据的数据类型,容纳的每一份数据称之为1个元素,每一个元素可以是任意类型的数据。
1、list列表
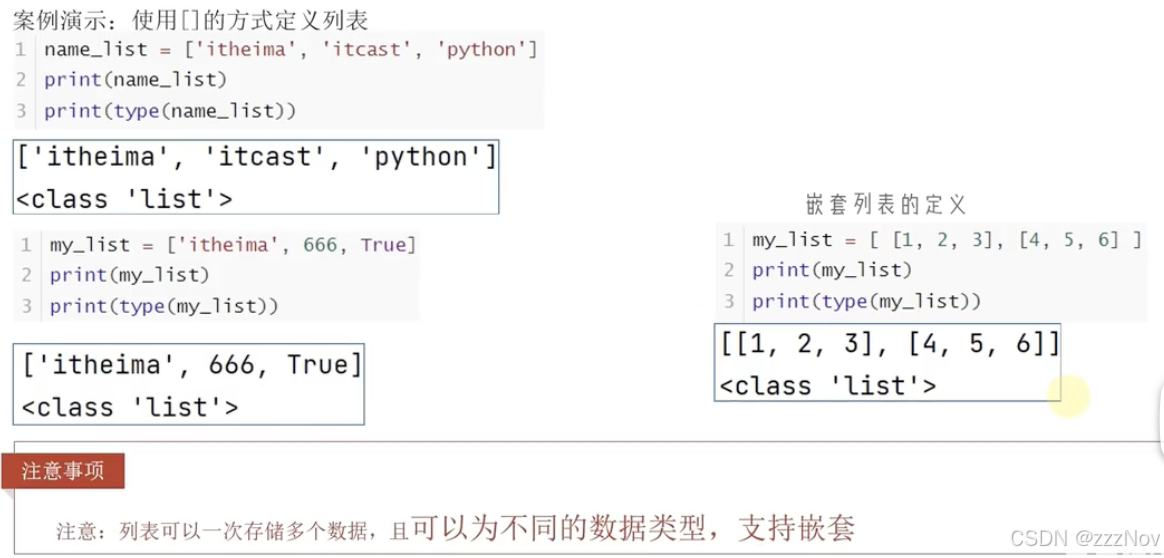
索引下标:
my_list = ["Tom",93,[1,2,3]]
# my_list[0]等于Tom 从前向后,从0开始递增
# my_list[-2]等于93 从后向前,从-1开始递减
# my_list[2][1]等于[1,2,3]里面的2
常用方法
列表.index(元素)---查找指定元素在列表的下标,如果找不到,报错ValueError
列表.insert(下标,元素)---在指定的下标位置,插入指定的元素
列表.append(元素)---将指定的元素,追加到列表的尾部
列表.extend(其他数据容器)---将其他数据容器的内容取出,依次追加到列表尾部
my_list = [1,2,3]
my_list.extend([4,5,6])
print(my_list) # [1,2,3,4,5,6]
del 列表[下标]---删除元素
列表.pop(下标)---删除元素,会返回去除的元素
列表.remove(元素)---删除元素在列表中的第一个匹配项
my_list = [1,2,3,4,2]
my_list.remove(2)
print(my_list) # [1,3,4,2]
列表.clear()---清空列表
列表.count(元素)---统计某元素在列表中的数量
len(列表)---统计列表中的元素数量
ex:

# 定义一个列表,并用变量接受它,内容是:[21,25,21,23,22,20]
my_list = [21,25,21,23,22,20]
# 追加一个数字31,到列表的尾部
my_list.append(31)
print(my_list)
# 追加一个新列表[29,33,30]到列表的尾部
my_list.extend([29,33,30])
print(my_list)
# 取出第一个元素(21)
print(my_list.pop(0))
print(my_list)
# 取出最后一个元素(30)
print(my_list.pop(len(my_list) - 1))
print(my_list)
# 查找元素31,在列表中的下标位置
print(my_list.index(31))ex:

# 定义列表my_list
my_list = [1,2,3,4,5,6,7,8,9,10]
i = 0
while_list = []
for_list = []
# 使用while和for遍历,取出列表中偶数,存入新列表中
while i < len(my_list):
if my_list[i] % 2 == 0:
while_list.append(my_list[i])
else:
continue
i += 1
print(f"通过while循环,从列表{my_list}中取出偶数,组成新列表:{while_list}")
for x in my_list:
for_list.append(x)
print(f"通过for循环,从列表{my_list}中取出偶数,组成新列表:{for_list}")2、turple元组
元组与列表一样,都是可以封装多个、不同类型的元素在内,但不同点是元组一旦定义完成,就不可以修改

注意⚠️:当元组只有一个数据时,这个数据后面要添加逗号---t = ("Hello",)如果不添加不是元组类型
常用方法
元组.index(元素)---查看元素的下标位置
元组.count(元素)---在元组中该元素的数量
len(元组)---元组的长度
不可以修改元组的内容,但是可以修改元组里的list内容
3、str字符串
字符串为一个容器,每个字符为一个元素。
索引同list一样,从前向后,从0开始递增, 从后向前,从-1开始递减
同元组一样,无法修改,如果要修改,只能得到一个新的字符串
常用方法
字符串.index(子串)---返回子串第一个字符的下标位置
字符串.count(元素)---在字符串中该元素出现的次数
len(元组)---元组的长度
字符串.replace(被替换的字符串,新的替换内容)
字符串.split(分割字符串)---按照指定的分隔符分割字符串,将字符串划分为多个字符串,并存入列表对象中;注意字符串本身不变,而是得到一个列表对象
字符串.strip()---去除前后空格
my_str = " itheima and itcast "
print(my_str.split()) #"itheima and itcast"
字符串.strip(字符串)---去除前后指定字符串
my_str = "12itheima and itcast21"
print(my_str.split("12")) #"itheima and itcast" 传入的是“12”,其实是“1”和“2”都会移除,是按照单个字符。
ex:
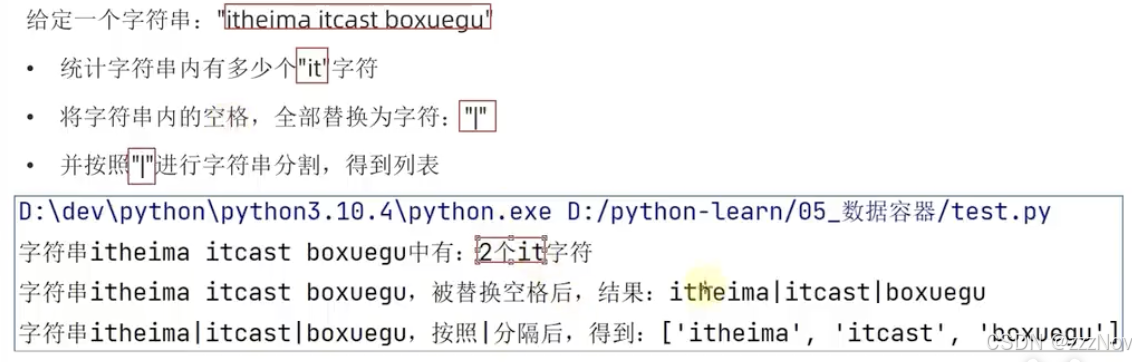
# 定义字符串
my_str = "itheima itcast boxuegu"
num = my_str.count("it")
print(f"字符串{my_str}中有:{num}个it字符")
replace_str = my_str.replace(" ","|")
print(f"字符串{my_str},被替换空格后,结果:{replace_str}")
split_str = replace_str.split("|")
print(f"字符串{replace_str},按照|分隔后,结果:{split_str}")序列
序列:内容连续、有序,可以使用下标索引的一类数据容器;如列表、元组、字符串
切片:从一个序列中,取出一个子序列

ex:

ex_str = "万过薪月,员序程马黑来,nohtyP学"
ex1_str = ex_str[5:10]
ex2_str = ex1_str[::-1]
print(ex2_str)4、set集合
集合定义:
变量名称 = set()
变量名称 = {元素,元素,元素,元素}
因为集合是无序的,所以集合不支持下标索引访问
常用方法
集合.add(元素)--添加已存在的元素,会自动去重
集合.remove(元素)--移除元素
集合.pop()--从集合中随机取出一个元素,会返回取出的元素
集合.clear()--清空集合
集合1.difference(集合2)--取出集合1和集合2的差集(集合1有而集合2没有),得到一个新集合,集合1和集合2不变
set1 = {1,2,3}
set2 = {1,5,6}
set3 = set1.difference(set2)
print(set3) # {2,3}
print(set1) # {1,2,3}
print(set2) # {1,5,6}
集合1.difference_update(集合2)--对比集合1和集合2,在集合1内,删除和集合2相同的元素;集合1被修改,集合2不变
set1 = {1,2,3}
set2 = {1,5,6}
set1.difference_update(set2)
print(set1) # {2,3}
print(set2) # {1,5,6}
集合1.union(集合2)--将集合1和集合2组合成新集合,得到一个新集合,集合1和集合2不变
set1 = {1,2,3}
set2 = {1,5,6}
set3 = set1.union(set2)
print(set3) # {1,2,3,5,6}
print(set1) # {1,2,3}
print(set2) # {1,5,6}
len(集合)--统计集合元素数量
集合只能用for循环遍历
ex:

my_list = ['黑马程序员','传智播客','黑马程序员','传智播客','itheima','itcast','itheima','itcast']
my_set = set()
for x in my_list:
my_set.add(x)
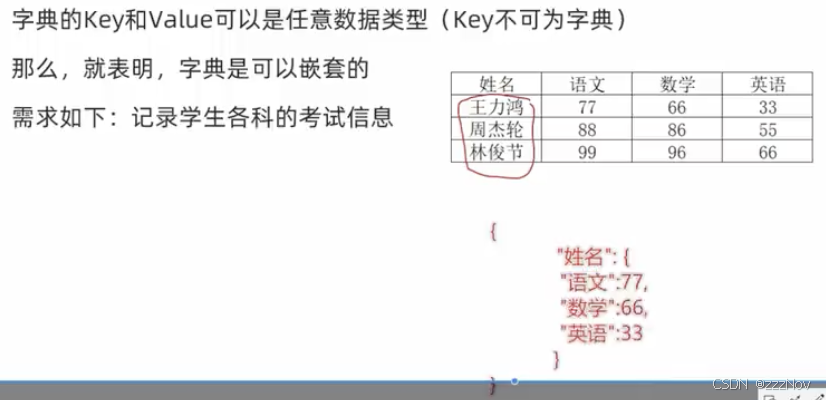
print(my_set)5、dict字典
定义
my_dict = {key:value,key:value,key:value}
my_dict = {}
my_dict = dict()
字典同集合一样,不可存储相同元素,也就不可以使用下标索引,但是字典可以通过Key值来取得对应的value
my_dict = {"name":"Cindy","age":20}
print(my_dict["name"])# Cindy
print(my_dict["age"])#20
常用操作
字典[Key] = Value---新增或更新(如果该key已经存在,则更新value,不存在则新增)
字典.pop(Key)---返回Key的value值,字典被修改指定Key的数据被删除
字典.clear()---清空字典中的全部key
字典.keys()---得到字典中的全部key
len(字典)---字典元素数量
ex:
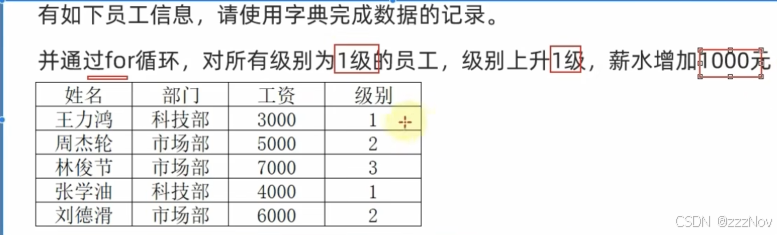
info_dict = {
"王力宏":{
"部门":"科技部",
"工资":3000,
"级别":1
},
"周杰伦":{
"部门":"市场部",
"工资":5000,
"级别":2
},
"林俊杰":{
"部门":"市场部",
"工资":7000,
"级别":3
},
"张学友":{
"部门":"科技部",
"工资":4000,
"级别":1
},
"刘德华":{
"部门":"市场部",
"工资":6000,
"级别":2
}
}
print("升职加薪前:",info_dict)
for key in info_dict:
if info_dict[key]["级别"] == 1:
info_dict[key]["级别"] = 2
info_dict[key]["工资"] += 1000
print("升职加薪后:",info_dict)总结

通用操作
1.max(容器)--获取容器中最大的元素
2.min(容器)--获取容器中最小的元素
3.list(容器)--将给定容器转换为列表(字符串转换为列表会将每个字符作为元素,字典则将每个key作为元素)
4.str(容器)--将给定容器转换为字符串(在原来本体上加上双引号)
5.turple(容器)--将给定容器转换为元组(字符串转换为元组会将每个字符作为元素,字典则将每个key作为元素)
6.set(容器)--将给定容器转换为集合(字符串转换为集合会将每个字符作为元素无序去重,字典则将每个key作为元素无序去重)
7.sorted(容器,reverse=True)--排序,当reverse=True时反向排序
第五章--函数
1.函数的多返回值

2.函数的多种传参方式




3.匿名函数
3.1函数作为参数传递

3.2lambda



第六章--文件
文件编码:将内容翻译为二进制,将二进制翻译为内容
编码技术:UFTF-8、GBK...


1.read
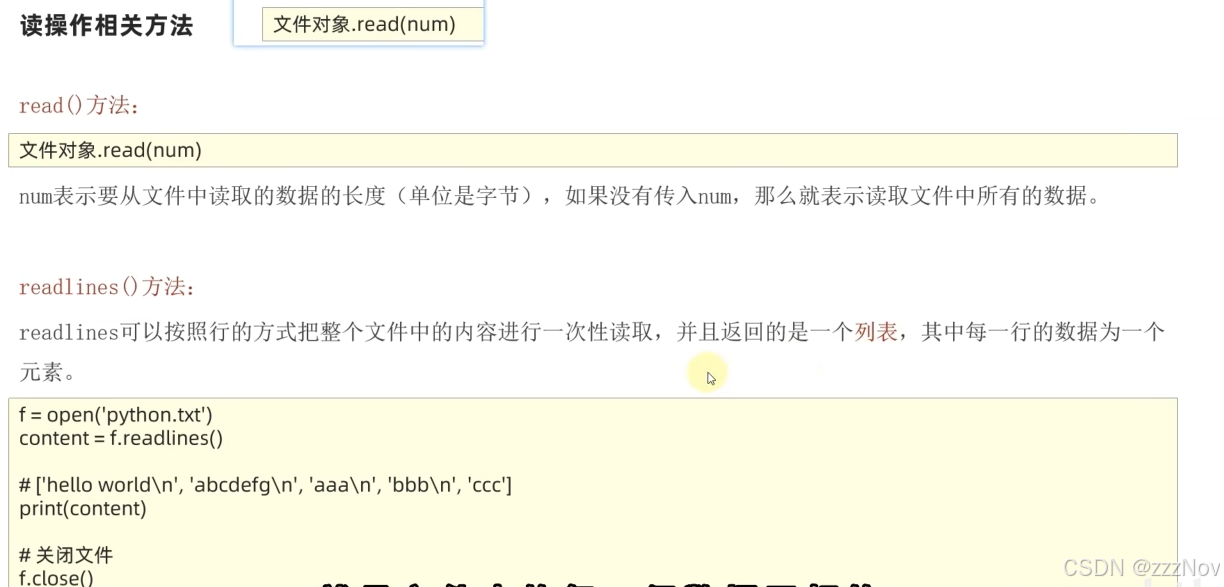




ex:

total = 0
with open("D:\PycharmProjects\python_ex\word.txt","r") as f:
for line in f:
total += line.count("itheima")
print(f"itheima的出现次数为:{total}" )2.write


3.append

ex:


f1 = open("D:\PycharmProjects\python_ex\ill.txt","r",encoding="UTF_8")
f2 = open("D:\PycharmProjects\python_ex\ill2.txt","w",encoding="UTF_8")
for line in f1:
if line.count("测试") != 0:
continue
else:
f2.write(line)
f1.flush()
f2.flush()第七章--异常
1.捕获异常





2.异常的传递

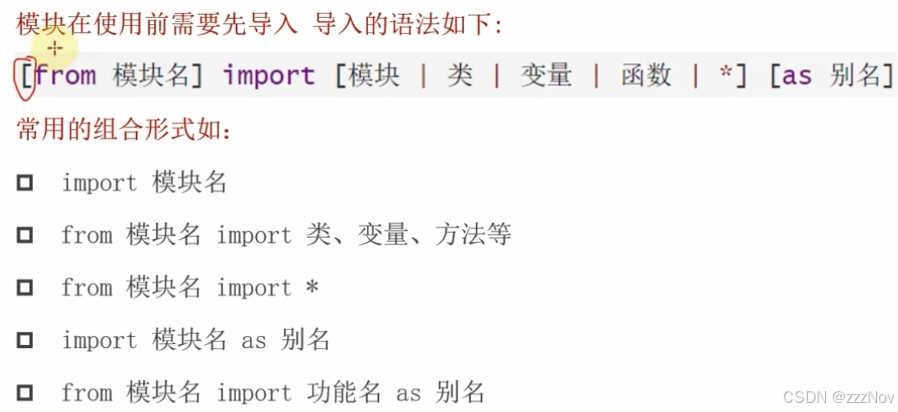
第八章--模块module
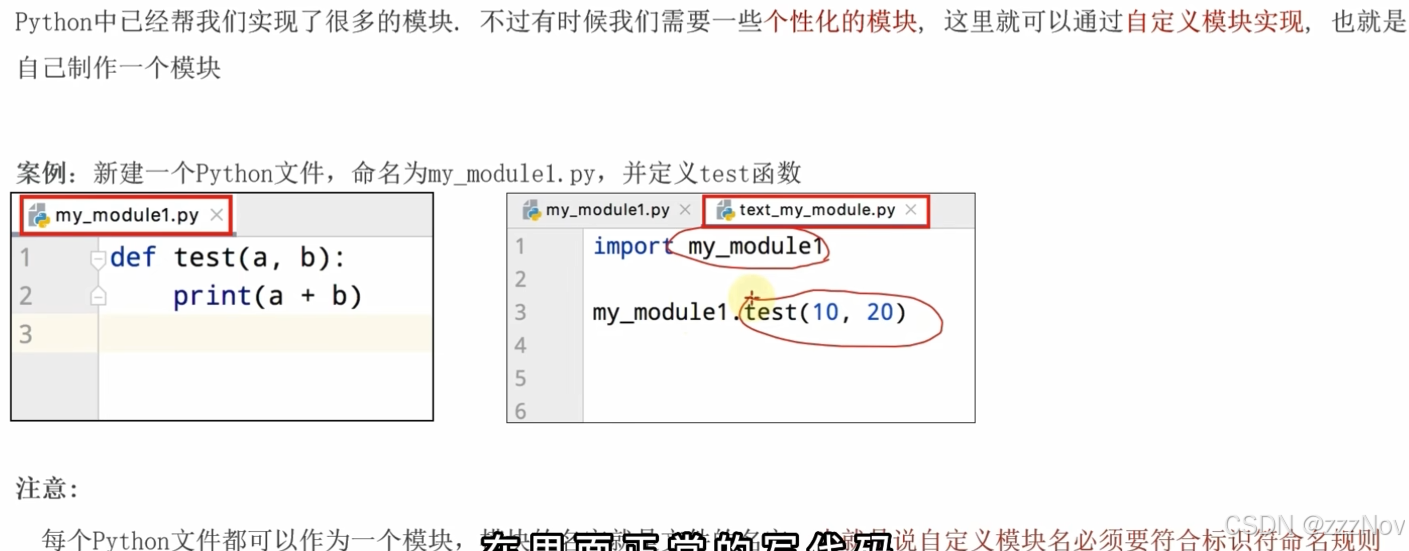
模块相当于包,内部有函数、变量、类

