



 本文详细介绍了MPEG音频压缩的原理,包括MPEG标准的背景及其在视听传播中的作用。重点阐述了编码流程,特别是听觉临界频带的概念,以及心理声学模型在量化和编码中的应用。通过模型分析音乐帧与噪声帧的差异,揭示了人耳对不同音频信号的感知特性,并探讨了比特分配策略。此外,还展示了代码实现中如何输出音频采样率和目标码率,并提及了对噪声帧和音乐帧的分析方法。
本文详细介绍了MPEG音频压缩的原理,包括MPEG标准的背景及其在视听传播中的作用。重点阐述了编码流程,特别是听觉临界频带的概念,以及心理声学模型在量化和编码中的应用。通过模型分析音乐帧与噪声帧的差异,揭示了人耳对不同音频信号的感知特性,并探讨了比特分配策略。此外,还展示了代码实现中如何输出音频采样率和目标码率,并提及了对噪声帧和音乐帧的分析方法。
MPEG原理
介绍:
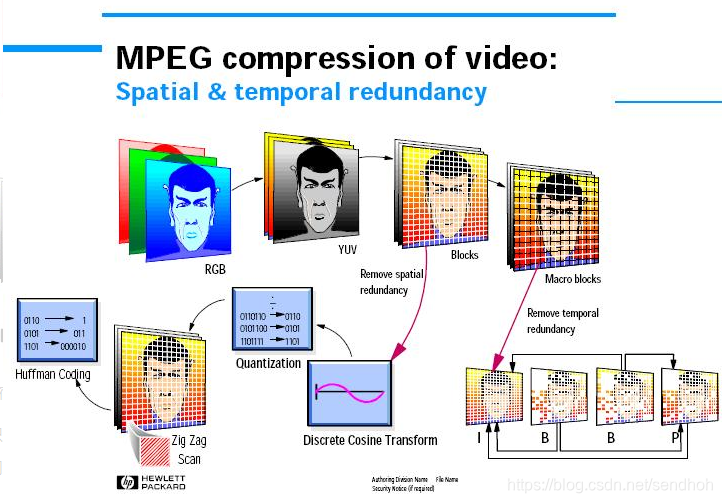
MPEG标准主要有以下五个,MPEG-1、MPEG-2、MPEG-4、MPEG-7及MPEG-21等。该专家组建于1988年,专门负责为CD建立视频和音频标准,而成员都是为视频、音频及系统领域的技术专家。及后,他们成功将声音和影像的记录脱离了传统的模拟方式,建立了ISO/IEC11172压缩编码标准,并制定出MPEG-格式,令视听传播方面进入了数码化时代。