




 本文探讨了多目标学习在推荐系统中的关键模型,包括MMoE、ESMM及DUPN等,解析了如何通过多任务学习解决样本选择偏差和数据稀疏问题,以及如何利用专家网络和门控机制提升模型效率。
本文探讨了多目标学习在推荐系统中的关键模型,包括MMoE、ESMM及DUPN等,解析了如何通过多任务学习解决样本选择偏差和数据稀疏问题,以及如何利用专家网络和门控机制提升模型效率。
MMOE
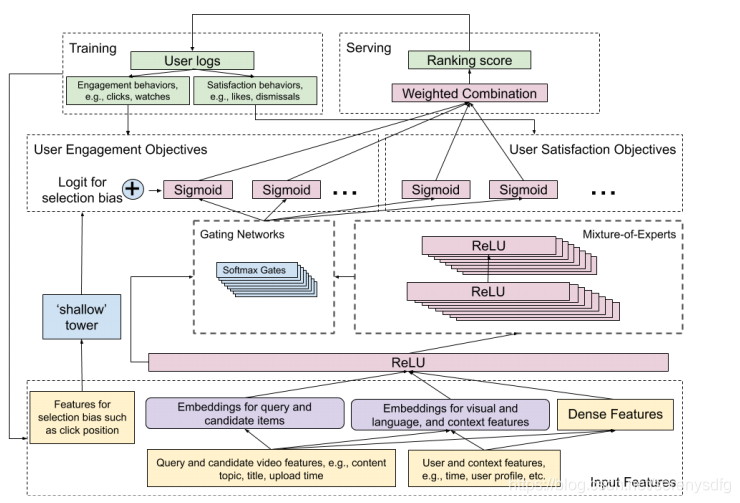
左侧的shallow tower部分和右侧的main tower部分,论文中提到的采用类似Wide&Deep模型结构就是指这两个tower,其中shallow tower可以对应Wide部分,main tower对应的是Deep部分
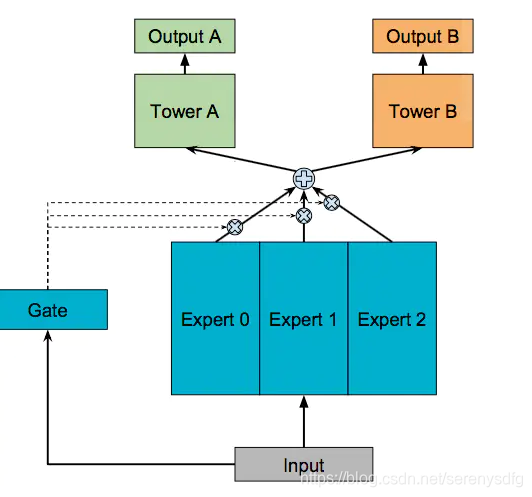
存在n个Expert网络,每个Expert网络的输出最终会经过Gating Network进行加权平均(比较简单的线性加权,Attention的思想)
对于不同的任务通过相应的Gating Network来对不同的Expert赋予不同的权重,使得部分Expert“专注于各自擅长的任务”
Shallow Tower部分
position bias问题,文章中shallow Tower部分主要作用就是消除Position bias的影响。这部分模型的输入是与position bias相关的一些特征(如广告展现时的排序位置、用户机型等),文章提到了用户机型也算在这部分feature当中,比较直观的认知是不同机型的尺寸的差异可能会对这些position bias有所影响。实际上我们线上的PC搜索模型当中也是采用同样的架构,即Main Tower + Shallow Tower这种类似Wide&Deep的模型结构
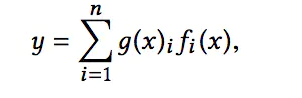
ESMM
CVR 是指从点击到购买的转化,传统的 CVR 预估会存在两个问题:样本选择偏差和稀疏数据。
样本选择偏差是指模型用用户点击的样本来训练,但是预测却是用的整个样本空间。数据稀疏问题是指用户点击到购买的样本太少。因此阿里提出了 ESMM 模型来解决上述两个问题:主要借鉴多任务学习的思路,引入两个辅助的学习任务,分别用来拟合 pCTR 和 pCTCVR。
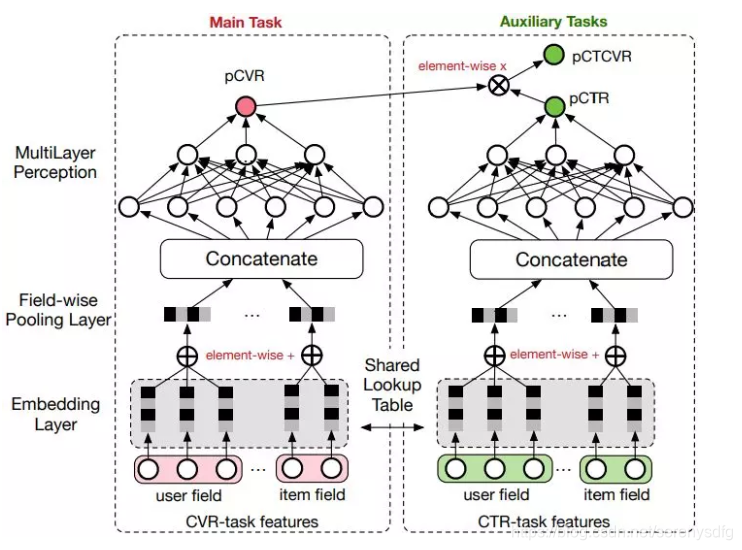
ESMM 模型由两个子网络组成,左边的子网络用来拟合 pCVR,右边的子网络用来拟合 pCTR,同时,两个子网络的输出相乘之后可以得到 pCTCVR。因此,该网络结构共有三个子任务,分别用于输出 pCTR、pCVR 和 pCTCVR
阿里 DUPN
比如多个任务共享一份 embedding 参数。学习的用户、商品向量表示可方便迁移到其它任务中。本文提出了一种多任务模型 DUPN
1天级更新模型:随着时间和用户兴趣的变化,ID 特征的 Embedding 需要不断更新,但每次都全量训练模型的话,需要耗费很长的时间。通常的做法是每天使用前一天的数据做增量学习,这样一方面能使训练时间大幅下降;另一方面可以让模型更贴近近期数据。
2 模型拆分:由于 CTR 任务是 point-wise 的,如果有 1w 个物品的话,需要计算 1w 次结果,如果每次都调用整个模型的话,其耗费是十分巨大的。其实 user Reprentation 只需要计算一次就好。因此我们会将模型进行一个拆解,使得红色部分只计算一次,而蓝色部分可以反复调用红色部分的结果进行多次计算。
美团 “猜你喜欢” 深度学习排序模型
Missing Value Layer:缺失的特征可根据对应特征的分布去自适应的学习出一个合理的取值。
阿里 MMoE
阿里ESM2
YouTube 多目标排序系统
知乎推荐页 Ranking 模型

















 611
611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