自定义模块


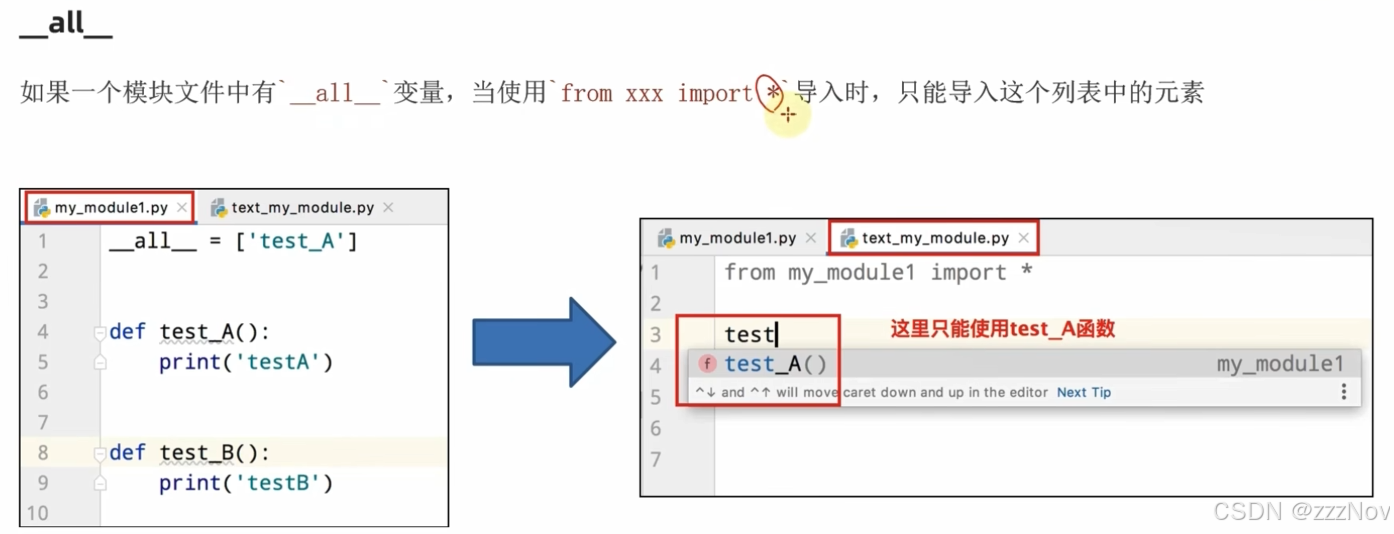
第九章--包package
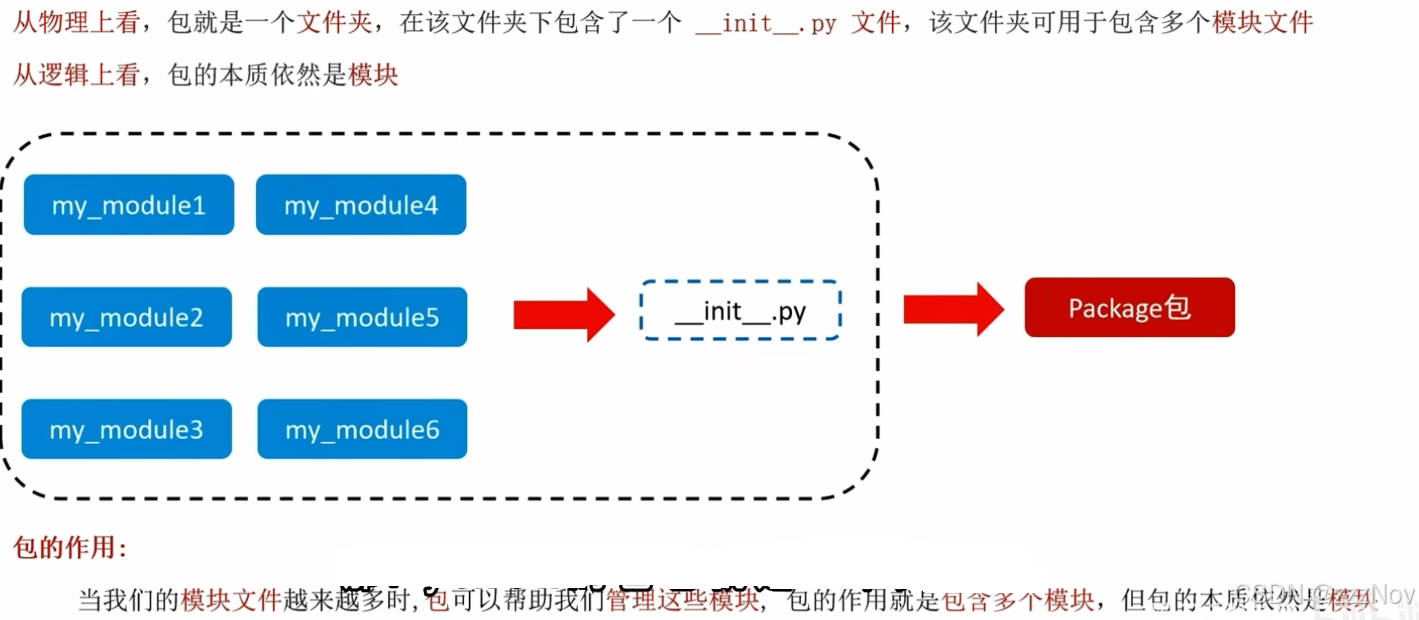
__init__.py标识了当前文件夹是否是包,如果有则是,没有则不是

ex:

str_util.py
# 字符串相关的工具模块
def str_reverse(s):
""""
接受传入字符串,将字符串反转返回
:param s:将被反转的字符串
:return:反转后的字符串
"""
return s[::-1]
def substr(s,x,y):
""""
接受下标x和y,对字符串进行切片
:param s:将被切片的字符串
:param x:切片的开始下标
:param y:切片的结束下标
:return:切片后的字符串
"""
return s[x:y]
if __name__ == '__main__':
print(str_reverse("黑马程序员"))
print(substr("黑马程序员", 1, 3))
file_util.py
# 文件处理相关的工具模块
from charset_normalizer.cd import encoding_unicode_range
def print_file_info(filename):
""""
打印文件内容
:param filename:要打印的文件路径
:return:文件内容
"""
f = None
try:
f = open(filename,'r',encoding="UTF-8")
print(f.read())
except Exception as e:
print(f"程序出现错误:{e}")
finally:
if f: # 如果变量是None,表示False,如果是文件,则关闭文件
f.close()
def append_to_file(filename,data):
""""
接收文件路径及传入内容,将数据追加写入到文件中
:param filename:文件路径
:param data:即将要传入的文件内容
:return:None
"""
f = open(filename,'a',encoding="UTF-8")
f.write(data)
f.write("\n")
f.close() #close带有flush的功能
if __name__ == '__main__':
append_to_file("D:\PycharmProjects\python_ex\ill.txt","aaaaaaa")
print_file_info("D:\PycharmProjects\python_ex\ill.txt")package_module.py
import package_module_ex.str_util
from package_module_ex import file_util
print(package_module_ex.str_util.str_reverse("黑马程序员"))
print(package_module_ex.str_util.substr("黑马程序员", 1, 3))
file_util.append_to_file("D:\PycharmProjects\python_ex\ill.txt","aaaaaaa")
file_util.print_file_info("D:\PycharmProjects\python_ex\ill.txt")输出结果
第十章 JSON


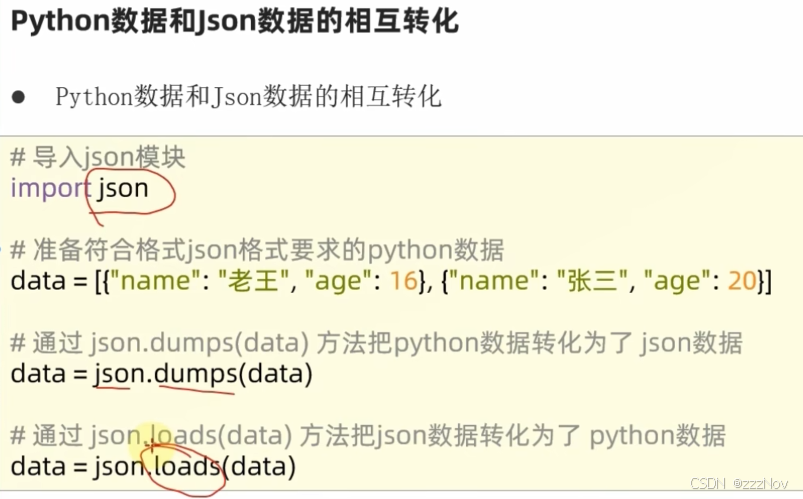
import json
# 准备列表,列表内每一个元素都是字典,将其转化为JSON
data = [{"name":"Lucky","age":21},{"name":"Lily","age":20},{"name":"Lucy","age":22}]
json_str = json.dumps(data)
print(type(json_str))# str
print(json_str)#[{'name': 'Lucky', 'age': 21}, {'name': 'Lily', 'age': 20}, {'name': 'Lucy', 'age': 22}]
# 准备字典,将字典转化为JSON
data2 = {"name":"Lucky","age":21}
json_str2 = json.dumps(data2)
print(type(json_str2))# str
print(json_str2)#{'name': 'Lucky', 'age': 21}
# 将JSON字符串转化为Python数据类型(列表)[{k:v,k:v},{k:v,k:v}]
l = json.loads(json_str)
print(type(l)) # list
print(l) #[{'name': 'Lucky', 'age': 21}, {'name': 'Lily', 'age': 20}, {'name': 'Lucy', 'age': 22}]
# 将JSON字符串转化为Python数据类型(字典){k:v,k:v}
d = json.loads(json_str2)
print(type(d)) #dict
print(d) #{'name': 'Lucky', 'age': 21}
#元组类型转化为list类型后再转为json
tup = (1, 2, 3)
json_str3 = json.dumps(list(tup))
print(json_str3) #[1, 2, 3]
print(type(json.loads(json_str3)))# list
#集合类型转化为元组类型后再转为json
s = {1, 2, 3}
json_str4 = json.dumps(tuple(s))
print(json_str4) #[1, 2, 3]
print(type(json.loads(json_str4)))# list在Python中,确实可以将列表和字典类型的数据转化为JSON格式,这是因为JSON格式本质上就是基于这两种数据结构的。然而,JSON标准并不直接支持Python中的所有数据类型。以下是一些常见的数据类型及其转换为JSON的注意事项:
- 字典(dict):可以转换为JSON对象。
- 列表(list):可以转换为JSON数组。
- 字符串(str):可以转换为JSON字符串。
- 整数(int)和浮点数(float):可以转换为JSON数字。
- 布尔值(bool):可以转换为JSON布尔值(true/false)。
- None:在JSON中没有直接对应的值,通常会被转换为
null。
对于其他数据类型,如元组(tuple)、集合(set)、自定义对象等,直接转换为JSON是不被支持的。如果你需要将这些类型的数据转换为JSON,通常需要先将它们转换为列表或字典,或者将它们的数据内容转换为上述支持的JSON数据类型。
第十一章 Pyecharts
1.折线图
from pyecharts.charts import Line
# 创建一个折线图对象
line = Line()
# 给折线图x轴添加数据
line.add_xaxis(["中国","美国","日本"])
# 给折线图y轴添加数据
line.add_yaxis("GDP",[30,20,10])
#查看 render(),生成图像
line.render()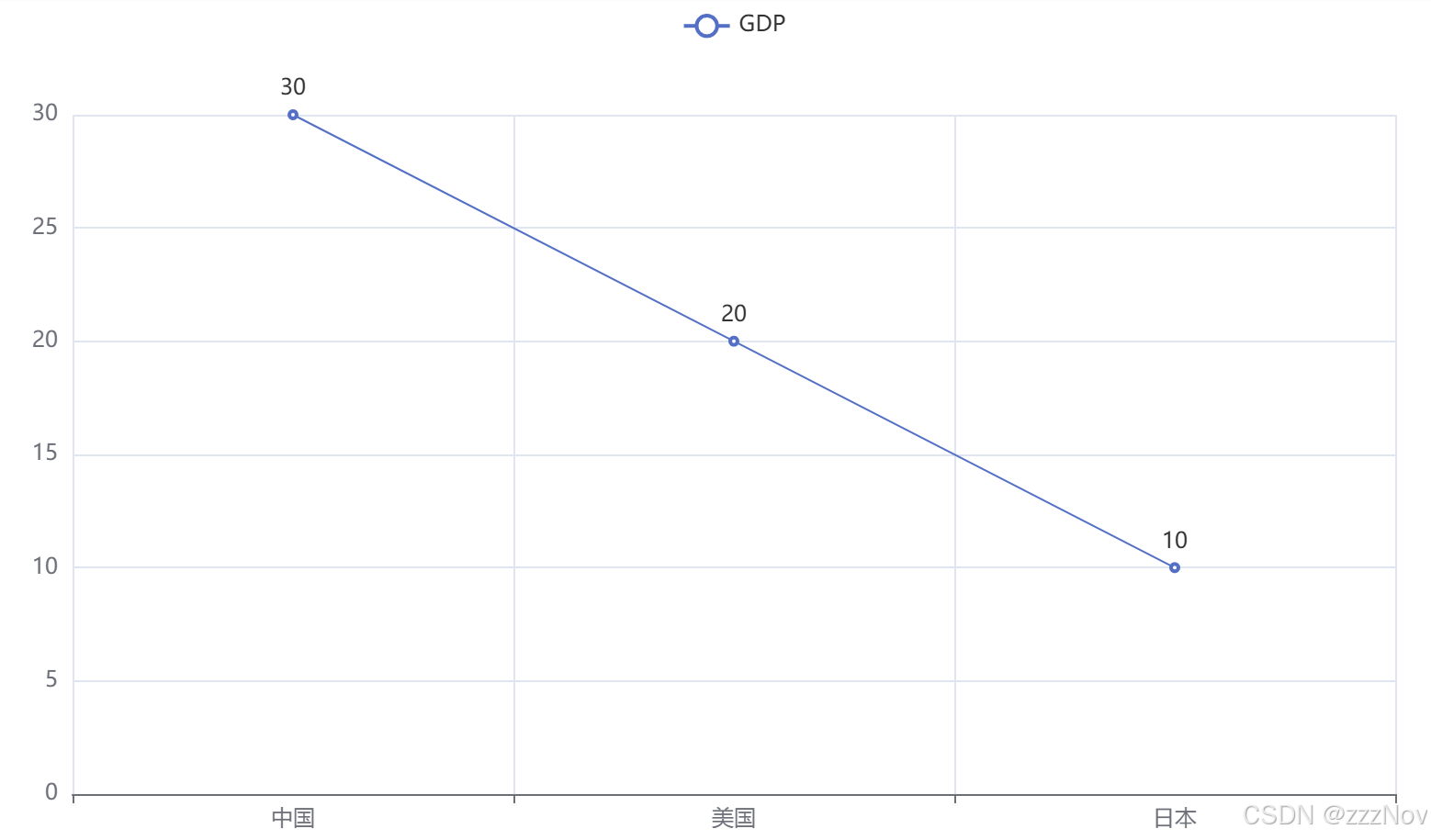
全局配置项set_global_opts
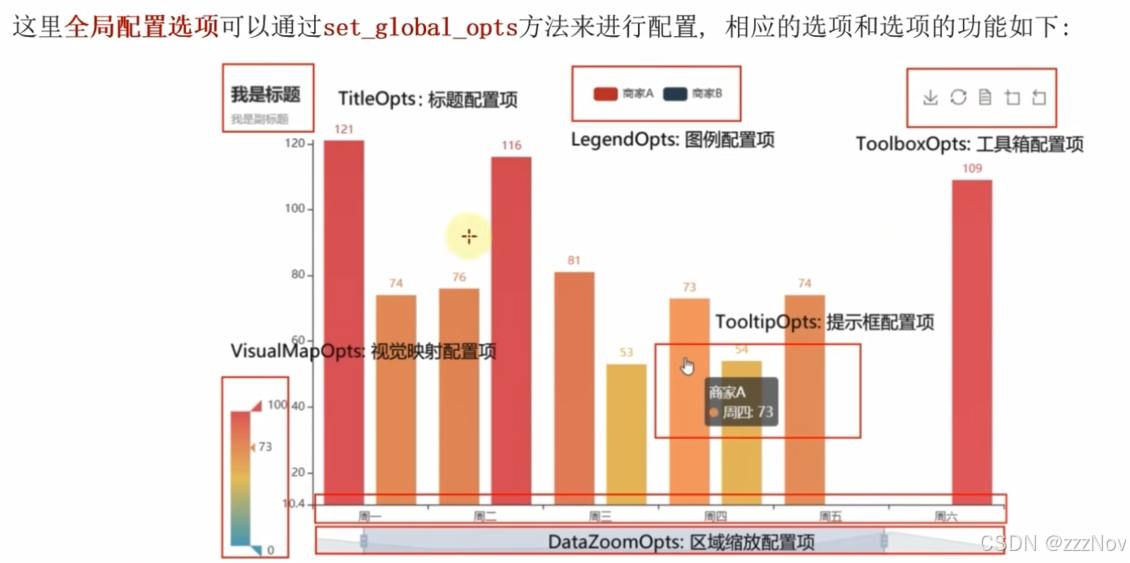
from idlelib.pyparse import trans
from pyecharts.charts import Line
from pyecharts.options import TitleOpts, LegendOpts, ToolboxOpts, VisualMapOpts
# 创建一个折线图对象
line = Line()
# 给折线图x轴添加数据
line.add_xaxis(["中国","美国","日本"])
# 给折线图y轴添加数据
line.add_yaxis("GDP",[30,20,10])
# 全局配置项
line.set_global_opts(
title_opts=TitleOpts(title="各国GDP展示",pos_left="center",pos_bottom="1%"),
legend_opts=LegendOpts(is_show=True),
toolbox_opts=ToolboxOpts(is_show=True),
visualmap_opts=VisualMapOpts(is_show=True)
)
#查看 render(),生成图像
line.render()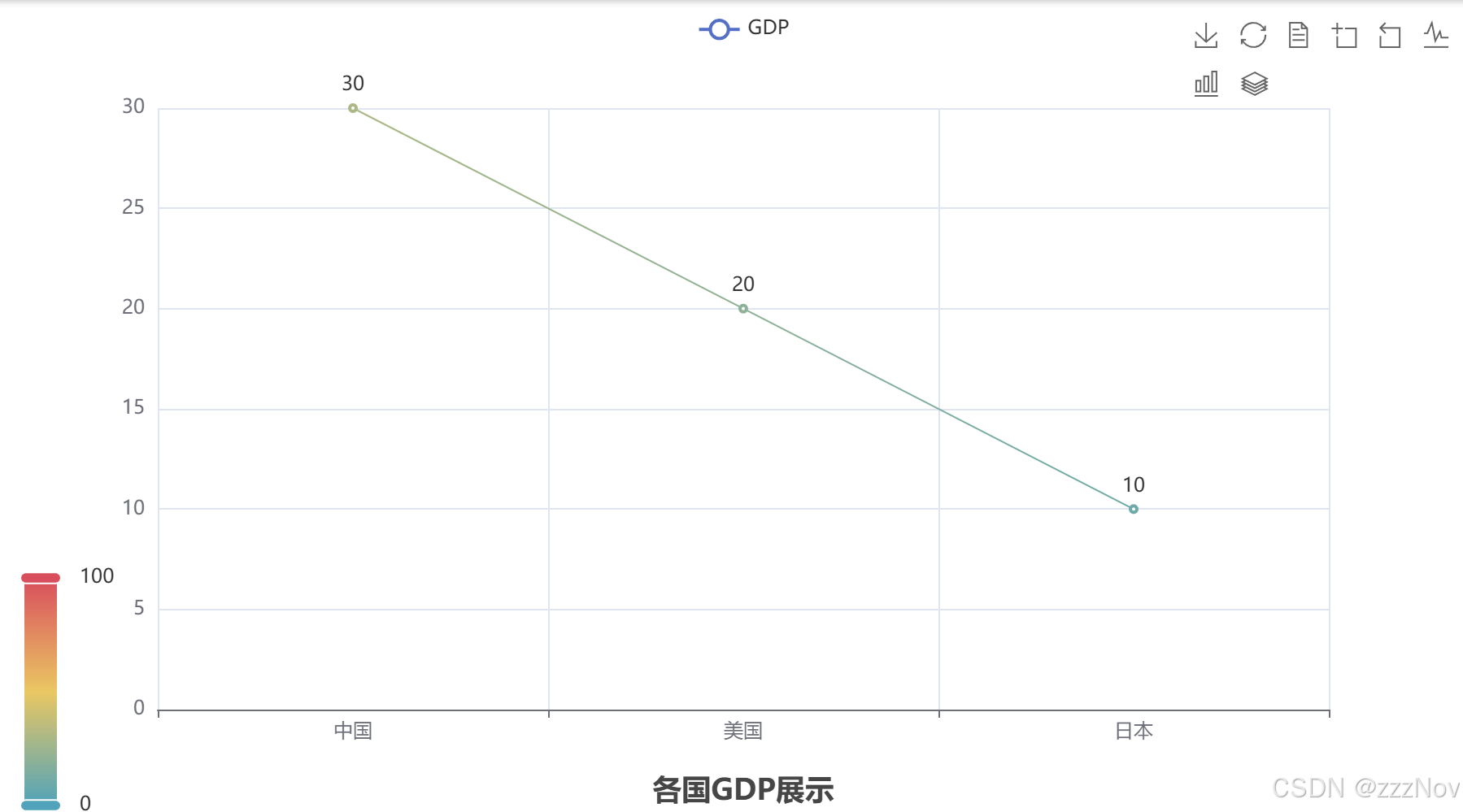
ex:美日印三国疫情期间确诊人数,文件数据的json格式如下


