







 本文探讨了embedding技术在特征工程、画像构建、召回排序等领域的应用,特别是在利用fasttext与faiss实现的多种召回算法中,如iten2vec、media2vec、tag2vec等,以及u2i召回算法的实现,包括uese2vec、word2vec个性化、crosstag和DSSM个性化等。同时,文章还讨论了embedding如何融入特征工程和排序流程。
本文探讨了embedding技术在特征工程、画像构建、召回排序等领域的应用,特别是在利用fasttext与faiss实现的多种召回算法中,如iten2vec、media2vec、tag2vec等,以及u2i召回算法的实现,包括uese2vec、word2vec个性化、crosstag和DSSM个性化等。同时,文章还讨论了embedding如何融入特征工程和排序流程。
腾讯技术工程
embedding 也迅速的用到了特征工程,画像构建召回排序等方面。而 faiss 作为专业的向量近邻检索工具则解决了向量召回在工程上的最后一公里的问题。
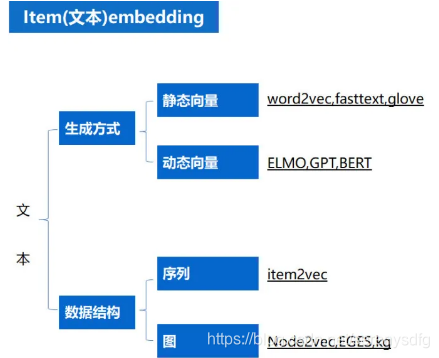
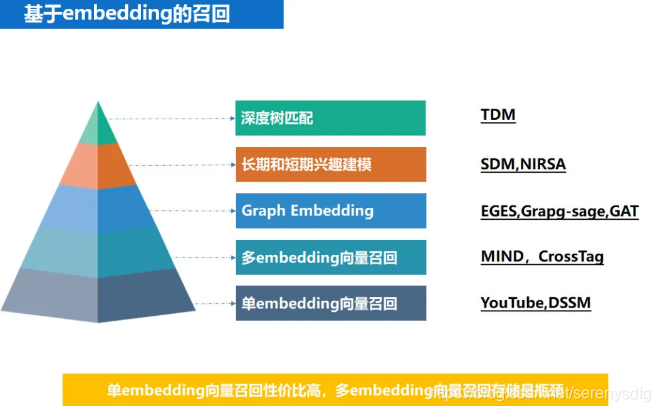
embedding召回分类
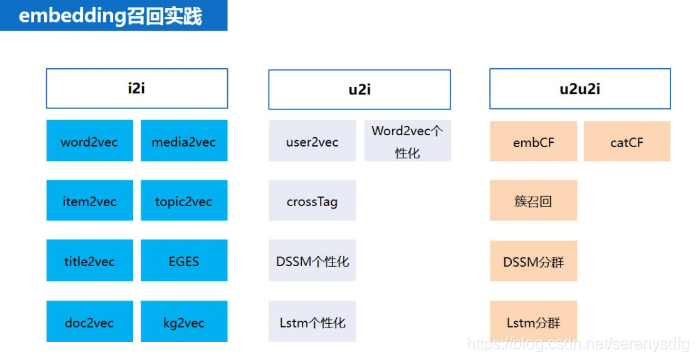
1. embedding 的基础用法——i2i 召回算法
单纯使用 fasttext+faiss 就可以实现好几路召回算法,比如 :
iten2vec,media2vec,tag2vec,loc2vec,title2vec。
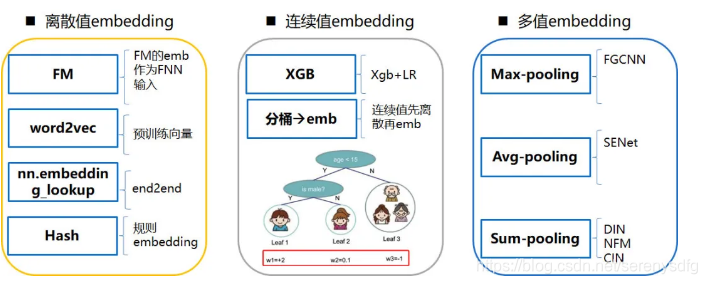
1、tag2vec 就是利用词向量去做召回,比如可以用文章的标签向量表示文章的向量,可以前 3 个 tag,做等权重向量相加,关于 embedding 向量的用法有很多种比如,等权重相加,加权相加,取平均,取最大等。
2、item2vec 是训练文章 ID(aid)所对应的向量,media2vec 训练的是文章的作者 ID(mid)所对应的向量,loc2vec 是训练地域名称所对应的向量,title2vec 是用 LSTM 训练得到的文章标题向量,doc2vec 是用 bert 计算出的文章正文(或者摘要)的向量。entity2vec 是利用我们自己构建的知识图谱通过 transE 得到的
2
2. u2i 召回算法初步
u2i 召回算法实现了,uese2vec,word2vec 个性化,crosstag,DSSM 个性化等召回算法;user2vec 是拿用户的 tag 向量和文章的 tag 向量求相似度,做的召回;DSSM 个性化是拿用户的 DSSM 向量和文章的 DSSM 向量求相似度,做的召回;crosstag 相当于多个 user2vec,需要把用户的 tag 按类别进行统计,每个类取 K 个 tag,共获取 m 组 tag,然后各组分别做 user2vec,最后汇总得到用户的推荐列表。
embedding与排序
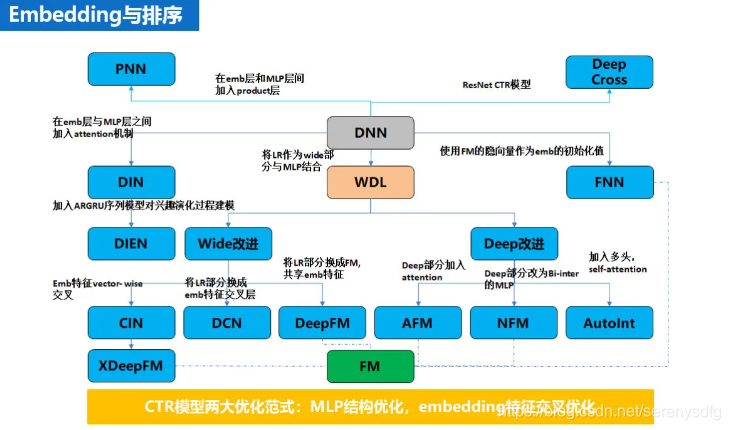
特征embedding化
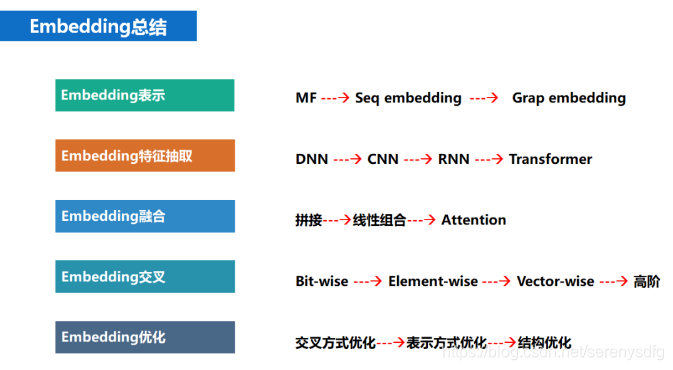
总结

















 5210
5210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