因此,大家现时泛指的MPEG-X版本,就是由ISO (InternationalOrganization for Standardization) 所制定而发布的视频、音频、数据的压缩标准。
编码流程框架:
MPEG音频压缩: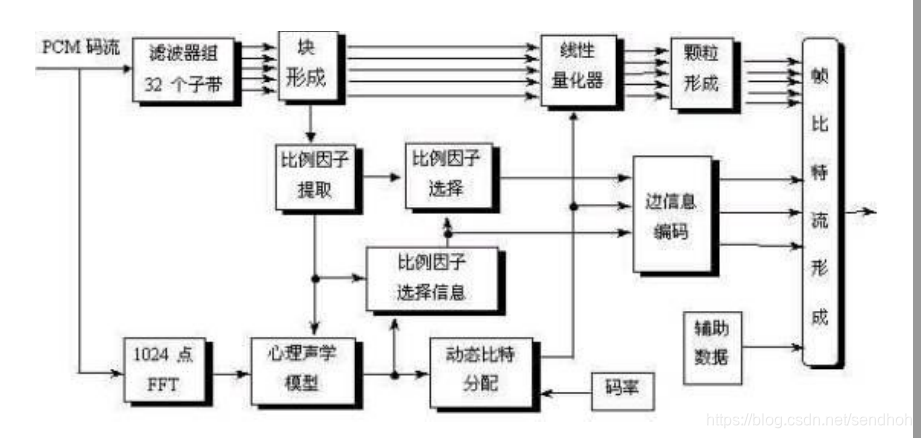
临界频带的概念
听觉临界频带:当噪声掩蔽纯音时,起作用的是以纯音频率为中心频率的一定频带宽度内的噪声频率。如这频带内的噪声功率等于在噪声中刚能听到的该纯音的功率,则这频带就称为听觉临界频带。
临界频带表征了人类最主要的听觉特性,它是在研究纯音对窄带噪声掩蔽量的规律时被发现的,在加宽噪声带宽时,最初是掩蔽量增大,但带宽超过某一定值后,掩蔽量就不再增加,这一带宽就称为临界频带。
编码时输入声音信号经过一个多相滤波器组,变换到多个子带。这里先分成32个相等的子带。
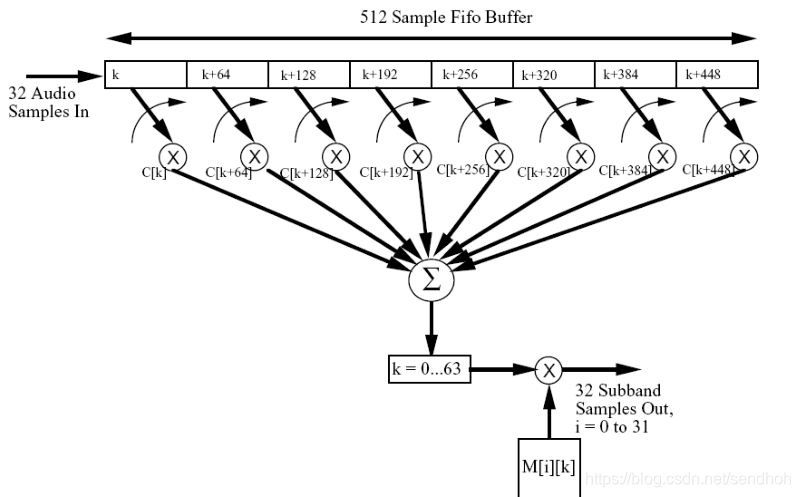
同时经过“心理声学模型”计算以频率为自变量的噪声掩蔽阈值。量化和编码部分用信掩比阈值。
然后进行量化和编码
心理声学模型:
1、用FFT求信号的频谱特性
2、根据频谱特性求各频率点上的有调成分和无调成分