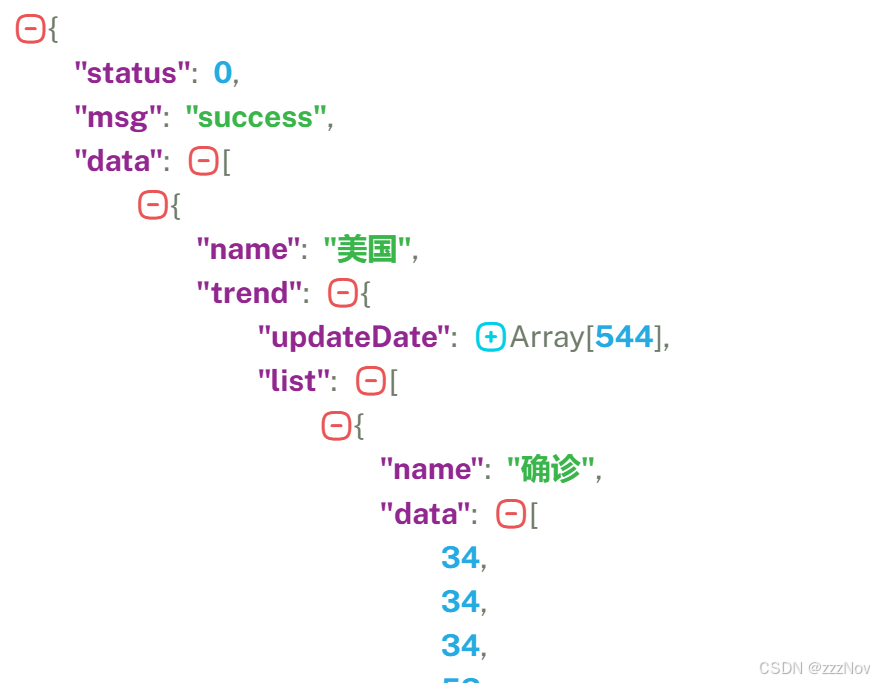
import json
from pyecharts.charts import Line
from pyecharts.options import TitleOpts, LabelOpts
# 处理数据,读取美国、日本、印度的全部数据
f1_file = open("D:\PycharmProjects\python_ex\可视化案例数据\折线图数据\美国.txt","r",encoding="UTF-8")
f2_file = open("D:\PycharmProjects\python_ex\可视化案例数据\折线图数据\日本.txt","r",encoding="UTF-8")
f3_file = open("D:\PycharmProjects\python_ex\可视化案例数据\折线图数据\印度.txt","r",encoding="UTF-8")
f1 = f1_file.read()
f2 = f2_file.read()
f3 = f3_file.read()
#去掉不符合json的开头部分
f1 = f1.replace("jsonp_1629344292311_69436(","")
f2 = f2.replace("jsonp_1629350871167_29498(","")
f3 = f3.replace("jsonp_1629350745930_63180(","")
#去掉不符合json结尾的部分
f1 = f1[:-2] # 相当于f1[0:-2:1]从头(0)到最后倒数第二个元素(不包含)正序取
f2 = f2[:-2]
f3 = f3[:-2]
# json转为python字典
f1_dit = json.loads(f1)
f2_dit = json.loads(f2)
f3_dit = json.loads(f3)
# print(type(f1_dit))
# print(f1_dit)
# 获取键为trend
f1_trend_data = f1_dit['data'][0]['trend']
f2_trend_data = f2_dit['data'][0]['trend']
f3_trend_data = f3_dit['data'][0]['trend']
# print(trend_data)
# 获取日期数据,用于x轴,取2020年(到12月31日,即下标为313结束)
f1_x_data = f1_trend_data['updateDate'][:314]
f2_x_data = f2_trend_data['updateDate'][:314]
f3_x_data = f3_trend_data['updateDate'][:314]
# print(x_data)
# 获取日期数据,用于y轴,取2020年(到314下标结束)
f1_y_data = f1_trend_data['list'][0]['data'][:314]
f2_y_data = f2_trend_data['list'][0]['data'][:314]
f3_y_data = f3_trend_data['list'][0]['data'][:314]
# print(y_data)
#生成图表
line = Line()
#添加x轴
line.add_xaxis(f1_x_data)
#添加y轴
line.add_yaxis("美国确诊人数",f1_y_data,label_opts=LabelOpts(is_show=False))
line.add_yaxis("日本确诊人数",f2_y_data,label_opts=LabelOpts(is_show=False))
line.add_yaxis("印度确诊人数",f3_y_data,label_opts=LabelOpts(is_show=False))
#设置全局选项
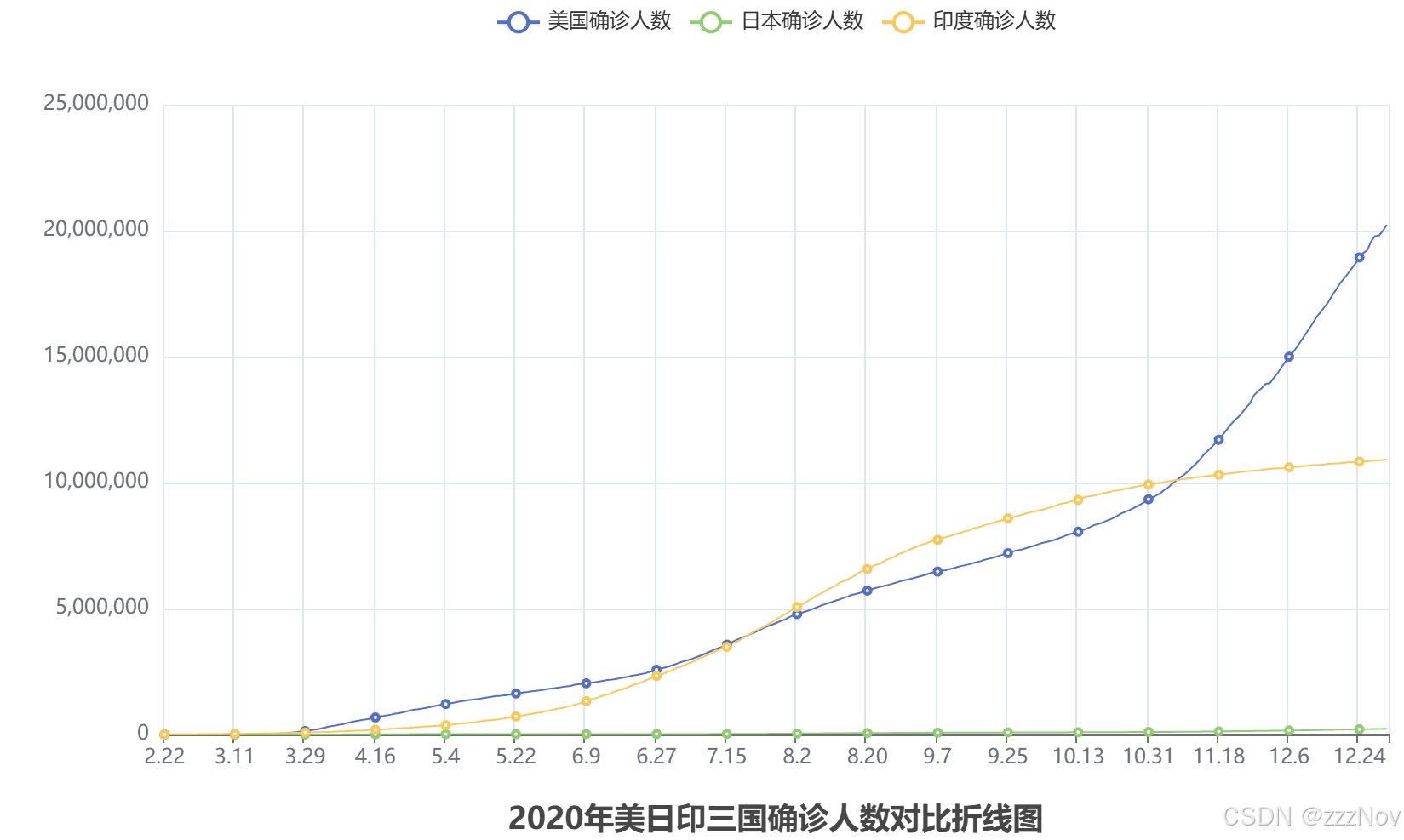
line.set_global_opts(
title_opts=TitleOpts(title="2020年美日印三国确诊人数对比折线图",pos_left="center",pos_bottom="1%")
)
#render生成
line.render()
# 关闭文件对象
f1_file.close()
f2_file.close()
f3_file.close()
2.地图
from pyecharts.charts import Map
from pyecharts.options import VisualMapOpts
map = Map()
data = [
("北京市",39),
("上海市",99),
("广东省",59),
("浙江省",79),
("江苏省",69)
]
map.add("测试地图",data,"china")
map.set_global_opts(
visualmap_opts=VisualMapOpts(
is_show=True,
is_piecewise=True, #手动校准范围,使得相应省份显示对应的颜色
pieces=[
{"min":1,"max":39,"label":"1-39","color":"#CCFFFF"},
{"min":40,"max":69,"label":"30-69","color":"#FF6666"},
{"min":70,"max":100,"label":"70-100","color":"#990033"}
]
)
)
map.render()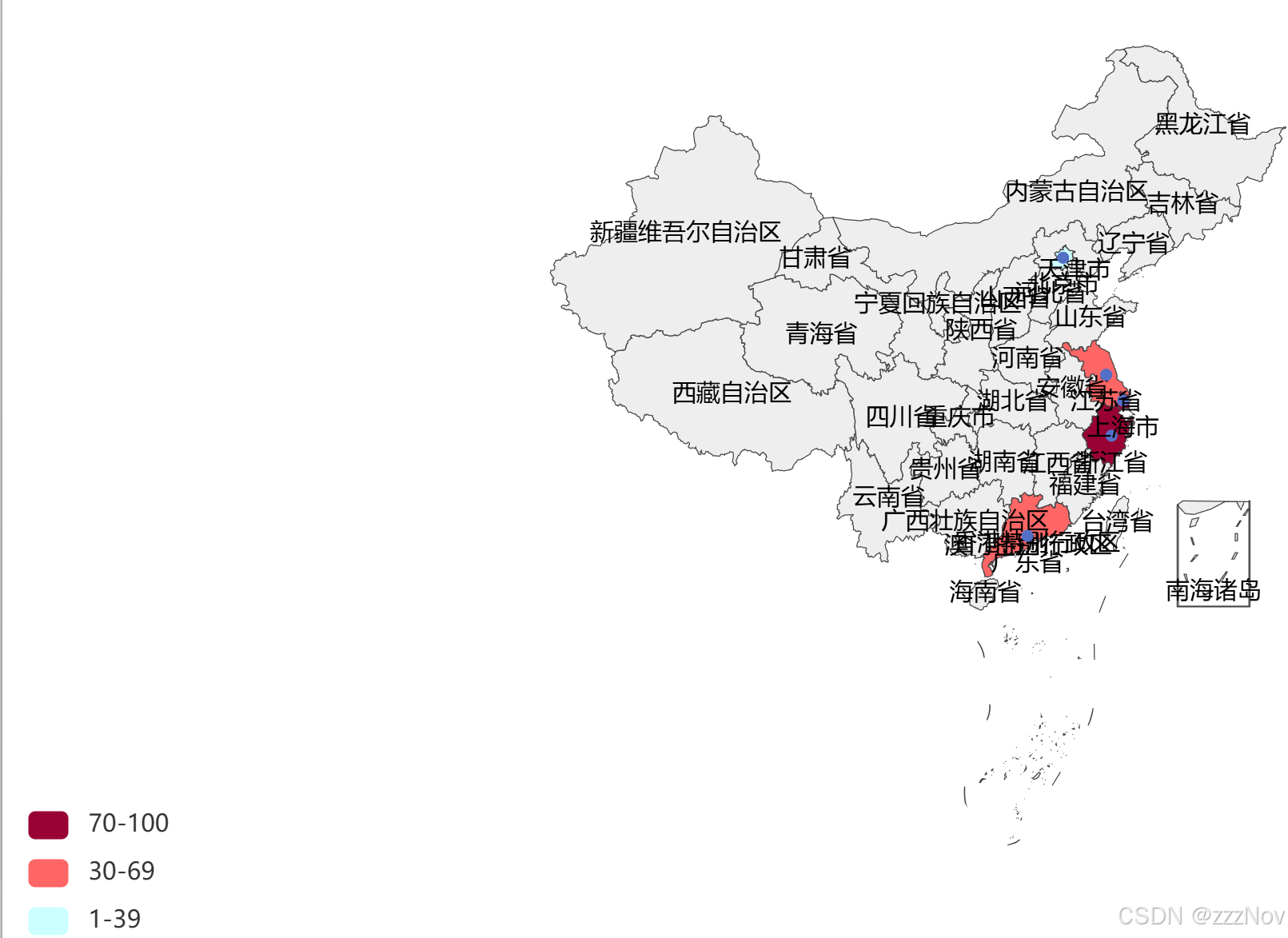
ex:全国疫情确诊地图
import json
from pyecharts.charts import Map
from pyecharts.options import TitleOpts, VisualMapOpts
f = open("D:\PycharmProjects\python_ex\可视化案例数据\地图数据\疫情.txt","r",encoding="UTF-8")
data = f.read()
f.close()
data_dict = json.loads(data)
# 从字典中取出省份数据
province_data_list = data_dict["areaTree"][0]["children"]
# 组装每个省份和确诊人数为元组,并各个省份的数据都封装到列表中
data_list = [] #列表
for province_data in province_data_list:
province_name = province_data["name"]
province_confirm = province_data["total"]["confirm"]
data_list.append((province_name,province_confirm))#把元组添加到列表中
map = Map()
map.add("各省份确诊人数",data_list,"china")
map.set_global_opts(
title_opts=TitleOpts(title="全国疫情地图"),
visualmap_opts=VisualMapOpts(
is_show=True,#是否显示
is_piecewise=True,#是否分段
pieces=[
{"min": 1, "max": 99, "label": "1-99人", "color": "#CCFFFF"},
{"min": 100, "max": 999, "label": "100-999人", "color": "#FFFF99"},
{"min": 1000, "max": 4999, "label": "1000-4999人", "color": "#FF99966"},
{"min": 5000, "max": 9999, "label": "5000-9999人", "color": "#FF6666"},
{"min": 10000, "max": 99999, "label": "10000-99999人", "color": "#CC3333"},
{"min": 100000, "label": "100000+人", "color": "#990033"}
]
)
)
map.render("全国疫情地图.html")#控制生成文件的文件名
ex:河南省各市级确诊人数
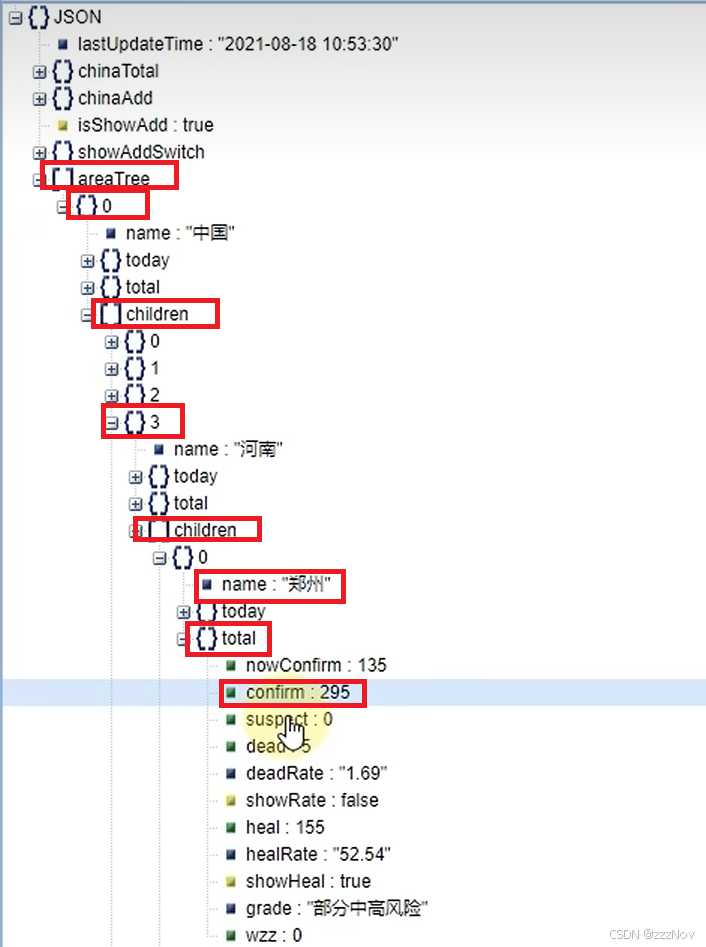
import json
from idlelib.iomenu import encoding
from pyecharts.charts import Map
from pyecharts.options import TitleOpts, VisualMapOpts
f = open("D:\PycharmProjects\python_ex\可视化案例数据\地图数据\疫情.txt","r",encoding="UTF-8")
data = f.read()
f.close()
# json转为python字典
data_dict = json.loads(data)
# 获取河南省的数据
cities_data = data_dict["areaTree"][0]["children"][3]["children"]
#获取河南省下的市级机器确诊人数,组装为元组,放入列表中
data_list = []
for city_data in cities_data:
city_name = city_data["name"] + "市"
city_confirm = city_data["total"]["confirm"]
data_list.append((city_name,city_confirm))
#手动添加济源市数据
data_list.append(("济源市",5))
map = Map()
map.add("河南各市级确诊人数",data_list,"河南")
map.set_global_opts(
title_opts=TitleOpts(title="河南疫情地图"),
visualmap_opts=VisualMapOpts(
is_show=True,#是否显示
is_piecewise=True,#是否分段
pieces=[
{"min": 1, "max": 99, "label": "1-99人", "color": "#CCFFFF"},
{"min": 100, "max": 999, "label": "100-999人", "color": "#FFFF99"},
{"min": 1000, "max": 4999, "label": "1000-4999人", "color": "#FF99966"},
{"min": 5000, "max": 9999, "label": "5000-9999人", "color": "#FF6666"},
{"min": 10000, "max": 99999, "label": "10000-99999人", "color": "#CC3333"},
{"min": 100000, "label": "100000+人", "color": "#990033"}
]
)
)
map.render("河南疫情地图.html")#控制生成文件的文件名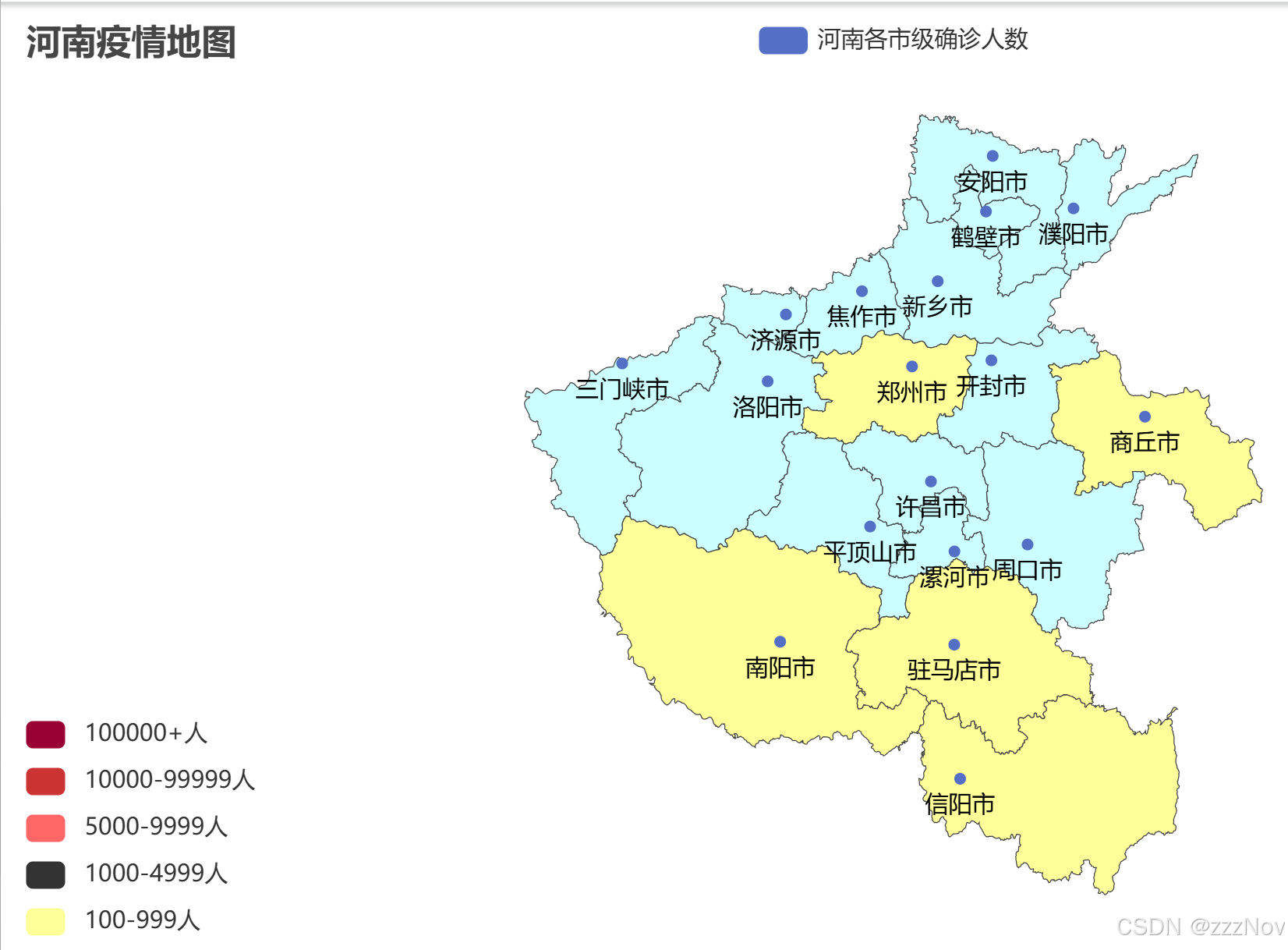
3.动态柱状图
ex:基础柱状图
from pyecharts.charts import Bar
from pyecharts.options import TitleOpts, LegendOpts, ToolboxOpts, VisualMapOpts, LabelOpts
# 创建一个折线图对象
bar = Bar()
# 给折线图x轴添加数据
bar.add_xaxis(["中国","美国","日本"])
# 给折线图y轴添加数据
bar.add_yaxis("GDP",[30,20,10],label_opts=LabelOpts(
position="right"
))
bar.reversal_axis()
# 全局配置项
# bar.set_global_opts(
# title_opts=TitleOpts(title="各国GDP展示",pos_left="center",pos_bottom="1%"),
# legend_opts=LegendOpts(is_show=True),
# toolbox_opts=ToolboxOpts(is_show=True),
# visualmap_opts=VisualMapOpts(is_show=True)
# )
#查看 render(),生成图像
bar.render("基础柱状图.html")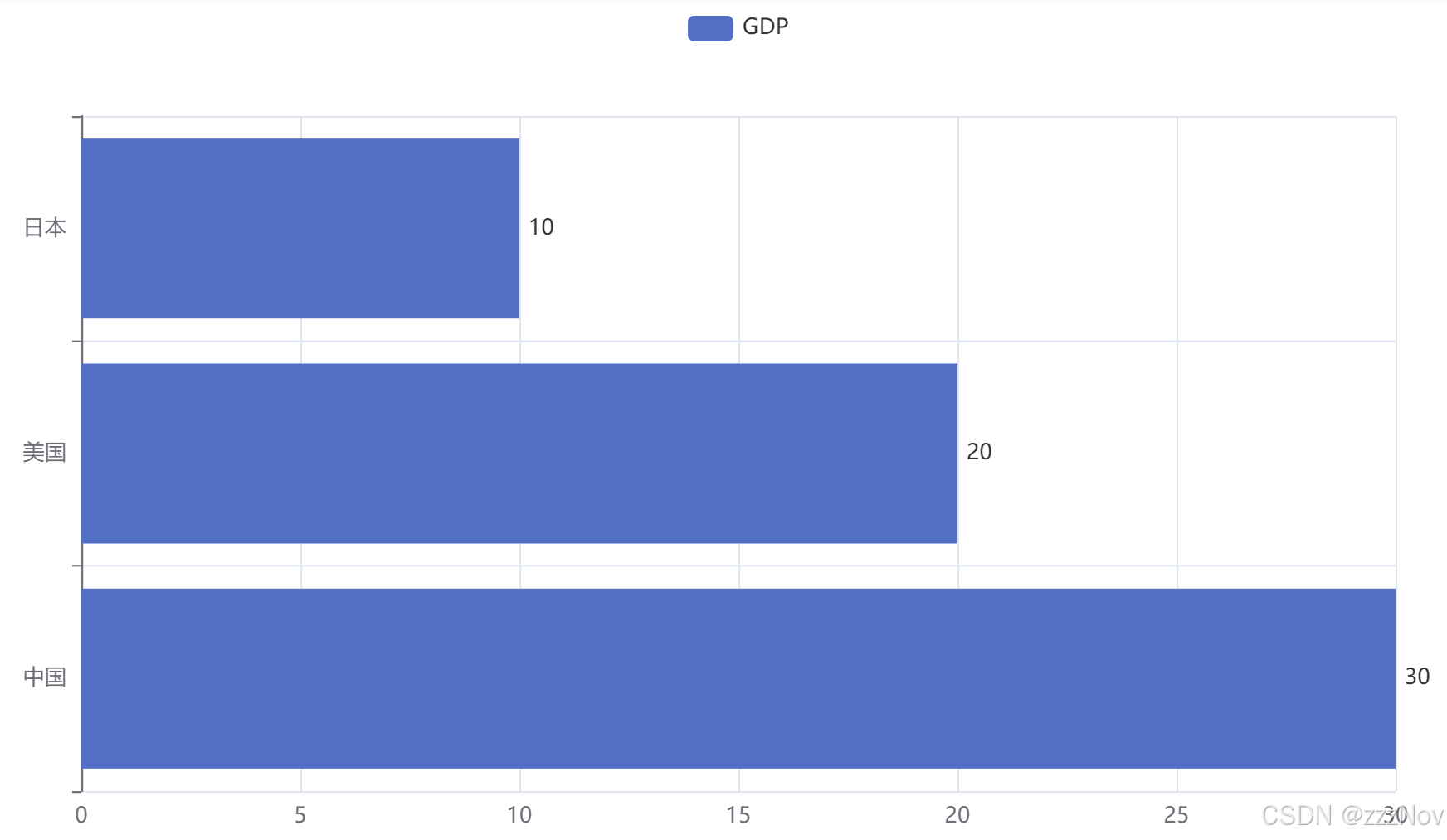
ex: 基础时间线柱状图
from pyecharts.charts import Bar,Timeline
from pyecharts.globals import ThemeType
from pyecharts.options import TitleOpts, LegendOpts, ToolboxOpts, VisualMapOpts, LabelOpts
# 创建一个折线图对象
bar1 = Bar()
# 给折线图x轴添加数据
bar1.add_xaxis(["中国","美国","日本"])
# 给折线图y轴添加数据
bar1.add_yaxis("GDP",[30,20,10],label_opts=LabelOpts(position="right"))
bar1.reversal_axis()
bar2 = Bar()
bar2.add_xaxis(["中国","美国","日本"])
bar2.add_yaxis("GDP",[40,30,20],label_opts=LabelOpts(position="right"))
bar2.reversal_axis()
bar3 = Bar()
bar3.add_xaxis(["中国","美国","日本"])
bar3.add_yaxis("GDP",[50,40,30],label_opts=LabelOpts(position="right"))
bar3.reversal_axis()
# 构建时间线对象
timeline = Timeline({"theme": ThemeType.LIGHT})
# 在时间线内添加柱状图
timeline.add(bar1,"点1")
timeline.add(bar2,"点2")
timeline.add(bar3,"点3")
# 自动播放设置
timeline.add_schema(
play_interval=1000,
is_timeline_show=True,
is_auto_play=True,
is_loop_play=True
)
# 绘图使用时间线timeline对象,而不是bar对象的render
timeline.render("基础时间线柱状图.html")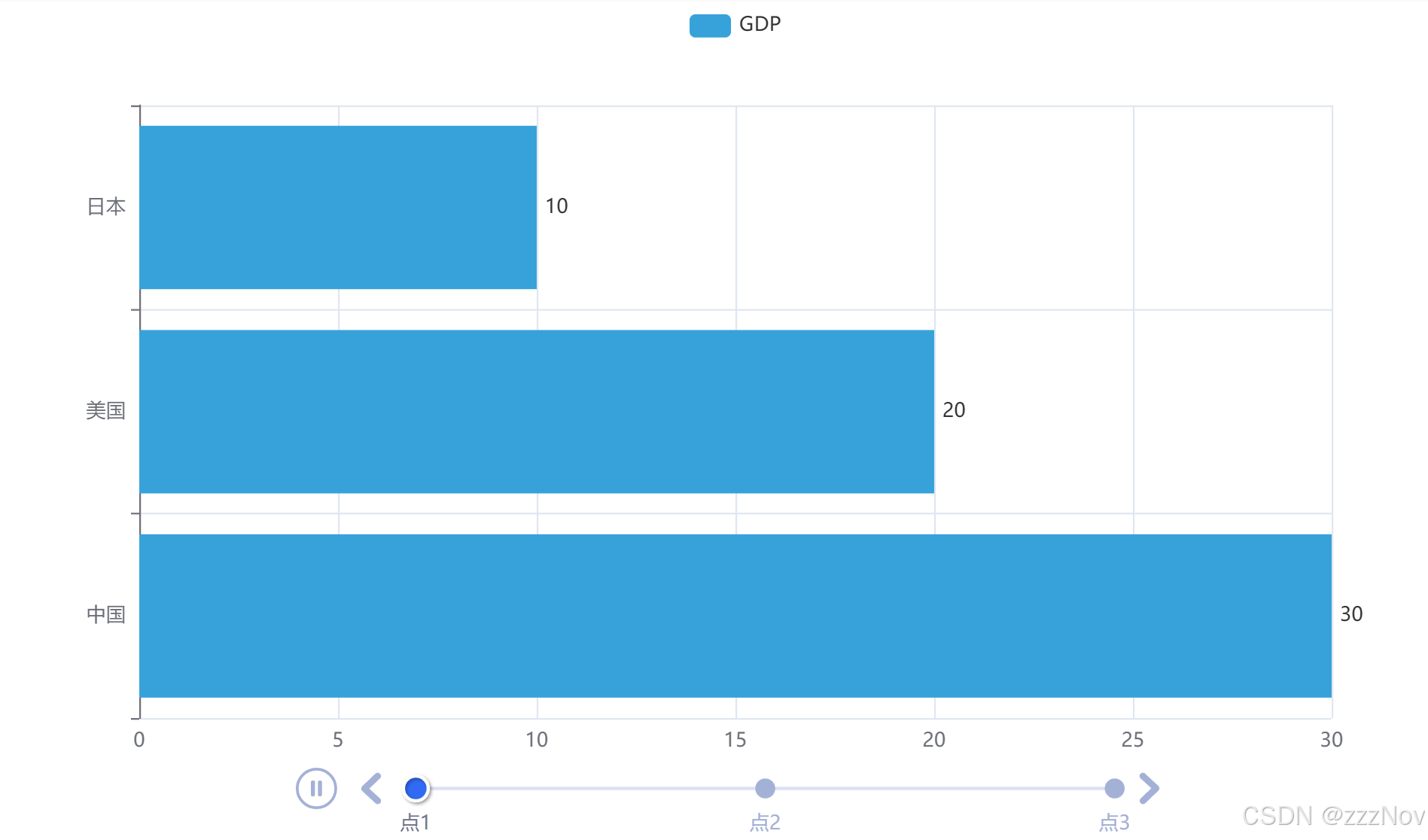
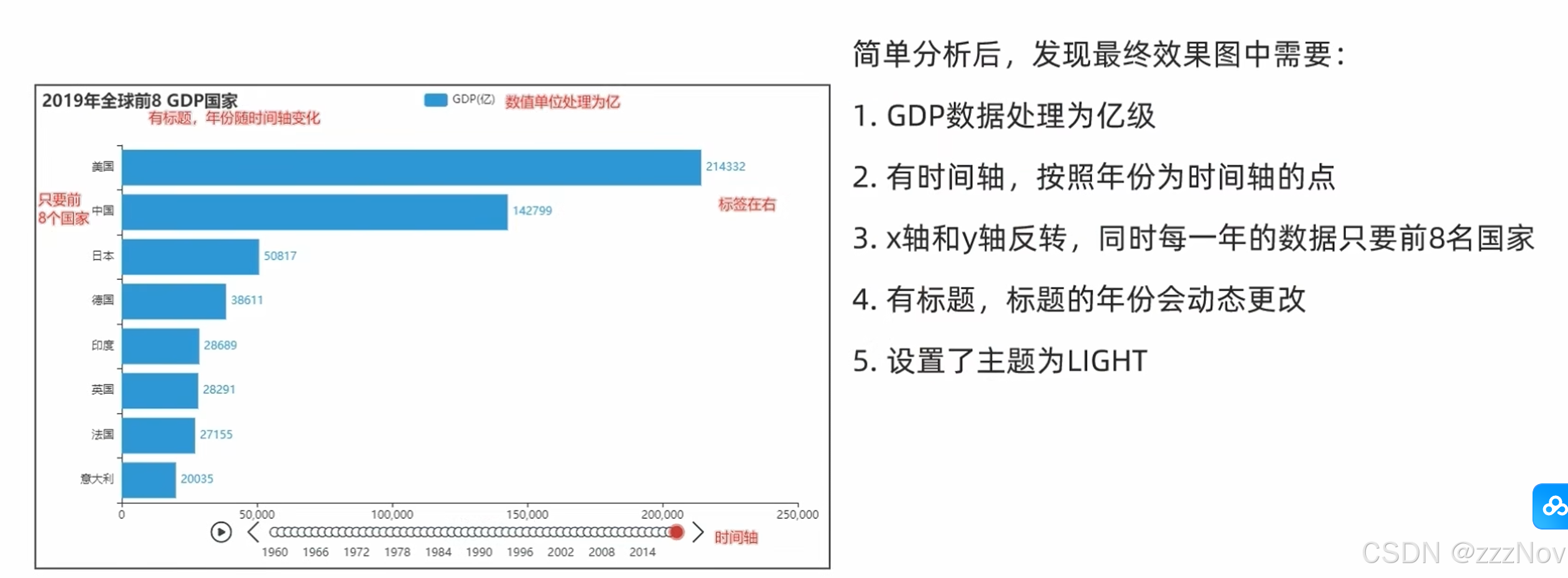
ex:动态GDP柱状图绘制
1.掌握列表的sort方法并配合lambda匿名函数完成列表排序
2.完成图表所需的数据处理
3.完成GDP动态图表绘制
from pyecharts.charts import Bar, Timeline
from pyecharts.globals import ThemeType
from pyecharts.options import LabelOpts, TitleOpts
from bar_ex_2 import timeline
f = open("D:\PycharmProjects\python_ex\可视化案例数据\动态柱状图数据\全球GDP数据.csv","r",encoding="GB2312")
data_lines = f.readlines()
f.close()
# 删除第一行 year,GDP,rate
data_lines.pop(0)
# 将数据转换为字典存储 ,格式为:
# {年份: [[国家,GDP],[国家,GDP],[国家,GDP],...]],年份: [[国家,GDP],[国家,GDP],[国家,GDP],...]],...年份: [[国家,GDP],[国家,GDP],[国家,GDP],...]]}
# {1960: [[美国,123],[中国,234],[英国,211],...]],1961: [[美国,123],[中国,234],[英国,211],...]],...年份: [[美国,123],[中国,234],[英国,211],...]]}
# 定义一个字典对象
data_dict = {}
for line in data_lines:
year = int(line.split(",")[0]) # 年份
country = line.split(",")[1] # 国家
gdp = float(line.split(",")[2]) # gdp
#判断字典中是否存在key(年份)
try:
data_dict[year].append([country,gdp])
except KeyError:
data_dict[year] = []
data_dict[year].append([country,gdp])
# 排序年份
sorted_year_list = sorted(data_dict.keys())
# 时间线
timeline = Timeline({"theme": ThemeType.LIGHT})
for year in sorted_year_list:
# 只需要每年gdp排名前8的国家
data_dict[year].sort(key=lambda element : element[1],reverse=True)
year_data = data_dict[year][0:8]
x_data = []
y_data = []
for country_gdp in year_data:
x_data.append(country_gdp[0]) #x轴添加国家
y_data.append(country_gdp[1] / 100000000) #y轴添加gdp
# 创建柱状图
bar = Bar()
# x轴数据反转
x_data.reverse()
# y轴数据反转
y_data.reverse()
bar.add_xaxis(x_data)
bar.add_yaxis("GDP(亿)",y_data,label_opts=LabelOpts(position="right"))
# 反转x轴和y轴
bar.reversal_axis()
#设置每一年的标题
bar.set_global_opts(
title_opts=TitleOpts(title=f"{year}年前8国家的GDP")
)
timeline.add(bar,str(year))
# 自动播放设置
timeline.add_schema(
play_interval=1000,
is_timeline_show=True,
is_auto_play=True,
is_loop_play=True
)
# 绘图使用时间线timeline对象,而不是bar对象的render
timeline.render("1960-2019前8国家GDP柱状图.html")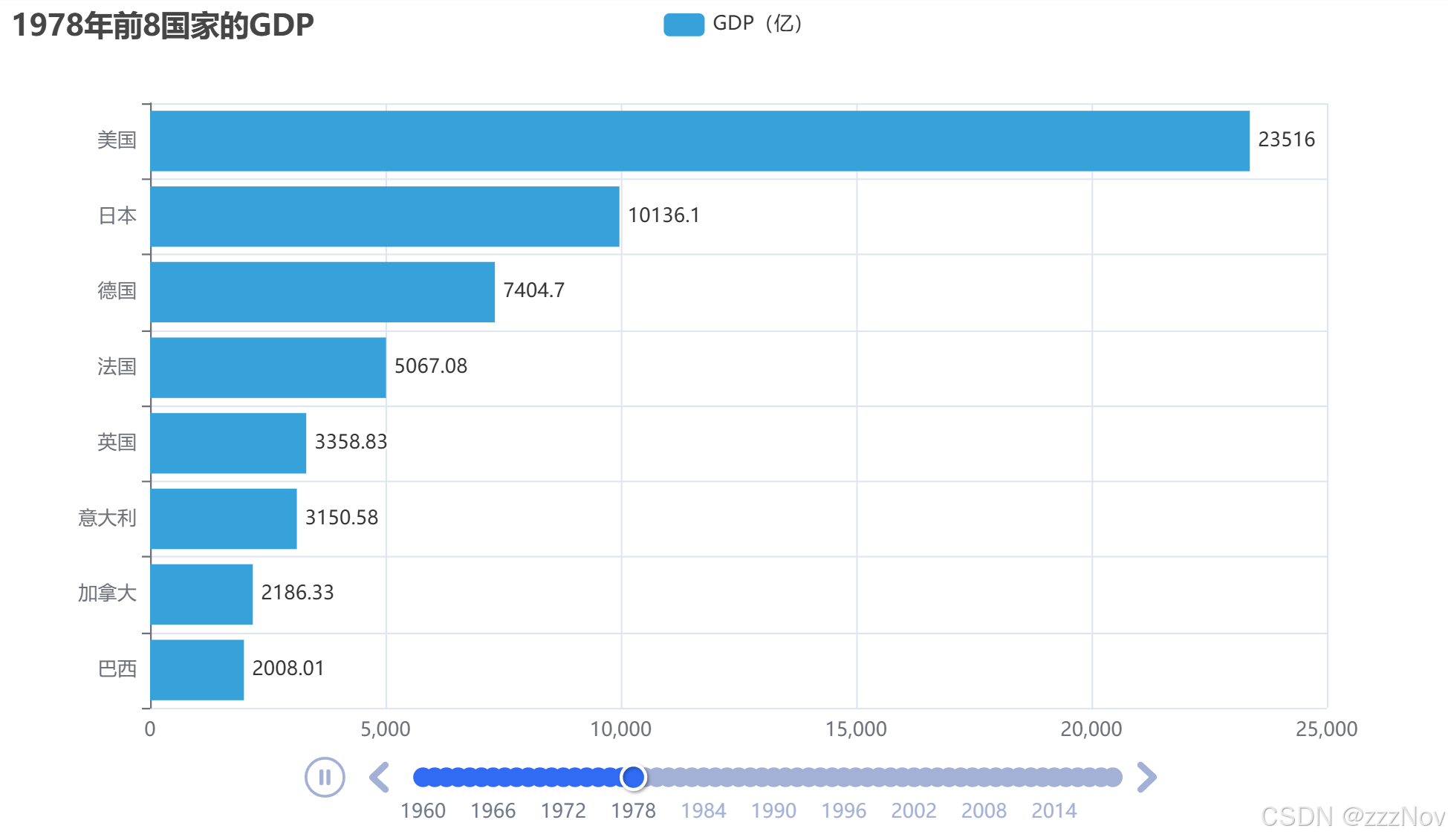
第二阶段
第一章 类
1.成员方法


