






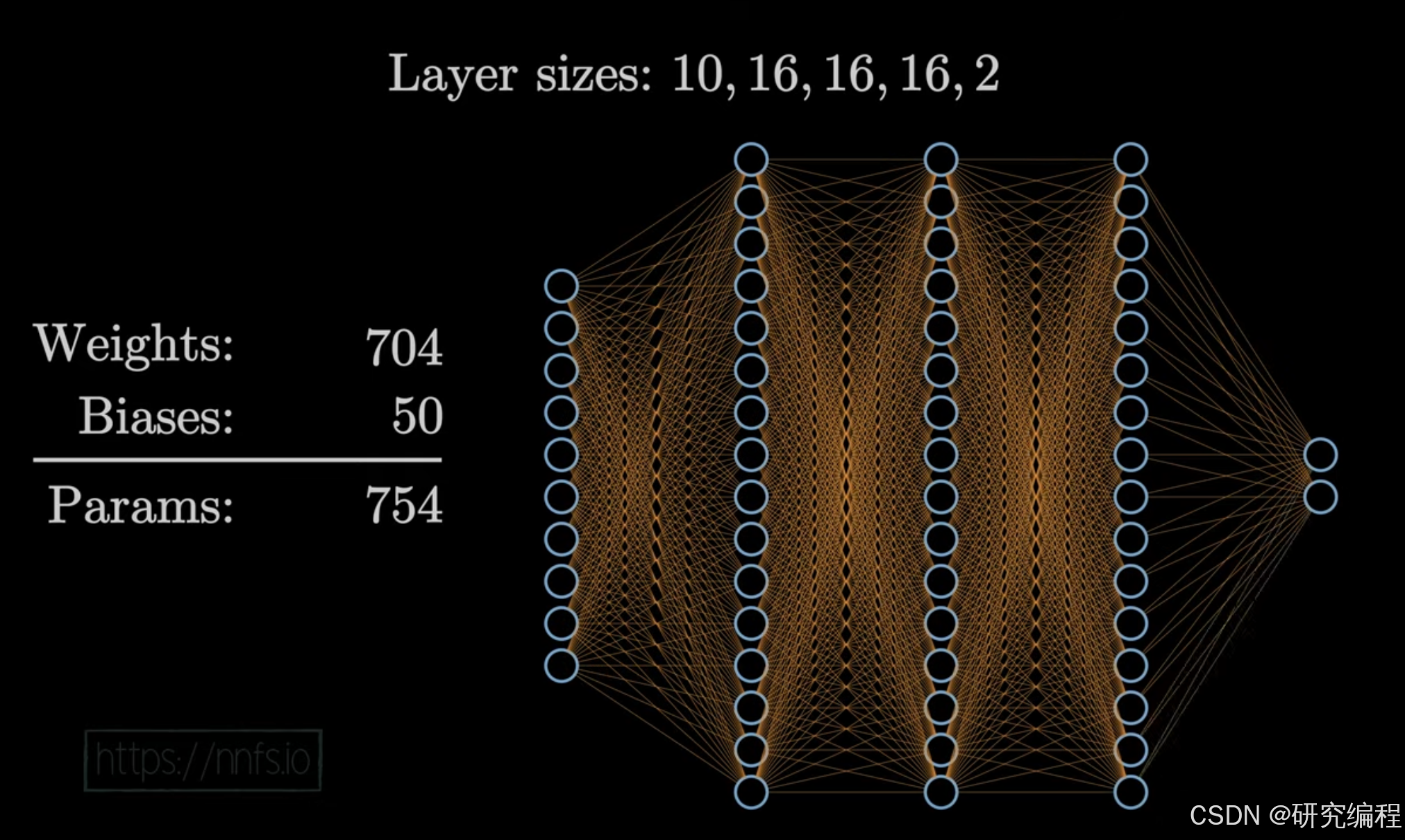
Today, we will try to implement backpropagation. We will discuss three main concepts: derivatives and partial derivatives, gradients, and the chain rule.
Backpropagation is a process of adjusting weights and biases to minimize loss in a neural network, which in turn increases its prediction accuracy. There are many ways to do backpropagation, from random and semi-random to intelligent and semi-intelligent. Randomly adjusting weights and biases may work on simple data, but with more complex patterns, this method doesn't work, as there are infinite combinations that would take infinite time to compute.
The first thing that we can do is to find which weights and biases affect the loss the most and how, and adjust those accordingly. We can do that with differentiation, or the metric of how y is affected by x.
With the linear function y = 2x, the impact, or slope, is 2 - y is double the x. With a non-linear function y = 2x^2 - a parabola, this depends on which two points (slopes) we choose to analyze.
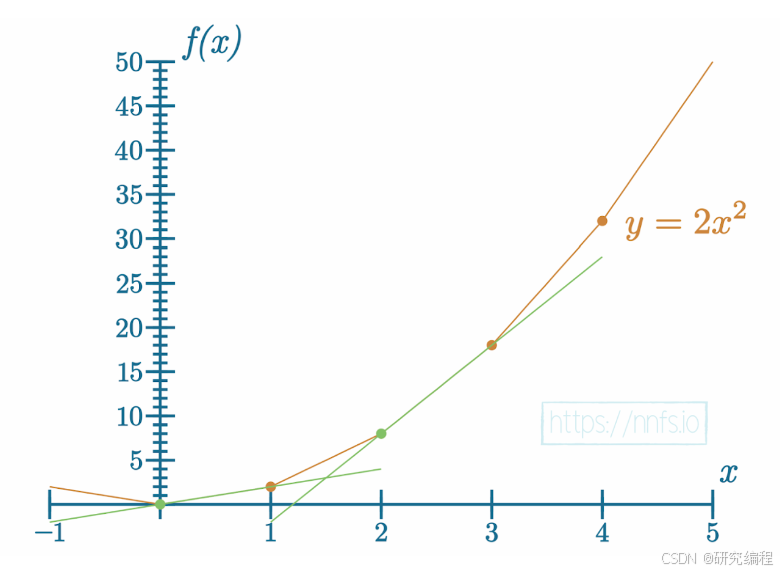
For the first 2 points, it is 2 ((y[1]-y[0]) / (x[1]-x[0])); for the third and fourth points it is 10, etc. We can draw a tangent line through these two points.
