




 本文深入探讨了一维和多维梯度下降算法,包括其数学原理和应用,对比了批量、随机及小批量梯度下降的不同特性,介绍了自适应方法如牛顿法和共轭梯度法,以及动态学习率的使用。
本文深入探讨了一维和多维梯度下降算法,包括其数学原理和应用,对比了批量、随机及小批量梯度下降的不同特性,介绍了自适应方法如牛顿法和共轭梯度法,以及动态学习率的使用。
1梯度下降
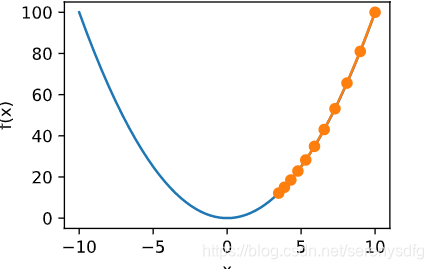
一维梯度下降
**证明:沿梯度反方向移动自变量可以减小函数值** (梯度:导数) x -= lr* gradf(x)
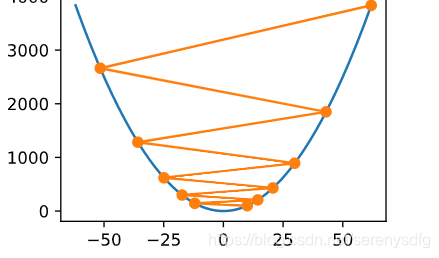
根据公式:学习率(lr)太小达不到最低点,太大动荡变化
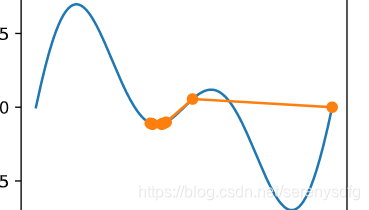
局部极小值挑战:学习率过大动荡会到另一个局部最小值
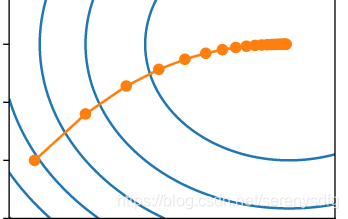
多维梯度下降
等高线 (x1 - eta * 2 * x1, x2 - eta * 4 * x2)
2自适应方法
2.1牛顿法
需要计算Heissan矩阵,计算量很大(也可以用Heissan阵辅助梯度下降,不详细介绍)

c = 0.5
def f(x):
return np.cosh(c * x) # Objective
def gradf(x):
return c * np.sinh(c * x) # Derivative
def hessf(x):
return c**2 * np.cosh(c * x) # Hessian
# Hide learning rate for now
def newton(eta=1):
x = 10
results = [x]
for i in range(10):
x -= eta * gradf(x) / hessf(x) #学习率*一阶导数/二阶导数
results.append(x)
print('epoch 10, x:', x)
return results
show_trace(newton()) #仍需要调整学习率2.2 共轭梯度法(梯度下降与线性搜索结合)
多维:方向正确加快速度
3随机梯度下降
(1)批量梯度下降BGD使用整个数据集(时间复杂度O(n)):全局最优解;易于并行实现
(2)随机梯度下降SGD使用单个样本的梯度(时间复杂度O(1)):每个样本计算完都对t梯度更新
优点:计算速度快,缺点:收敛性能不好 解决(使用动态学习率,学习率变化开始快后面慢)
def exponential(): #动态学习率
global ctr
ctr += 1
return math.exp(-0.1 * ctr)
lr=exponential()(3)小批量梯度下降法MBGD
把数据分为若干个批,按批来更新参数,这样,一个批中的一组数据共同决定了本次梯度的方向,下降起来就不容易跑偏,减少了随机性. 优点:减少了计算的开销量,降低了随机性
随机梯度下降(SGD)和 批量梯度下降(BGD)的公式对比、实现对比
1、批量梯度下降
由于是要最小化风险函数,所以按每个参数theta的梯度负方向,来更新每个theta,得到的是一个全局最优解,迭代速度慢
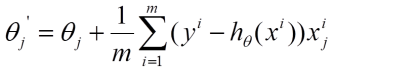
2、随机梯度下降的求解思路如下:
每个样本的损失函数,对theta求偏导得到对应梯度,来更新theta
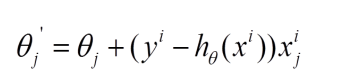
随机梯度下降是通过每个样本来迭代更新一次,如果样本量很大的情况(例如几十万),那么可能只用其中几万条或者几千条的样本,就已经将theta迭代到最优解了,对比上面的批量梯度下降,迭代一次需要用到十几万训练样本,一次迭代不可能最优,如果迭代10次的话就需要遍历训练样本10次。但是,SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。

















 333
333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