2.构造方法


ex:
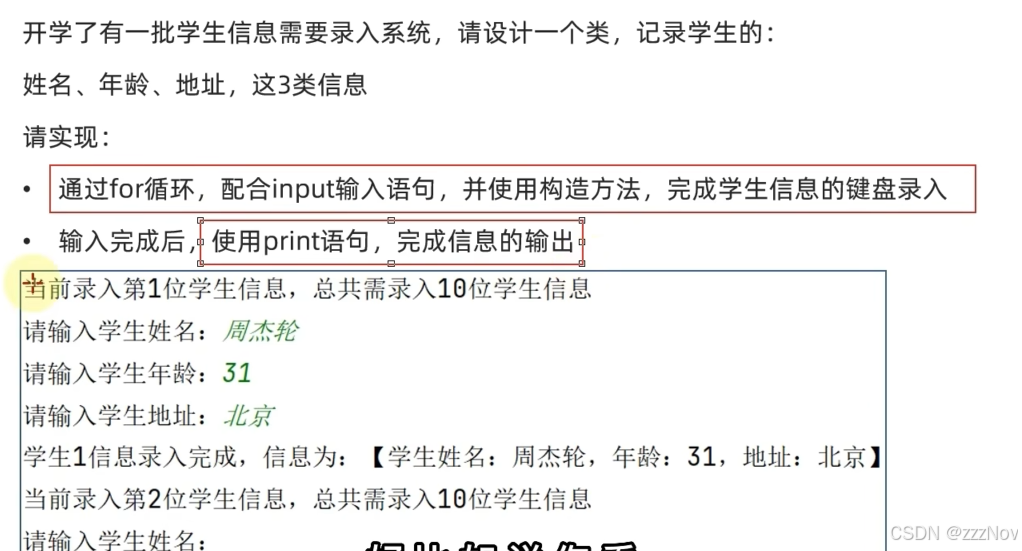
class Student():
name = None
age = None
address = None
def __init__(self,name,age,address):
self.name = name
self.age = age
self.address = address
for i in range(10):
print(f"当前录入第{i}位学生信息,总共需录入10位学生信息")
name = input("请输入学生姓名:")
age = input("请输入学生年龄:")
address = input("请输入学生地址:")
student = Student(name,age,address)
print(f"学生{i}信息录入完成,信息为:【学生姓名:{name},年龄:{age},地址:{address}")

3.魔术方法





4.私有成员变量(方法)

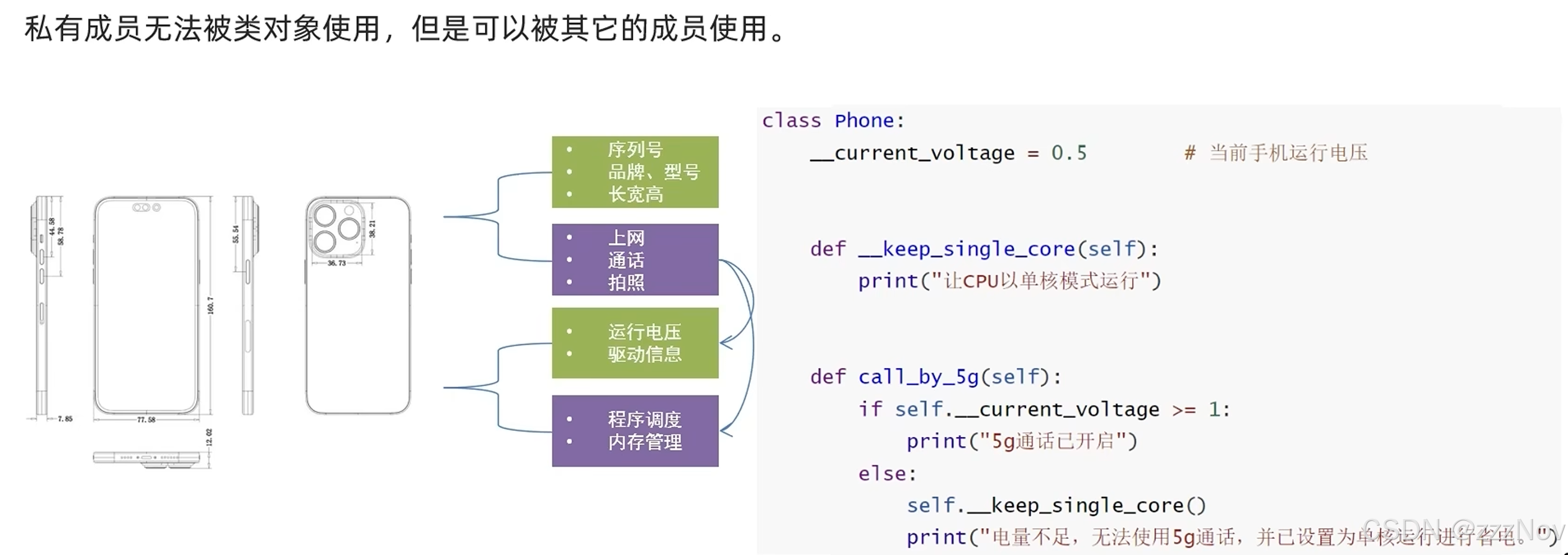
ex:

class Phone:
__is_5g_enable = None
def __check_5g(self):
if self.__is_5g_enable == True:
print("5g开启")
else:
print("5g关闭,使用4g网络")
def call_by_5g(self):
self.__check_5g()
print("正在通话中")
phone = Phone()
phone.call_by_5g()5.继承