How do we quantify the impact of any x on y at a given point in a non-linear function that is more granual than that? Because the longer the distance between two points, the larger the margin of error is; we need to use two infinitely close points, but because we cannot calculate infinity, we use a very small number 0.0001. We measure the slope of the tangent line at x, the "instantaneous rate of change", which is called the derivative.
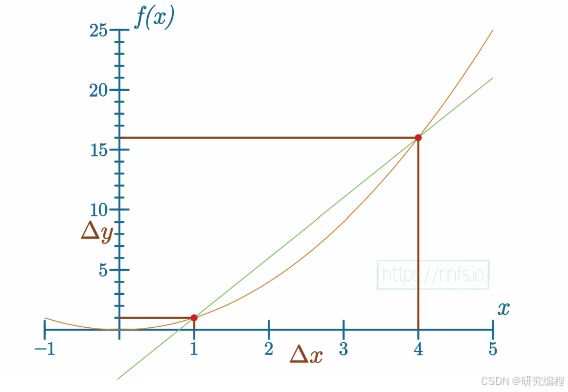
Example of two points at a large distance and the resulting error margin
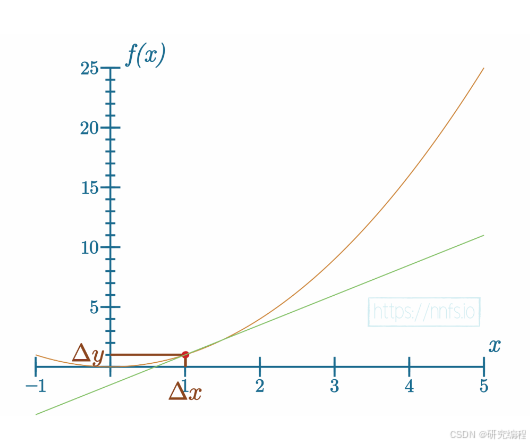
Example of tangent line at points infinitely close to each other
The tangent line tells us about the impact of x on the y at a particular point. For example, the approximate derivative for f(x) where x = 1 is 4.0001999999987845. This approach is called numerical differentiation where we come up with a number to solve a problem. There is a better method called analytical differentiation where we use a proven set of rules that let us skip a number of steps and simplify deriving inputs from outputs in our network.
Let's examine a single neuron with the ReLU activation function to illustrate those rules. Because it contains multiple inputs x1, x2, x3...xn, weights as well as the bias, all of which affect the output y, we calculate what is called the partial derivative. And because a network consists of a chain of neurons and activation functions where one neuron's output becomes another's input, we need to calculate partial derivatives for every element in the chain. For that, we apply the so-called chain rule.
let x = [1.0, -2.0, 3.0]
let w = [-3.0, -1.0, 2.0]
let b = 1.0
let xw0 = x[0] * w[0]
let xw1 = x[1] * w[1]
let xw2 = x[2] * w[2]
println("Dot product of inputs and weights: ${xw0} ${xw1} ${xw2}")
let z = xw0 + xw1 + xw2 + b
println("Dot product of inputs and weights + bias: ${z}")
let y = max([z, 0.0]).getOrThrow()
println("ReLU output: ${y}")
>>>
Dot product of inputs and weights: -3.000000 2.000000 6.000000
Dot product of inputs and weights + bias: 6.000000
ReLU output: 6.000000Imagine that a derivative from the next layer is 1. We call it `dvalue`. The rule is that the derivative of the max() function (ReLU) is 1 for values that are > 0 and 0 for others.
let dvalue = 1.0
func f() {
if (z > 0.0) {
return 1.0
} else {
return 0.0
}
}
let dreluDz = dvalue * f()
println(dreluDz)
>>> 1.0Remember that we are moving backwards and finding (deriving) x by the value y.
Because ReLU output is 6 (and the rule says that everything above 0 is 1), the derivative of ReLU function is 1 * 1 (dvalue from the previous layer) = 1.
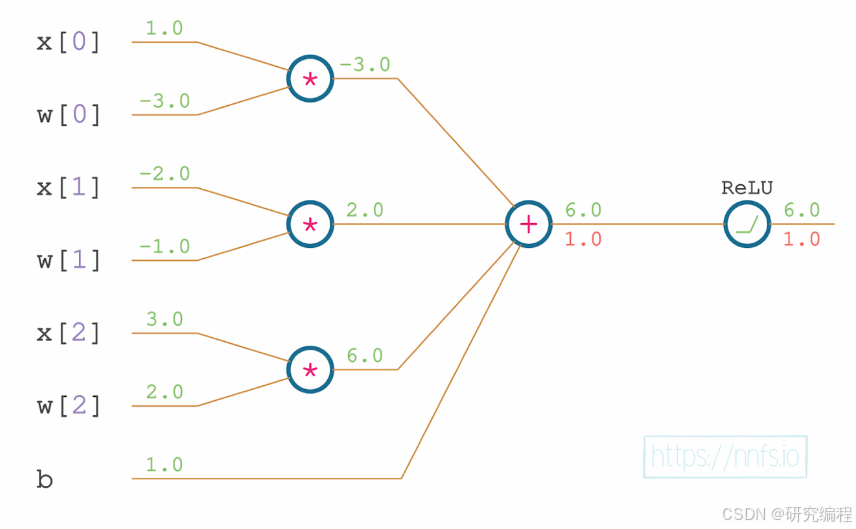
Next, we deal with partial derivatives, as the neuron's output is the results of the dot product of inputs and weights + bias.