3、根据遮蔽曲线,求各个有调成分和无调成分在其他频点的遮蔽值。
4、求各频点的总遮蔽曲线,并折算到编码子带上。
心理声学模型最终输出每个子带的值:SMR(signalto‐mask ratio)信掩比。

我们看到心理声学模型给我提供了至关重要的一条就是人耳的频率掩蔽效应:
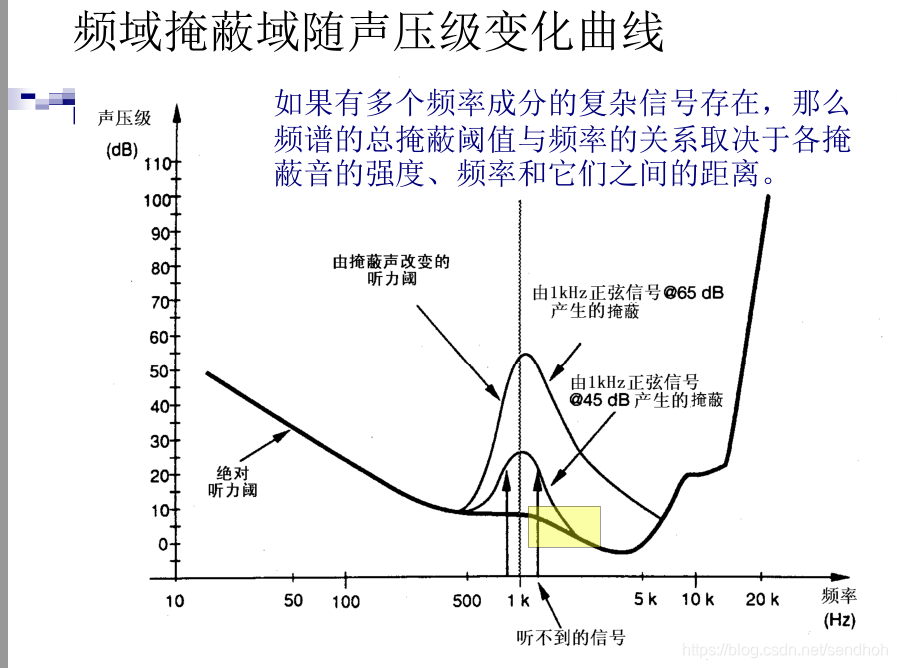
对高频不正确——高频区的临界频带很宽,可能跨越多个子带,从而导致模型1将临界带宽内所有的非音调部分集中为一个代表频率,当一个子带在很宽的频带内却远离代表频率时,无法得到准确的非音调掩蔽值。但计算量低。
然后我们进行:
对各个子带每12 个样点进行一次比例因子计算。先定出12个样点中绝对值的最大值。查比例因子表中比这个最大值大的最小值作为比例因子。
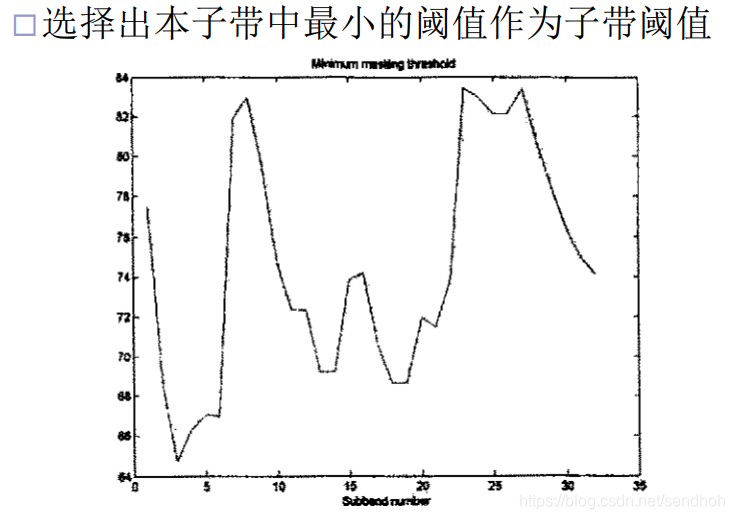
用6bit表示: 第2 层的一帧对应36 个子带样值,是第1 层的三倍,原则上要传三个比例因子。为了降低比例因子的传输码率,采用了利用人耳时域掩蔽特性的编码策略。
通过这一模型可以得出信掩比,再通过比特分配这里的公式为MNR = SNR–SMR。最后我们将SMR传递给编码单元。
而要把噪掩比降低,最好降低到0。其中,我们知道根据量化的估计,每提升1比特,信噪比就可以提升6dB,于是就可以利用这一点进行比特分配。