6.复写


7.变量的类型注解



8.函数和方法类型注解
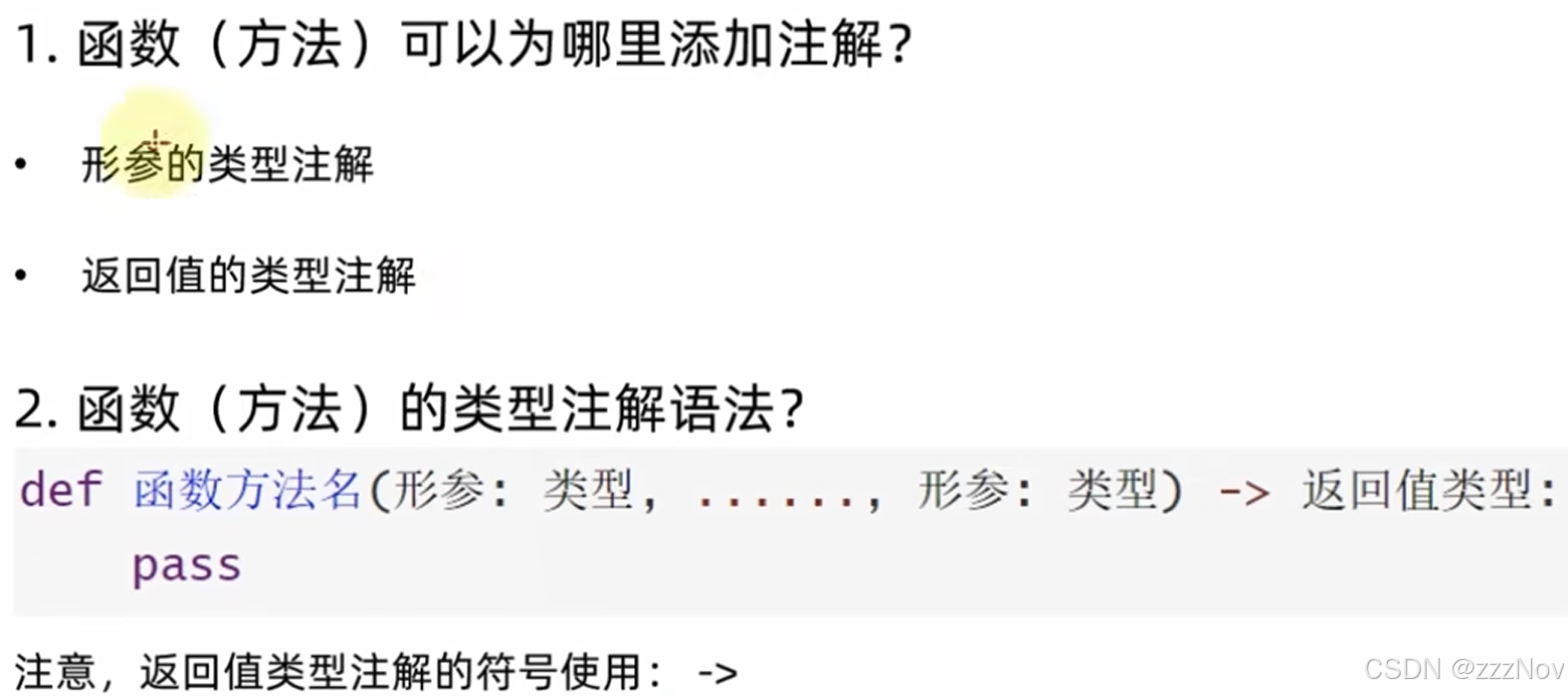
9.Union联合类型注解


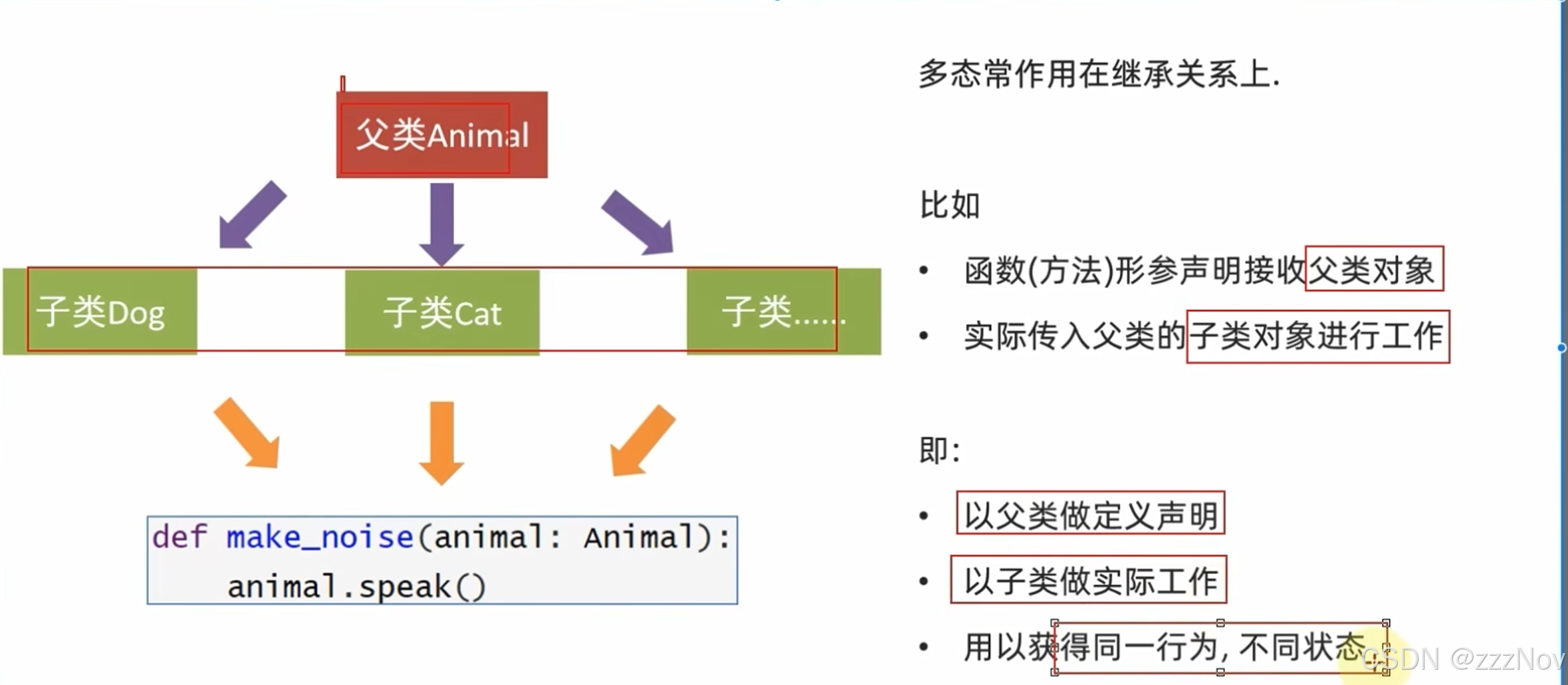
10.多态
11.抽象类(接口)

ex:
"""
数据定义类
"""
class Record:
def __init__(self,date,order_id,money,province):
self.date = date #订单日期
self.order_id = order_id #订单ID
self.money = money #订单金额
self.province = province #订单省份
def __str__(self):
return f"{self.date},{self.order_id},{self.money},{self.province}""""
文件相关的类定义
"""
import json
from 数据分析案例.data_define import Record
# 定义一个顶层抽象类,决定要做哪些事情
class FileReader:
def read_data(self) -> list[Record]:
"""读取文件的数据,读取到的每一条数据都转换为Record对象,将它们都封装到list内返回即可"""
pass
class TextFileReader(FileReader):
def __init__(self,path):
self.path = path #定义成员变量记录文件的路径
# 复写(实现抽象方法)父类的方法
def read_data(self) -> list[Record]:
f = open(self.path,"r",encoding="UTF-8")
record_list: list[Record] = []
for line in f.readlines():
line = line.strip() #消除读取到的每一行数据中的\n
data_list = line.split(",")
record = Record(data_list[0],data_list[1],int(data_list[2],),data_list[3])
record_list.append(record)
f.close()
return record_list
class JSONFileReader(FileReader):
def __init__(self,path):
self.path = path #定义成员变量记录文件的路径
# 复写(实现抽象方法)父类的方法
def read_data(self) -> list[Record]:
f = open(self.path, "r", encoding="UTF-8")
record_list: list[Record] = []
for line in f.readlines():
data_dict = json.loads(line)
record = Record(data_dict["date"],data_dict["order_id"],int(data_dict["money"]),data_dict["province"])
record_list.append(record)
f.close()
return record_list
if __name__ == '__main__':
text_file_reader = TextFileReader("D:\PycharmProjects\python_ex/2011年1月销售数据.txt")
line1 = text_file_reader.read_data()
json_file_reader = JSONFileReader("D:\PycharmProjects\python_ex/2011年2月销售数据JSON.txt")
line2 = json_file_reader.read_data()
for l in line1:
print(l)
for l in line2:
print(l)
"""
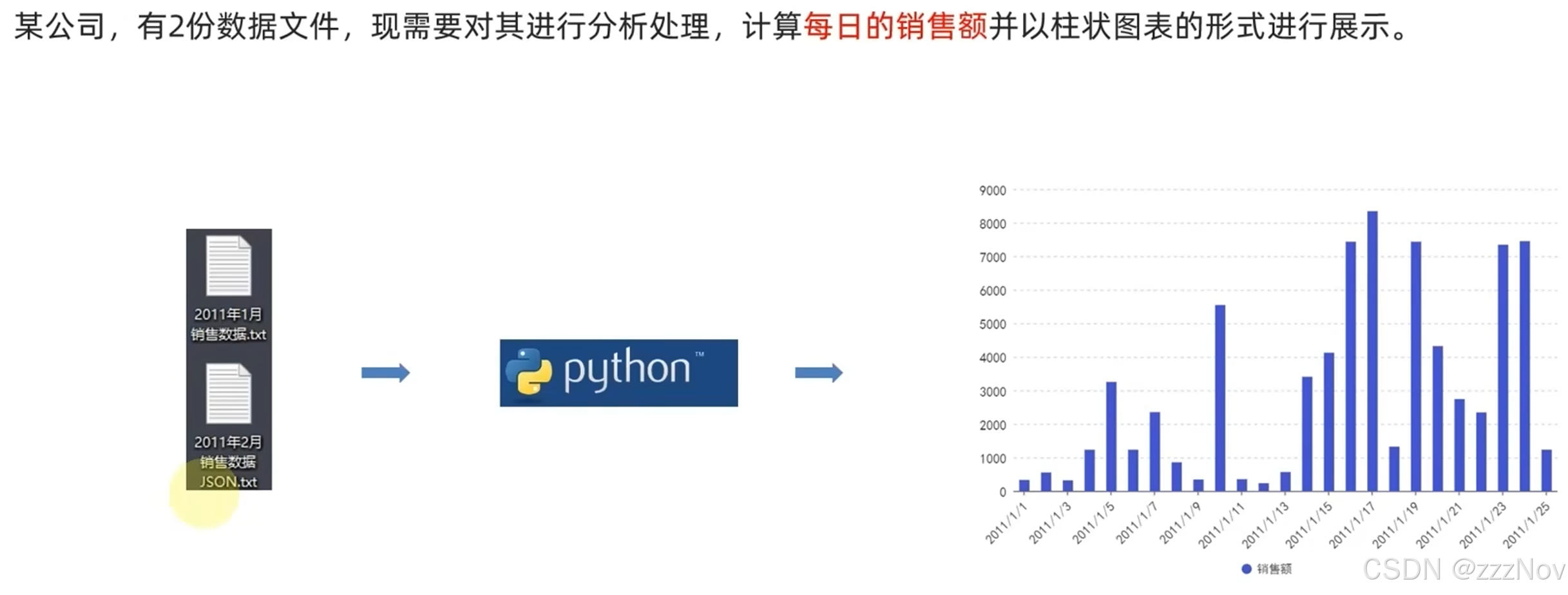
面向对象,数据分析案例
实现步骤:
1.设计一个类,可以完成数据的封装
2.设计一个抽象类,定义文件读取的相关功能,并使用子类实现具体功能
3.读取文件,生产数据对象
4.进行数据需求的逻辑运算
5.通过pyecharts进行图形绘制
"""
from pyecharts.charts import Bar
from pyecharts.options import *
from pyecharts.globals import ThemeType
from file_define import FileReader,TextFileReader,JSONFileReader
from data_define import Record
text_file_reader = TextFileReader("D:\PycharmProjects\python_ex/2011年1月销售数据.txt")
jan_data: list[Record] = text_file_reader.read_data()
json_file_reader = JSONFileReader("D:\PycharmProjects\python_ex/2011年2月销售数据JSON.txt")
feb_data: list[Record] = json_file_reader.read_data()
#将两个月份的数据合并为一个list来存储
all_data: list[Record] = jan_data + feb_data
#开始数据计算
#{"2011-01-01":1111,"2011-01-02":1111}
data_dict = {}
for record in all_data:
if record.date in data_dict.keys():
# 当前日期有记录,需累加
data_dict[record.date] += record.money
else:
data_dict[record.date] = record.money
#创建图表
bar = Bar(init_opts=InitOpts(theme=ThemeType.LIGHT))
bar.add_xaxis(list(data_dict.keys()))
bar.add_yaxis("销售额",list(data_dict.values()),label_opts=LabelOpts(is_show=False))
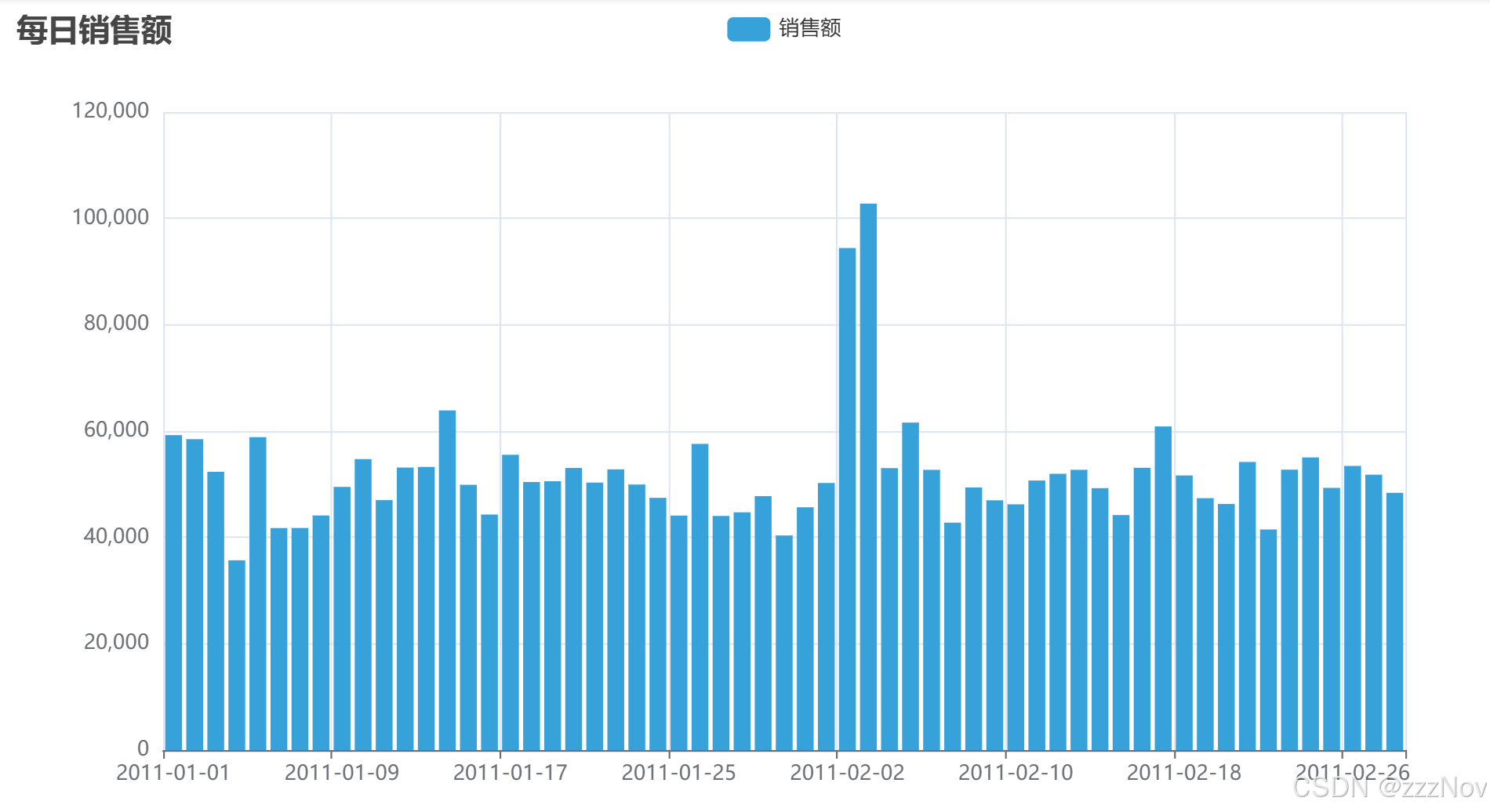
bar.set_global_opts(title_opts=TitleOpts(title="每日销售额"))
bar.render("每日销售额柱状图.html")
第二章 SQL


分组聚合


pycharm操作数据库


ex:

1.在navicat创建数据库、表
create DATABASE py_sql CHARSET utf8;
use py_sql;
create TABLE orders(
order_date date,
order_id varchar(255),
money int,
province VARCHAR(10)
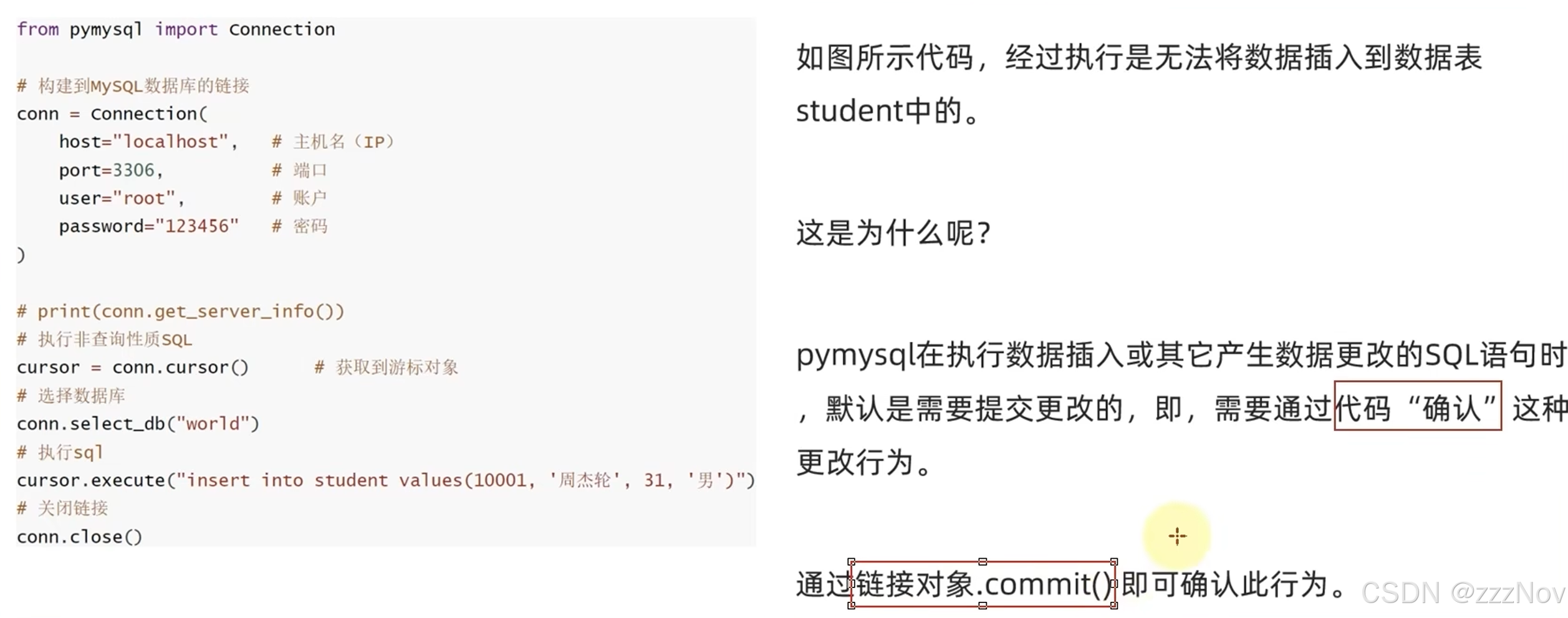
);2.编写代码连接数据库
from pyecharts.charts import Bar
from pyecharts.options import *
from pyecharts.globals import ThemeType
from pymysql import Connection
from file_define import FileReader,TextFileReader,JSONFileReader
from data_define import Record
text_file_reader = TextFileReader("D:\PycharmProjects\python_ex/2011年1月销售数据.txt")
jan_data: list[Record] = text_file_reader.read_data()
json_file_reader = JSONFileReader("D:\PycharmProjects\python_ex/2011年2月销售数据JSON.txt")
feb_data: list[Record] = json_file_reader.read_data()
#将两个月份的数据合并为一个list来存储
all_data: list[Record] = jan_data + feb_data
# 构建MySQL连接对象
conn = Connection(
host="localhost",
port=3306,
user="root",
password="123456",
autocommit=True
)
# 获取游标对象
cursor = conn.cursor()
# 选择数据库
conn.select_db("py_sql")
# 组织SQL语句
for record in all_data:
sql = f"insert into orders(order_date,order_id,money,province) values('{record.date}','{record.order_id}','{record.money}','{record.province}')"
# 执行SQL语句
cursor.execute(sql)
#关闭MySQL连接对象
conn.close()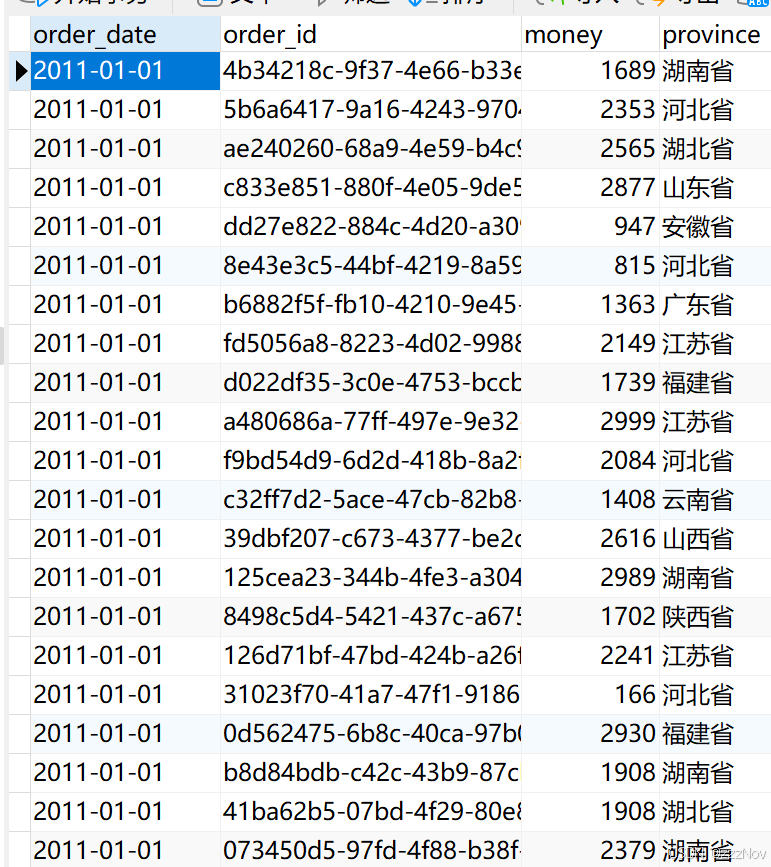
ex:
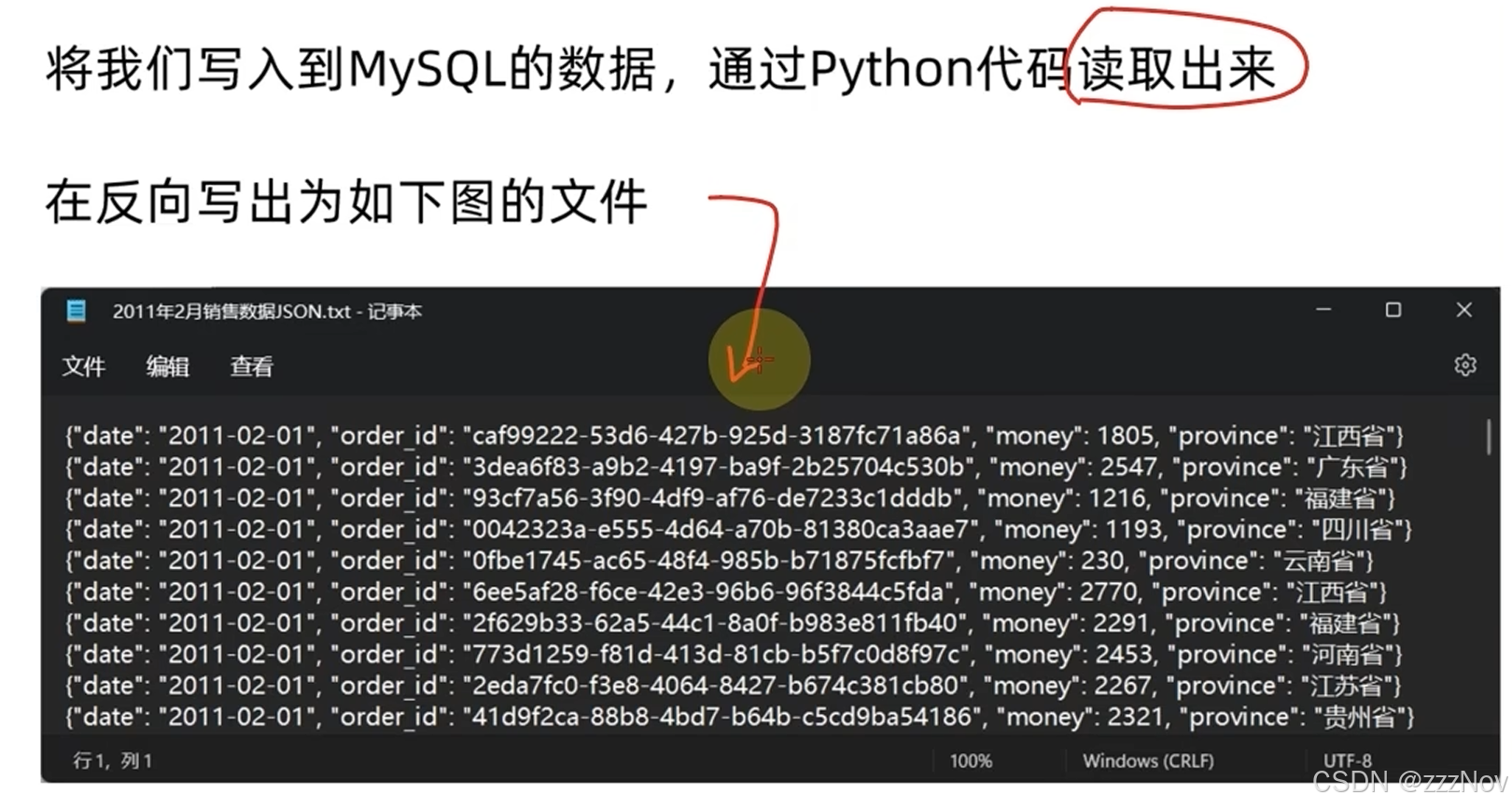
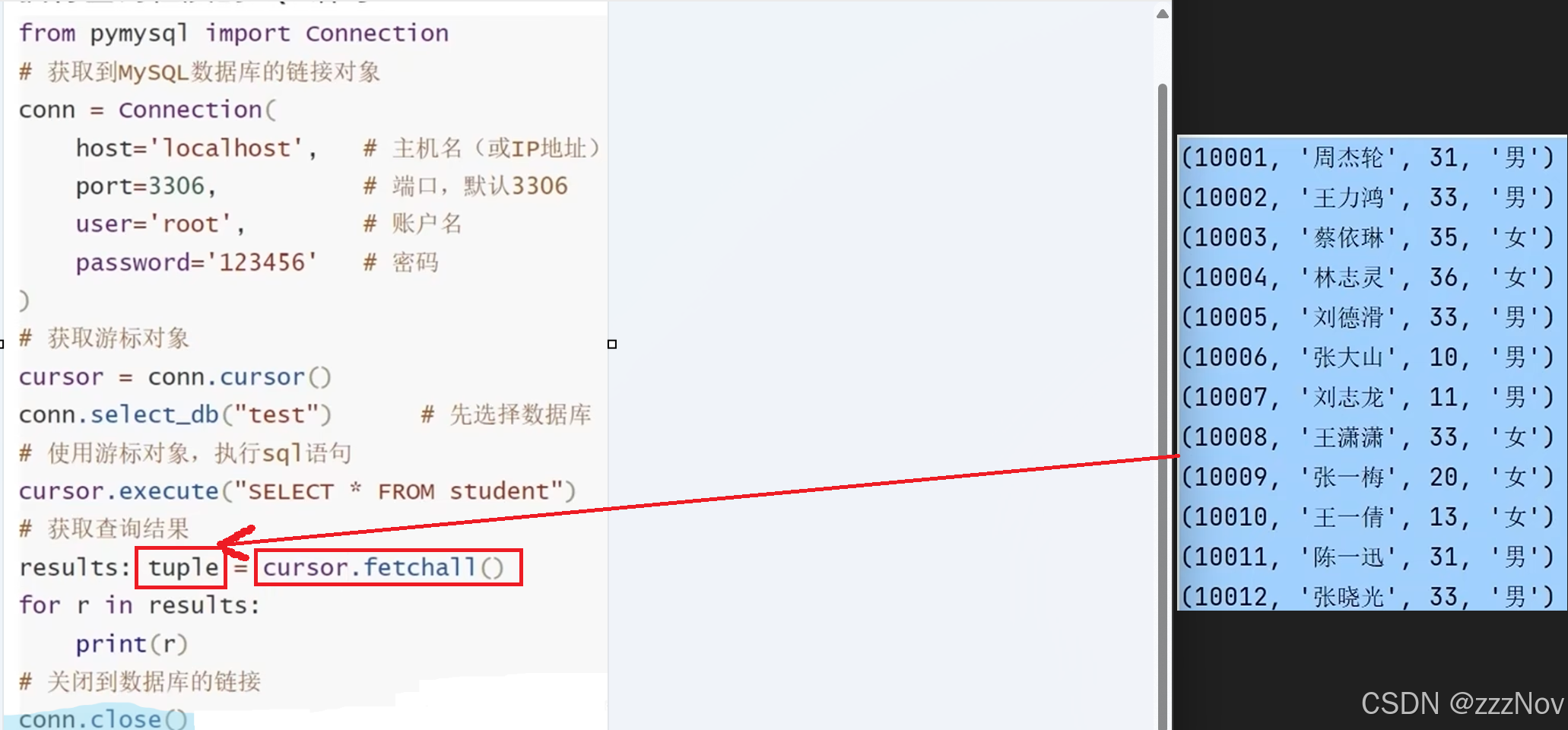
cursor.execute("select * from orders")
results :tuple = cursor.fetchall()
write_data = {}
f = open("D:\PycharmProjects\python_ex\反写数据库数据到文件.txt","a",encoding="UTF-8")
for line in results:
write_data['date'] = str(line[0])
write_data['order_id'] = str(line[1])
write_data['money'] = str(line[2])
write_data['province'] = str(line[3])
tmp = json.dumps(write_data, ensure_ascii=False)
f.write(tmp + '\n')
f.close()
第三阶段
第一章 PySpark
1.入门
from pyspark import SparkConf,SparkContext
# 创建SparkConf类对象
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
# 基于SparkConf类对象创建SparkContext对象
sc = SparkContext(conf=conf)
# 打印pySpark的运行版本
print(sc.version)
# 停止SparkContext对象的运行(停止PySpark程序)
sc.stop()

2.数据输入

方式一:parallelize()
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("")
sc = SparkContext(conf=conf)
rdd1 = sc.parallelize([1,2,3,4,5])
rdd2 = sc.parallelize((1,2,3,4,5))
rdd3 = sc.parallelize("abcde")
rdd4 = sc.parallelize({1,2,3,4,5})
rdd5 = sc.parallelize({"key1":"value1","key2":"value2"})
# 如果要查看RDD里有什么,需要使用collect()方法
print(rdd1.collect())
print(rdd2.collect())
print(rdd3.collect())
print(rdd4.collect())
print(rdd5.collect())
sc.stop()
方式二:文件
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("")
sc = SparkContext(conf=conf)
rdd = sc.textFile("D:\PycharmProjects\python_ex\sprk_dataInput.txt")
print(rdd.collect())
sc.stop()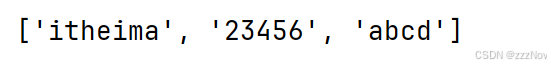

3.数据计算-map方法

import os
os.environ['PYSPARK_PYTHON'] = "D:\Program_files\Python\Python39\python.exe"
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_map")
sc = SparkContext(conf=conf)
# 准备一个RDD
rdd = sc.parallelize([1,2,3,4,5])
# 通过map方法将全部数据乘以10
def func(data):
return data * 10
rdd2 = rdd.map(func)
或
rdd2 = rdd.map(lambda x: x*10)
print(rdd2.collect())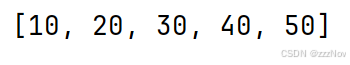
4.数据计算-flatMap

import os
os.environ['PYSPARK_PYTHON'] = "D:\Program_files\Python\Python39\python.exe"
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_map")
sc = SparkContext(conf=conf)
# 准备一个RDD
rdd = sc.parallelize(["itheima itcast 234","itheima itcast itcast","itheima itcast python"])
# 通过map方法将每个单词提取出来
rdd2 = rdd.map(lambda x: x.split(" "))# [['itheima', 'itcast', '234'], ['itheima', 'itcast', 'itcast'], ['itheima', 'itcast', 'python']]
# 通过flatMap解除嵌套
rdd3 = rdd.flatMap(lambda x: x.split(" "))# ['itheima', 'itcast', '234', 'itheima', 'itcast', 'itcast', 'itheima', 'itcast', 'python']
print(rdd3.collect())5.数据计算-reduceByKey
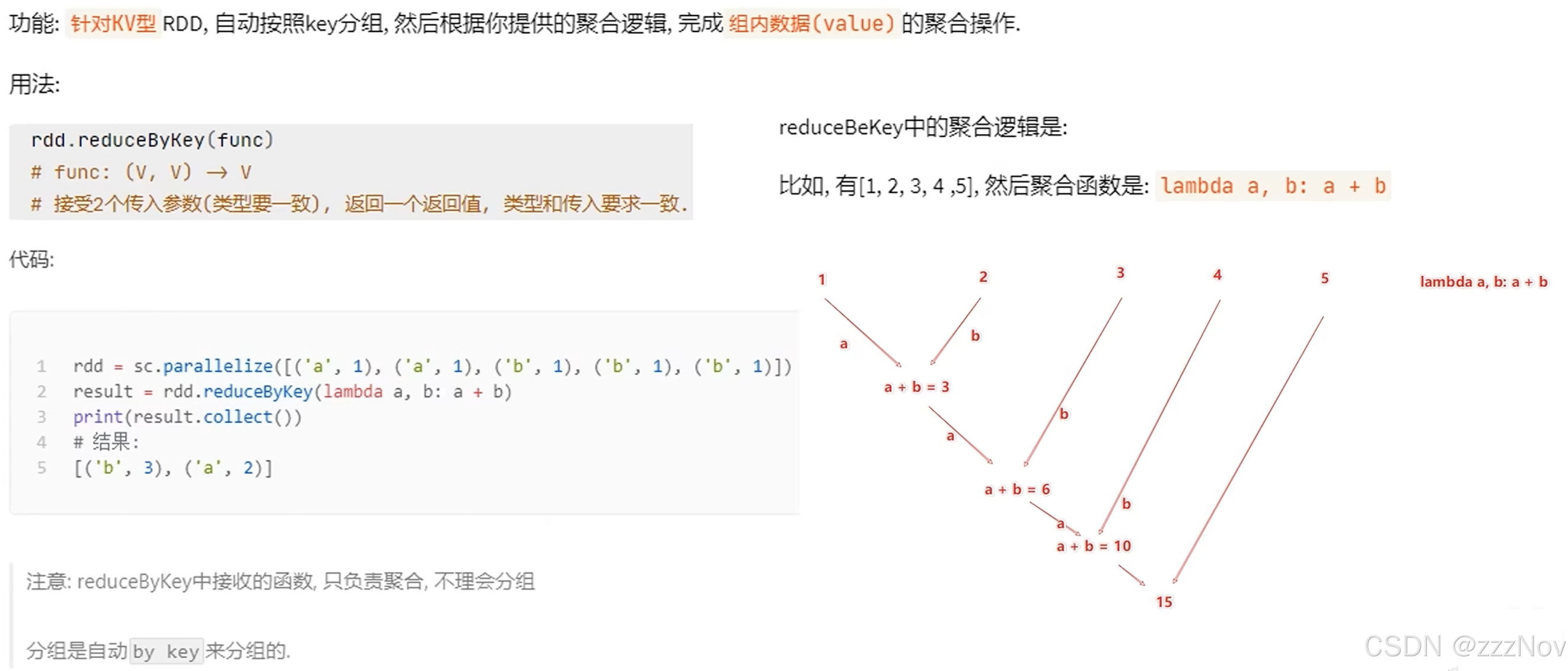
import os
os.environ['PYSPARK_PYTHON'] = "D:\Program_files\Python\Python39\python.exe"
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_map")
sc = SparkContext(conf=conf)
# 准备一个RDD
rdd = sc.parallelize([('a',23),('b',25),('b',29),('a',21)])
rdd1 = rdd.reduceByKey(lambda x,y : x+y)
print(rdd1.collect())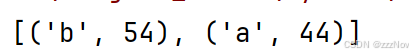
ex:


# 单词数量统计
# 1.构建执行环境入口对象
import os
os.environ['PYSPARK_PYTHON'] = "D:\Program_files\Python\Python39\python.exe"
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_wordscount")
sc = SparkContext(conf=conf)
# 2.读取数据文件
rdd = sc.textFile("D:\PycharmProjects\python_ex\Spark练习\spark_ex_1.txt")
# 3.取出全部单词
word_rdd = rdd.flatMap(lambda x : x.split(" "))
# 4.将所有单词都转换为二元元组,单词为key,value为1
word_with_one_rdd = word_rdd.map(lambda x : (x,1))
# 5.分组并求和
result_rdd = word_with_one_rdd.reduceByKey(lambda x,y : x+y)
# 6.打印输出结果
print(result_rdd.collect())6.数据计算-filter
import os
os.environ['PYSPARK_PYTHON'] = "D:\Program_files\Python\Python39\python.exe"
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_map")
sc = SparkContext(conf=conf)
# 准备一个RDD
rdd = sc.parallelize([1,2,3,4,5])
rdd2 = rdd.filter(lambda x: x%2 == 0)
print(rdd2.collect())
7.数据计算-distinct

import os
os.environ['PYSPARK_PYTHON'] = "D:\Program_files\Python\Python39\python.exe"
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_map")
sc = SparkContext(conf=conf)
# 准备一个RDD
rdd = sc.parallelize([1,2,3,4,5,1,2,3,4,5,5,6,7])
rdd2 = rdd.distinct()
print(rdd2.collect())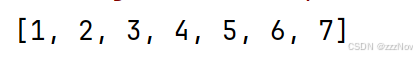
8.数据计算-sortBy
# 单词数量统计
# 1.构建执行环境入口对象
import os
os.environ['PYSPARK_PYTHON'] = "D:\Program_files\Python\Python39\python.exe"
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_wordscount")
sc = SparkContext(conf=conf)
# 2.读取数据文件
rdd = sc.textFile("D:\PycharmProjects\python_ex\Spark练习\spark_ex_1.txt")
# 3.取出全部单词
word_rdd = rdd.flatMap(lambda x : x.split(" "))
# 4.将所有单词都转换为二元元组,单词为key,value为1
word_with_one_rdd = word_rdd.map(lambda x : (x,1))
# 5.分组并求和
result_rdd = word_with_one_rdd.reduceByKey(lambda x,y : x+y)
# 6.打印输出结果
print(result_rdd.sortBy(lambda x : x[1],ascending=False,numPartitions=1).collect())
ex:

# json商品统计
# 需求:
# ①各个城市销售额排名,从大到小
# ②全部城市,有哪些商品类别在售卖
# ③北京市有哪些商品类别在售卖
# 1.构建执行环境入口对象
import json
import os
os.environ['PYSPARK_PYTHON'] = "D:\Program_files\Python\Python39\python.exe"
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_wordscount")
sc = SparkContext(conf=conf)
# 2.读取数据文件
rdd = sc.textFile("D:\PycharmProjects\python_ex\Spark练习\orders.txt")
# 3.取出一个json字符串
json_str_rdd = rdd.flatMap(lambda x : x.split("|"))
# 4.将一个json字符串转为字典
dict_rdd = json_str_rdd.map(lambda x : json.loads(x))
# 5.取出城市和销售额数据
city_with_money_rdd = dict_rdd.map(lambda x : (x['areaName'],int(x['money'])))
# 6.按城市分组 按销售额聚合
city_result_rdd = city_with_money_rdd.reduceByKey(lambda x,y : x + y)
# print(city_result_rdd.collect()) #[('杭州', 28831), ('天津', 12260), ('北京', 91556), ('上海', 1513), ('郑州', 1120)]
# 7.按销售额聚合结果进行排序
result1_rdd = city_result_rdd.sortBy(lambda x : x[1],ascending=False,numPartitions=1)
print(result1_rdd.collect())
# 8.取出全部的商品类别 9.对全部商品类别进行去重
result2_rdd = dict_rdd.map(lambda x : x['category']).distinct()
print(result2_rdd.collect())
# 10.过滤得到北京的数据
beijing_data_rdd = dict_rdd.filter(lambda x : x['areaName'] == '北京')
# 11.取出全部商品类别
result3_rdd = beijing_data_rdd.map(lambda x : x['category']).distinct()
print(result3_rdd.collect())
9.数据输出-输出为python对象


import os
os.environ['PYSPARK_PYTHON'] = "D:\Program_files\Python\Python39\python.exe"
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_wordscount")
sc = SparkContext(conf=conf)
rdd = sc.parallelize(range(1,10))
# collect算子,输出rdd对象为list对象
print(type(rdd.collect())) # <class 'list'>
# reduce算子,对rdd对象进行两两聚合
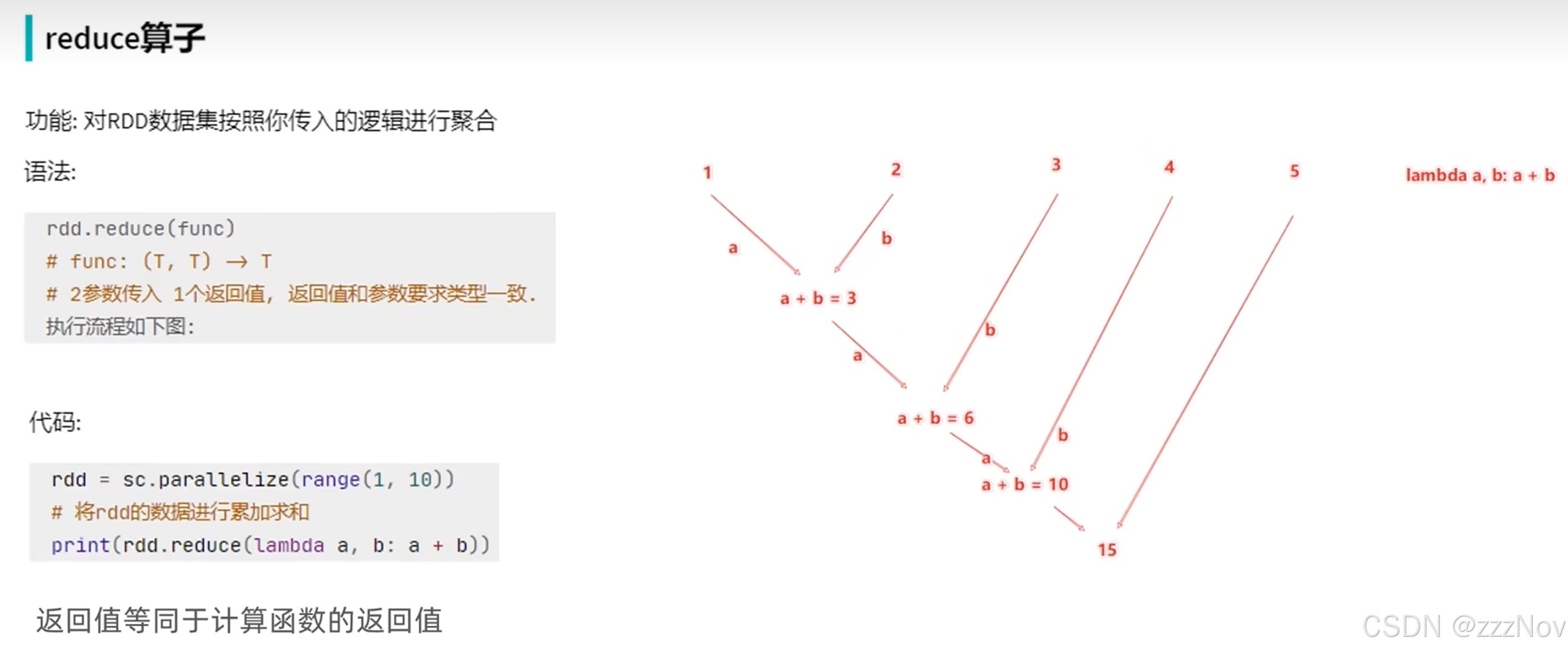
num = rdd.reduce(lambda x,y : x+y)
print(num) # 45
print(type(num)) # <class 'int'>
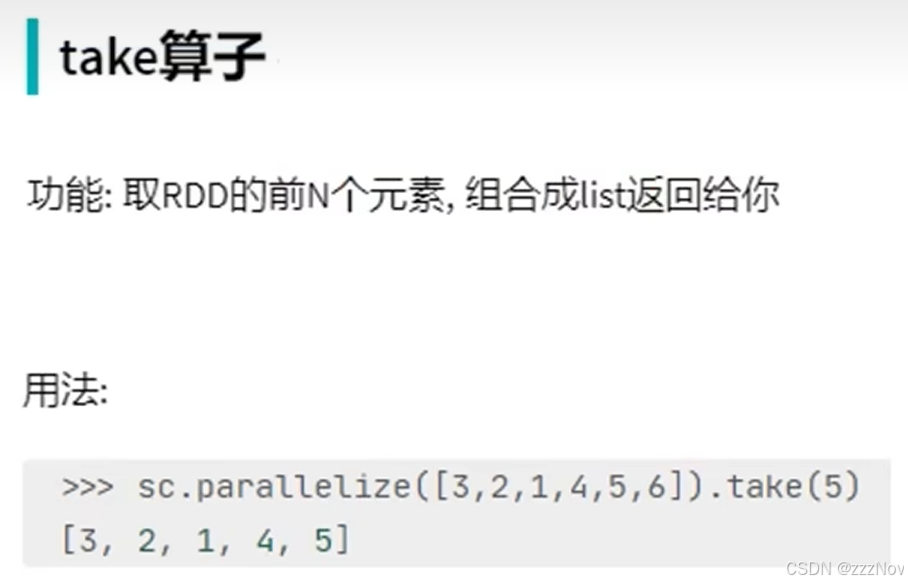
# take算子,取出rdd对象的前N个元素,组成list返回
take_rdd = rdd.take(4)
print(take_rdd) #[1, 2, 3, 4]
print(type(take_rdd)) #<class 'list'>
# count算子,统计rdd内有多少条数据,返回值为数字
print(rdd.count())
print(type(rdd.count())) # 9
sc.stop() # <class 'int'>
10.数据输出-输出到文件中