The rule says that the derivative of a sum is always 1. As the result, the sum of dot product and the bias is 1. Multiplying it with the derivative from ReLU (1) gives us 1.
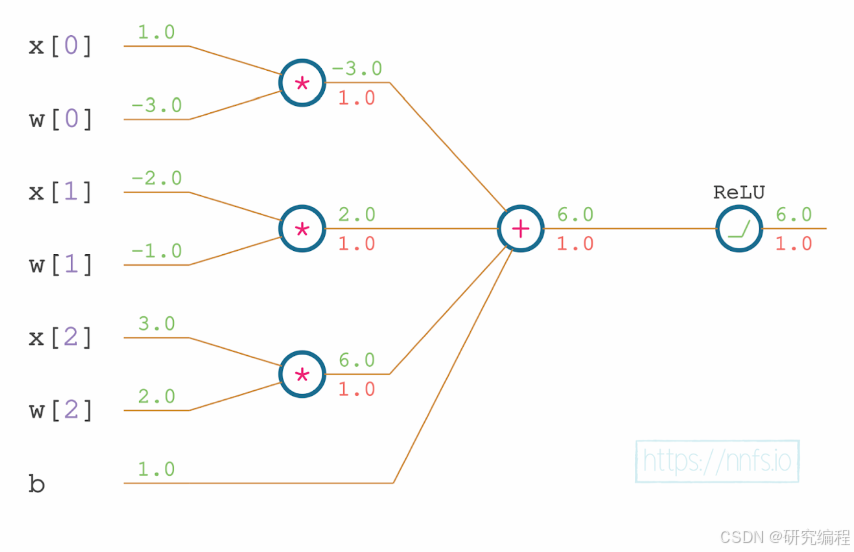
let dsumDxw0 = 1.0
let dreluDxw0 = dreluDz * dsumDxw0
println(dreluDxw0)
>>> 1.0dsumDxw0 above is "the partial derivative of the sum with respect to the x (input), weighted, for the 0th pair of inputs and weights". We repeat that for dsumDxw1, dsumDxw2, and the bias.
Because bias does not have a preceding operation, its derivative is 1, which we then multiply by the derivative of ReLU: 1.0 * 1.0 = 1.0.
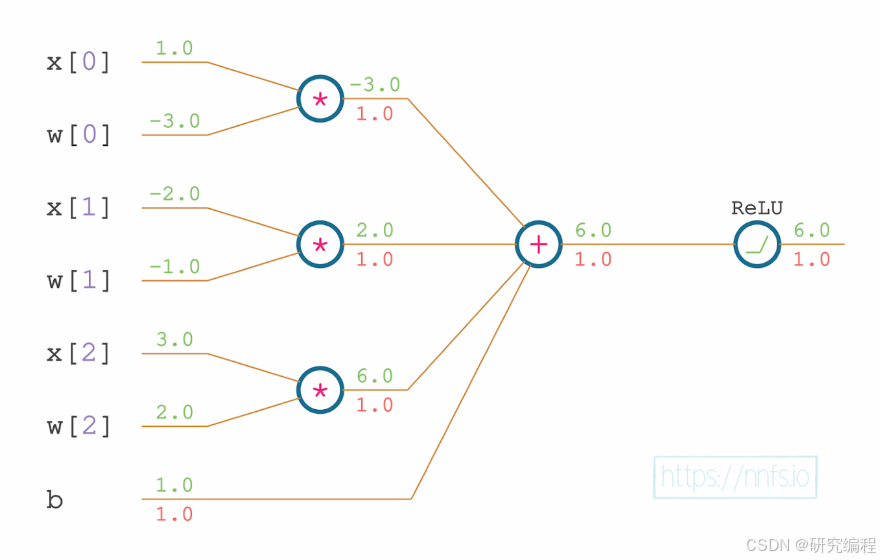
The next step is the derivatives of multiplication of the dot product. The derivative for a product is whatever the input is being multiplied by. We multiply the value of the first weight by the previous derivative, which is 1: -3.0 * 1.0 = -3.0, which gives us the derivative of the dot product respective to x[0]. We repeat that for every input: -1.0 (w[1]) * 1.0 = -1.0; 3.0 (w[2]) * 1.0 = 3.0.
The derivatives of the dot product respective to weights is a similar operation: 1.0 (x[0]) * 1.0 = 1.0 (w[0]); -2.0 (x[1]) * 1.0 = -2.0 (w[1]); 3.0 (x[2]) * 1.0 = 3.0 (w[2]).
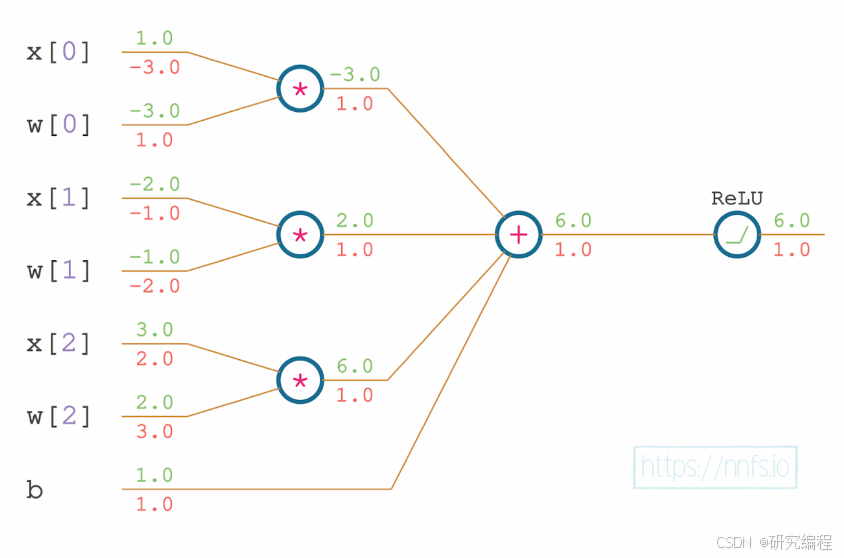
The current values for weights are [-3.0, -1.0, 2.0] and the bias is 1.0.