代码实现
直接可输出音频采样率和目标码率:
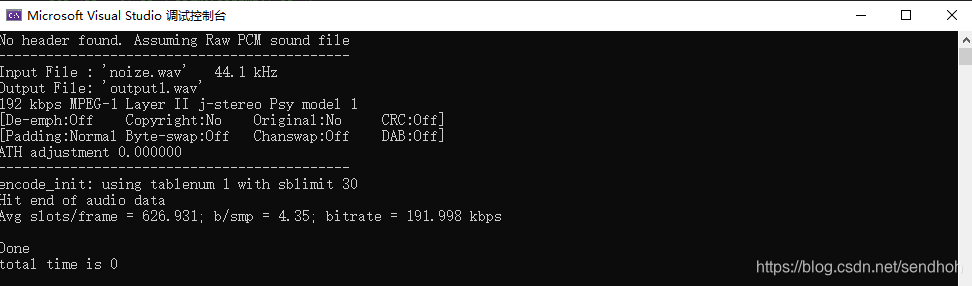
下面这个是自己录的噪声的:
下面是老师给出的test.wav:
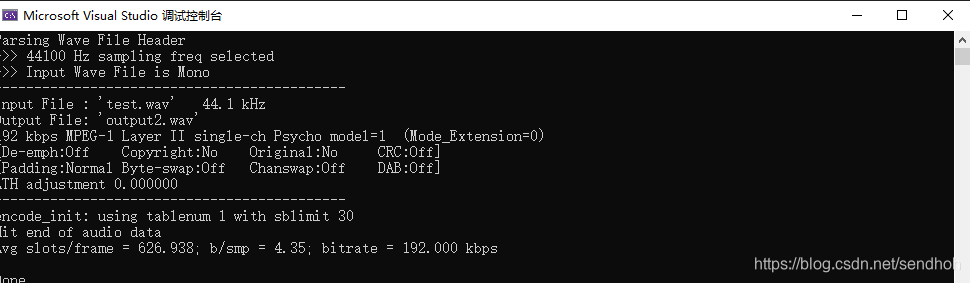
可以看出音频采样率是44.1kHz,而目标码率是192kbps。
下面我们在主函数中:
增加代码输出每一帧的比例因子以及比特分配以及声道数以及每一帧的比特数。
这个实验其实还需要在主函数中用trace打开文件并定义初值,这里不给出了。
噪声帧分析
挑选某一帧分析:
我录的这个噪音文件的第一帧都是零,所以我们选取第二帧。
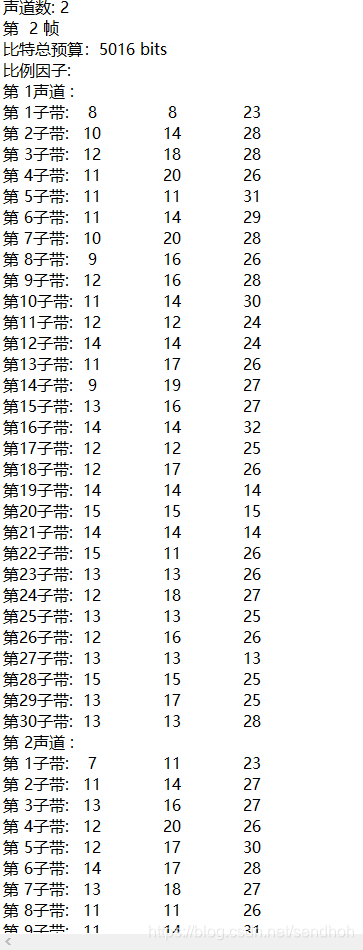


音乐帧分析
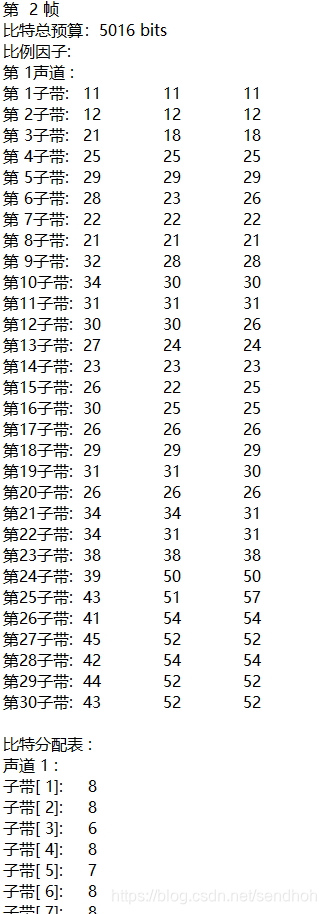

我们可以看见这个音乐文件在23以后的子带就没有分布了,而噪音则在高频区仍然有分布。噪音分布的频率更加的平均了

















 329
329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