import os
os.environ['PYSPARK_PYTHON'] = "D:\Program_files\Python\Python39\python.exe"
os.environ['HADOOP_HOME'] = "D:\Program_files\Hadoop\hadoop-3.0.0"
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_map")
conf.set("spark.default.parallelism","1")
sc = SparkContext(conf=conf)
# 准备一个RDD1
rdd1 = sc.parallelize([1,2,3,4,5])
# rdd1 = sc.parallelize([1,2,3,4,5],1)
# 准备一个RDD2
rdd2 = sc.parallelize([("Hello",3),("itcast",6),("Hi",8)])
# rdd2 = sc.parallelize([("Hello",3),("itcast",6),("Hi",8)],1)
# 准备一个RDD3
rdd3 = sc.parallelize([[1,3,5],[6,7,9],[11,13,15]])
# rdd3 = sc.parallelize([[1,3,5],[6,7,9],[11,13,15]]),1)
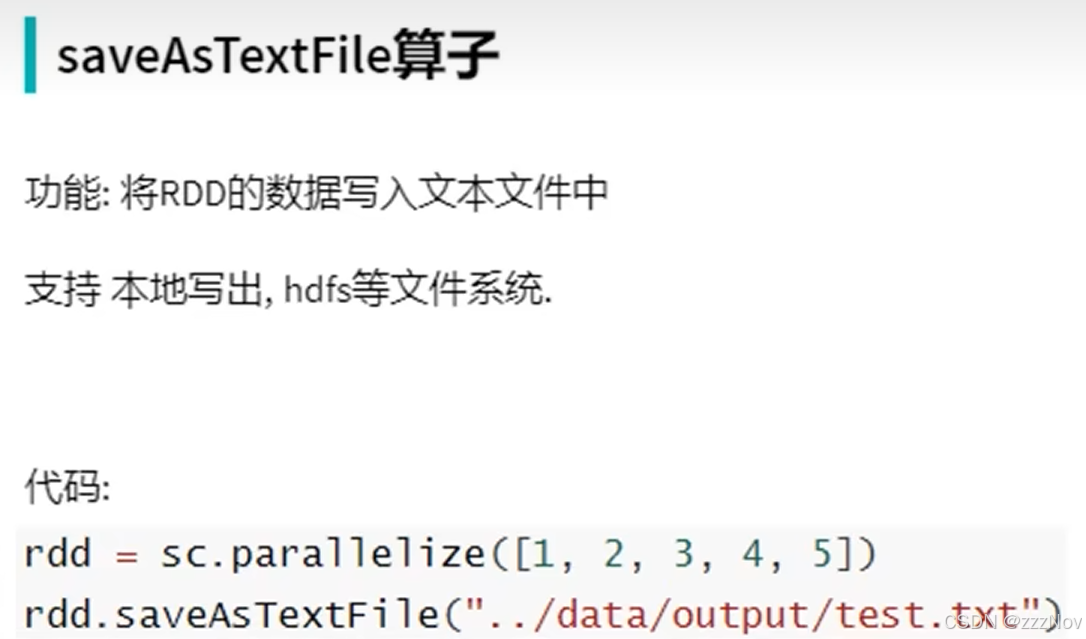
rdd1.saveAsTextFile("D:\PycharmProjects\python_ex\Spark练习\output_file_1")
rdd2.saveAsTextFile("D:\PycharmProjects\python_ex\Spark练习\output_file_2")
rdd3.saveAsTextFile("D:\PycharmProjects\python_ex\Spark练习\output_file_3")ex:

# 1.构建执行环境入口对象
import json
import os
os.environ['PYSPARK_PYTHON'] = "D:\Program_files\Python\Python39\python.exe"
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_wordscount")
conf.set("spark.default.parallelism","1")
sc = SparkContext(conf=conf)
# 2.读取数据文件
rdd = sc.textFile("D:\PycharmProjects\python_ex\Spark练习\search_log.txt")
# 2.1 取出全部的时间并转换为小时
# 2.2 转换为二元组(小时,1)
# 2.3 key分组聚合value
# 2.4 排序(降序)
# 2.5 取前3
result1 = rdd.map(lambda x: (x.split("\t")[0][:2],1)).\
reduceByKey(lambda x,y : x+y).\
sortBy(lambda x : x[1],ascending=False,numPartitions=1).\
take(3)
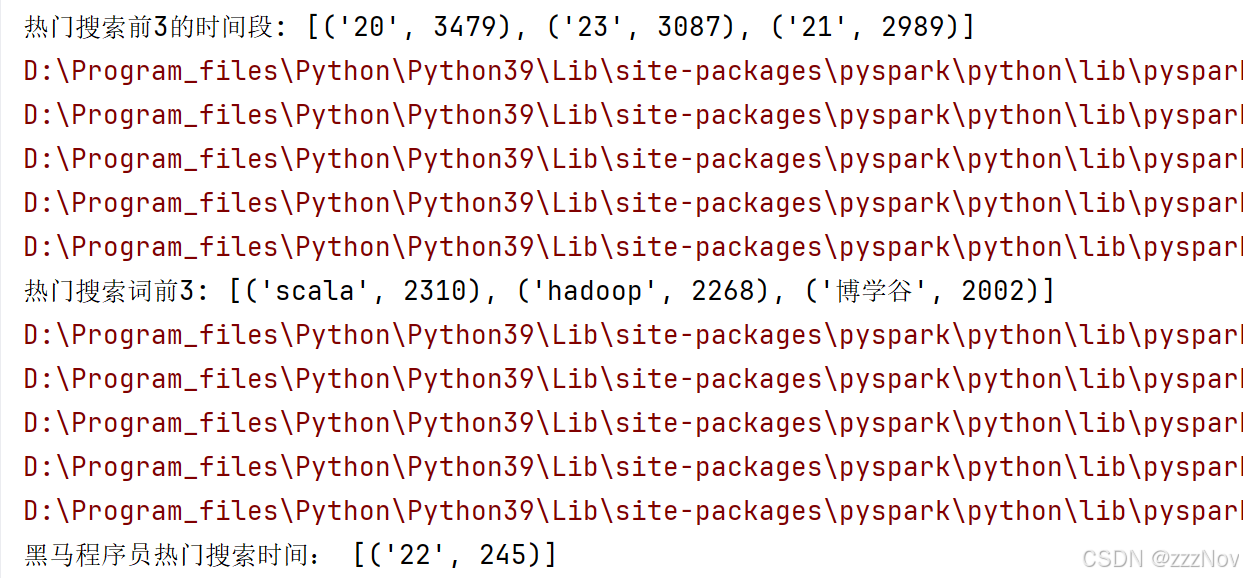
print("热门搜索前3的时间段:",result1)
# 3.1 取出全部的搜索词
# 3.2 (词,1)二元元组
# 3.3 分组聚合
# 3.4 排序
# 3.5 Top3
result2 = rdd.map(lambda x : (x.split("\t")[2],1)).\
reduceByKey(lambda x,y : x+y).\
sortBy(lambda x : x[1],ascending=False,numPartitions=1).\
take(3)
print("热门搜索词前3:",result2)
# 4.1 过滤内容,只保留黑马程序员关键字
# 4.2 转换为(小时,1)的二元元组
# 4.3 key分组聚合value
# 4.4 排序(降序)
# 4.5 取前1
result3 = rdd.map(lambda x : x.split("\t")).\
filter(lambda x : x[2] == '黑马程序员').\
map(lambda x : (x[0][:2],1)).\
reduceByKey(lambda x,y : x+y).\
sortBy(lambda x : x[1],ascending=False,numPartitions=1).\
take(1)
print("黑马程序员热门搜索时间:",result3)
# 转为json格式的rdd
# 写出到文件中
rdd.map(lambda x : x.split("\t")).\
map(lambda x : {"time":x[0],"user_id":x[1],"key_word":x[2],"rank1":x[3],"rank2":x[4],"url":x[5]}).\
saveAsTextFile("D:\PycharmProjects\python_ex\Spark练习\output_file_ex_3")
output_file_ex_3:

第二章
1.闭包
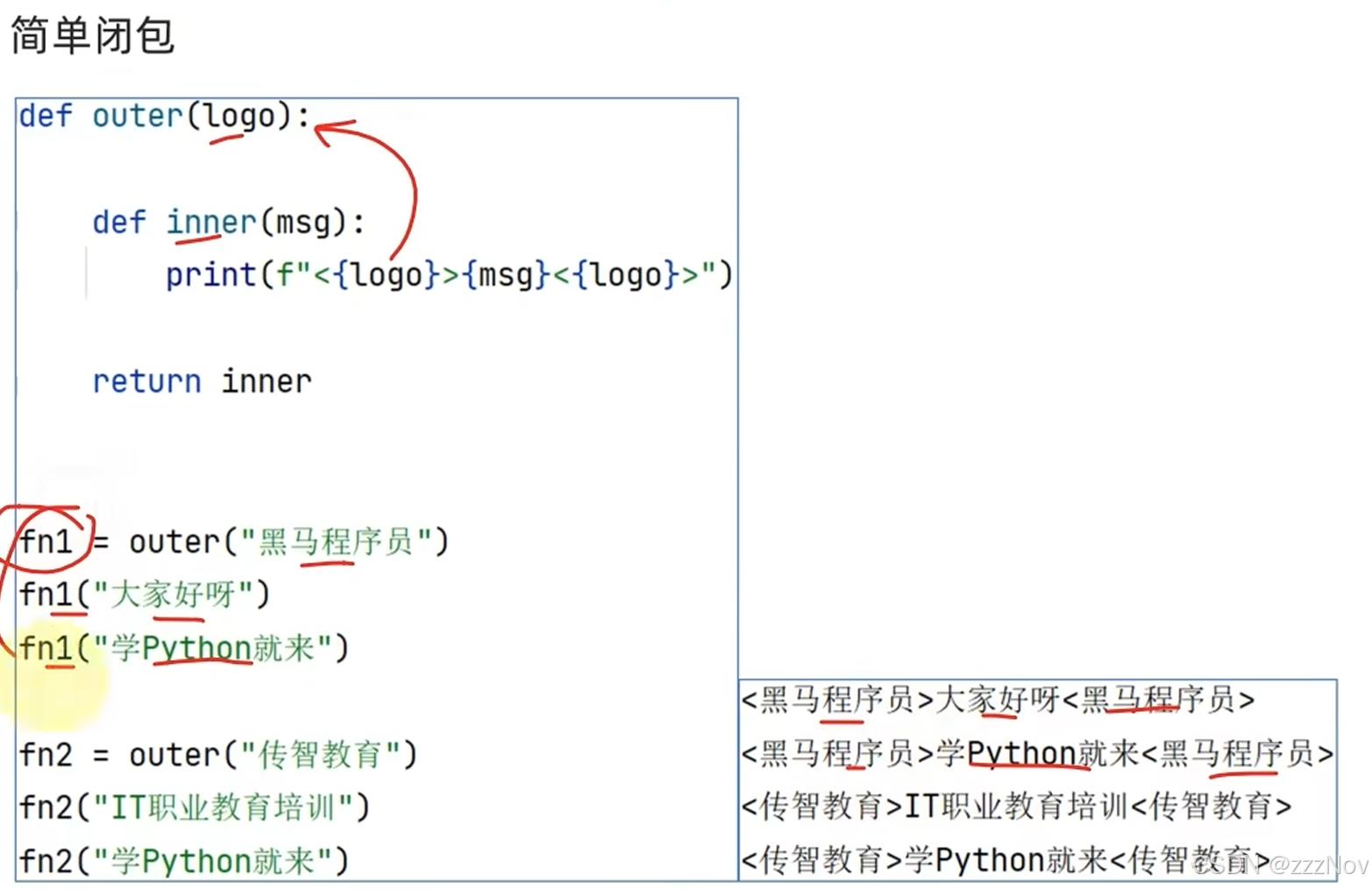
def account_create(initial_account = 0):
def atm(num,deposite = True):
nonlocal initial_account
if deposite:
initial_account += num
print(f"存款:{num},余额:{initial_account}")
else:
initial_account -= num
print(f"取款:{num},余额:{initial_account}")
return atm
atm = account_create()
atm(100)
atm(200)
atm(50,False)



2.装饰器

def outer(func):
def inter():
print("我要睡觉了")
func()
print("我睡醒了")
return inter
def sleep():
import random
import time
print("我在睡觉中")
time.sleep(random.randint(1,5))
sleep = outer(sleep)
sleep()
语法糖:
def outer(func):
def inter():
print("我要睡觉了")
func()
print("我睡醒了")
return inter
@outer
def sleep():
import random
import time
print("我在睡觉中")
time.sleep(random.randint(1,5))
sleep()
3.设计模式

3.1单例模式

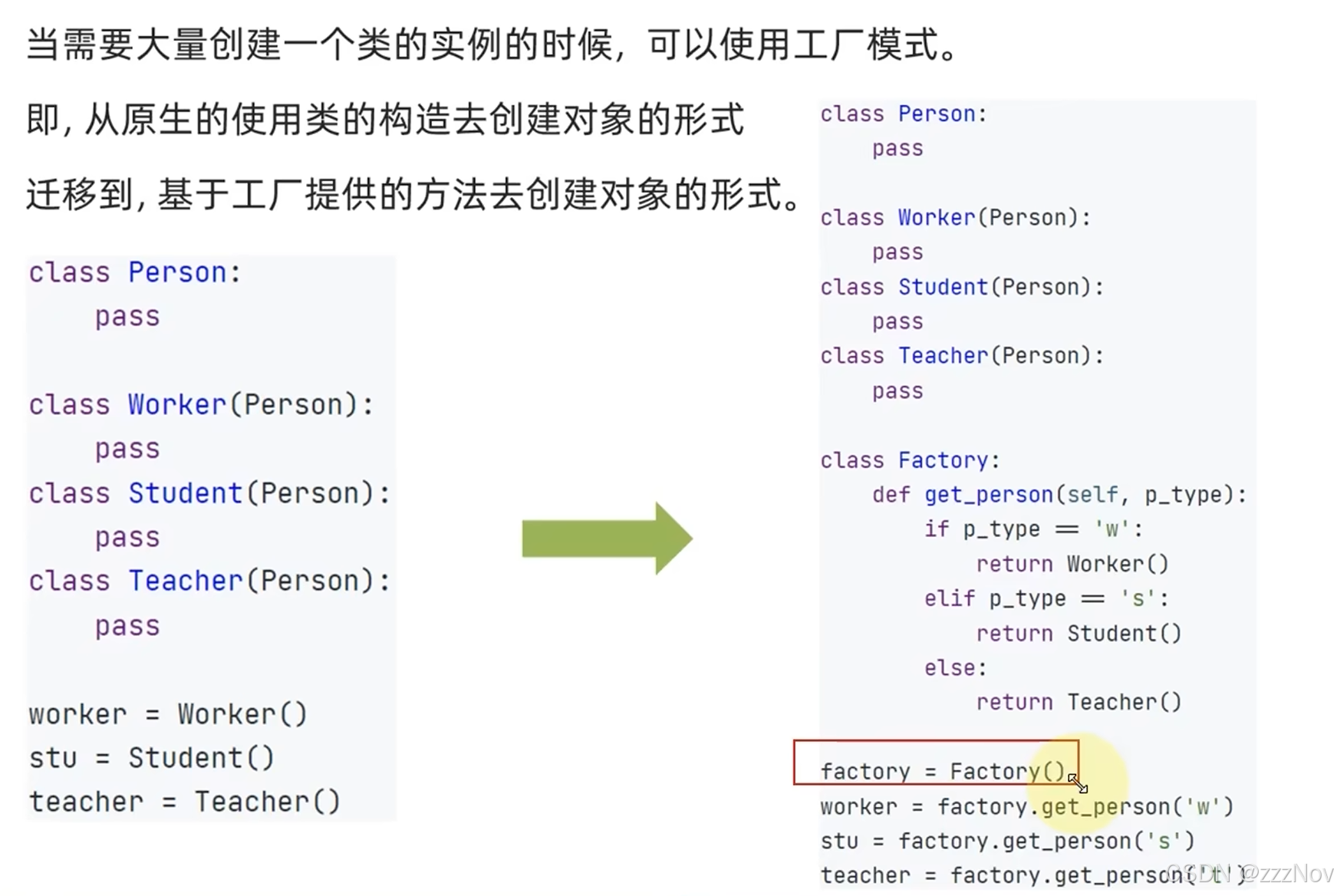
3.2 工厂模式

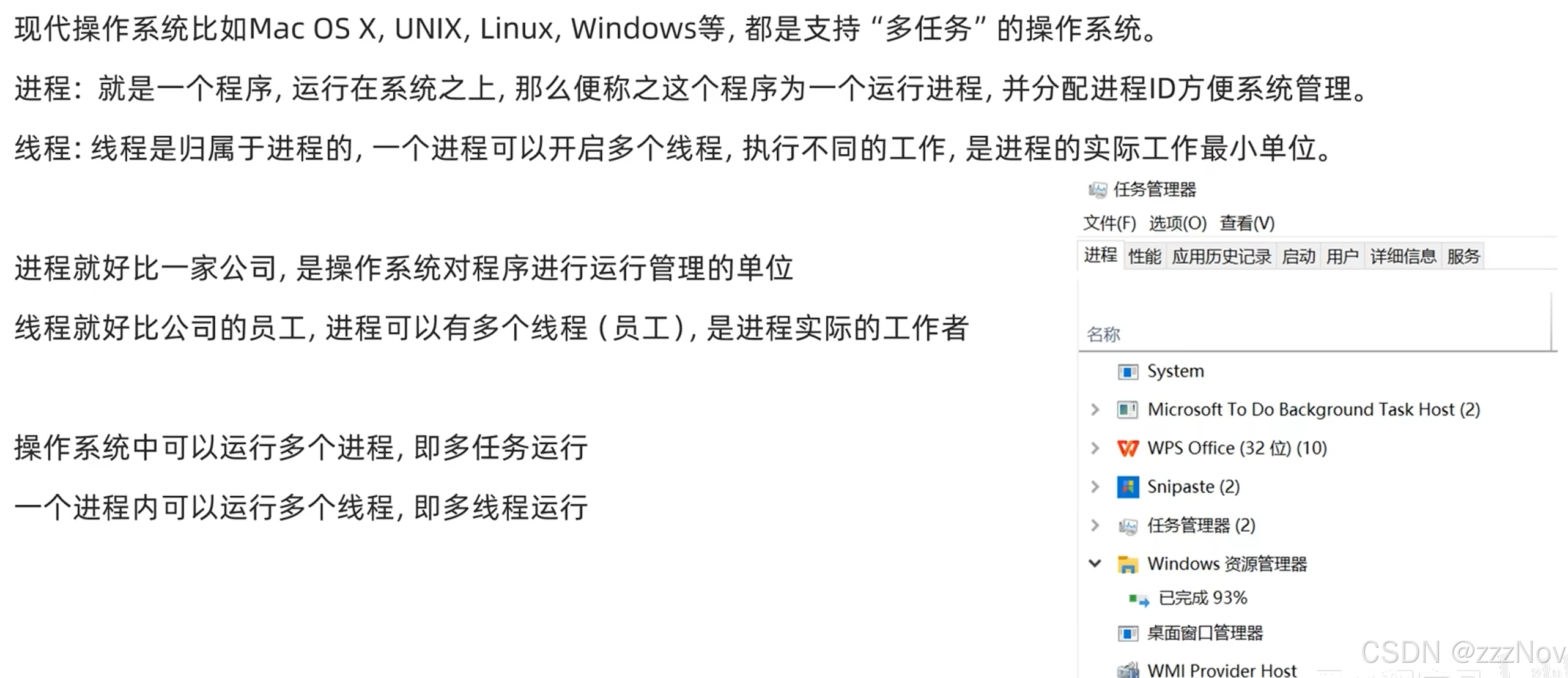
4.进程、线程
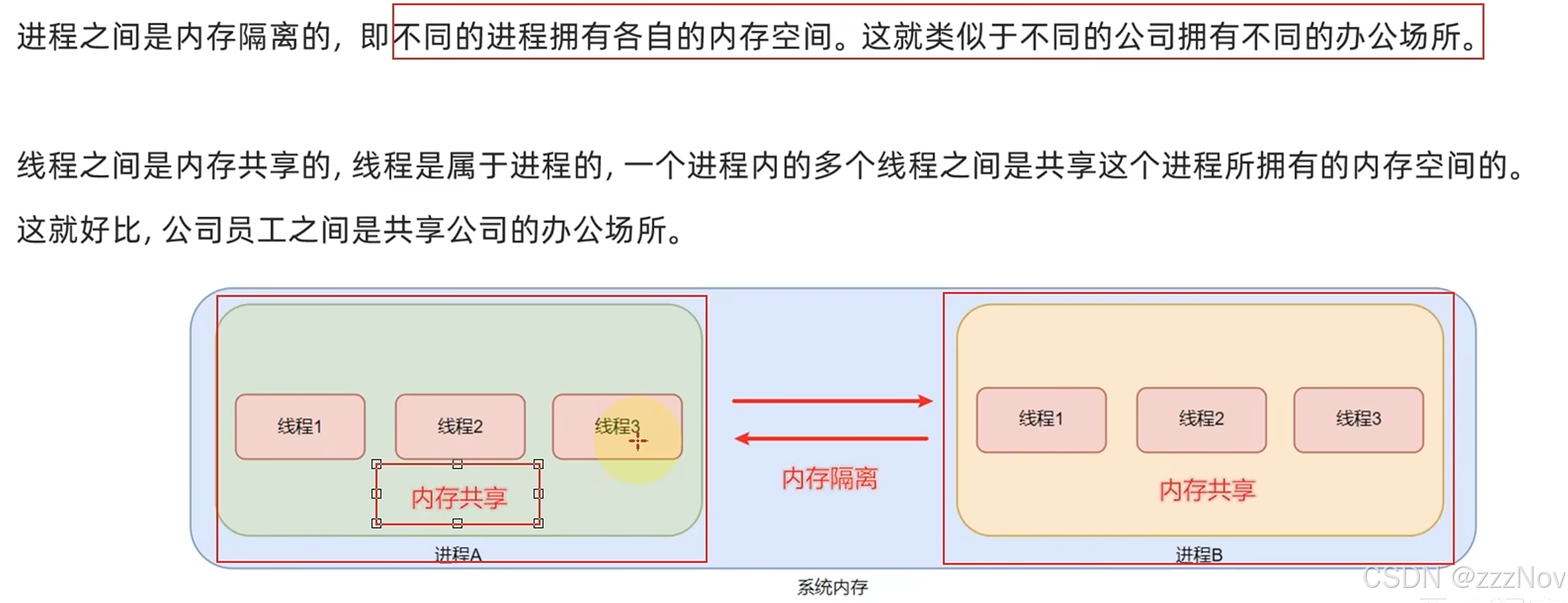
并行执行