In order to decrease the loss in the full network or in this case the output of the ReLU function, we can apply the derived gradients to these values. The value of -0.001 is called learning rate. It specifies the amount by which the parameters are altered in the direction opposite to the gradient of the loss function. Because we want to decrease the output, the value is negative.
w[0] = -3.0 (w[0]) + -0.001 * 1.0 (dw[0]) = -3.001
w[1] = -1.0 (w[1]) + -0.001 * -2.0 (dw[1]) = -1.0 + 0.002 = -0.998
w[2] = 2.0 (w[2]) + -0.001 * 3.0 (dw[2]) = 2.0 + -0.003 = 1.997
b = 1.0 (b) + -0.001 * 1.0 (db) = 0.999
If we do a forward pass with these new values, we will get 5.985 - a decrease of 0.015.
Now to scale it all up to a single layer:
let dvalues = Matrix([[1.0, 1.0, 1.0], [2.0, 2.0, 2.0], [3.0, 3.0, 3.0]])
let weights = Matrix([[0.2, 0.8, -0.5, 1.0], [0.5, -0.91, 0.26, -0.5], [-0.26, -0.27, 0.17, 0.87]]).transpose()
let dinputs = dvalues.times(weights.transpose())
println(dinputs.getArray())
>>> [[0.440000, -0.380000, -0.070000, 1.370000], [0.880000, -0.760000, -0.140000, 2.740000], [1.320000, -1.140000, -0.210000, 4.110000]]What we did manually is basically the dot product, so the above operation where we find derivative values for x can be done like this.
let dvalues = Matrix([[1.0, 1.0, 1.0], [2.0, 2.0, 2.0], [3.0, 3.0, 3.0]])
let inputs = Matrix([1.0, 2.0, 3.0, 2.5], [2.0, 5.0, -1.0, 2.0], [-1.5, 2.7, 3.3, -0.8])
let dweights = inputs.transpose().times(dvalues)
println(dweights.getArray())
>>> [[0.500000, 0.500000, 0.500000], [20.100000, 20.100000, 20.100000], [10.900000, 10.900000, 10.900000], [4.100000, 4.100000, 4.100000]]The same is done for the weights...
let dvalues = Matrix([[1.0, 1.0, 1.0], [2.0, 2.0, 2.0], [3.0, 3.0, 3.0]])
let biases = Matrix([[2.0, 3.0, 0.5]])
let dbiases = Matrix(Array<Array<Float64>>(1, {_ => Array<Float64>(3, {_ => 0.0})}))
for (i in dvalues.getArray()) {
dbiases.plusEquals(Matrix(i))
}
println(dbiases.getArray())
>>> [[6.000000, 6.000000, 6.000000]]...and biases. Because the derivative of a sum is 1, we can ignore the biases and simply do a column-wise sum of the incoming derivatives, which gets us our bias derivatives.
Because we can't do column-wise sum in `matrix4cj`, there is a workaround of splitting the columns into individual matrices and summing them up with the `plusEquals` operation. For that, we create an intermediate array filled with zeroes: 0 + 1 + 2 + 3 = 6.
The last step is the derivative of ReLU.
let z = [[1.0, 2.0, -3.0, -4.0], [2.0, -7.0, -1.0, 3.0], [-1.0, 2.0, 5.0, -1.0]]
let dvalues = [[1.0, 2.0, 3.0, 4.0], [5.0, 6.0, 7.0, 8.0], [9.0, 10.0, 11.0, 12.0]]
let drelu = Array<Array<Float64>>(z.size, {_ => Array<Float64>(z[0].size, {_ => 0.0})})
for (i in 0..drelu.size) {
for (j in 0..drelu[i].size) {
if (z[i][j] > 0.0) {
drelu[i][j] = 1.0
}
}
}
println(drelu)
for (i in 0..drelu.size) {
for (j in 0..drelu[i].size) {
drelu[i][j] *= dvalues[i][j]
}
}
print(drelu)
>>>
[[1.000000, 1.000000, 0.000000, 0.000000], [1.000000, 0.000000, 0.000000, 1.000000], [0.000000, 1.000000, 1.000000, 0.000000]]
[[1.000000, 2.000000, 0.000000, 0.000000], [5.000000, 0.000000, 0.000000, 8.000000], [0.000000, 10.000000, 11.000000, 0.000000]]*z is example layer outputs.
We also create an array filled with zeroes that has the same shape as layer outputs. Then, by looping through the nested structure, we find every value that is > 0, and mark it with 1.0 in the `drelu` array. We then multiply the `drelu` array by the array with derivative values from the previous layer.
let z = [[1.0, 2.0, -3.0, -4.0], [2.0, -7.0, -1.0, 3.0], [-1.0, 2.0, 5.0, -1.0]]
let dvalues = [[1.0, 2.0, 3.0, 4.0], [5.0, 6.0, 7.0, 8.0], [9.0, 10.0, 11.0, 12.0]]
let drelu = dvalues.clone()
for (i in 0..drelu.size) {
for (j in 0..drelu[i].size) {
if (z[i][j] <= 0.0) {
drelu[i][j] = 0.0
}
}
}
println(drelu)
>>> [[1.000000, 2.000000, 0.000000, 0.000000], [5.000000, 0.000000, 0.000000, 8.000000], [0.000000, 10.000000, 11.000000, 0.000000]]We can greatly simplify these operations by doing the inverse - marking values that are less than or equal 0 - with 0. This gives us the same result as before.
Now let's do test forward and backward passes.
let dvalues = Matrix([[1.0, 1.0, 1.0], [2.0, 2.0, 2.0], [3.0, 3.0, 3.0]])
let inputs = Matrix([[1.0, 2.0, 3.0, 2.5], [2.0, 5.0, -1.0, 2.0], [-1.5, 2.7, 3.3, -0.8]])
let weights = Matrix([[0.2, 0.8, -0.5, 1.0], [0.5, -0.91, 0.26, -0.5], [-0.26, -0.27, 0.17, 0.87]]).transpose()
// let biases = Matrix([[2.0, 3.0, 0.5]])
let biases = Matrix(Array<Array<Float64>>(inputs.getArray().size, {_ => [2.0, 3.0, 0.5]}))
println(biases.getArray())
// Forward pass
// ===========================
let layer_outputs = inputs.times(weights).plus(biases)
println(layer_outputs.getArray())
// ReLU
func maximum(input: Array<Float64>): Array<Float64> {
func clip(i: Float64): Float64 {
if (i > 0.0) {
return i
} else {
return 0.0
}
}
return input |> map {i => clip(i)} |> collectArray
}
let output = ArrayList<Array<Float64>>([])
for (array in layer_outputs.getArray()) {
output.append(maximum(array))
}
let relu_outputs = output.toArray()
println(relu_outputs)
// Backward pass
// ===========================
// ReLU derivatives
let drelu = relu_outputs.clone()
for (i in 0..drelu.size) {
for (j in 0..drelu[i].size) {
if (layer_outputs.getArray()[i][j] <= 0.0) {
drelu[i][j] = 0.0
}
}
}
// Layer output derivatives
let dinputs = Matrix(drelu).times(weights.transpose())
// Layer weight derivatives
let dweights = inputs.transpose().times(Matrix(drelu))
// Layer bias derivatives
let dbiases = Matrix(Array<Array<Float64>>(1, {_ => Array<Float64>(drelu[0].size, {_ => 0.0})}))
for (i in drelu) {
dbiases.plusEquals(Matrix(i))
}
println(dbiases.getArray())
let dbiasesPadded = Matrix(Array<Array<Float64>>(biases.getArray().size, {_ => dbiases.getArray()[0]}))
println(dbiasesPadded.getArray())
// Adjusting weights and biases to reduce ReLU output
weights.plusEquals(dweights.times(-0.001))
biases.plusEquals(dbiasesPadded.times(-0.001))
println(weights.getArray())
println(biases.getArray()[0])Padded biases:
[[2.000000, 3.000000, 0.500000], [2.000000, 3.000000, 0.500000], [2.000000, 3.000000, 0.500000]]
Layer outputs:
[[4.800000, 1.210000, 2.385000], [8.900000, -1.810000, 0.200000], [1.410000, 1.051000, 0.026000]]
ReLU outputs:
[[4.800000, 1.210000, 2.385000], [8.900000, 0.000000, 0.200000], [1.410000, 1.051000, 0.026000]]
Layer bias derivatives:
[[15.110000, 2.261000, 2.611000]]
Layer bias derivatives padded:
[[15.110000, 2.261000, 2.611000], [15.110000, 2.261000, 2.611000], [15.110000, 2.261000, 2.611000]]
New weights and biases (padded):
[[0.179515, 0.500367, -0.262746], [0.742093, -0.915258, -0.275840], [-0.510153, 0.252902, 0.162959], [0.971328, -0.502184, 0.863658]]
[[1.984890, 2.997739, 0.497389], [1.984890, 2.997739, 0.497389], [1.984890, 2.997739, 0.497389]]
If we do a second forward pass with these weights and biases, we get different results.
// Second forward pass
let layer_outputs2 = inputs.times(weights).plus(biases)
println(layer_outputs2.getArray())
let output2 = ArrayList<Array<Float64>>([])
for (array in layer_outputs2.getArray()) {
output2.append(maximum(array))
}
let relu_outputs2 = output2.toArray()
println(relu_outputs2)ReLU outputs after the second forward pass:
[[4.546452, 1.170835, 2.330986], [8.507194, 0.000000, 0.157053], [1.258701, 1.012316, 0.000000]] <- [[4.800000, 1.210000, 2.385000], [8.900000, 0.000000, 0.200000], [1.410000, 1.051000, 0.026000]]
We successfully reduced the output.
Now, let's modify Dense Layer and Activation ReLU classes to implement the above changes, such as the backward method and other minor fixes.
class Activation_ReLU {
var output: Array<Array<Float64>>
var dinputs: Array<Array<Float64>> // new
var inputs: Array<Array<Float64>> // new
public init() {
this.output = []
this.dinputs = [] // new
this.inputs = [] // new
}
public func forward(inputs: Array<Array<Float64>>) {
this.inputs = inputs // new
let output = ArrayList<Array<Float64>>([])
for (array in inputs) {
output.append(maximum(array))
}
this.output = output.toArray()
}
// new
public func backward(dvalues: Array<Array<Float64>>) {
this.dinputs = dvalues.clone()
for (i in 0..this.dinputs.size) {
for (j in 0..this.dinputs[i].size) {
if (this.inputs[i][j] <= 0.0) {
this.dinputs[i][j] = 0.0
}
}
}
}
private func maximum(input: Array<Float64>): Array<Float64> {
func clip(i: Float64): Float64 {
if (i > 0.0) {
return i
} else {
return 0.0
}
}
let output = input |> map {i => clip(i)} |> collectArray
return output
}
}The backward method in the Activation ReLU class is where we calculate and store ReLU derivatives called `dinputs`. We also store the inputs during the forward pass, so that we can access them during the backward pass. Otherwise, the class remains the same.