5.多线程并行执行
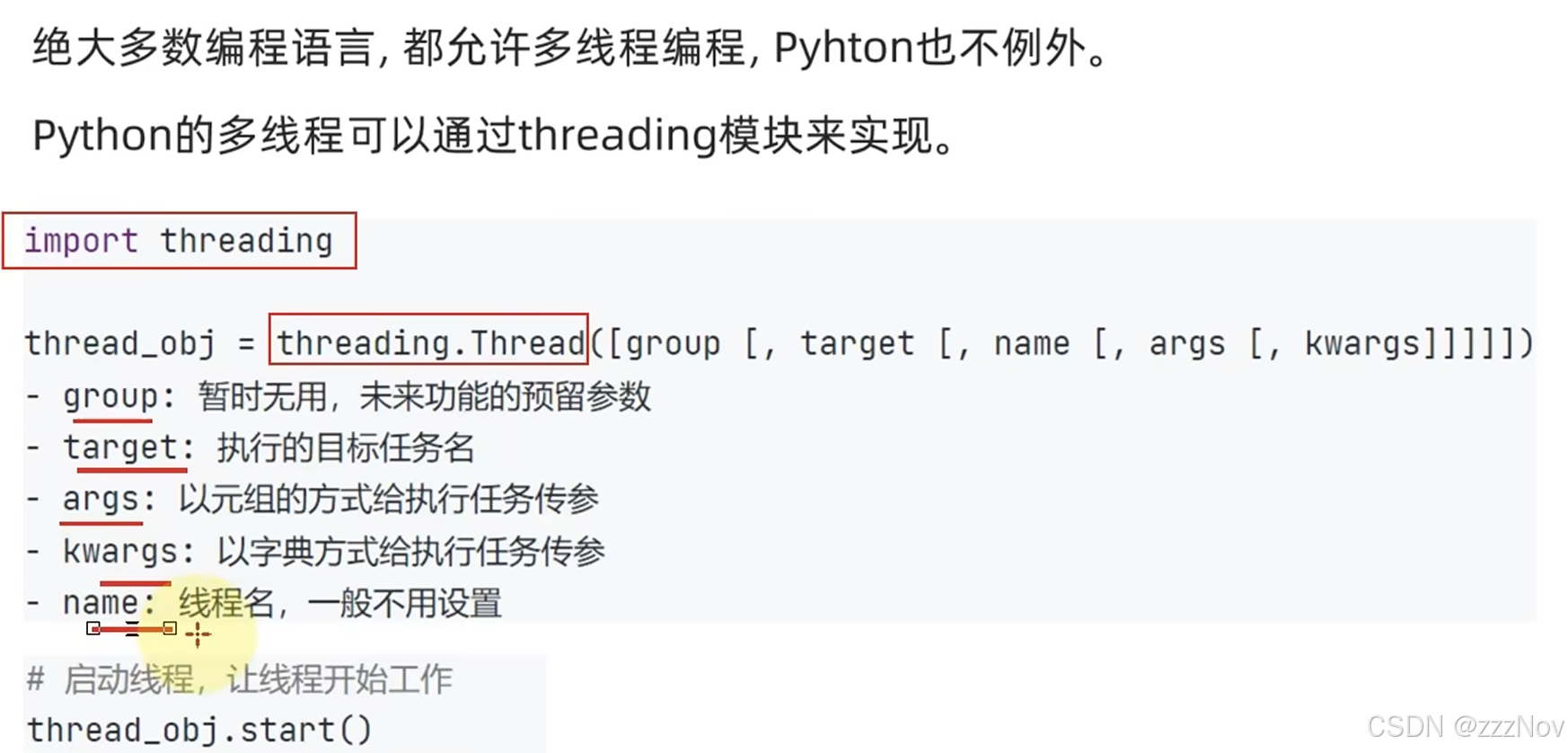
import threading
import time
def sing():
while True:
print("唱歌 do re mi fa so la xi")
time.sleep(1)
def dance():
while True:
print("跳舞💃")
time.sleep(1)
if __name__ == '__main__':
sing_thread = threading.Thread(target=sing)
dance_thread = threading.Thread(target=dance)
sing_thread.start()
dance_thread.start()

参数传递
import threading
import time
def sing(msg):
while True:
print(msg)
time.sleep(1)
def dance(msg):
while True:
print(msg)
time.sleep(1)
if __name__ == '__main__':
sing_thread = threading.Thread(target=sing,args=("唱歌 do re mi fa so la xi", ))
dance_thread = threading.Thread(target=dance,kwargs={"msg":"跳舞💃"})
sing_thread.start()
dance_thread.start()
6.Socket服务端开发

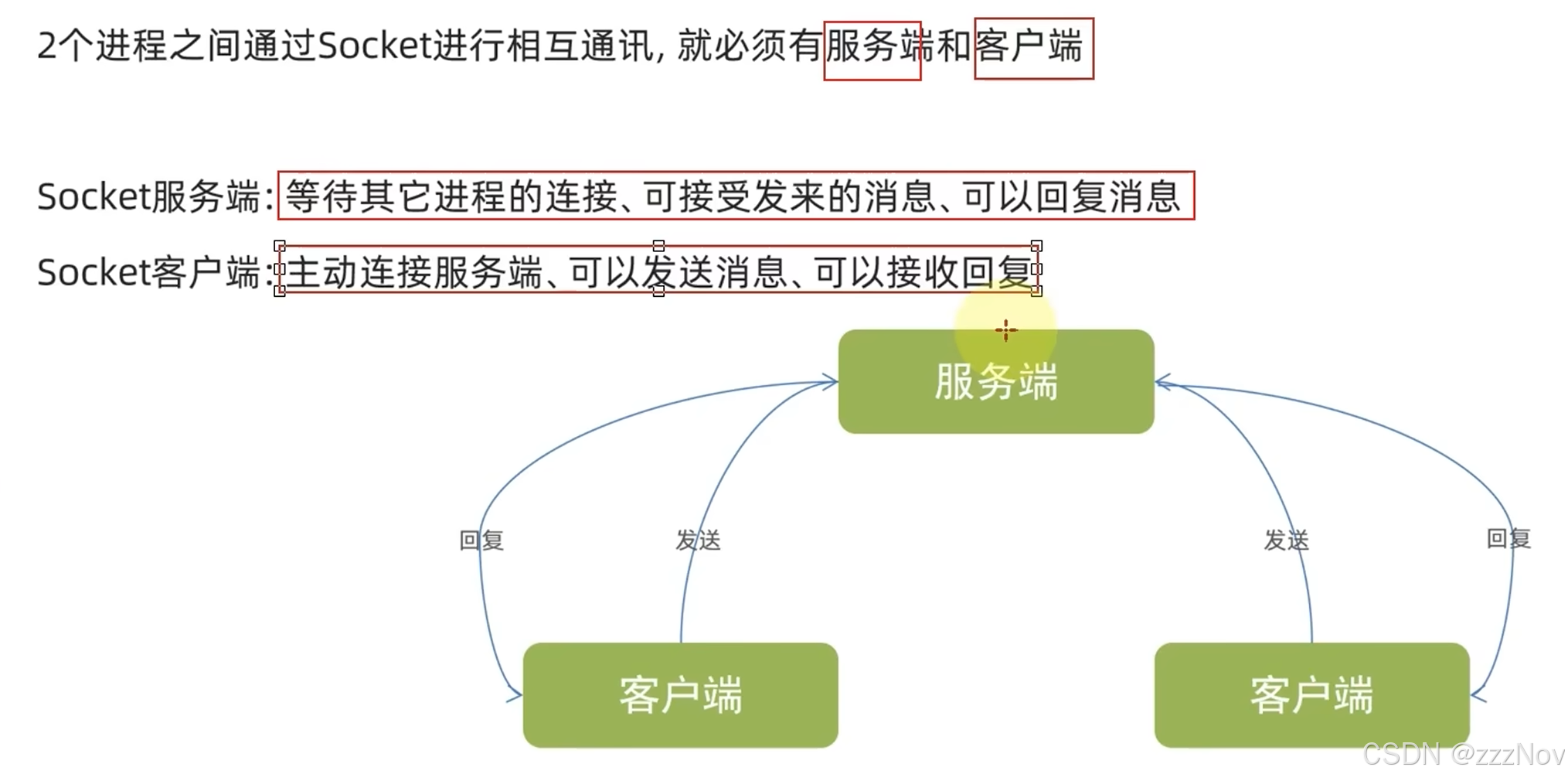
import socket
# socket服务端开发
# 创建socket对象
socket_server = socket.socket()
# 指定IP地址和端口
socket_server.bind(("localhost",8888))
# 监听器()
socket_server.listen(1) # listen()表示可以接受的客户端数量
# 等待客户端连接
# result : tuple = socket_server.accept()
# conn = result[0] #客户端和服务端的连接对象
# add = result[1] #客户端的地址信息
conn,add = socket_server.accept() # accep()方法是阻塞方法,当没有连接时,就会一直卡住不会往下执行
while True:
print("接收到了客户端的信息是:",{add})
# 接受客户端信息,使用客户端和服务端的连接对象,而非socket_server
data : str= conn.recv(1024).decode("UTF-8") #recv()传入的参数是缓冲区大小,recv返回的是byte数组对象,通过decode方法使用UTF-8解码,将字节数组转为字符串对象
print(f"客户端发来的信息是:{data}")
# 发送回复信息
msg = input("请输入你要回复客户端的信息:").encode("UTF-8") # encode可以将字符串数组编码为字节数组
if msg == 'exit':
break
conn.send(msg)
# 关闭连接
conn.close()
socket_server.close()
7.Socket客户端开发
import socket
# socket客户端开发
# 创建socket对象
socket_client = socket.socket()
# 连接到服务器
socket_client.connect(("localhost",8888))
while True:
# 发送信息
msg = input("请输入要发送给服务端的信息:")
if msg == 'exit':
break
socket_client.send(msg.encode("UTF-8"))
# 接收信息
recv_data = socket_client.recv(1024)
print(f"服务端回复的信息是:{recv_data.decode('UTF-8')}")
# 关闭连接
socket_client.close()
服务端:

客户端:

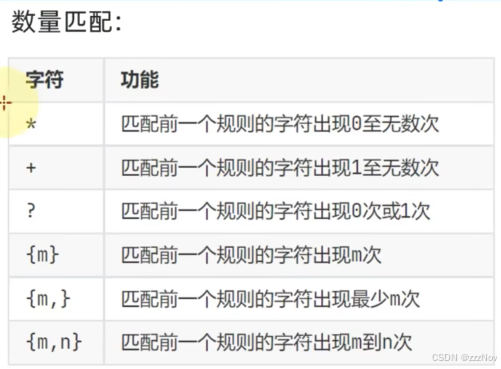
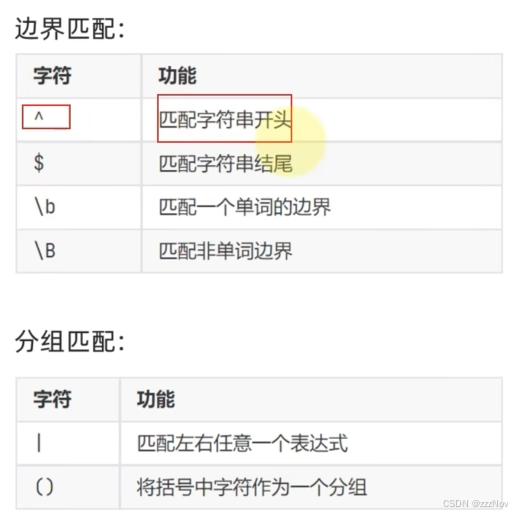
8.正则表达式



9.正则表达式-元字符匹配
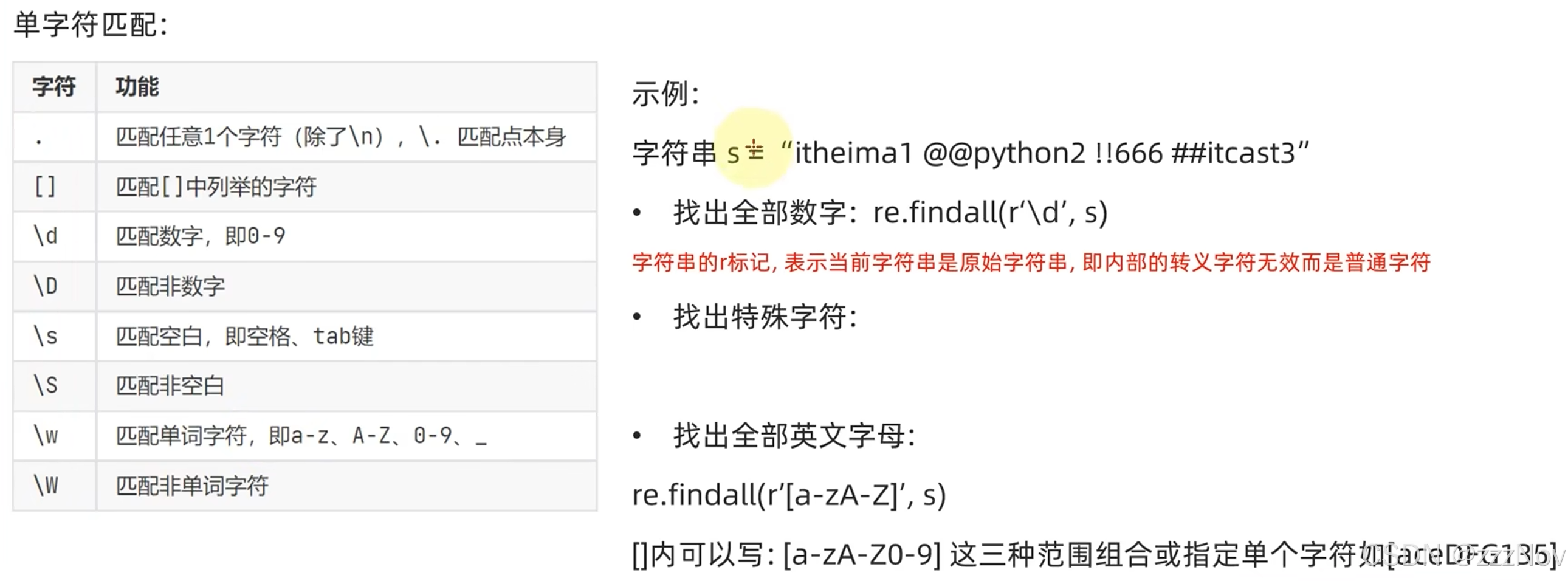
import re
s = "itheima1 @@python2 !! 666##itcast3"
result1 = re.findall(r'\d',s) # r可以使得转义字符无效,s是要匹配的字符
print(result1)
result2 = re.findall(r'\W',s) # r可以使得转义字符无效,s是要匹配的字符
print(result2)
result3 = re.findall(r'[a-zA-Z]',s) # r可以使得转义字符无效,s是要匹配的字符
print(result3)
# 匹配账号,只能由字母和数字组成,长度限制6到10位
r1 = '^[a-zA-Z0-9]{6,10}$'
s1 = '123456789'
print(re.findall(r1,s1))
# 匹配QQ号,要求纯数字,长度5-11,第一位不为0
r2 = '^[1-9][0-9]{4,10}$'
s2 = '123456'
print(re.findall(r2,s2))
# 匹配邮件地址,只允许QQ、163、gmail三种邮箱地址
# 格式:{内容}.{内容}@{内容}.{内容}.{内容}
r3 = '(^[\w-]+(\.[\w-]+)*@(qq|163|gmail)(\.[\w-]+)+$)'
s3 = 'a.b.c.d.e@163.com.w.e.r'
print(re.findall(r3,s3))
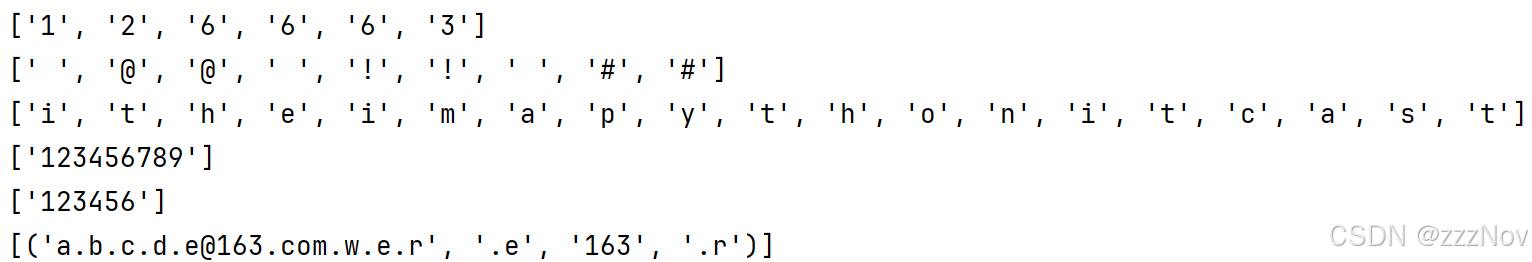
10.递归
输出文件名,对于文件夹下的文件进行递归
import os.path
def get_files_recursion_from_dir(path):
"""
从指定的文件夹中使用递归方式,获取全部的文件列表
:param path: 被判断的文件夹
:return: 包含所有文件,如果目录不存在或者无文件就返回一个空list
"""
file_list = []
if os.path.exists(path):
for f in os.listdir(path):
new_path = path + '/' + f
if os.path.isdir(new_path):
file_list += get_files_recursion_from_dir(new_path)
else:
file_list.append(new_path)
else:
print(f"指定的路劲{path}不存在")
return []
return file_list
if __name__ == '__main__':
print(get_files_recursion_from_dir("D:/PycharmProjects/python_ex/Spark练习"))['D:/PycharmProjects/python_ex/Spark练习/dataCmp_distinct.py', 'D:/PycharmProjects/python_ex/Spark练习/dataCmp_filter.py', 'D:/PycharmProjects/python_ex/Spark练习/dataCmp_flatMap.py', 'D:/PycharmProjects/python_ex/Spark练习/dataCmp_map.py', 'D:/PycharmProjects/python_ex/Spark练习/dataCmp_ReduceByKey.py', 'D:/PycharmProjects/python_ex/Spark练习/dataInput.py', 'D:/PycharmProjects/python_ex/Spark练习/dataOutput_file.py', 'D:/PycharmProjects/python_ex/Spark练习/dataOut_pythonObject.py', 'D:/PycharmProjects/python_ex/Spark练习/ex_2.py', 'D:/PycharmProjects/python_ex/Spark练习/ex_3.py', 'D:/PycharmProjects/python_ex/Spark练习/orders.txt', 'D:/PycharmProjects/python_ex/Spark练习/output_file_1/.part-00000.crc', 'D:/PycharmProjects/python_ex/Spark练习/output_file_1/._SUCCESS.crc', 'D:/PycharmProjects/python_ex/Spark练习/output_file_1/part-00000', 'D:/PycharmProjects/python_ex/Spark练习/output_file_1/_SUCCESS', 'D:/PycharmProjects/python_ex/Spark练习/output_file_2/.part-00000.crc', 'D:/PycharmProjects/python_ex/Spark练习/output_file_2/._SUCCESS.crc', 'D:/PycharmProjects/python_ex/Spark练习/output_file_2/part-00000', 'D:/PycharmProjects/python_ex/Spark练习/output_file_2/_SUCCESS', 'D:/PycharmProjects/python_ex/Spark练习/output_file_3/.part-00000.crc', 'D:/PycharmProjects/python_ex/Spark练习/output_file_3/._SUCCESS.crc', 'D:/PycharmProjects/python_ex/Spark练习/output_file_3/part-00000', 'D:/PycharmProjects/python_ex/Spark练习/output_file_3/_SUCCESS', 'D:/PycharmProjects/python_ex/Spark练习/output_file_ex_3/.part-00000.crc', 'D:/PycharmProjects/python_ex/Spark练习/output_file_ex_3/._SUCCESS.crc', 'D:/PycharmProjects/python_ex/Spark练习/output_file_ex_3/part-00000', 'D:/PycharmProjects/python_ex/Spark练习/output_file_ex_3/_SUCCESS', 'D:/PycharmProjects/python_ex/Spark练习/search_log.txt', 'D:/PycharmProjects/python_ex/Spark练习/Spark_basis.py', 'D:/PycharmProjects/python_ex/Spark练习/spark_ex_1.txt', 'D:/PycharmProjects/python_ex/Spark练习/word_count.py', 'D:/PycharmProjects/python_ex/Spark练习/word_count_filter.py']


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