Next, we modify the Dense Layer class. We again store the inputs to be able to calculate `dweights` in the backward method. We instantiate `dweights`, `dbiases`, and `dinputs` as matrices of size 1x1, as we cannot create empty matrices. Inputs are stored as an array of arrays.
class Layer_Dense {
var weights: Matrix
var biases: Matrix
var output: Array<Array<Float64>>
var inputs: Array<Array<Float64>> // new
var dweights: Matrix // new
var dbiases: Matrix // new
var dinputs: Matrix // new
public init(nInputs: Int64, nNeurons: Int64, batchSize: Int64) {
this.weights = Matrix(
Array<Array<Float64>>(nNeurons, {_ => Array<Float64>(nInputs, {_ => random.nextFloat64() * 0.01})})).
transpose()
this.biases = Matrix(Array<Array<Float64>>(batchSize, {_ => Array<Float64>(nNeurons, {_ => 0.0})}))
this.output = []
this.inputs = [] // new
this.dweights = Matrix(1, 1) // new
this.dbiases = Matrix(1, 1) // new
this.dinputs = Matrix(1, 1) // new
}
public func forward(inputs: Array<Array<Float64>>) {
this.inputs = inputs // new
this.output = Matrix(inputs).times(this.weights).plus(this.biases).getArray()
}
// new
public func backward(dvalues: Array<Array<Float64>>) {
this.dinputs = Matrix(dvalues).times(this.weights.transpose())
this.dweights = Matrix(this.inputs).transpose().times(Matrix(dvalues))
this.dbiases = Matrix(Array<Array<Float64>>(1, {_ => Array<Float64>(dvalues[0].size, {_ => 0.0})})) // fix for the Matrix dimensions must agree exception
for (i in dvalues) {
this.dbiases.plusEquals(Matrix(i))
}
this.dbiases = Matrix(Array<Array<Float64>>(this.biases.getArray().size, {_ => this.dbiases.getArray()[0]})) // padding the biases
}
}The last thing we need to deal with Softmax and CategoricalCrossentropy classes. Instead of implementing the backward method in these classes, we can combine them into one superclass. This will simplify calculations and make backward passes through the 2 classes much faster, as we cut out intermediate steps.
class Activation_Softmax_Loss_CategoricalCrossentropy {
let activation: Activation_Softmax
let loss: Loss_CategoricalCrossentropy
var output: Array<Array<Float64>>
var dinputs: Array<Array<Float64>>
public init() {
this.activation = Activation_Softmax()
this.loss = Loss_CategoricalCrossentropy()
this.output = []
this.dinputs = []
}
public func forward(inputs: Array<Array<Float64>>, yTrue: Array<Int64>) {
this.activation.forward(inputs)
this.output = this.activation.output
return this.loss.calculate(this.output, yTrue)
}
public func backward(dvalues: Array<Array<Float64>>, yTrue: Array<Int64>) {
let samples = dvalues.size
this.dinputs = dvalues.clone()
for ((i, j) in 0..samples |> zip(yTrue)) {
this.dinputs[i][j] -= 1.0
}
for (i in 0..this.dinputs.size) {
for (j in 0..this.dinputs[i].size) {
this.dinputs[i][j] /= Float64(samples)
}
}
}
}Here, we use composition to instantiate the two classes inside one `Activation_Softmax_Loss_CategoricalCrossentropy` superclass. The forward method now combines two previously separate operations - Softmax's forward pass and loss/accuracy calculation - into one step.
The backward method calculates and normalizes the combined gradient of both activation and loss functions in one step. We do that by zipping together the outputs from the forward pass - the predictions - and the predicted values y. We copy the outputs array and call it `dinputs` so that we can safely modify it without affecting the original outputs. Remember that, outputs is a nested array of arrays - each array is a batch of values X. Because y values are indexes in inner predictions arrays, we can access the values corresponding to the prediction and calculate its derivative by subtracting 1 from the original value. Later, we loop through the dinputs array once again to normalize the values by dividing each value by the number of samples in the original array.
The final thing that we need to implement is an optimizer. The optimizer's function is to adjust weights and biases and control the learning process, such as adjusting the learning rate (the direction and magnitude of weights and biases change) and `decay` that lets us decrease the learning rate as time progresses so as to only allow small adjustments to weights and biases toward the end. Learning rate that is too high or is too low affects the learning process. One needs to experiment with different values for his or her network configuration.
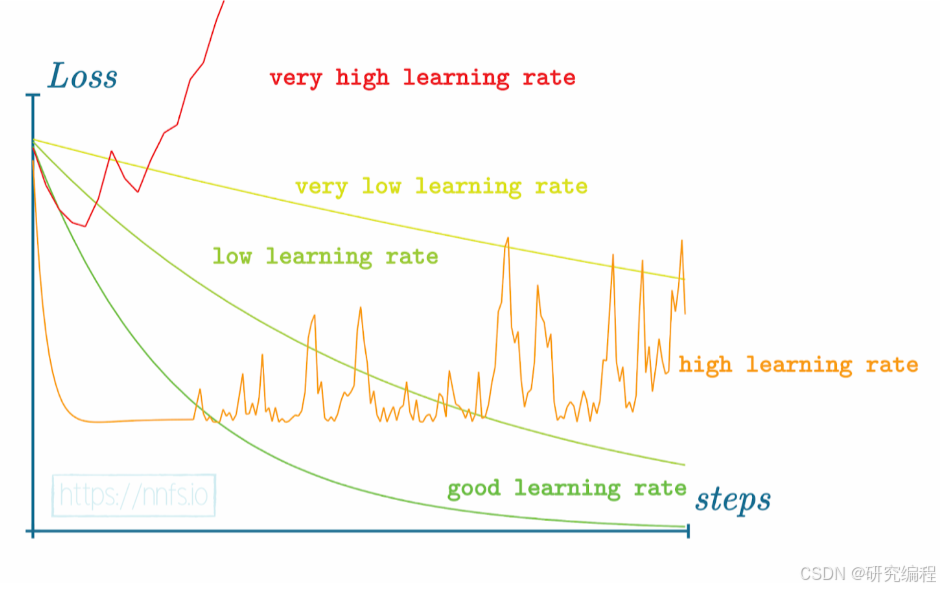
There exist many types of optimizers. The more advanced an optimizer is and the more parameters it can adjust, the more accuracy one can expect from the network.
Today, we will implement one of the basic ones, called Stochastic Gradient Descent (SGD). Its purpose is to update weights and biases with new derived weights and biases and decrease the learning rate with the value of `decay` before each iteration, or forward-backward pass (also called "epoch").
class Optimizer_SGD {
var learningRate: Float64
var decay: Float64
var currentLearningRate: Float64
var iterations: Int64
public init(learningRate!: Float64 = 1.0, decay!: Float64 = 0.0) {
this.learningRate = learningRate
this.currentLearningRate = learningRate
this.decay = decay
this.iterations = 0
}
public func preUpdateParameters() {
if (this.decay > 0.0) {
this.currentLearningRate = this.learningRate * (1.0 / (1.0 + this.decay * Float64(this.iterations)))
}
}
public func postUpdateParameters() {
this.iterations += 1
}
public func updateParameters(layer: Layer_Dense) {
layer.weights.plusEquals(layer.dweights.times(-this.learningRate))
layer.dbiases.plusEquals(layer.dbiases.times(-this.learningRate))
}
}Finally, the full network code up to this point:
import matrix4cj.*
import std.collection.*
import std.random.*
import csv4cj.*
import std.os.posix.*
import std.fs.*
import std.convert.*
import std.math.*
import std.reflect.*
let random = Random(0) // seed = 0
let EPOCHS = 30000
main() {
let X: Array<Array<Float64>>
let y: Array<Int64>
(X, y) = getData()
let dense1 = Layer_Dense(2, 64, X.size)
let activation1 = Activation_ReLU()
let dense2 = Layer_Dense(64, 3, X.size)
let lossActivation = Activation_Softmax_Loss_CategoricalCrossentropy()
// let optimizer = Optimizer_SGD(learningRate: 1.0)
let optimizer = Optimizer_SGD(learningRate: 0.85, decay: 1e-3)
for (epoch in 0..EPOCHS) {
dense1.forward(X)
activation1.forward(dense1.output)
dense2.forward(activation1.output)
let (loss, acc) = lossActivation.forward(dense2.output, y)
if (epoch % 100 == 0) {
println()
println("epoch: ${epoch}, loss: ${loss}, acc: ${acc}, lr: ${optimizer.currentLearningRate}")
}
lossActivation.backward(lossActivation.output, y)
dense2.backward(lossActivation.dinputs)
activation1.backward(dense2.dinputs.getArray())
dense1.backward(activation1.dinputs)
optimizer.preUpdateParameters()
optimizer.updateParameters(dense1)
optimizer.updateParameters(dense2)
optimizer.postUpdateParameters()
}
}
class Optimizer_SGD {
var learningRate: Float64
var decay: Float64
var currentLearningRate: Float64
var iterations: Int64
public init(learningRate!: Float64 = 1.0, decay!: Float64 = 0.0) {
this.learningRate = learningRate
this.currentLearningRate = learningRate
this.decay = decay
this.iterations = 0
}
public func preUpdateParameters() {
if (this.decay > 0.0) {
this.currentLearningRate = this.learningRate * (1.0 / (1.0 + this.decay * Float64(this.iterations)))
}
}
public func postUpdateParameters() {
this.iterations += 1
}
public func updateParameters(layer: Layer_Dense) {
layer.weights.plusEquals(layer.dweights.times(-this.learningRate))
layer.dbiases.plusEquals(layer.dbiases.times(-this.learningRate))
}
}
class Activation_Softmax_Loss_CategoricalCrossentropy {
let activation: Activation_Softmax
let loss: Loss_CategoricalCrossentropy
var output: Array<Array<Float64>>
var dinputs: Array<Array<Float64>>
public init() {
this.activation = Activation_Softmax()
this.loss = Loss_CategoricalCrossentropy()
this.output = []
this.dinputs = []
}
public func forward(inputs: Array<Array<Float64>>, yTrue: Array<Int64>) {
this.activation.forward(inputs)
this.output = this.activation.output
return this.loss.calculate(this.output, yTrue)
}
public func backward(dvalues: Array<Array<Float64>>, yTrue: Array<Int64>) {
let samples = dvalues.size
this.dinputs = dvalues.clone()
for ((i, j) in 0..samples |> zip(yTrue)) {
this.dinputs[i][j] -= 1.0
}
for (i in 0..this.dinputs.size) {
for (j in 0..this.dinputs[i].size) {
this.dinputs[i][j] /= Float64(samples)
}
}
}
}
open class Loses {
public func calculate(output: Array<Array<Float64>>, y: Array<Int64>): (Float64, Float64) {
// mean loss
let sampleLoses = this.forward(output, y)
let sampleLosesSum = sampleLoses |> reduce(this.sum)
let dataLoss = sampleLosesSum.getOrThrow() / Float64(sampleLoses.size)
// argmax
let result = this.argmax(output)
// accuracy
let acc = accuracy(result, y)
return (dataLoss, acc)
}
public open func forward(yPred: Array<Array<Float64>>, yTrue: Array<Int64>): Array<Float64> {
return []
}
private func sum(x: Float64, y: Float64): Float64 {
return x + y
}
private func accuracy(argmax: Array<Int64>, y: Array<Int64>): Float64 {
let values = ArrayList<Float64>([])
for ((i, j) in argmax |> zip(y)) {
if (i == j) {
values.append(1.0)
} else {
values.append(0.0)
}
}
let valuesSum = values |> reduce(this.sum)
let accuracy = valuesSum.getOrThrow() / Float64(values.size)
return accuracy
}
private func argmax(yPred: Array<Array<Float64>>) {
let indexes = ArrayList<Int64>([])
for (y in yPred) {
var index = 0
var value = y[0]
for ((e, v) in enumerate(y)) {
if (v > value) {
index = e
value = v
}
}
indexes.append(index)
}
return indexes.toArray()
}
}
class Loss_CategoricalCrossentropy <: Loses {
public override func forward(yPred: Array<Array<Float64>>, yTrue: Array<Int64>): Array<Float64> {
var confidencesList = ArrayList<Float64>([])
for ((targIdx, distribution) in yTrue |> zip(yPred)) {
confidencesList.append(distribution[targIdx])
}
let negativeLogLikelyhoods = confidencesList |> map {i => -log(clamp(i, 1e-7, 1.0 - 1e-7))} |> collectArray
return negativeLogLikelyhoods
}
}
class Activation_Softmax {
var output: Array<Array<Float64>>
public init() {
this.output = []
}
public func forward(inputs: Array<Array<Float64>>) {
let output = ArrayList<Array<Float64>>([])
for (input in inputs) {
let maxValue = max(input)
let subtractedInput = input |> map {i: Float64 => i - maxValue.getOrThrow()} |> collectArray
let exponentiatedInput = subtractedInput |> map {i => exp(i)} |> collectArray
let normBase = exponentiatedInput |> reduce(sum)
// 标准化
let probabilities = exponentiatedInput |> map {i => i / normBase.getOrThrow()} |> collectArray
output.append(probabilities)
}
this.output = output.toArray()
}
private func sum(x: Float64, y: Float64): Float64 {
return x + y
}
}
class Activation_ReLU {
var output: Array<Array<Float64>>
var dinputs: Array<Array<Float64>> // new
var inputs: Array<Array<Float64>> // new
public init() {
this.output = []
this.dinputs = [] // new
this.inputs = [] // new
}
public func forward(inputs: Array<Array<Float64>>) {
this.inputs = inputs // new
let output = ArrayList<Array<Float64>>([])
for (array in inputs) {
output.append(maximum(array))
}
this.output = output.toArray()
}
// new
public func backward(dvalues: Array<Array<Float64>>) {
this.dinputs = dvalues.clone()
for (i in 0..this.dinputs.size) {
for (j in 0..this.dinputs[i].size) {
if (this.inputs[i][j] <= 0.0) {
this.dinputs[i][j] = 0.0
}
}
}
}
private func maximum(input: Array<Float64>): Array<Float64> {
func clip(i: Float64): Float64 {
if (i > 0.0) {
return i
} else {
return 0.0
}
}
let output = input |> map {i => clip(i)} |> collectArray
return output
}
}
class Layer_Dense {
var weights: Matrix
var biases: Matrix
var output: Array<Array<Float64>>
var inputs: Array<Array<Float64>> // new
var dweights: Matrix // new
var dbiases: Matrix // new
var dinputs: Matrix // new
public init(nInputs: Int64, nNeurons: Int64, batchSize: Int64) {
this.weights = Matrix(
Array<Array<Float64>>(nNeurons, {_ => Array<Float64>(nInputs, {_ => random.nextFloat64() * 0.01})})).
transpose() // <-
this.biases = Matrix(Array<Array<Float64>>(batchSize, {_ => Array<Float64>(nNeurons, {_ => 0.0})}))
this.output = []
this.inputs = [] // new
this.dweights = Matrix(1, 1) // new
this.dbiases = Matrix(1, 1) // new
this.dinputs = Matrix(1, 1) // new
}
public func forward(inputs: Array<Array<Float64>>) {
this.inputs = inputs // new
this.output = Matrix(inputs).times(this.weights).plus(this.biases).getArray()
}
// new
public func backward(dvalues: Array<Array<Float64>>) {
this.dinputs = Matrix(dvalues).times(this.weights.transpose())
this.dweights = Matrix(this.inputs).transpose().times(Matrix(dvalues))
this.dbiases = Matrix(Array<Array<Float64>>(1, {_ => Array<Float64>(dvalues[0].size, {_ => 0.0})})) // fix for the Matrix dimensions must agree exception
for (i in dvalues) {
this.dbiases.plusEquals(Matrix(i))
}
this.dbiases = Matrix(Array<Array<Float64>>(this.biases.getArray().size, {_ => this.dbiases.getArray()[0]})) // padding the biases
}
}
func getData() {
let yIdx: Int64 = 2
let X = ArrayList<Array<Float64>>([])
let y = ArrayList<Int64>([])
let path: String = getcwd()
let fileStream = File("${path}/test.csv", OpenOption.Open(true, false))
//打开文件流
if (fileStream.canRead()) {
//创建字符读取的解析流
let stream = UTF8ReaderStream(fileStream)
let reader = CSVReader(stream)
//创建格式化的解析参数
let format: CSVParseFormat = CSVParseFormat.DEFAULT
//创建解析器
let csvParser = CSVParser(reader, format)
for (csvRecord in csvParser) {
let values = csvRecord.getValues()
X.append(Array<Float64>(values[..yIdx].size, {j => Float64.parse(values[..yIdx][j].toString())}))
y.append(Int64.parse(values[yIdx].toString()))
}
fileStream.close()
}
return (X.toArray(), y.toArray())
}We can begin training our network.
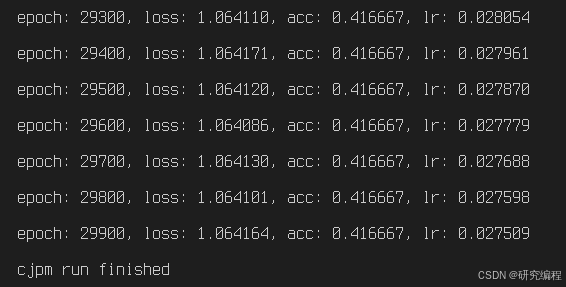
With the initial learning rate set to 0.85 and decay set to 0.001, after 30,000 epochs, the best result that I saw was the accuracy of 44%. It is an improvement from the randomly initialized 33%, but it is still very low. While the loss is continuously decreasing, it decreases very slowly and also spikes randomly.
The next thing we can do is implement better and smarter optimizers and look into the so-called L1 and L2 regularization. After examining individual weights and biases, it appears that we have exploding gradient - very big values for derived weights and biases. This is a solution for the next tutorial, as I need time to study the book and experiment with different parameters. I will also try a simpler dataset to do some comparison tests.
下次见,谢谢阅读!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









